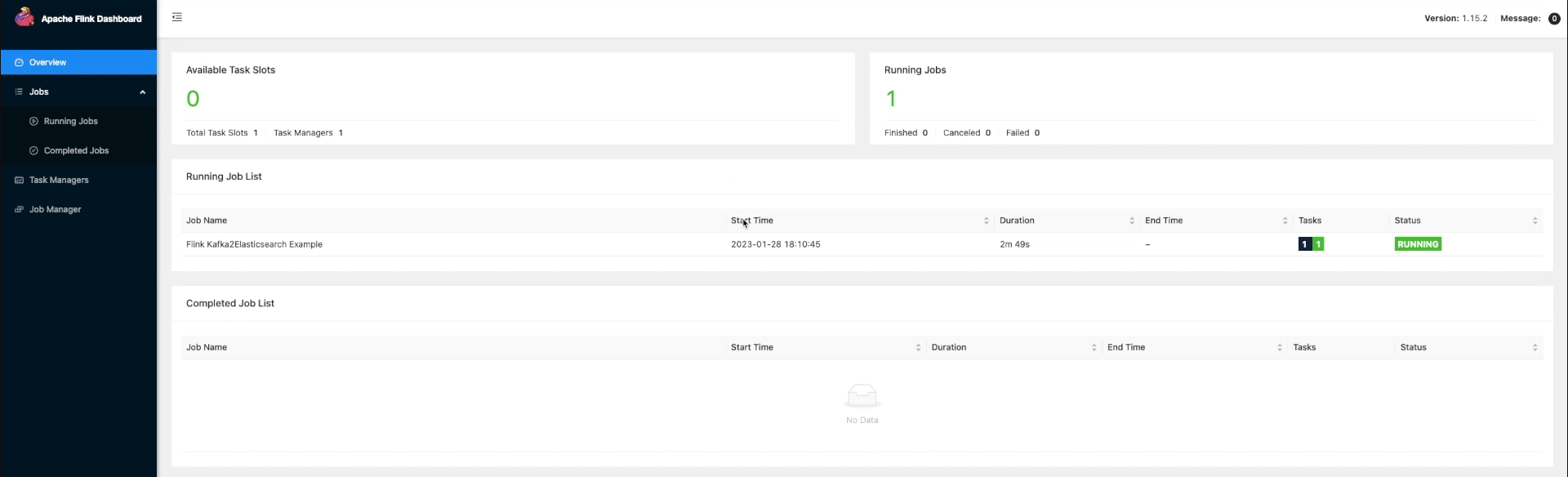
이전 실습에 이어서 진행
파라미터 변환
ParameterStore
Scala Class -> Object
build.sbt 에 awsSdkVersion 의존성 추가
package org.example
import com.amazonaws.regions.Regions
import com.amazonaws.services.simplesystemsmanagement.AWSSimpleSystemsManagementClientBuilder
import com.amazonaws.services.simplesystemsmanagement.model.GetParameterRequest
object ParameterStore {
val ssm = AWSSimpleSystemsManagementClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build()
def getParameter(name: String, withDecryption: Boolean = false): String = { // 암호화되지 않은 경우가 많아 false를 주로 사용
val req = (new GetParameterRequest).withName(name).withWithDecryption(withDecryption)
val result = ssm.getParameter(req)
result.getParameter.getValue
}
}AWS System Managers에 저장한 데이터를 리턴함
ElasticSearchSink
package org.example
import org.apache.flink.api.connector.sink2.SinkWriter
import org.apache.flink.connector.elasticsearch.sink.{Elasticsearch7SinkBuilder, RequestIndexer}
import org.apache.http.HttpHost
import org.elasticsearch.client.Requests
import java.net.URI
import java.time.ZonedDateTime
import scala.collection.JavaConverters.mapAsJavaMap
object ElasticSearchSink {
val esUrl = ParameterStore.getParameter("/skybluelee/es/url") // hostname, port, scheme으로 나누어야 함
val esUsername = ParameterStore.getParameter("/skybluelee/es/username")
val esPassword = ParameterStore.getParameter("/skybluelee/es/password", withDecryption = true)
val esUri = new URI(esUrl)
val esHost = new HttpHost(esUri.getHost, if(esUri.getScheme=="https") 443 else 80, esUri.getScheme)
def getSink = { // 정상적으로 파싱된 데이터
new Elasticsearch7SinkBuilder[MSG]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(esHost)
.setEmitter { (element: MSG, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"data" -> element.num.asInstanceOf[AnyRef],
"event_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-index")
.id(element.num.toString)
.create(true)
.source(mapAsJavaMap(map)))
}.setConnectionUsername(esUsername)
.setConnectionPassword(esPassword)
.build()
}
def getErrorSink = { // 오류가 발생한 데이터
new Elasticsearch7SinkBuilder[String]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(esHost)
.setEmitter { (element: String, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"error" -> element.asInstanceOf[AnyRef],
"error_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-error").source(mapAsJavaMap(map)))
}.setConnectionUsername(esUsername)
.setConnectionPassword(esPassword)
.build()
}
}실행시 정상적으로 작동
KDA(Kinesis Data Analytics) 사용
Kafka2ElasticSearch
package org.example
