[Cache API] 프론트엔드의 자체적인 HTTP caching 구현 및 만료 일자 지정하기 (feat. 서버의 response headers를 변경할 수 없을 때)
Frontend | Library & Framework
본 글은 개인적인 주짓수 도복 큐레이션 웹 앱의 개발 과정을 담았으며, 정보의 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
0. Introduction
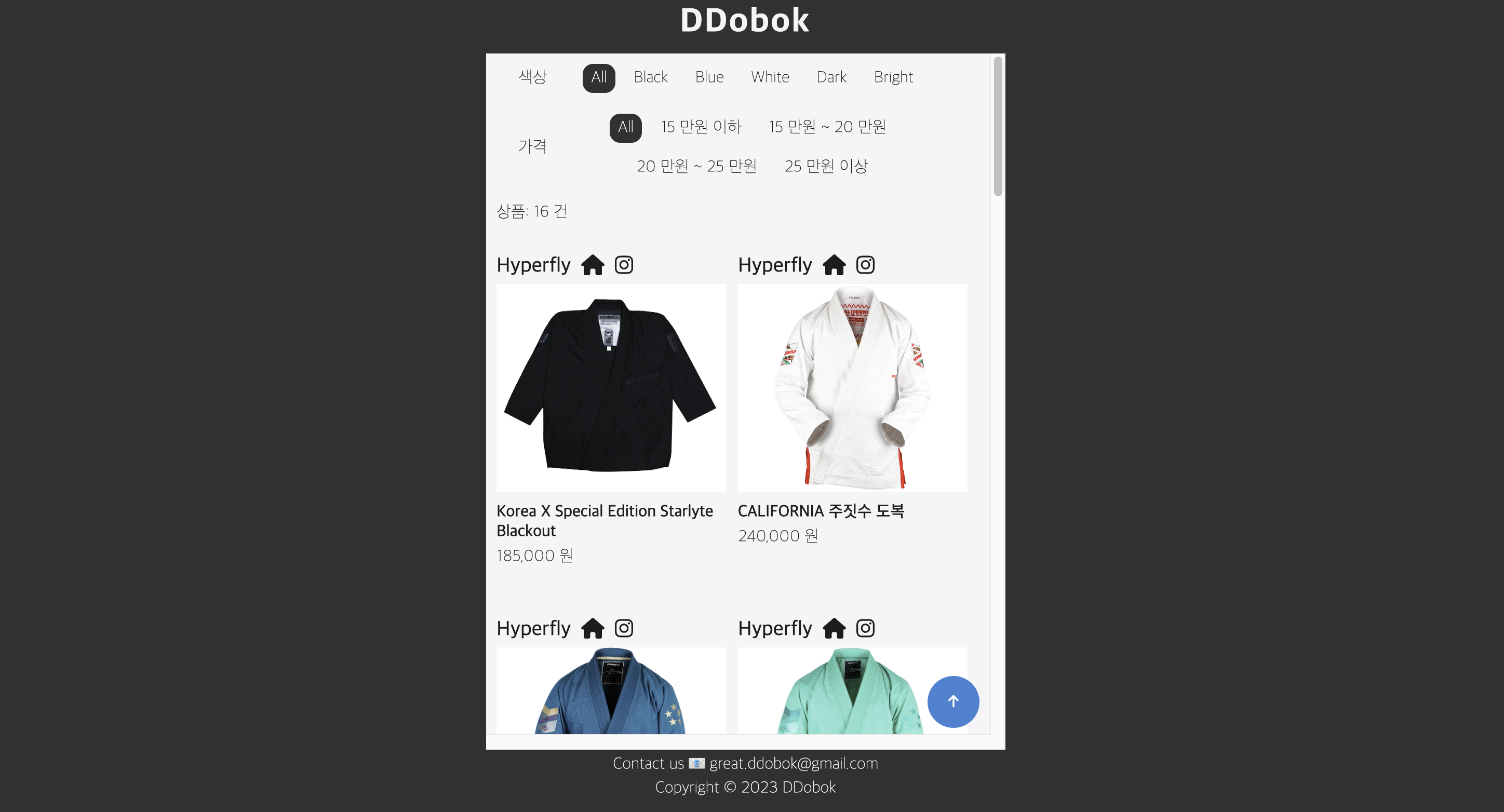
백엔드로부터 리소스를 받기 위해 API 통신을 하다보면 이미 존재하는 데이터를 불필요하게 재요청하는 경우가 있다. 이 경우 서버의 부하를 높일 뿐만 아니라 프론트 단에서도 서버의 응답을 매번 기다려야 하므로 웹 성능이 저하되는 문제점이 발생한다. 필자는 아래의 웹 페이지에서 도복의 정보와 이미지를 응답받는 경우 2 가지의 개선점이 필요하다고 느꼈고 캐싱 기술을 도입하기로 하였다.
- 사용자가 색상/가격 필터를 변경할 때마다
GET요청이 매번 발생한다.- 용량이 비교적 큰 이미지 데이터를 매번 요청하면 웹 로딩 성능이 좋지 않을 것이다.
0.1 HTTP caching 이란?
캐싱(Caching)은 주어진 리소스의 복사본을 저장하고 있다가 요청 시에 서버로부터 리소스를 다시 다운받지 않고 해당 복사본을 반환하는 기술이다. 이를 활용하면 서버의 부하를 완화하고, 리소스가 클라이언트에 더 가깝게 존재하므로 회신에 더 적은 시간이 소요되어 성능이 향상될 수 있다. HTTP 캐싱에서는 일반적으로 GET에 대한 응답을 캐싱한다.
0.2 본 프로젝트의 캐싱 목표
본 프로젝트의 리소스는 개발자가 admin 페이지에서 변경하고 있으므로 정보의 실시간 업데이트가 비교적 중요하지 않다. 또한 리소스 변경 빈도도 낮으므로 사용자가 하루 단위로 새로운 데이터를 전달받는 것도 적절하다고 판단하였다.
- 리소스 복사본이 1 일이 지나면 만료(
stale)되었다고 판단하여 서버에 요청을 보낸다. - 도복 정보 필터링에 의한 잦은 HTTP 요청을 줄이자.
1. HTTP cahcing 구현하기
1.1 누가 캐싱 유효 기간을 결정할 것인가?
일반적인 HTTP caching은 프론트와 백엔드 간 사전에 캐싱 규약을 정하고, 서버에서 응답을 보내줄 때 Cache-Control 헤더에 따라 리소스의 유효 기간을 전달한다. 리소스가 아직 신선하다면 브라우저는 서버에 요청을 보내는 것이 아니라 디스크/메모리에서만 캐시를 읽어와 사용한다. 본 프로젝트의 서버 응답은 아래와 같이 2 가지로 나눌 수 있다.
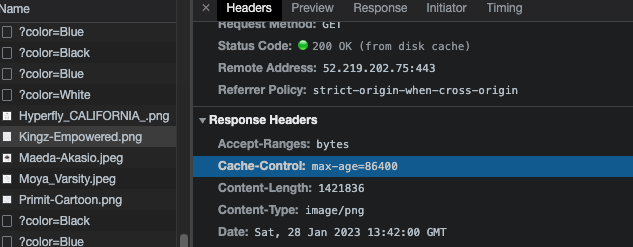
예시 1: Response Header를 통한 HTTP caching
첫 번째 예시는 서버로부터 받아오는 이미지 리소스의 응답에 Cache-Control이 이미 되어 있는 경우이다. 백엔드에서 이미지 저장소로 AWS S3 버킷을 사용하고 있는데 자동으로 Cache-Control 헤더를 아래와 같이 1 일로 붙여주고 있다고 한다.
따라서 좌측의 최초 페이지 로딩 시에는 서버의 응답을 일일히 받아오지만, 우측에서는 이미지가 메모리에 캐싱되어 리소스 로딩 시간이 단축된 것을 확인할 수 있다.
