dag
task로 구성되어 ETL 역할을 수행
parameter
dag 예시
dag = DAG(
dag_id = 'MySQL_to_Redshift_v2',
start_date = datetime(2023,4,20), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 9 * * *', # 적당히 조절
max_active_runs = 1,
catchup = True,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
dag_id: dag의 id Airflow Web UI에서 dag_id를 통해 확인 가능.
start date: 데이터를 처음으로 불러와야 할 날짜.
schedule: 실행 주기, 크론탭 문법 사용
max_active_runs: 한번에 실행 가능한 최대 dags의 수
catchup: True이면 현재를 기준으로 과거에 실행되어야 했을 모든 dag를 실행, False이면 현재를 기준으로 1번만 실행
default_args: fail이 발생하는 경우 재시도에 대한 설정
크론탭문법
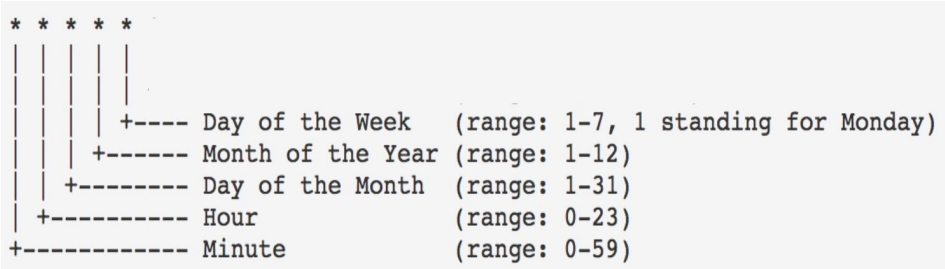
// examples
* * * * * // 매 분마다 실행
0 5 * * 5 // 매주 금요일 오전 5시에 실행dag 사용법
'>>'를 사용하여 task 순서를 지정
task1 >> task2: task1을 수행한 후 task2 수행
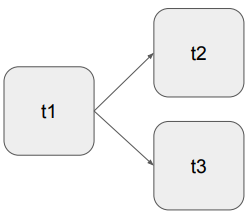
위의 경우
t1 << t2
t1 << t3로 dag를 만들 수 있다. 위와 같은 경우 t1 -> t2, t3로 동시에 영향을 주므로
t1 << [t2, t3]와 같이 간단하게 줄일 수 있다.
마찬가지로 아래의 경우
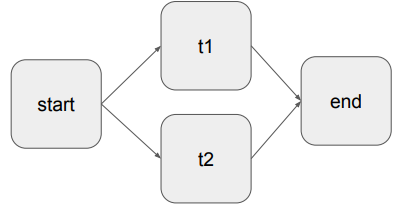
start << [t1, t2] << end로 표현이 가능하다.
task
task는 Dag 파일이 존재하는 순간 실행함 실행 목적이 없는 파일에 dag 단어가 있다면 주석처리
task functions
PythonOperator
// example
def etl():
...
etl = PythonOperator(
task_id = 'etl',
python_callable = etl,
# 서울의 위도/경도
params = {
"lat": 37.5665,
"lon": 126.9780,
"schema": "kusdk",
"table": "weather_forecast"
},
dag = dag
)파이썬 파일을 실행하는 task 함수이다.
task_id: Airflow web UI에서 확인 가능하다. 각 task 별로 진행 상태를 확인할 수 있고 클릭하고 log를 확인해 어느 부분에서 오류가 발생했는지 확인할 수 있다.
python_callable = etl을 통해 etl 함수를 실행하고 dag를 지정한다.
SqlToS3Operator
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = "SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution_date }}')",
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False},
dag = dag
)sql의 db table을 aws S3에 저장하는 함수이다.
query: sql에서 실행한 결과를 S3에 복사
s3_bucket: 데이터가 저장될 장소
s3_key: 이름. 스키마의 table 명과 비슷한 개념
sql_conn_id, aws_conn_id: sql, aws(s3) connection. Connection 파트 참조.
verify: S3에 대한 SSL 증명 확인
replace: S3 내부에 파일이 있다면 대체할 지에 대한 설정. sql의 if exist와 비슷한 맥락
pd_kwargs: dataframe에 대한 설정값
현재 mysql prod schema에 있는 nps table에서 특정 데이터를 불러오고 필터링한 결과를 S3에 저장한다.
S3ToRedshiftOperator
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
method = "UPSERT",
upsert_keys = ["id", "created_at"],
dag = dag
)copy_options: redshift내에 저장될 type
method: 실행할 sql 언어. APPEND, UPSERT, REPLACE 3가지가 존재한다.
upsert_keys: upsert 동작을 실행하는 attribute 설정
S3에서 저장된 파일을 기준으로 redshift의 schema table의 "id", "created_at" 속성을 업데이트함.