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Kafka2ElasticSearch {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment // 스트리밍 변수 생성
val kafkaSource = KafkaSource.builder()
.setBootstrapServers(<MSK 프라이빗 엔드포인트>) // bootstrap server 설정
.setTopics("flink-test") // topic 설정
.setGroupId("flink") // group id 설정
.setStartingOffsets(OffsetsInitializer.latest()) // 데이터를 어떤 순서대로 받는지 결정
.setValueOnlyDeserializer(new SimpleStringSchema()) // streaming 데이터를 어떻게 받을지 설정
.build() // 위의 경우 string으로 받음
val inputStream: DataStream[String] = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
inputStream.print()
val parser = new MessageParser // MSG에서 정의
val processStream = inputStream // 데이터 가공
.process(parser) // parser에서 ProcessFunction을 상속
val errorStream = processStream
.getSideOutput(parser.outputTag)
errorStream.print() // parsing이 실패한 데이터는 print
errorStream.sinkTo(ElasticSearchSink.getErrorSink)
processStream.sinkTo(ElasticSearchSink.getSink)
env.execute("Flink Kafka2ElasticSearch Example")
}
}기존에는 로컬에서 연결하여 사용하였기 때문에 MSK 프라이빗 엔드포인트로 변경
build.sbt
ThisBuild / resolvers ++= Seq(
"Apache Development Snapshot Repository" at "https://repository.apache.org/content/repositories/snapshots/",
Resolver.mavenLocal
)
name := "flink-project"
version := "0.1-SNAPSHOT"
organization := "org.example"
ThisBuild / scalaVersion := "2.12.7"
val flinkVersion = "1.15.2"
val json4sVersion = "4.0.6"
val awsSdkVersion = "1.12.300"
val flinkDependencies = Seq(
"org.apache.flink" %% "flink-scala" % flinkVersion,
"org.apache.flink" %% "flink-streaming-scala" % flinkVersion,
"org.apache.flink" % "flink-clients" % flinkVersion,
"org.apache.flink" % "flink-connector-kafka" % flinkVersion,
"org.apache.flink" % "flink-connector-elasticsearch7" % flinkVersion,
"org.json4s" %% "json4s-jackson" % json4sVersion,
"com.amazonaws" % "aws-java-sdk-ssm" % awsSdkVersion
)
lazy val root = (project in file(".")).
settings(
libraryDependencies ++= flinkDependencies
)
assembly / mainClass := Some("org.example.Kafka2ElasticSearch")
// make run command include the provided dependencies
Compile / run := Defaults.runTask(Compile / fullClasspath,
Compile / run / mainClass,
Compile / run / runner
).evaluated
// stays inside the sbt console when we press "ctrl-c" while a Flink programme executes with "run" or "runMain"
Compile / run / fork := true
Global / cancelable := true
// exclude Scala library from assembly
assembly / assemblyOption := (assembly / assemblyOption).value.copy(includeScala = true)Packaging
$ sbt 'set test in assembly := {}' clean assembly
[INFO] Packaging /mnt/d/flink-project/target/scala-2.12/finkk-project-assembly-0.1-snapshot.jar생성된 파일을 S3에 업로드하여 KDA가 참조하도록 함.
