환경
flink_project의 환경을 기준으로 실행
IDE는 IntelliJ를 사용
파일 생성
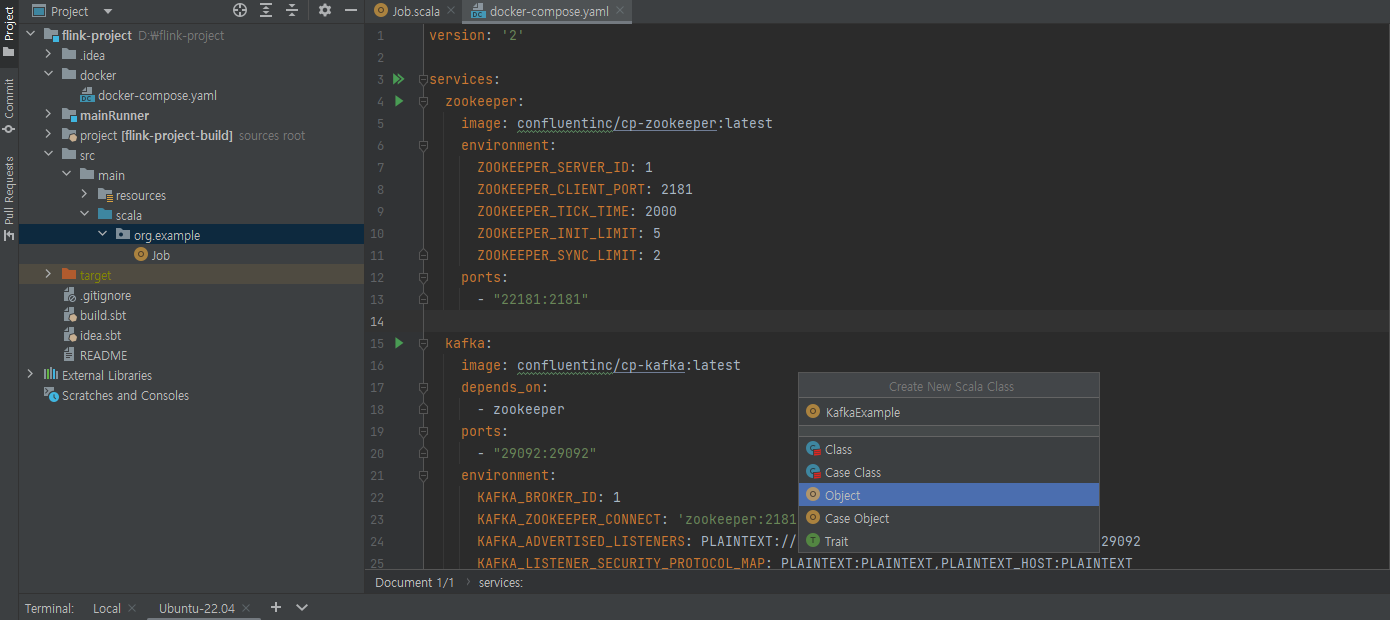
Job.scala 위치에 우클릭 -> New -> Scala Class -> Object 선택후 파일 이름 선택
코드
build.sbt
ThisBuild / resolvers ++= Seq(
"Apache Development Snapshot Repository" at "https://repository.apache.org/content/repositories/snapshots/",
Resolver.mavenLocal
)
name := "flink-project"
version := "0.1-SNAPSHOT"
organization := "org.example"
ThisBuild / scalaVersion := "2.12.7"
val flinkVersion = "1.15.2"
val json4sVersion = "4.0.6"
val awsSdkVersion = "1.12.300"
val flinkDependencies = Seq(
"org.apache.flink" %% "flink-scala" % flinkVersion,
"org.apache.flink" %% "flink-streaming-scala" % flinkVersion,
"org.apache.flink" % "flink-clients" % flinkVersion,
"org.apache.flink" % "flink-connector-kafka" % flinkVersion,
"org.apache.flink" % "flink-connector-elasticsearch7" % flinkVersion,
"org.json4s" %% "json4s-jackson" % json4sVersion,
"com.amazonaws" % "aws-java-sdk-ssm" % awsSdkVersion
)
lazy val root = (project in file(".")).
