저는 weights를 최적화하는 논문들을 주로 읽습니다. 꽤 많은 수의 논문을 읽었지만 기억력이 훌륭한 편이 아니라 계속해서 까먹곤하네요. 그래서 제가 처음 딥러닝을 공부하는 교보재가 되었던 '밑바닥부터 시작하는 딥러닝'에 나온 optimization 부분을 정리하고자 합니다.(optimization에 대해 발표했던 자료입니다.)
Chapter 6
optimization
궁극적으로 우리가 모델을 학습시키면서 얻고자 하는 것이 무엇일까요? 당연히 뛰어난 성능을 얻고자 함이겠지만, 좀 더 정확히 표현하면 이 뛰어난 성능을 보여주는 모델의 가중치 매개변수의 최적값입니다. 우리는 이러한 최적값을 찾는 문제를 푸는 것을 optimization이라 합니다. 앞서 배운 내용들은 인간도 노력하면 계산해낼 수 있는 수준이었지만, 딥러닝까지 넘어가면 이러한 매개변수는 수십 수백이 아닌 수십만 혹은 수억 단위까지 넘어가곤 합니다. 책에 간혹 등장하는 AlexNet만 하더라도 파라미터의 수가 6천만에 달하는데, 감히 건드릴 엄두가 안 나는 숫자입니다.
지금까지 최적의 매개변수 값을 찾는 단서로 매개변수의 고차원에서(비록 지금까진 2차원 평면이나 3차원 곡면 정도의 불과했고 실제로 고차원이라 하더라도 PCA와 같은 방법으로 차원을 줄여 다루기는 합니다.) 기울기를 이용했습니다. 몇 번이고 반복하여 최적값에 도달하는 것인데, Stochastic Gradient Descent (SGD)라는 방법이었습니다. 상당히 오래된 기법이고, 단순한 기법이지만 머신러닝이 사랑하는 기법입니다. 여전히 이 방법을 많이들 애용하고 이 방법에서 업그레이드 된 많은 기법들이 있습니다. 대표적으로 Stochastic Averaging Weights라는 기법은 캐글 대회에서 2등에도 오르는 등 상당한 성능을 발휘합니다.Averaging Weights Leads to Wider Optima and Better Generalization라는 논문에서 발표한 내용인데, 러시아 대학과 삼성 연구소에서 협업으로 발표한 논문입니다. https://arxiv.org/pdf/1803.05407.pdf%20%20https://github.com/timgaripov/swa
해당 연구진의 논문들을 살펴보면 가중치 매개변수 최적화에 초점이 맞춰줘 있습니다. 그런데 이렇게 매개변수를 최적화 하는데 초점을 맞춰 진행된 연구들을 살펴보면 하나같이 매개변수 및 성능 지표와의 관계들에서 기하학적 특징들이 상당히 두드러집니다. 모든 논문을 소개할 수는 없고 공부하면서 상당히 흥미로웠던 부분이라 잠시 언급했습니다. 미분기하학 시간에 배웠던 곡률이나 대수학 및 선대수 시간에 배웠던 subspace 및 matrix에 대한 심도 깊은 수학적 논의들이 난무하니 전공 시간에 배웠던 내용들을 착실하게 되짚어 보시기 바랍니다. 딴 소리가 길었습니다. 본격적으로 어떤 방법들이 있는지 알아볼 차례입니다. 책에서는 최적화 기법으로 다음과 같은 네가지 방법을 제안합니다.
1.확률적 경사 하강법
2.모멘텀
3.AdaGrad
4.Adam
SGD에 대해 간단하게 복습하겠습니다.
여기서 각각 나타난 순서대로 갱신할 가중치 매개변수, 학습률, W에 대한 손실 함수의 기울기입니다. 초기값 W_0을 설정하고 그에 대응되는 손실함수의 기울기를 구한 후 적절한 학습률을 취해 W를 갱신하는 방법이죠. 그림으로 나타내면 다음과 같습니다.