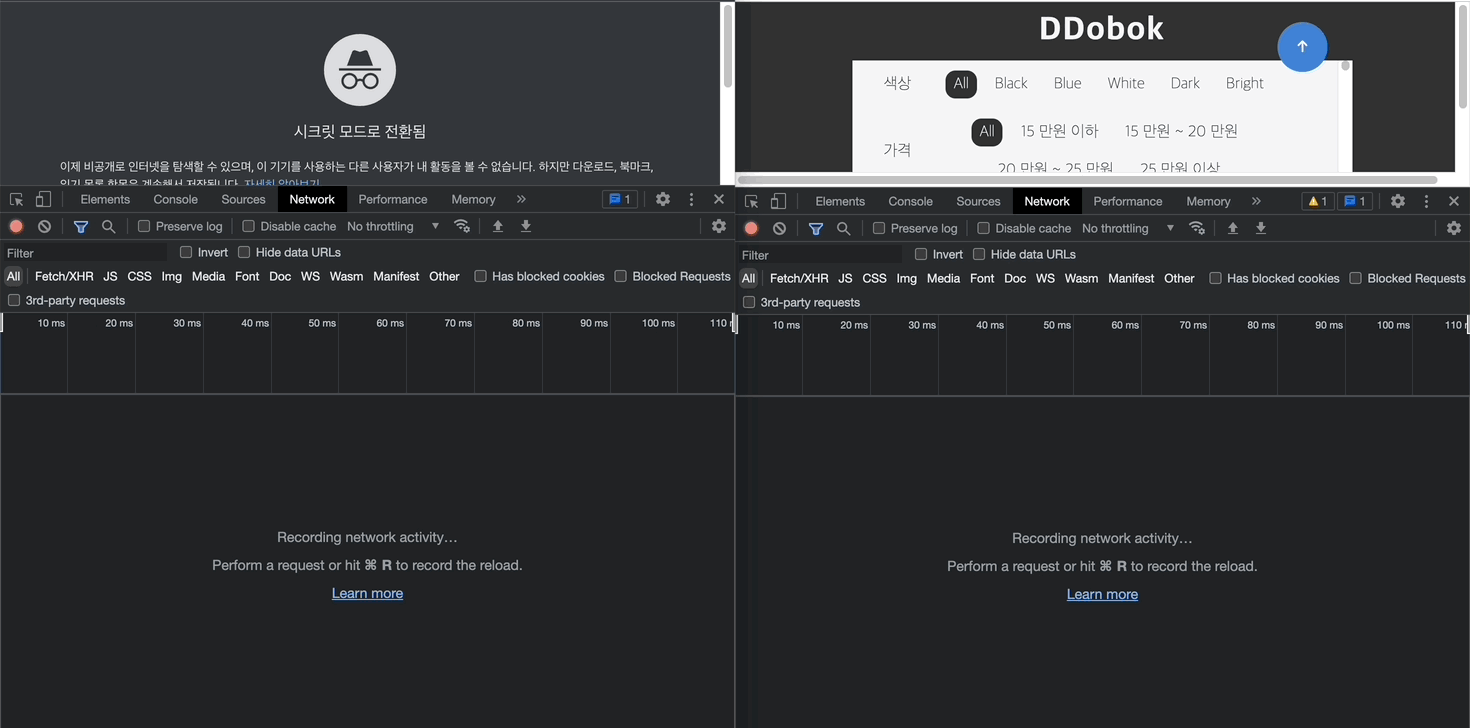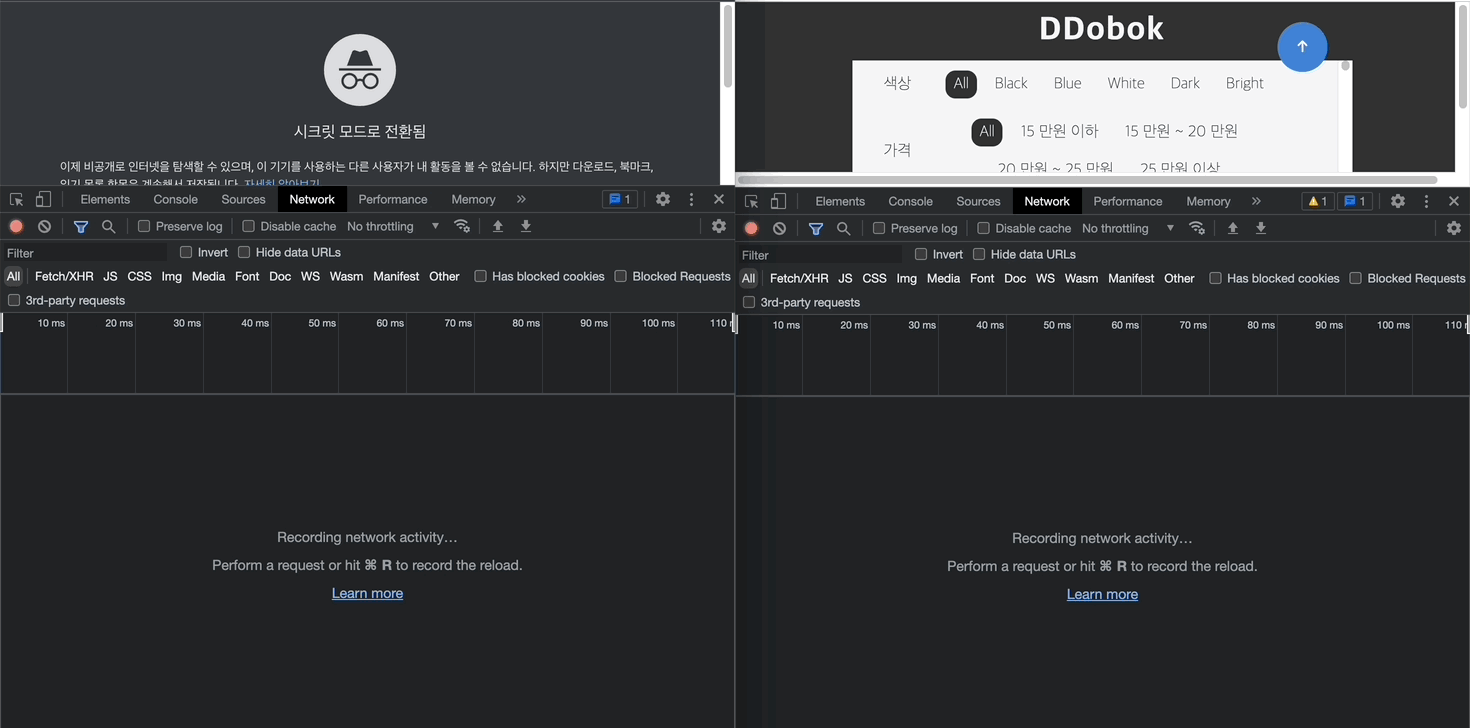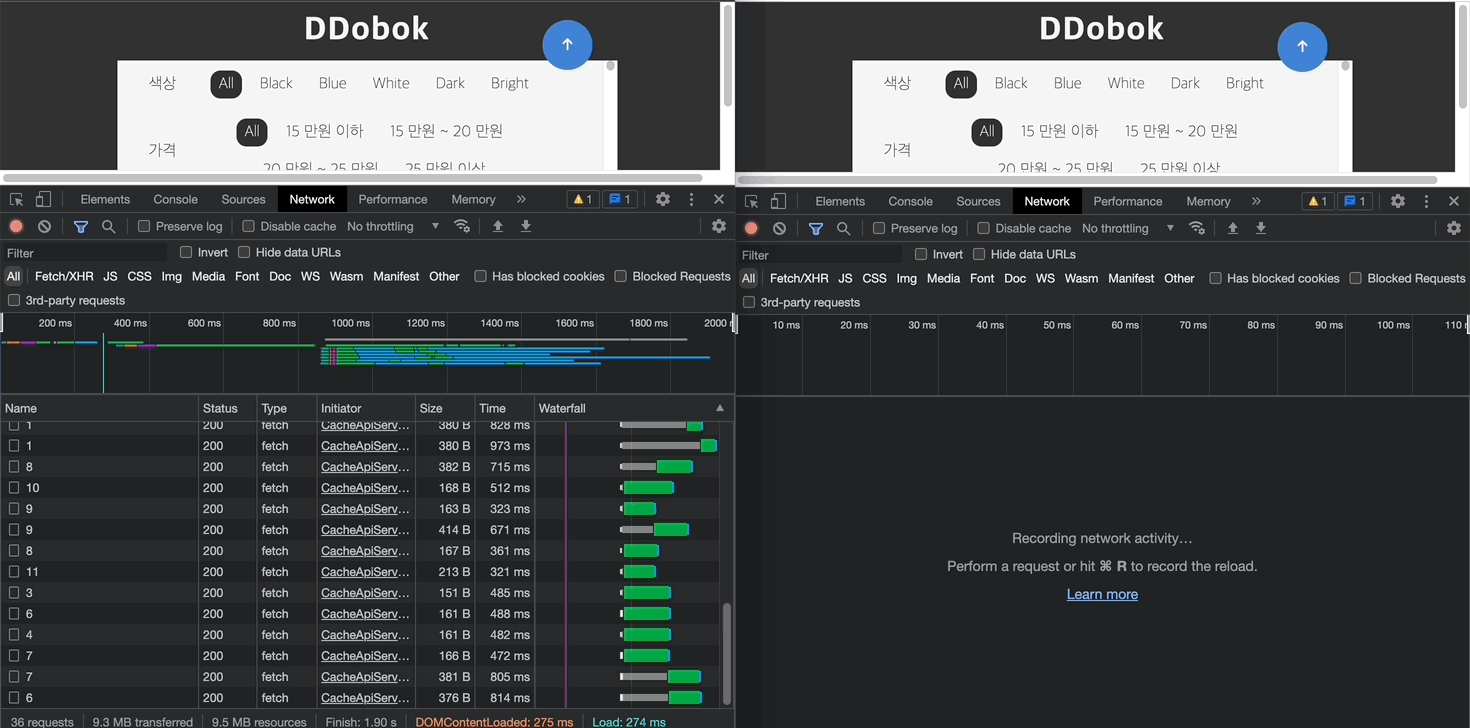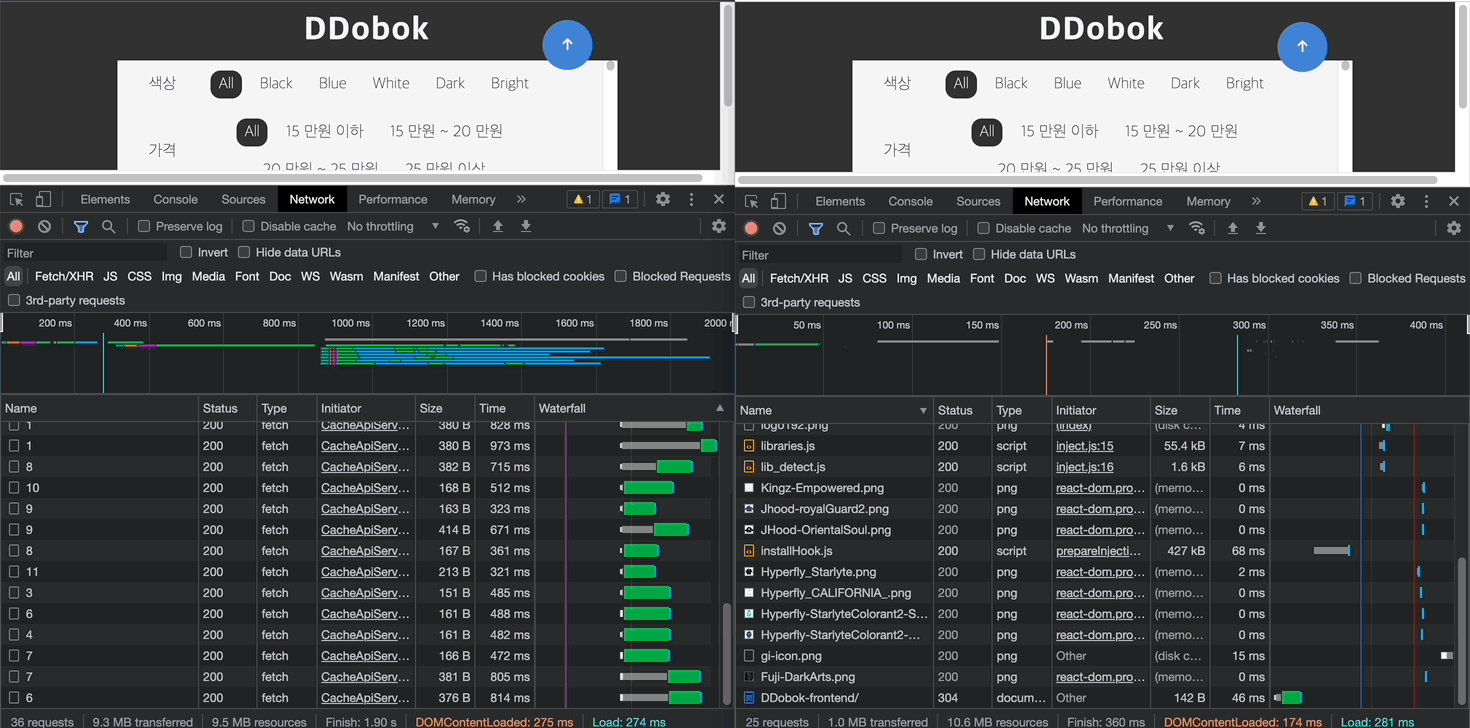
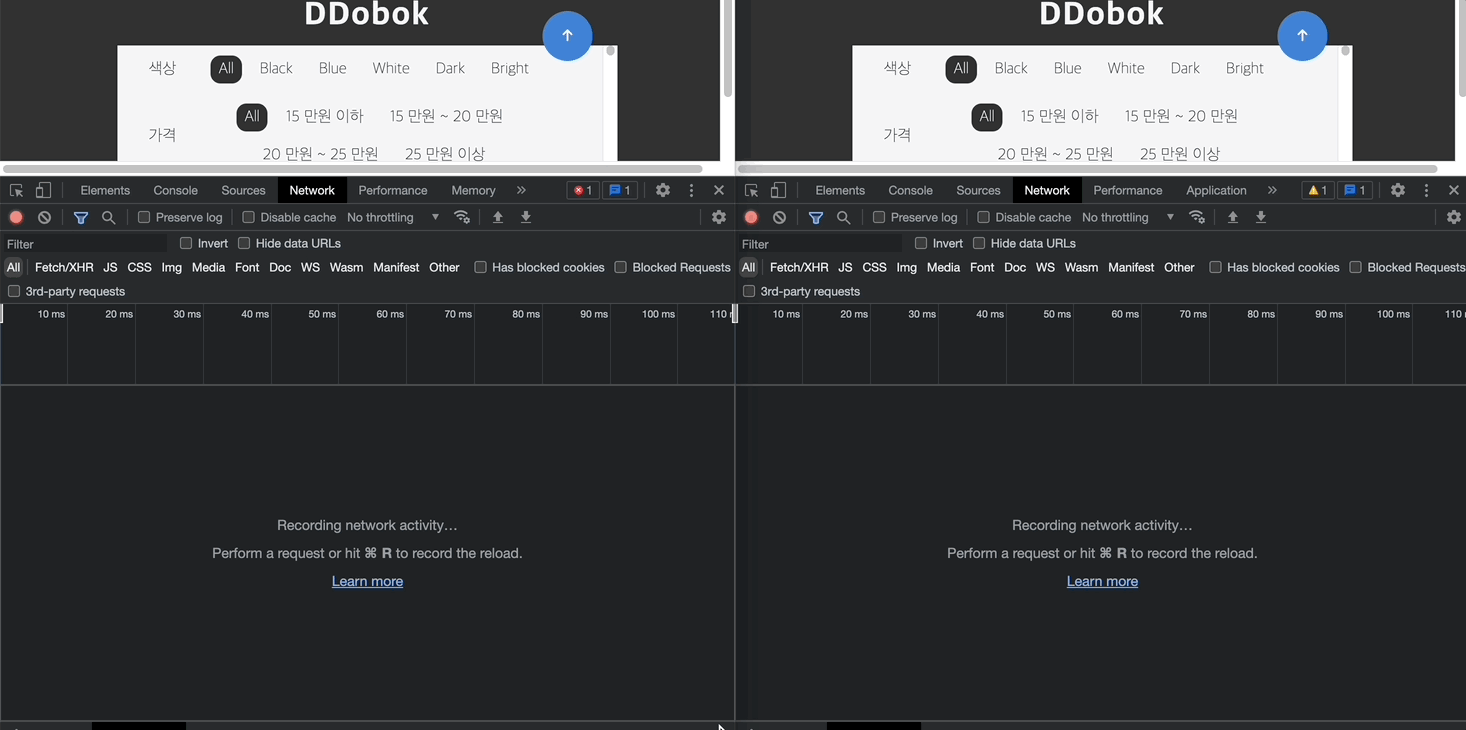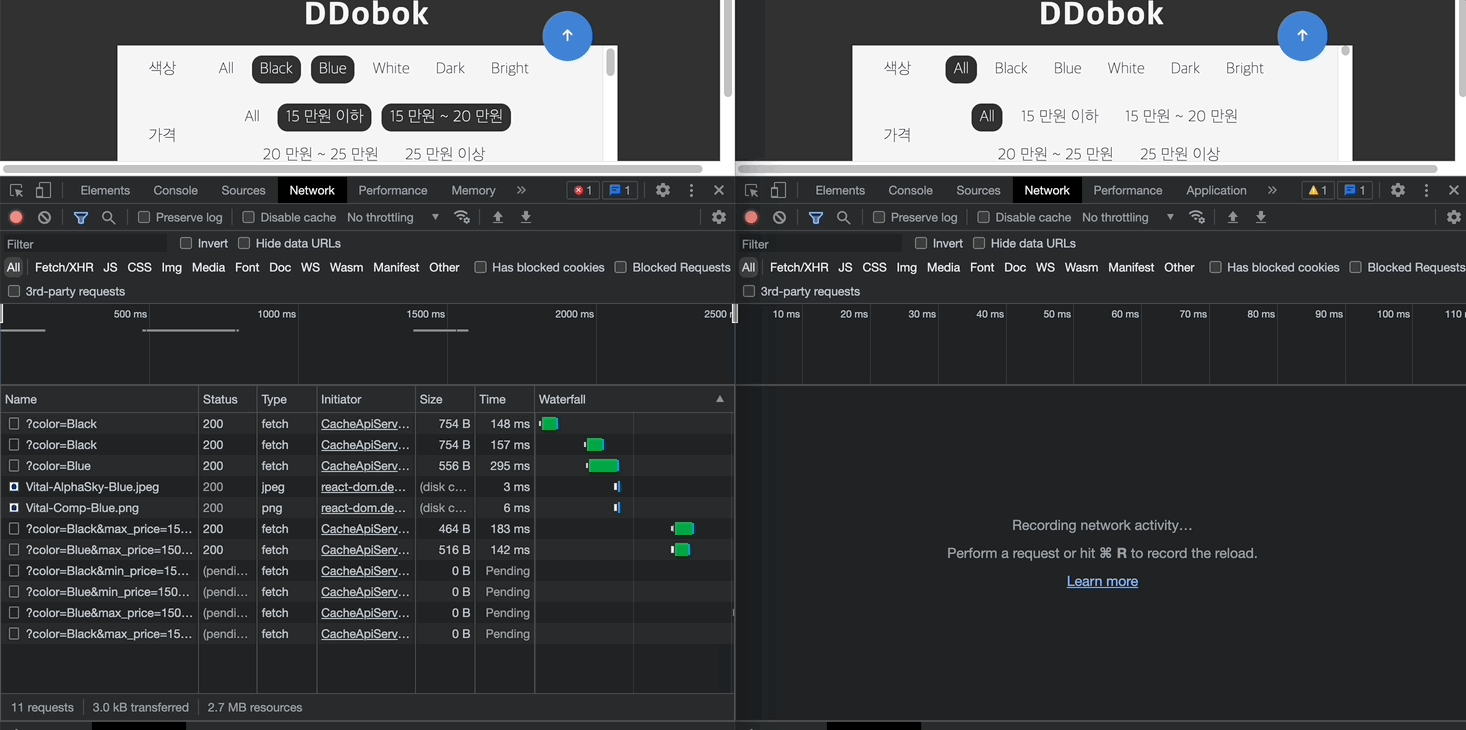