settings(
libraryDependencies ++= flinkDependencies
)
assembly / mainClass := Some("org.example.Job")
// make run command include the provided dependencies
Compile / run := Defaults.runTask(Compile / fullClasspath,
Compile / run / mainClass,
Compile / run / runner
).evaluated
// stays inside the sbt console when we press "ctrl-c" while a Flink programme executes with "run" or "runMain"
Compile / run / fork := true
Global / cancelable := true
// exclude Scala library from assembly
assembly / assemblyOption := (assembly / assemblyOption).value.copy(includeScala = false)KafkaExample.scala
package org.example
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object KafkaExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment // 스트리밍 변수 생성
val kafkaSource = KafkaSource.builder()
.setBootstrapServers("localhost:29092") // bootstrap server 설정
.setTopics("flink-test") // topic 설정
.setGroupId("flink") // group id 설정
.setStartingOffsets(OffsetsInitializer.earliest()) // 데이터를 어떤 순서대로 받는지 결정
.setValueOnlyDeserializer(new SimpleStringSchema()) // streaming 데이터를 어떻게 받을지 설정
.build() // 위의 경우 string으로 받음
val inputStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
inputStream.print()
env.execute("Flink Kafka Example")
}
}StartingOffsets 살펴보기
latest()의 경우 새로 들어온 메시지에 대해서만 처리. 기존에 토픽에 전송한 데이터가 나오지 않음
committedOffsets()의 경우 consumer가 정상적으로 commit이 된 시점부터 읽어옴.
실행
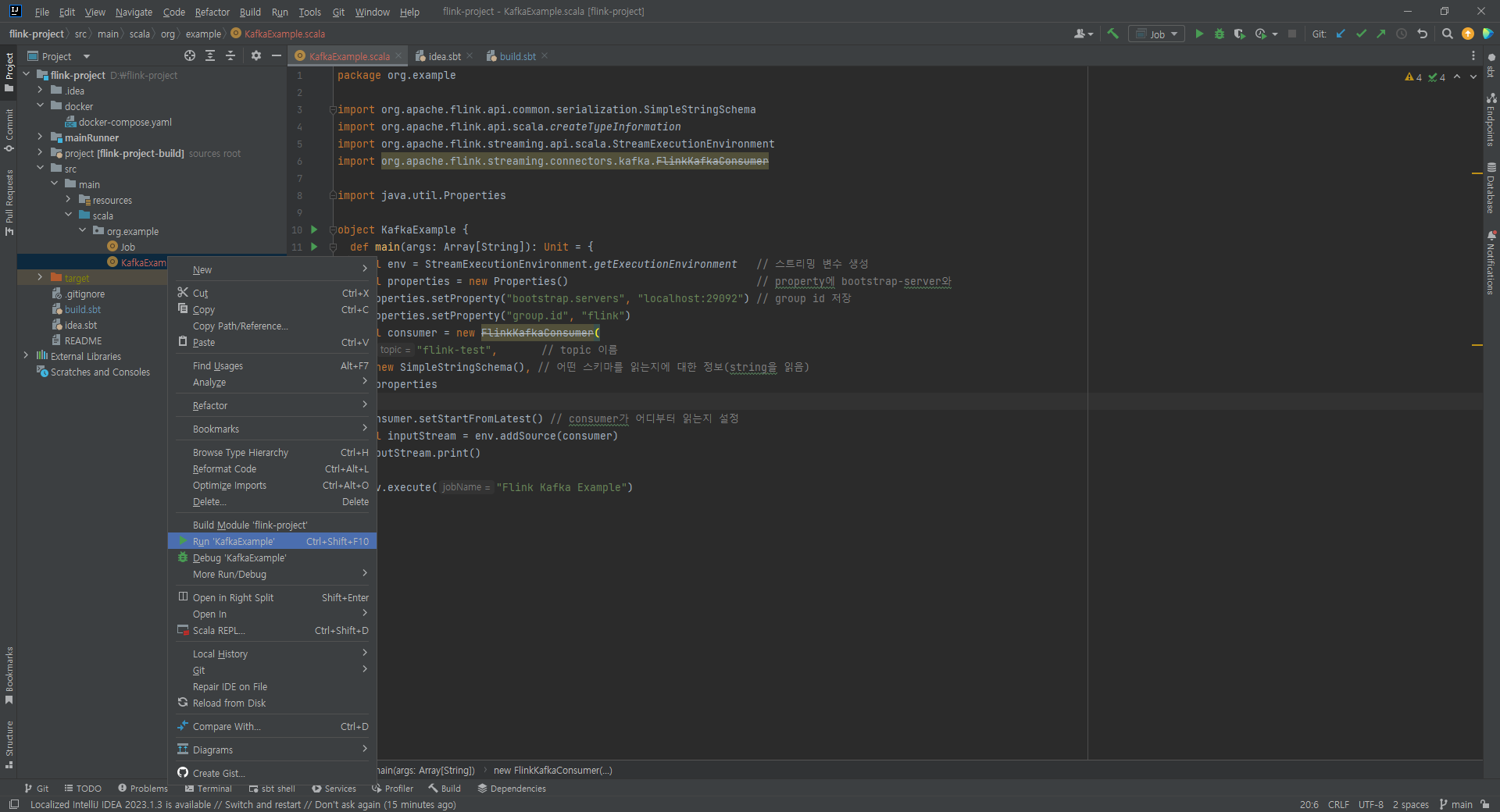
우클릭 후 Run 실행
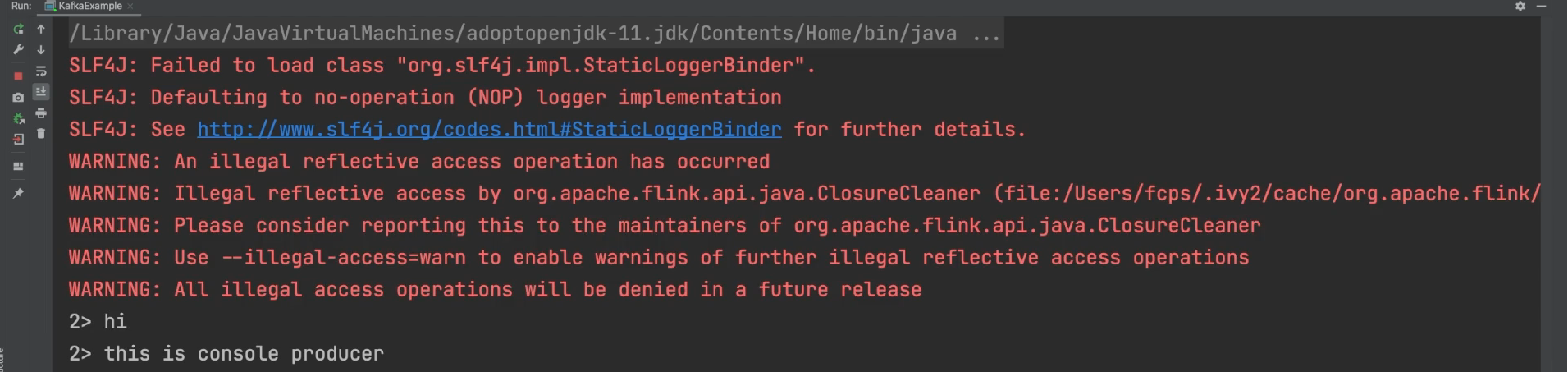
consumer가 동작
종료

우측 상단의 빨간 네모를 클릭하여 종료
topic에 오랫동안 메시지가 전송되지 않으면 자동 종료 되기도 한다.
OpenSearch와 연동
동일한 방식으로 Scala Class -> Object로 파일 생성
build.sbt에 dependency 추가
버전
OpenSearch 버전을 1.3으로 낮춰야 함. 권장 버전과 호환이 되지 않음
코드
package org.example