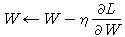
SGD를 class로 표현하면 다음과 같습니다.
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, parameters, gradients):
for key in parameters.keys():
parameters[key] -= self.lr * gradients[key] 여기서 key라는 것에 대해 잠시만 설명하자면, 사전에서 우리가 찾고자 하는 단어의 역할을 한다고 이해하시면 됩니다. value는 그 단어의 뜻이 되겠죠. 예를 들어 {'투수' : '박철순', '타자' : '이만기'}와 같은 딕셔너리가 있다고 생각해봅시다. 파이썬에서도 딕셔너리는 사전과 거의 같다고 생각해도 무방합니다. 여기서 투수와 타자는 key를 박철순과 이만기는 value에 해당하게 되겠죠. 여기서 keys()는 그러한 key들을 순회할 수 있는 iterator를 불러옵니다.
이제 다시 코드를 살펴보면, 클래스를 만들 때 초기화 하는 방법인 init을 이용하여 초기화 방법을 정하고, self에 lr을 부여합니다. update라는 메서드에 self(lr), parameters, gradients를 변수로 하고, keys()를 이용하여 parameters에 속하는 key들을 순회하기 위해 필요한 iterator를 불러냅니다. 그리고 그 iterator에 key가 속해 있을 때마다 간단한 수식으로 parameters를 업데이트 합니다. 다음은 책에서 수도코드로만 간단하게 언급하고 넘어간 부분을 이미 짜여진 코드를 바탕으로 제가 다시 구현한 코드입니다. 사실 별 거 없습니다. 각 부분은 의사코드 (수도코드)에 다 설명이 되어있으니 실행 결과만 보겠습니다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
from dataset.mnist import load_mnist
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
self.loss(x, t)
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
network = TwoLayerNet(input_size=784, hidden_size=100, output_size=10)
optimizer = SGD()
for i in range(10000):
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = x_train.shape[0]
batch_size = 100
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
params = network.params
optimizer.update(params, grads)a = params['W1']
b = params['W2']
c = params['b1']
d = params['b2']
a.shape, b.shape, c.shape, d.shape
((784, 100), (100, 10), (100,), (10,))
자 이제 위 결과를 살펴봅시다. 우선 가중치를 갖는 층이 2개인 network, TwoLayerNet을 이용하였습니다. (인터넷(github)에 이 책의 코드들이 담긴 파일이 올라와 있어 굳이 이렇게 책에 있는 코드를 옮겨 올 필요는 없었네요.) (W1, b1), (W2, b2) 각각 층마다 가중치와 편향이 한 쌍씩 올바르게 나왔습니다. shape함수를 이용하여 살펴보면 (784X100), (100, )으로 나오네요. 784의 크기를 가지는 input data를 첫번째 층에서 사이즈를 100으로 줄였고, 편향도 그에 따라 크기를 100으로 가짐을 알 수 있네요. W2,b2도 마찬가지입니다. 네 제대로 코드가 실행되었고, 올바르게 매개변수들을 구했습니다.
현재까지도 이 SGD는 애용되고 있는 기법입니다. 그 응용들도 다양하게 나오고 있죠. 하지만 이런 SGD도 단점은 있습니다.특정 함수에서 비효율적입니다. 비등방성 함수와 같이 방향에 따라 기울기의 특성이 달라지는, 정확히는 기울기가 가르키는 방향이 달라지는 함수에서 비효율적입니다. 전체 범위에서의 MINIMUM으로 수렴하는 것이 아니라 지역 일부의 MINIMUM에 수렴하여 빠져나오지 못할 수도 있습니다.
또한 위 그림을 보면 알 수 있겠지만, 진동하며 수렴하고 있습니다.(이렇게 진동하는 이유는 gradient의 특성을 고려해보면 알 수 있습니다. 등고선의 수직한 방향으로 벡터가 형성되니 이런 모양을 띄게 되겠지요.) 진동하며 수렴하다보니, 학습 시간이 오래 걸리기도 하고, 학습률을 높여 속도를 빠르게하면 발산해 버릴 수도 있습니다.