$ aws s3 cp finkk-project-assembly-0.1-snapshot.jar s3://<s3-bucket>/<s3-key>/finkk-project-assembly-0.1-snapshot.jars3로 복사
KDA 생성

Flink Version: 1.15
애플리케이션 이름: kafka2elasticsearch
애플리케이션 리소스에 대한 액세스: 필요한 정책을 사용하여 IAM 역할 kinesis-analytics-kafka2elasticsearch-ap-northeast-1을(를) 생성/업데이트
템플릿: 개발
구성 변경
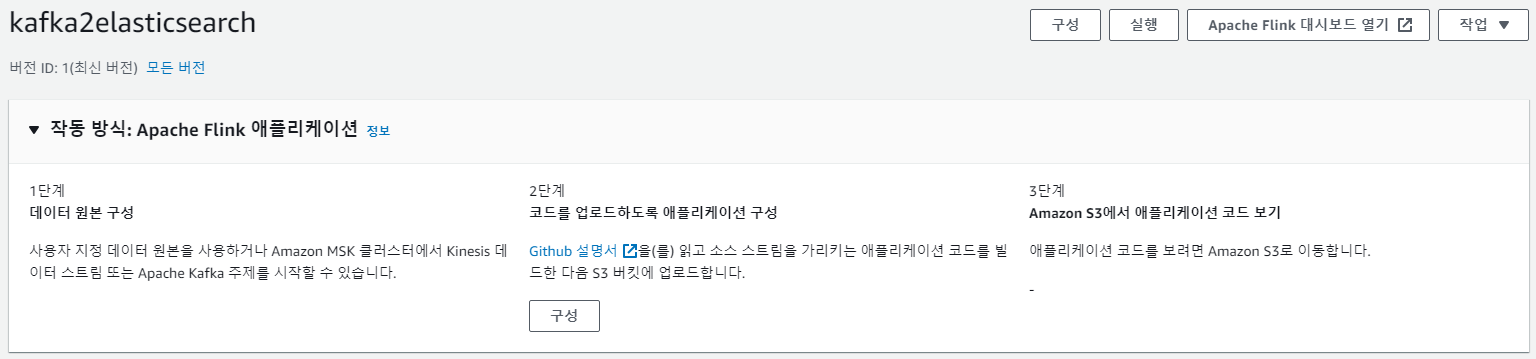
2단계 구성 클릭
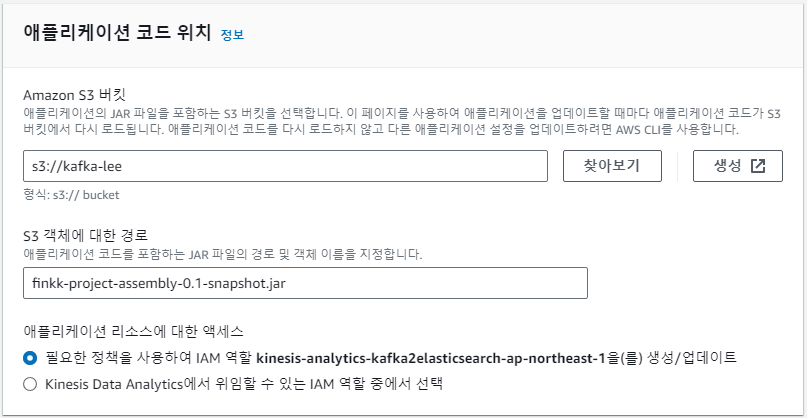
packaging한 파일에 대한 경로를 bucket 칸에 저장.
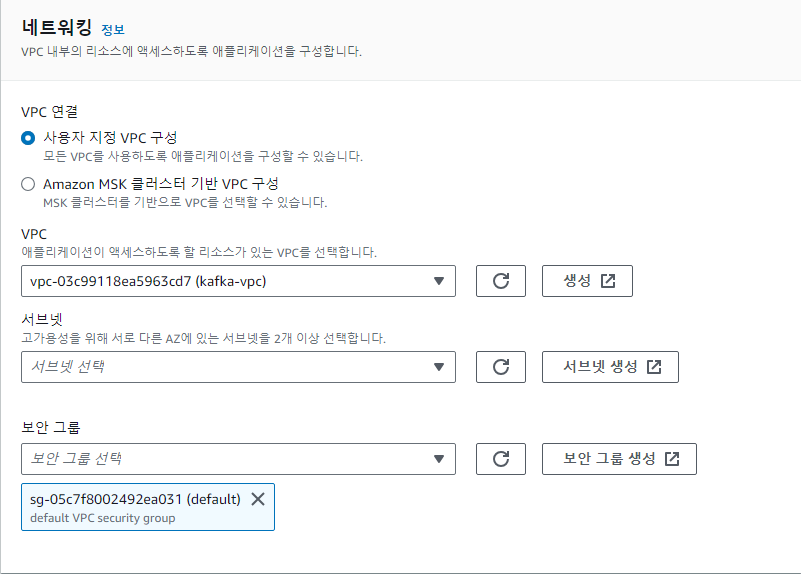
vpc에서 서브넷은 반드시 private한 서브넷을 설정해야 함. KDA는 퍼블릭으로 설정하면 잘 동작하지 않음.
IAM 설정
생성 과정에서 IAM을 사용하도록 하였으므로
IAM 역할에서 IAM 정책을 생성한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowSSMGetParameter",
"Effect": "Allow",
"Action": [
"ssm:GetParameter"
],
"Resource": [
"arn:aws:ssm:ap-northeast-1:427800754317:parameter/*"
]
}
]
}Parameter를 인식할 수 있게 하며 리전 이후의 숫자는 user정보이다. user 정보는 parameter store에 들어가서 생성한 파라미터를 클릭하면 arn:aws:iam::<user정보>:root에서 확인할 수 있다.
해당 유저의 parameter의 모든 데이터를 식별할 수 있게 해준다.
Apache Flink Dashboard