TriggerDagOperator
dag = DAG(
dag_id = 'TriggerDagRunOperator',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 4 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
trigger_B = TriggerDagRunOperator(
task_id="trigger_dag_run_test",
trigger_dag_id="Gsheet_to_Redshift",
# DAG B에 넘기고 싶은 정보. DAG B에서는 Jinja 템플릿(dag_run.conf["path"])으로 접근 가능.
# DAG B PythonOperator(**context)에서라면 kwargs['dag_run'].conf.get('conf')
conf={ 'path': '/opt/ml/conf' },
# Jinja 템플릿을 통해 DAG A의 execution_date을 패스
execution_date="{{ ds }}",
reset_dag_run=True, # True일 경우 해당 날짜가 이미 실행되었더라는 다시 재실행
wait_for_completion=True, # DAG B가 끝날 때까지 기다릴지 여부를 결정. 디폴트값은 False
dag = dag
)task_id: dag내의 task의 id
trigger_dag_id: trigger시킬 dag id. 'TriggerDagRunOperator'를 실행하면 'Gsheet_to_Redshift' dag를 동작시킨 후 'TriggerDagRunOperator'가 실행된다.
ExternalTaskSensor
dag = DAG(
dag_id = 'ExternalTaskSensor',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 4 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
waiting_for_end_of_dag_a = ExternalTaskSensor(
task_id='waiting_for_end_of_dag_a',
external_dag_id='Gsheet_to_Redshift',
external_task_id='run_copy_sql_spreadsheet_copy_testing',
timeout=5*60,
# execution_date_fn=lambda x: x - timedelta(hours=5),
mode='reschedule',
dag = dag
)
task_id: dag내의 task의 id
external_dag_id: 실행에 참조하는 Dag id.
external_task_id: 실행에 참조하는 Dag의 task id. 위 경우 'Gsheet_to_Redshift'의 'run_copy_sql_spreadsheet_copy_testing'가 실행된 이후 ExternalTaskSensor가 동작한다. TriggerDagOperator와 다르게 참조하는 dag와 execution date이 동일해야 한다. 즉 내가 임의로 2개의 dag를 실행한다고 동작하지 않으며 schedule을 맞추어야 한다.
mode='reschedule': external_task_id가 실행할 때까지 대기한다.
timeout: 대기 시간
execution_date_fn: execution date에 차이가 발생하는 경우 timedelta를 사용하여 조정 가능.
BranchPythonOperator
def skip_or_cont_trigger():
if Variable.get("mode", "dev") == "dev":
return ["print_hello"]
else:
return ["print_goodbye"]
# "mode"라는 Variable의 값이 "dev"이면 trigger_b 태스크를 스킵
branching = BranchPythonOperator(
task_id='branching',
python_callable=skip_or_cont_trigger,
dag = dag
)
dag = DAG(
dag_id = 'BranchPythonOperator',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 4 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
// print_hello, print_goodbye는 hello, goodbye를 출력하는 task임
branching >> [print_hello, print_goodbye]if 조건문을 사용하여 task_id를 리턴하게 만들어 각 상황에 맞는 task를 골라 수행 가능.
Airflow Connection
variables
Airflow web UI의 Admin -> Variables에서 설정 가능. Key, Value 형태로 저장한다.
dag 코드에서 Variable을 얻어 사용이 가능하다.
'url': Variable.get("csv_url")위 코드는 Variables에 저장된 csv_url을 불러옴.