학습 속도나 SGD가 발산 및 엉뚱한 지점으로 수렴하는 것을 방지하기 위해 즉 SGD를 대체하기 위해 고안된 3가지 기법에 대해 이제 알아보겠습니다. 자 이제 그 대안 중 하나로 첫번 째로 소개해드릴 모멘텀에 대해 알아봅시다.
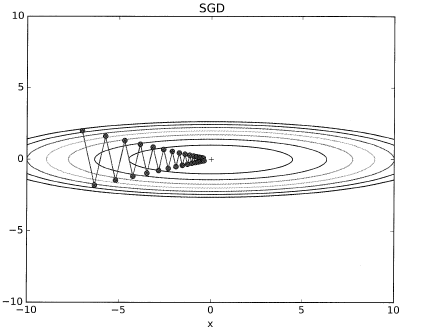
모멘텀에 대해 간단하게 설명하자면, 관성을 주는 것입니다. local minimum에 빠지거나 굳이 필요 없는 곳까지 오버해서 가지 않도록 일종의 추를 달아 놓는 것이죠. 산에서 공을 굴릴 때 끝까지 올바르게 내려가기 바란다고 생각해봅시다. 만약 산 중간 지점에 오목한 부분이 있다면 그 지점에서 멈춰버릴 수도 있습니다. 하지만 무거운 추를 달아놓고 굴린다면 그 무게로 인해서 오목한 지점에서 비교적 잘 탈출하고 잘 내려갈 확률이 높겠죠. 다음은 적절한 그림을 찾다가 한 블로그에서 너무 이쁘게 잘 정리해 놓았길래 가져왔습니다.
출처:https://blog.naver.com/tlsfkaus4862/222344225931
앞서 SGD와 유사하지만 가중치를 업데이트 할 때 일종의 관성부분을 담당하는 alpha*v가 추가로 생겼습니다. alpha는 적절한 값을 넣어주면 되는 상수값에 해당하고 v는 속도에 해당합니다. 방향과 속력 모두 지니고 있어, 가중치를 갱신할 때 관성을 지닐 수 있게됩니다. 또 v는 아무런 힘을 받지 않는 상태라면 MINIMUM을 향해 서서히 하강시키는 역할도 하게 되겠죠. 또한 그림을 살펴보면 SGD보다 지그재도도 덜하고, 좀 더 완만하게 최저점을 향해 찾아갑니다.
다음은 momentum의 class 코드입니다.
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[keys] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key] 학습률과 alpha에 해당하는 momentum을 구체적으로 설정하고, v는 일단 아무 값도 담지 않습니다. 대신 업데이트 함수가 처음 호출될 때 주어진 매개변수 (params)와 같은 구조의 데이터를 딕셔너리로 저장합니다.(np.zeros를 이용해 0으로 채워넣어놨네요) 그래야 호응이 되겠죠. 그 후는 앞서 소개드린 수식을 코드로 옮겨 놓은 것에 불과합니다.