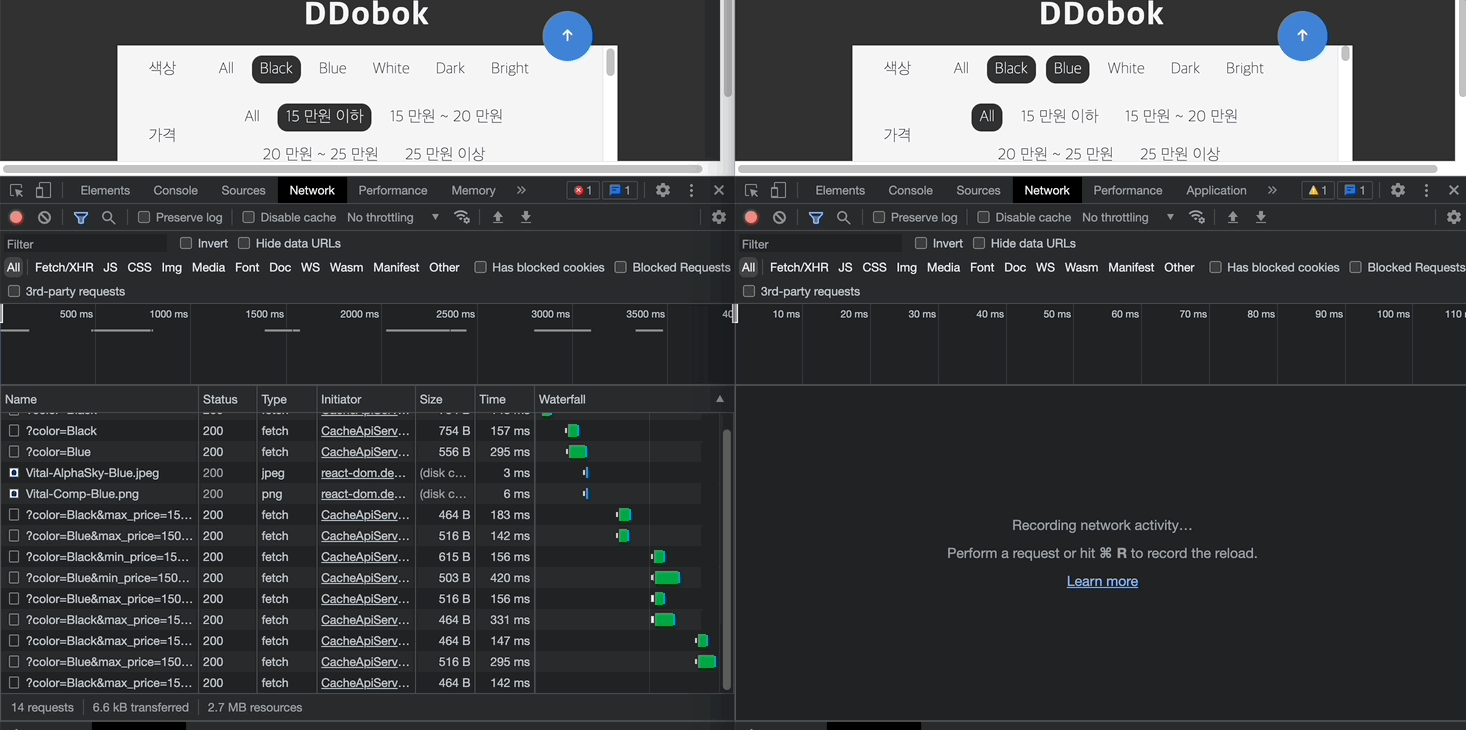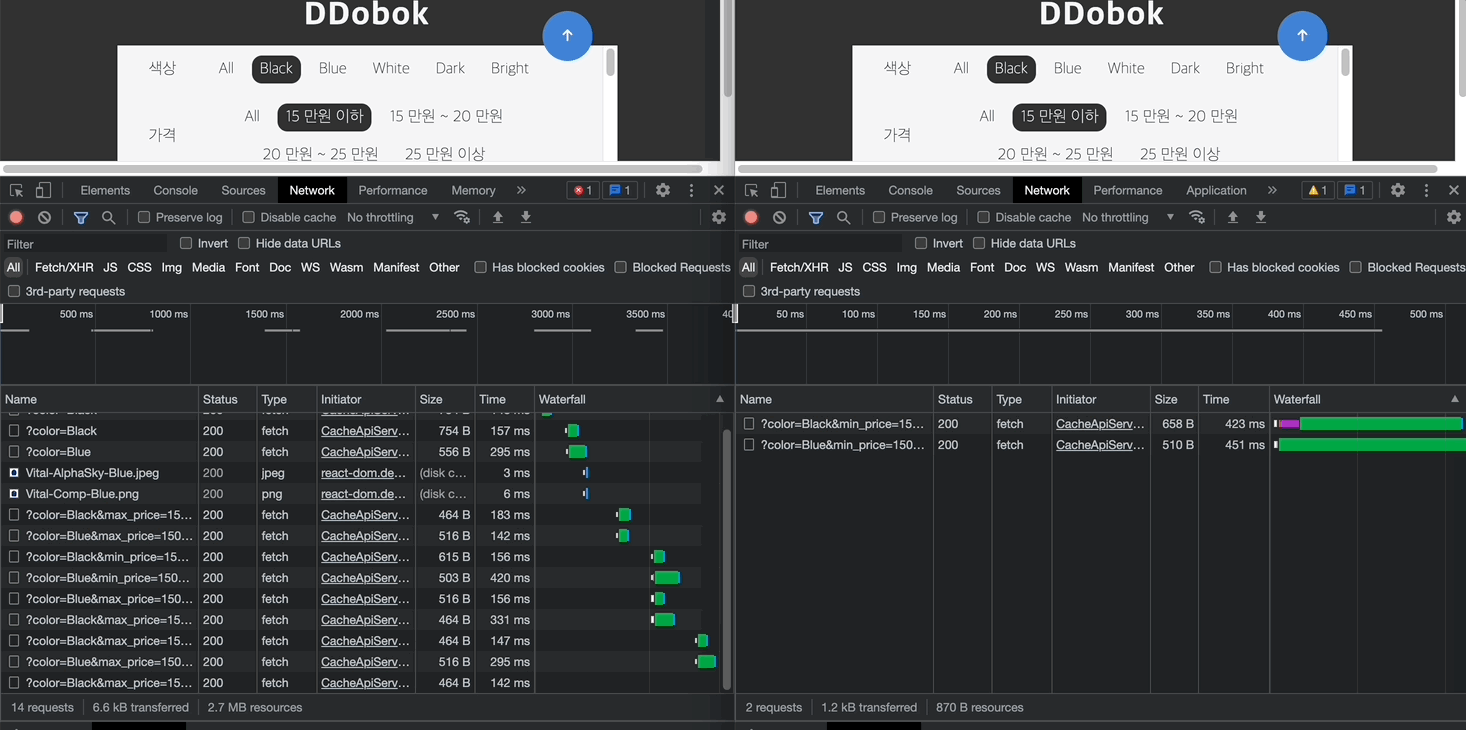
예시 2: 프론트엔드에서 HTTP caching 작업이 필요
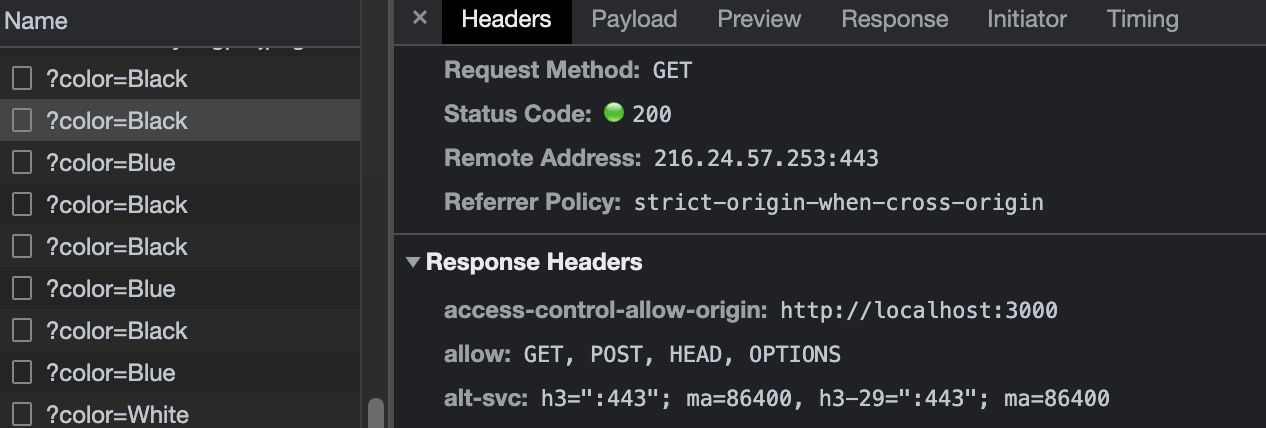
두 번째 예시에서는 응답 헤더에 캐싱과 관련된 정보가 들어있지 않다. 따라서 좌측의 Name에서 확인할 수 있듯이 요청이 중복으로 발생되고 있어 캐싱이 필요하다. 