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.connector.sink2.SinkWriter
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.elasticsearch.sink.{Elasticsearch7SinkBuilder, RequestIndexer}
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.http.HttpHost
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.Requests
import scala.collection.JavaConverters.mapAsJavaMap
object KafkaExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment // 스트리밍 변수 생성
val kafkaSource = KafkaSource.builder()
.setBootstrapServers("localhost:29092") // bootstrap server 설정
.setTopics("flink-test") // topic 설정
.setGroupId("flink") // group id 설정
.setStartingOffsets(OffsetsInitializer.earliest()) // 데이터를 어떤 순서대로 받는지 결정
.setValueOnlyDeserializer(new SimpleStringSchema()) // streaming 데이터를 어떻게 받을지 설정
.build() // 위의 경우 string으로 받음
val inputStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
inputStream.print()
val processStream = inputStream // 데이터 가공
processStream.sinkTo(
new Elasticsearch7SinkBuilder[String]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(new HttpHost("<https://를 제외한 opensearch 도메인 엔드포인트(search...)>", 443, "https"))
.setEmitter((element: String, context: SinkWriter.Context, indexer: RequestIndexer) =>
indexer.add(createIndexRequest(element))
).setConnectionUsername("master")
.setConnectionPassword("passwd")
.build())
def createIndexRequest(element: (String)): IndexRequest = {
val map = Map (
"data" -> element.asInstanceOf[AnyRef]
)
Requests.indexRequest.index("flink-index").source(mapAsJavaMap(map))
}
// 실제로는 {"data": "수신 msg"} 식으로 저장될 것
env.execute("Flink Kafka2ElasticSearch Example")
}
}OpenSearch에서 확인
GET _cat/indices?s=i:desc
green open flink-index XSYoa7s9RcuJM7SZ0aoh4A 5 1 6 0 31.5kb 15.7kbflink-index란 collection이 추가됨.