다음은 AdaGrad에 대해 소개해드리겠습니다. 이번엔 학습률에 초점을 맞춰 생각해보겠습니다. 학습률이 너무 낮으면 학습의 진행이 매우 더디게 될 것이고, 그렇다고 학습률을 너무 높이면 발산해버리는 일이 발생할겁니다. 그래서 보통 학습률을 높게 설정하고 서서히 낮춰가는 방향으로 학습률에 변화를 주는 방식을 많이 체택합니다. learnig rate decay라는 방식으로 AdaGrad도 이 방법을 사용합니다. AG는 그 중 가장 간단한 방법인 매개변수 전체의 학습률울 일괄적으로 낮추는 방식에서 약간 발전된 방법입니다. 매개변수마다 학습률을 다르게 하거든요. 아까 momentum 관련 그림을 가져온 블로그에서 한 번 더 가져오겠습니다. 제가 직접 만들려했는데 잘 만들어놔서 제가 만드는 것보다 훨씬 나을 것 같습니다...ㅎㅎ : )
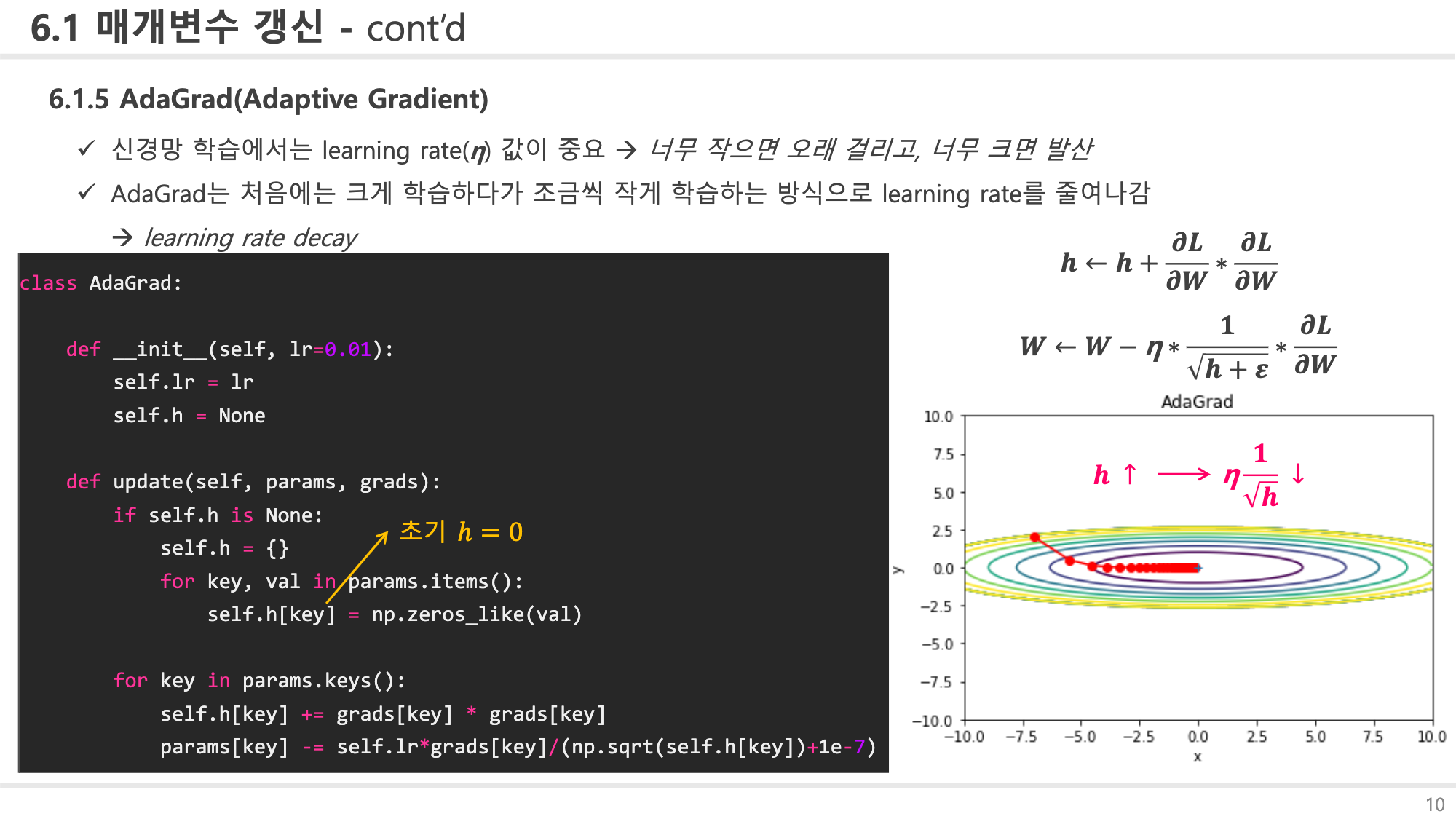 AdaGrad.png
AdaGrad.png
우선 위 수식을 살펴보면 매개변수마다 미분을 하여 gradient를 다르게 구합니다. 그래서 앞서 설명한 방식의 약간의 업데이트 버전이라는 것입니다. 전체 매개변수의 학습률을 서서히 줄이지만, 매개변수마다 다른 학습률을 적용시키는 것이죠. 그리고 책에 나와있는 수식과 약간 다르기에 설명하자면, 로스함수의 gradient를 계산하면 행렬의 형태로 나오게 됩니다. 기울기가 행렬로 주어지기 때문에 기울기 값을 제곱하는 방식으로 같은 항끼리 곱하는 방식을 체택한 것입니다.(책에 나오는 수식) a_11은 a_11과 곱해지게 되겠지요. 그리고 분모에 0이 오는 경우를 방지하기 위해서 아주 작은 양수값 1e-7정도를 더해줍니다. 위 코드를 살펴보면 업데이트를 처음 호출할 때 h를 params과 같은 데이터 구조의 딕셔너리로 저장하고 0값을 채워넣는 걸 알 수 있습니다. 이런 경우에 분모에 0이 오게되는 참사가 발생할 수도 있겠죠. 참고로 행렬에 루트를 씌우는 건 대체 무슨 행동인가 싶은 분들이 있을 수도 있습니다. 다음 코드의 결과를 살펴보면 쉽게 납득하실 수 있으리라 생각합니다.