이 경우 <예시 1>처럼 서버 측에 헤더를 추가해달라고 이야기할 수 있으나, 본 프로젝트에서는 프론트엔드에서 자체적으로 캐싱을 구현해보기로 하였다.
1.2 어떤 저장소를 사용할 것인가?
웹 브라우저는 많은 형태의 저장소를 지원한다. 프론트엔드 개발자라면 local storage, session storage가 친근하겠지만 이들은 5 MB 크기의 문자열만 저장 가능하므로 HTTP 캐싱에 사용하기에는 제약이 많다. 필자는 타 팀프로젝트에서 유사한 문제를 해결하기 위해 Map 객체를 활용하여 로컬 캐싱을 구현한 경험이 있다. 그러나 이 예시에서 캐시의 유효 기간은 세션이 종료되기 전까지가 되므로 본 프로젝트의 유효 기간 1 일 조건을 만족할 수 없다.
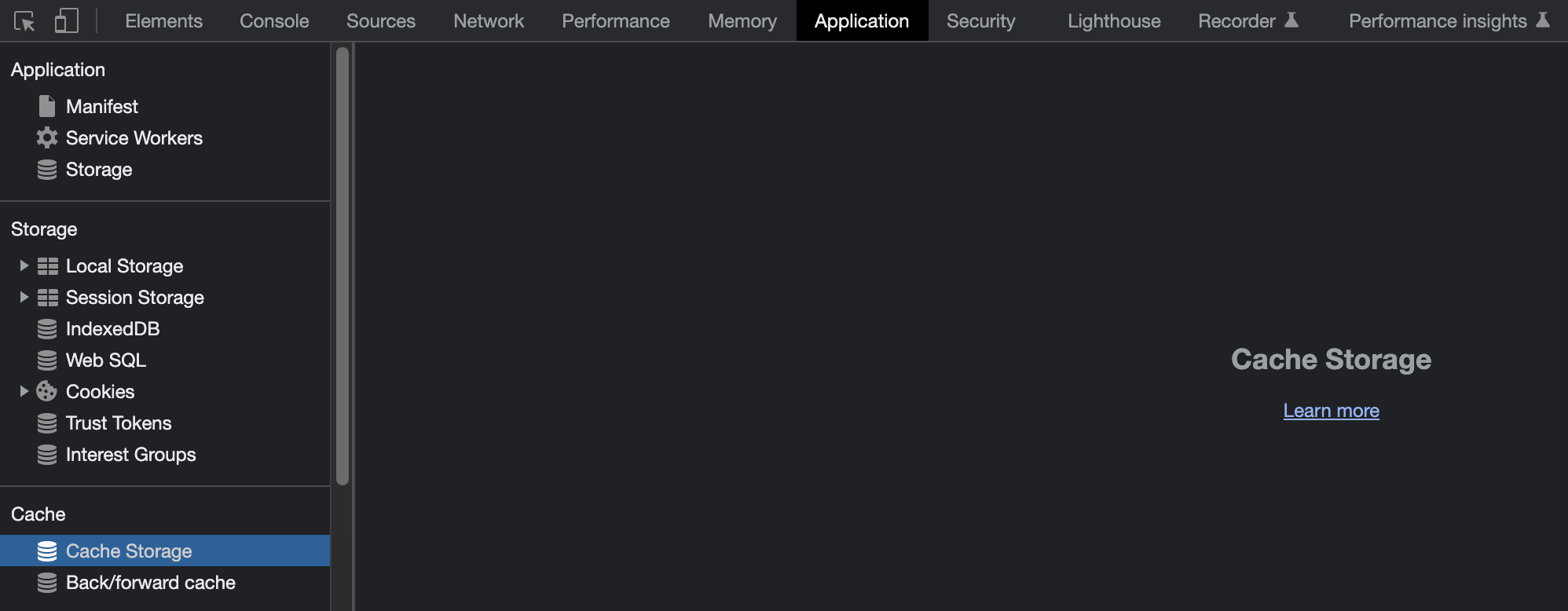
공식 문서에 따르면 네트워크 요청(request url)에 따라 리소스를 캐싱할 경우 Cache Stroage API가 적합하다고 한다.