GET flink_index/_search
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "flink-index",
"_type": "_doc",
"_id": "_RUP7oUBnp6WJWXPT4pi",
"_score": 1.0,
"_source": {
"data" : """{"num":1}"""
}
},
{
"_index": "flink-index",
"_type": "_doc",
"_id": "_RUP7oUBnp6WJWXPT4pi",
"_score": 1.0,
"_source": {
"data" : "hi"
}
},
...
]
}
}SideOutput 구현
가공하는 단계에서 문제가 발생할 때 처리하는 방식
Parser
scala class -> Trait
package org.example
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.util.{Collector, OutputTag}
trait Parser extends ProcessFunction[String, MSG]{ // String이 input, MSG가 output
val outputTag: OutputTag[String] = new OutputTag[String]("side-output"){}
def parse(input: String): MSG
override def processElement(input: String, context: ProcessFunction[String, MSG]#Context, collector: Collector[MSG]) = {
try{
val event = parse(input)
collector.collect(event) // 이벤트가 제대로 파싱되면 collect로 넘김
} catch { // 오류 발생시
case exception: Throwable =>
context.output(outputTag, exception.toString) // side output tag를 바탕으로 Exception 메시지 전달
}
}
}MSG
scala class -> Case Class
dependency에 json 추가
package org.example
import org.json4s.DefaultFormats
import org.json4s.jackson.JsonMethods
case class MSG(num: Int)
class MessageParser extends Parser{
override def parse(input: String): MSG = { // return type이 MSG
// String으로 넘어온 json 형태의 input값을 num이란 필드가 존재하는 case class MSG로 변환
implicit val formats: DefaultFormats.type = org.json4s.DefaultFormats
JsonMethods.parse(input).extract[MSG]
}
}ElasticSearchSink
scala class -> Object
package org.example
import org.apache.flink.api.connector.sink2.SinkWriter
import org.apache.flink.connector.elasticsearch.sink.{Elasticsearch7SinkBuilder, RequestIndexer}
import org.apache.http.HttpHost
import org.elasticsearch.client.Requests
import java.time.ZonedDateTime
import scala.collection.JavaConverters.mapAsJavaMap
object ElasticSearchSink {
def getSink = { // 정상적으로 파싱된 데이터
new Elasticsearch7SinkBuilder[MSG]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(new HttpHost("<도메인 엔드포인트>", 443, "https"))
.setEmitter { (element: MSG, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"data" -> element.num.asInstanceOf[AnyRef],
"event_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-index").source(mapAsJavaMap(map)))
}.setConnectionUsername("master")
.setConnectionPassword("passwd")
.build()
}
def getErrorSink = { // 오류가 발생한 데이터
new Elasticsearch7SinkBuilder[String]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(new HttpHost("<도메인 엔드포엔트>", 443, "https"))
.setEmitter { (element: String, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"error" -> element.asInstanceOf[AnyRef],
"error_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-error").source(mapAsJavaMap(map)))
}.setConnectionUsername("master")
.setConnectionPassword("passwd")
.build()
}
}Kafka2ElasticSearch
package org.example
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Kafka2ElasticSearch {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment // 스트리밍 변수 생성
val kafkaSource = KafkaSource.builder()
.setBootstrapServers("localhost:29092") // bootstrap server 설정
.setTopics("flink-test") // topic 설정
.setGroupId("flink") // group id 설정
.setStartingOffsets(OffsetsInitializer.earliest()) // 데이터를 어떤 순서대로 받는지 결정
.setValueOnlyDeserializer(new SimpleStringSchema()) // streaming 데이터를 어떻게 받을지 설정
.build() // 위의 경우 string으로 받음
val inputStream: DataStream[String] = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
inputStream.print()
val parser = new MessageParser // MSG에서 정의
val processStream = inputStream // 데이터 가공