Redshift Connection
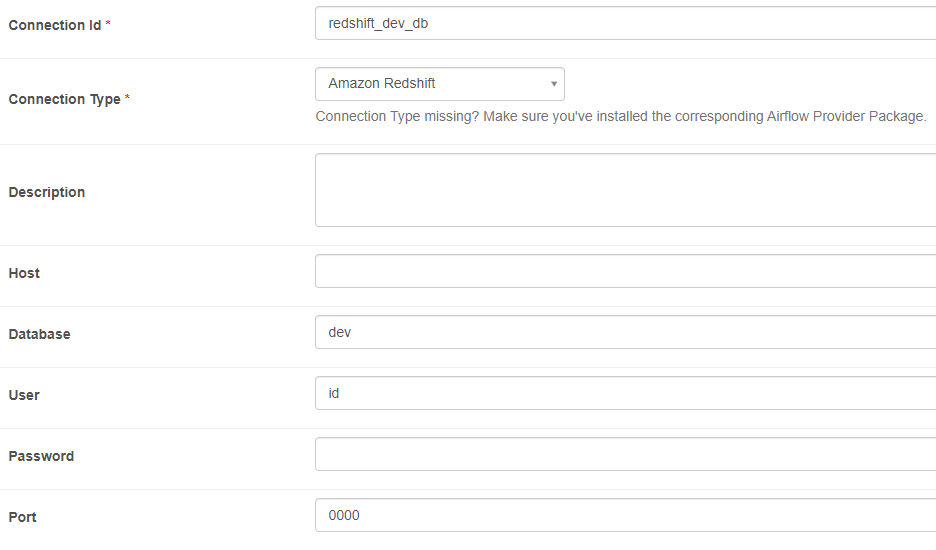
connection Id는 dag의 redshift_conn_id의 parameter로 사용
사용하는 parameter: Host, Database, User, Password, Port
MySQL Connection
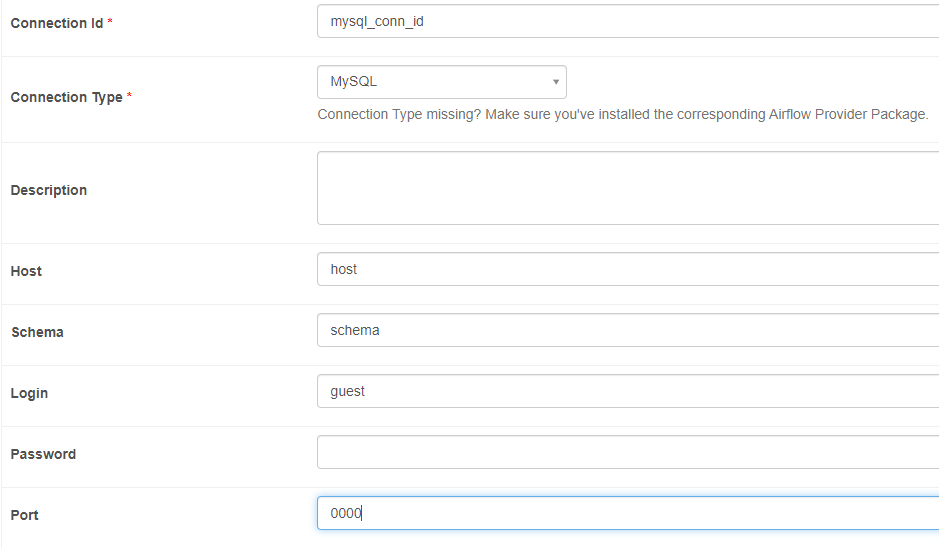
connection Id는 dag의 sql_conn_id parameter로 사용
사용하는 parameter: Host, Schema, Login, Password, Port
S3 Connection
Connection Id에서 S3는 사라짐. 대신 Amazon Web Services 사용
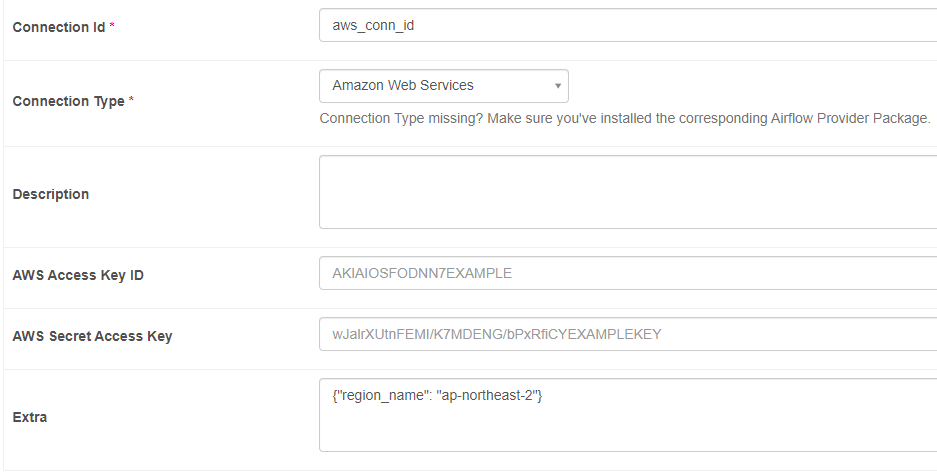
connection Id는 dag의 aws_conn_id parameter로 사용
사용하는 parameter: Extra
AWS Access Key ID, AWS Secret Access Key의 경우 S3에서 해당 사용자에 대한 접근을 이미 허가한 상태라면 Airflow 내에서 추가할 필요는 없지만, 그렇지 않은 경우 사용자가 key를 사용해야 함.