다음 장부터는 캐시 저장소를 활용하여 서버측 headers의 영향을 받지 않고 리소스를 캐싱하는 과정을 코드와 함께 설명해보려 한다.
2. Cache API를 사용하여 자체적으로 HTTP 캐싱하기
2.0 필터링 요청을 최소화하는 쿼리 고민하기

본 프로젝트에서는 도복 데이터를 색상과 가격으로 필터링하는 로직을 서버에 쿼리를 요청해 구현하고 있다. 모든 필터링 경우의 수(ex. color=Black&color=Blue&color=White&max_price=150000)를 각각의 쿼리로 보낸다면 캐싱의 장점이 저하되므로, 필자는 색상 1 개 이하 * 가격 1 개 이하 조합의 쿼리(ex. color=Black&max_price=150000)를 사용하기로 하였다.
따라서 캐싱을 사용한다면 필터링에 대한 요청은 1 일 최대 30 개(색상 6 가지 * 가격 5 가지)로 제한할 수 있다.
사용자가 필터를 클릭하면 color와 price 두 개의 atom에 해당 정보가 저장되고, 쿼리 생성 로직은 querySelector에서 담당하도록 구현하였다(Recoil 사용). 해당 셀렉터는 서버에 요청할 문자열인 쿼리들을 배열에 담아 반환하게 된다.
export const querySelector = selector({
key: "querySelector",
get: ({ get }) => {
const colorQueries = get(colorQueryState);
const priceQueries = get(priceQueryState);
return combineQueries(colorQueries, priceQueries);
},
});2.1 요청 리소스 캐싱하기
이제 30 개 요청을 Cache API 를 사용하여 캐싱해보자. 필자는 CacheApiServer 클래스 내에 정적 메소드인 getGisByQuery를 구현하였다. caches.match() 메소드를 사용하여 해당 쿼리에 대한 캐시를 찾아 캐시가 존재하면 리턴하고 없으면 서버로부터 데이터를 요청받아 사용하는 간단한 로직이다.
export class CacheApiServer {
private static giCacheStorage = CACHE_STORAGE.GIS;
static async getGisByQuery(query: string) {
const url = `${BASE_URL}/gis/${query}`; // 쿼리 url 생성
const cache = await caches.open(this.giCacheStorage); // 캐시 저장소 열기
return await this.getValidResponse(cache, url);
}
private static async getValidResponse(cache: Cache, url: string) {
const cacheResponse = await caches.match(url); // 요청 쿼리와 일치하는 캐시 응답 가져오기
return cacheResponse
? await cacheResponse.json() // 응답이 존재하면 반환
: await this.getFetchResponse(cache, url); // 존재하지 않으면 서버에 요청
}
private static async getFetchResponse(cache: Cache, url: string) {
const fetchResponse = await fetch(url);
cache.put(url, fetchResponse.clone()); // 캐시 저장
return fetchResponse.json();
}
}
}크롬의 개발자 도구에서 캐시 저장소에 쿼리에 따라 응답이 저장되어 있는 모습을 확인할 수 있다.
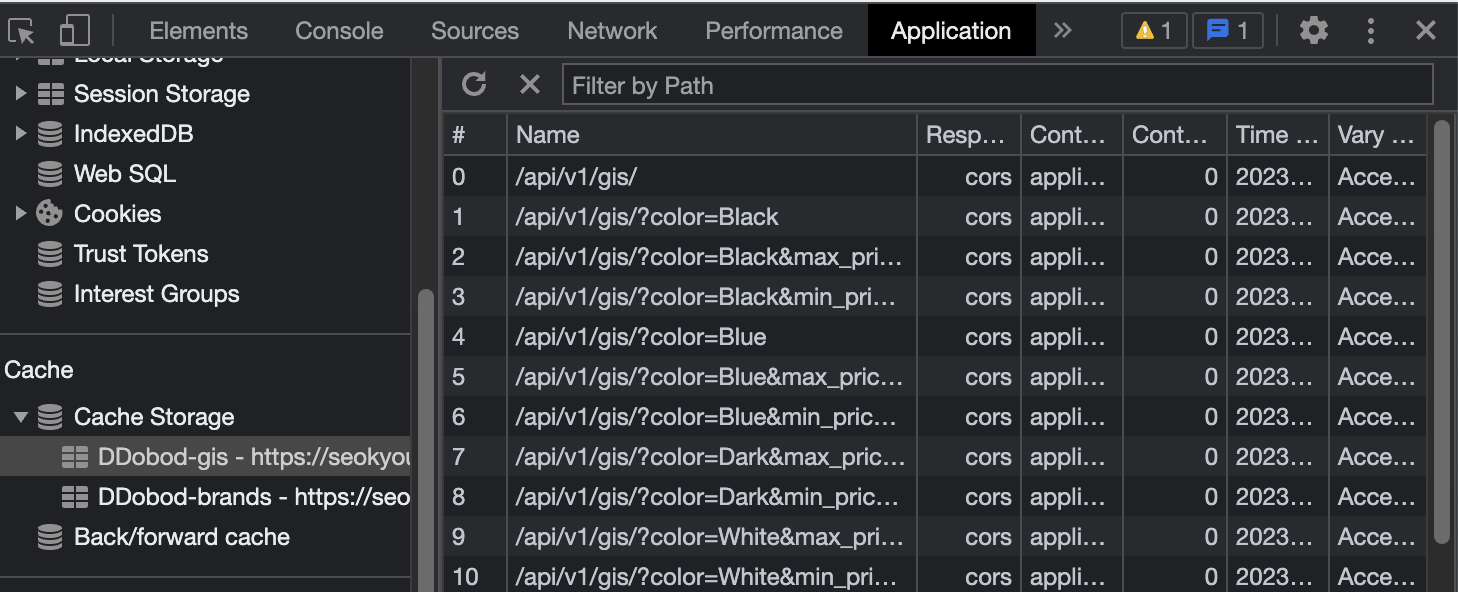
2.2 유효 기간 지정하기
그 다음으로 저장한 캐시의 유효 기간을 지정해보자. 캐시 저장소와 함께 활용할 수 있든 Service Worker API를 사용하면 ExpirationPlugin을 활용하여 캐시의 생명 주기를 지정할 수 있다고 한다. 그러나 본 프로젝트는 규모가 크지 않으므로 플러그인을 사용하지 않고 fetchResponse에 응답 시간 정보를 담은 fetch-date 헤더를 직접 추가하여 캐시를 저장하는 방법을 사용하였다.
const HEADER_FETCH_DATE = "fetch-date";
private static async getResponseWithFetchDate(fetchResponse: Response) {
const cloneResponse = fetchResponse.clone();
const newBody = await cloneResponse.blob();
let newHeaders = new Headers(cloneResponse.headers);
newHeaders.append(HEADER_FETCH_DATE, new Date().toISOString());
return new Response(newBody, {
status: cloneResponse.status,
statusText: cloneResponse.statusText,
headers: newHeaders,
});
}
캐싱된 데이터의 만료 여부를 판단하는 isCacheExpired 로직은 아래와 같다.
const ONE_DAY_MILISECOND = 60 * 60 * 24 * 1000;
private static isCacheExpired(cacheResponse: Response) {
const fetchDate = new Date(
cacheResponse.headers.get(HEADER_FETCH_DATE)!