.process(parser) // parser에서 ProcessFunction을 상속
val errorStream = processStream
.getSideOutput(parser.outputTag)
errorStream.print() // parsing이 실패한 데이터는 print
errorStream.sinkTo(ElasticSearchSink.getErrorSink)
processStream.sinkTo(ElasticSearchSink.getSink)
env.execute("Flink Kafka2ElasticSearch Example")
}
}실행 후
2> {"num":1}
2> hi
2> com.fasterxml.jackson.coreJsonParseException: Unrecognized token 'hi': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')
at [Source: (String)"hi"; line: 1, column: 3]
...json 형태로 전송된 값은 제대로 실행되지만, string으로만 보낸 'hi'는 오류가 발생하는 것을 확인
Opensearch에서 확인
GET _cat/indices?s=i:desc
green open flink-index XSYoa7s9RcuJM7SZ0aoh4A 5 1 2 0 15.1kb 7.5kb
green open flink-error BKdsji388SSLK23kds0sAA 5 1 5 0 45.3kb 22.5kb{
"_index": "flink-index",
"_type": "_doc",
"_id": "SDkdjfke993Dks_ID",
"_version": 1
"_score": null,
"_source": {
"data" : 2,
"event_time": "2023-08-13T08:21:16.861351+09:00"
}
},
"_field": {
"event_time": [
"2023-08-13T14:31:15.861Z"
]
},
"sort": [
1674743475861
]
}{
"_index": "flink-error",
"_type": "_doc",
"_id": "Sslk390sdjDKkjdwSL",
"_version": 1
"_score": null,
"_source": {
"error" : "com.fasterxml.jackson.coreJsonParseException: Unrecognized token 'hi': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')\n at [Source: (String)"hi"; line: 1, column: 3]",
"error_time": "2023-08-13T08:21:17.8179421+09:00"
}
},
"_field": {
"event_time": [
"2023-08-13T15:13:42.863Z"
]
},
"sort": [
1674743475833
]
}멱등적 쓰기 구현
같은 코드를 여러번 실행 혹은 같은 메시지를 여러번 전송하더라도 한번만 저장하도록 만드는 방식
사용중인 코드의 일부분인 .setStartingOffsets(OffsetsInitializer.earliest()) 를 보면 맨처음 받은 데이터를 전부 읽어옴. 만약 재배포를 실행한다면 수많은 데이터를 처음부터 다시 읽게 됨.

elasticsearch의 경우 같은 위와 같은 경우 같은 document 내용물이라도 _id가 전부 다르게 사용됨.
ElasticSearchSink - 1
object ElasticSearchSink {
def getSink = { // 정상적으로 파싱된 데이터
new Elasticsearch7SinkBuilder[MSG]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(new HttpHost("<도메인 엔드포인트>", 443, "https"))
.setEmitter { (element: MSG, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"data" -> element.num.asInstanceOf[AnyRef],
"event_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-index")
.id(element.num.toString) // 추가
.source(mapAsJavaMap(map)))
}.setConnectionUsername("master")
.setConnectionPassword("passwd")
.build()
}id 또한 지정하여 같은 내용이 중복되지 않도록 getSink 함수를 변경
에러를 처리하는 경우 멱등성을 필요로하지 않으므로 변경하지 않음

id 필드가 고정됨.
{
"_index": "flink-index",
"_type": "_doc",
"_id": "1",
"_version": 2
"_score": null,
"_source": {
"data" : 2,
"event_time": "2023-08-13T08:26:15.846315+09:00"
}
},
"_field": {
"event_time": [
"2023-08-13T14:31:15.861Z"
]
},
"sort": [
1674743475861
]
}단 위의 경우 version이 올라가는 것을 확인할 수 있음. 데이터를 덮어 씌우는 것.
ElasticSearchSink - 2
overwrite를 원하지 않는 경우 같은 데이터가 존재하는 경우 id를 비교하고 동일한 id라면 exception을 사용하는 방법도 있음.
object ElasticSearchSink {
def getSink = { // 정상적으로 파싱된 데이터
new Elasticsearch7SinkBuilder[MSG]
.setBulkFlushMaxActions(1) // 한번에 몇개의 데이터를 넣을지 결정
.setHosts(new HttpHost("<도메인 엔드포인트>", 443, "https"))
.setEmitter { (element: MSG, context: SinkWriter.Context, indexer: RequestIndexer) =>
val map = Map(
"data" -> element.num.asInstanceOf[AnyRef],
"event_time" -> ZonedDateTime.now().asInstanceOf[AnyRef]
)
indexer.add(Requests.indexRequest.index("flink-index")
.id(element.num.toString)
.create(true) // 추가
.source(mapAsJavaMap(map)))
}.setConnectionUsername("master")
.setConnectionPassword("passwd")
.build()
}
...ElasticSearch exception [type=version_conflict_engine_exception, reason=[1]: version conflict, document already exists (current version [3])]].create(true) 를 사용하면 동일한 이벤트가 색인되는 것을 막을 수 있음.

개발자로서 배울 점이 많은 글이었습니다. 감사합니다.