).getTime();
const today = new Date().getTime();
return today - fetchDate > ONE_DAY_MILISECOND;
}
2.3 캐싱 서비스 사용하기
최종적으로 응답된 도복 정보를 받는 GiItems 컴포넌트는 아래와 같이 구현되어 있다. 사용자가 선택한 필터값이 바뀔 때마다 querySelector는 서버에 요청할 문자열인 쿼리들을 배열에 담아 반환하고, useEffect의 의존성에 의해 loadData가 실행된다. 이 때 CacheApiServer.getGisByQuery 메소드를 사용하여queries 배열의 각각의 응답을 순차적으로 가져오게 되며, 모든 응답을 기다리기 위해 해당 로직을 Promise로 감싸는 비동기처리를 진행했다. loadData 내의 로직이 마무리되면 마지막으로 gis 상태가 업데이트된다.
const queries = useRecoilValue(querySelector); // 사용자가 필터에서 선택한 쿼리
const [gis, setGis] = useState<Gis>([] as Gis);
const loadData = useCallback(async () => {
let results: Gis = [];
const promises = queries.map(async (query) => {
const result = await CacheApiServer.getGisByQuery(query); // query에 대한 응답 가져오기(cach / api)
results.push(...result);
});
await Promise.all(promises);
setGis(results);
}, [queries]);
useEffect(() => {
loadData();
}, [queries, loadData]); //쿼리가 바뀔 때마다 새로운 도복 데이터 로딩
3. 결과물 및 마무리
최종 데모는 아래와 같다. 좌측의 페이지로 처음 진입한 경우 서버로 각각의 요청을 발생시키지만, 우측의 경우 사용자가 필터링을 변경하여도 서버로 요청을 보내지 않고 브라우저의 Cache Storage에서 해당 응답을 가져오게 된다.
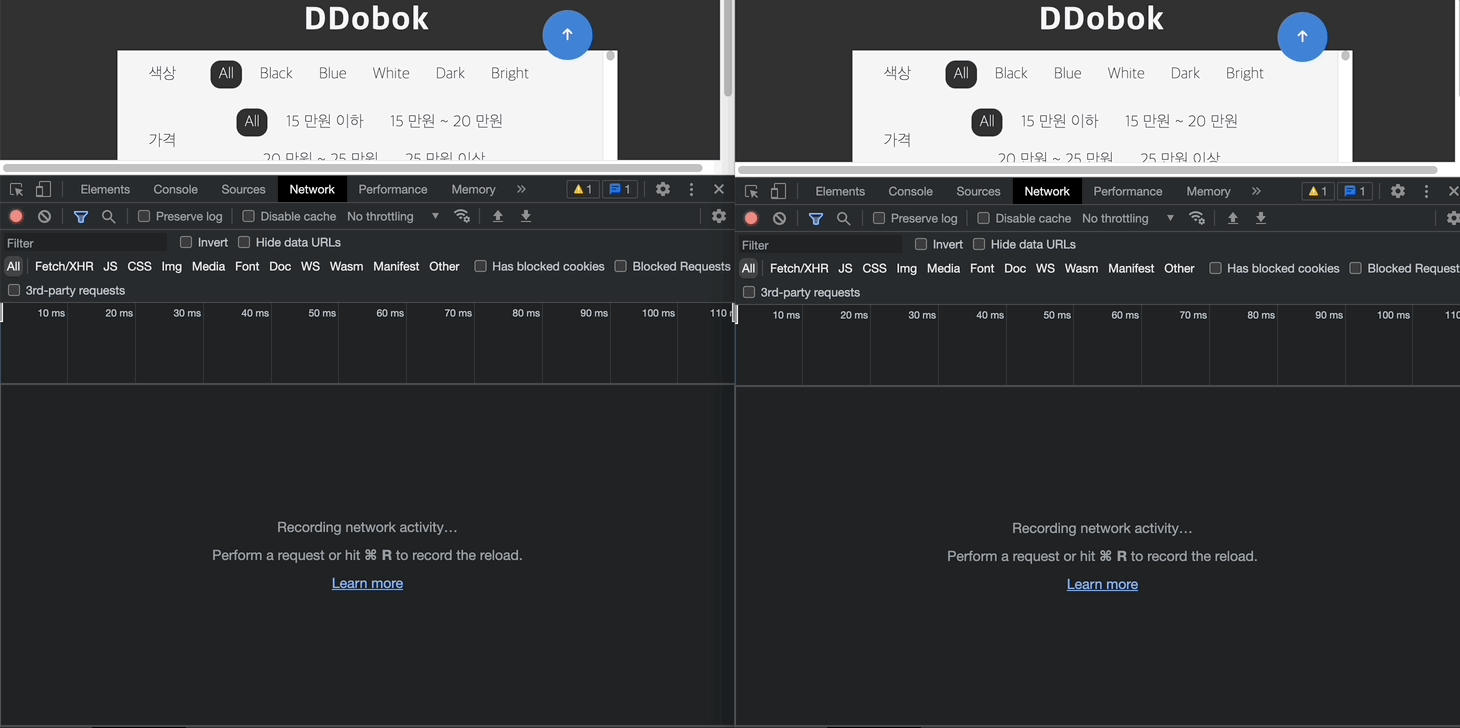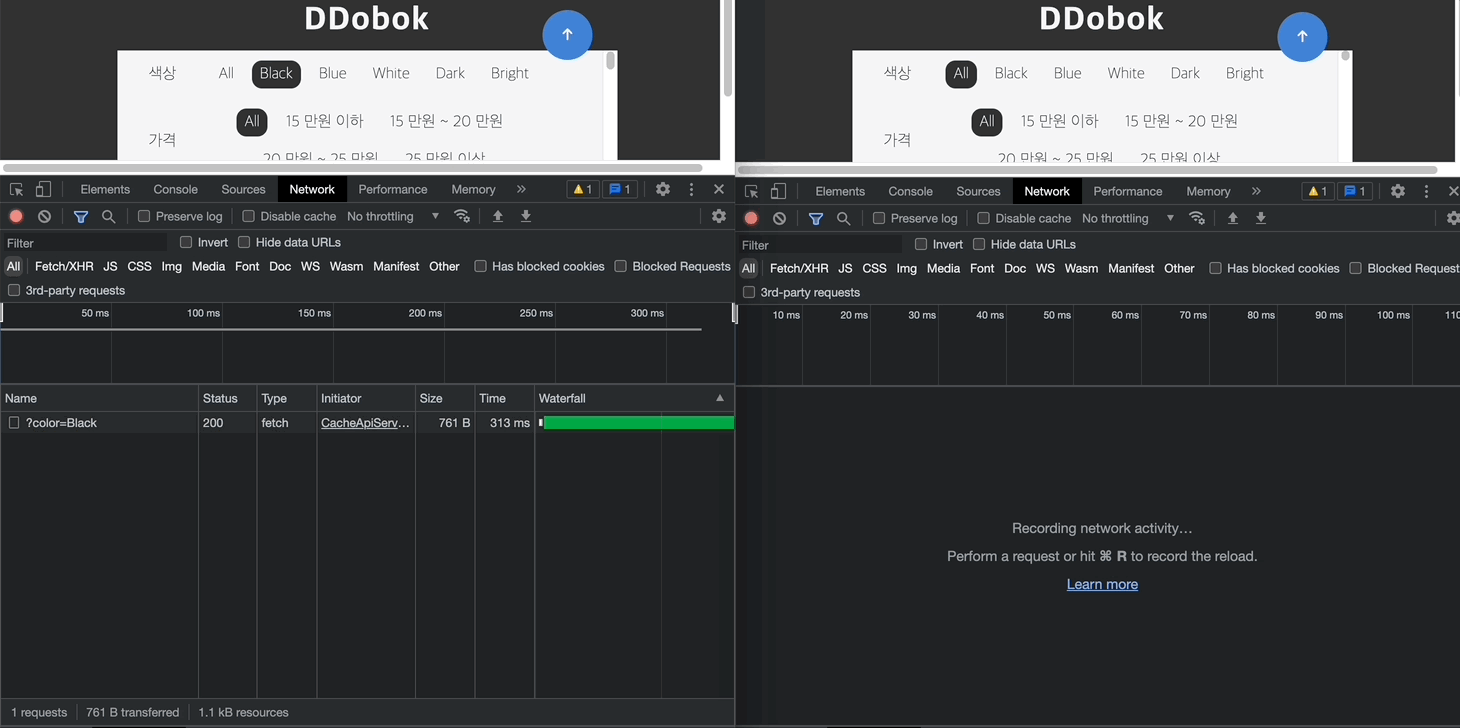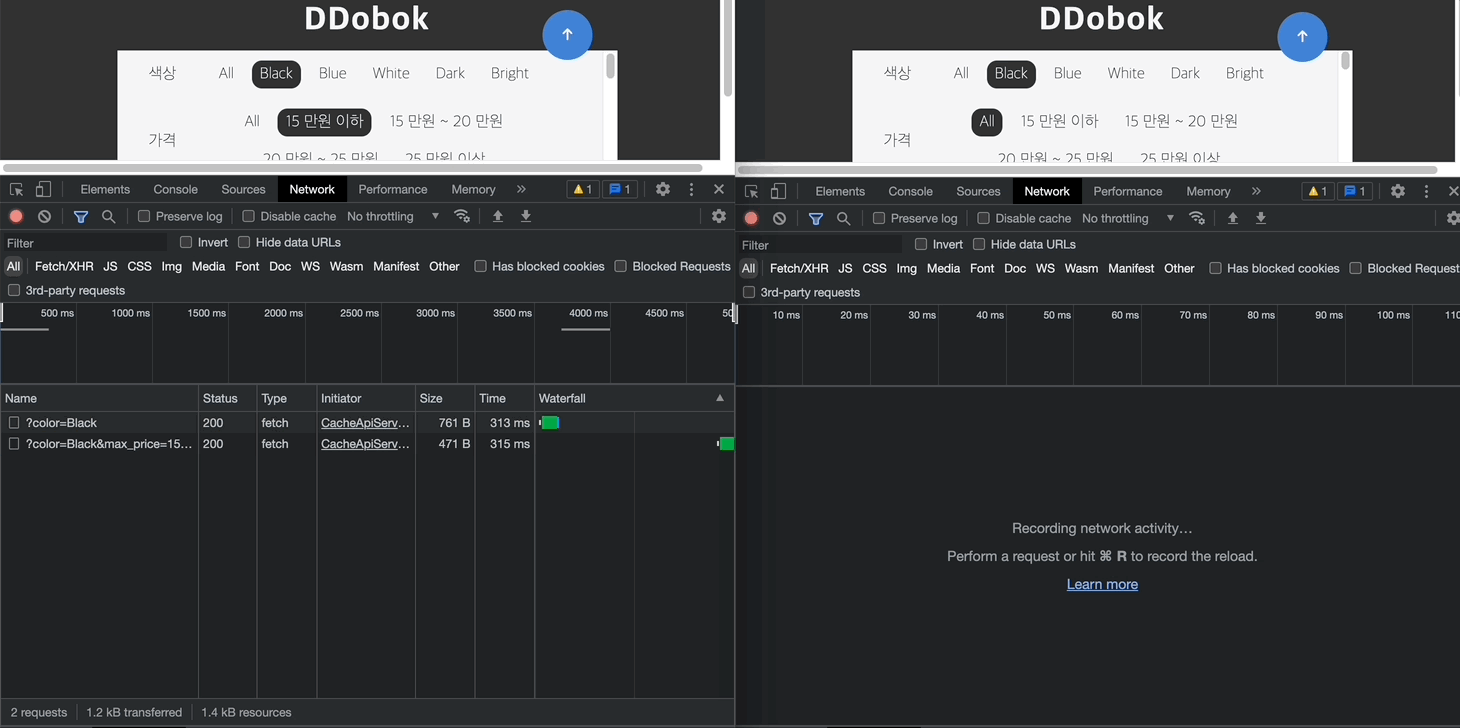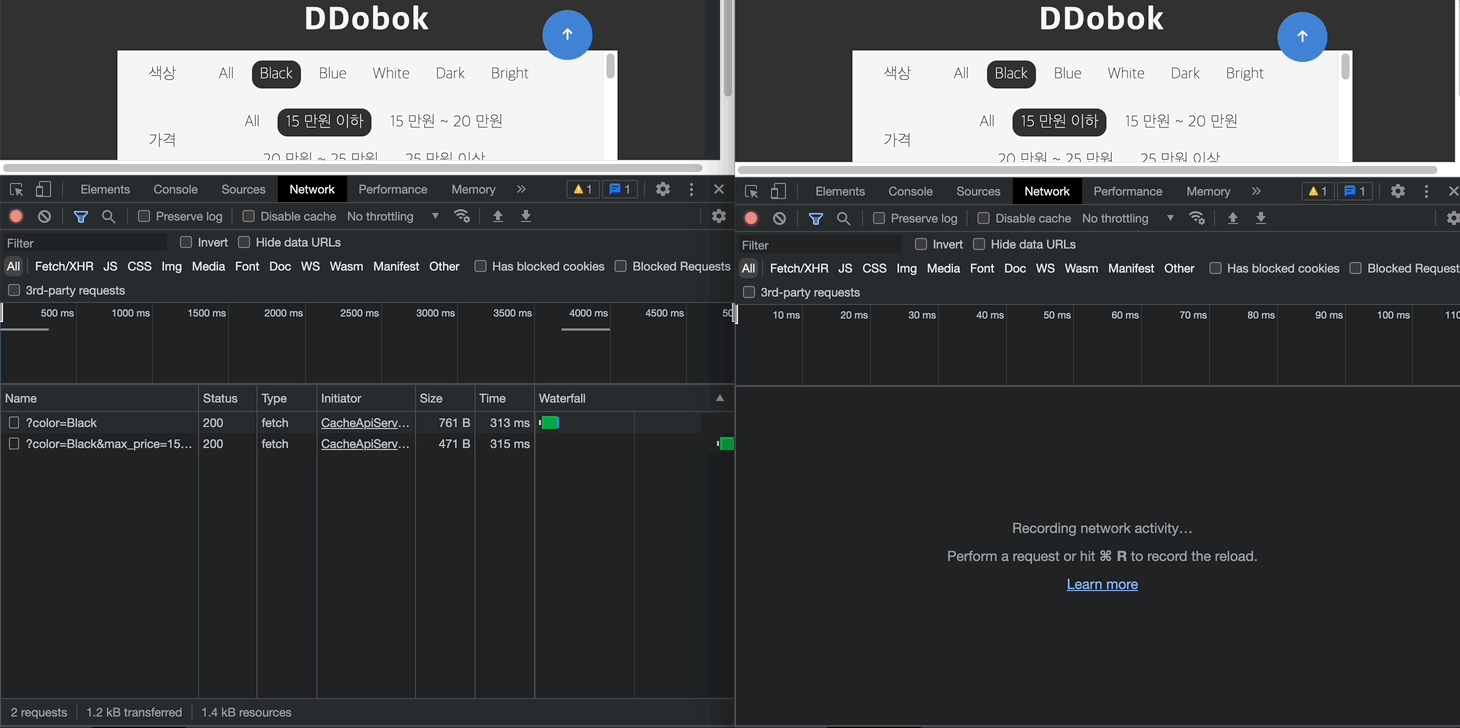
캐싱이라는 개념이 단순히 서버 요청을 줄이기 위한 기술이라고 생각하였는데, 리소스를 클라이언트단에 더 가깝게 두어 웹 성능을 높일 수 있다는 점을 새롭게 배울 수 있었다. 실무에서는 Cache-Control 헤더를 사용하는 경우가 많겠지만, 서버 단의 코드를 변경할 수 없다는 특수한 상황을 상정하고 나니 브라우저 (저장소)에 대해 더 깊은 이해를 해볼 수 있어 뜻깊었다. 잘 구축되어있는 라이브러리와 패키지를 활용하는 것도 좋지만 기초 뼈대 직접 만들어보는 것도 좋은 경험이었다고 생각한다.
전체 코드는 깃허브 저장소에서 확인하실 수 있습니다.
참고 자료