import numpy as np
h = np.array( [[1,2,3], [4,5,6], [7,8,9]])
np.sqrt(h)
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974],
[2.64575131, 2.82842712, 3. ]])이제 우측 그림을 살펴보면 처음엔 기울기 값이 커져 y축 방향으로 크게 움직이지만, 후엔 학습률도 낮아져 불필요한 움직임이 적어진 상태로 minimum을 향해 잘 찾아가는 것을 확인하실 수 있습니다.
이제 정말 실전에서 자주 마주치게 될 Adam에 대해 소개해드리겠습니다. 네 앞서 설명한 모멘텀과 AdaGrad를 융합한 버전입니다. 책에 class 구현을 적어놓지 않아 가져와 보겠습니다. 아 수식도 적어놓지 않았으니 수식 먼저 가져 오겠습니다. 다음과 같습니다.
하이퍼 파라미터를 세개 설정합니다. 각각 학습률 (논문에서는 alpha로 나와있다고 하네요.), 일차(beta1) 이차(beta2) 모멘텀용 계수입니다. 하이퍼파라미터란 간단하게 초기에 모델을 만들 때 우리 의지대로 설정할 수 있는 매개변수라고 생각하면 편합니다.
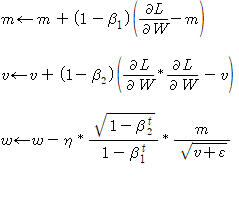
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)네... 수식과 코드를 확인했지만 대체 무슨 소리인지 와닿지 않으실겁니다. 그 이유는 사실 AdaGrad와 Adam 사이에 한 가지 기법이 더 있기 때문입니다. 바로 RMSProp이라는 기법입니다. 원논문에서도 RMSProp라는 기법과 momentum을 섞어 사용했다고 언급이 나옵니다. RMSprop은 adaptive gradient 즉 AdaGrad를 업그레이드 시킨 버젼입니다. AG는 반복할수록 STEPSIZE(간단하게 움직이는 보폭)가 너무 작아지는 문제가 발생할 수 있습니다. 이러한 문제를 보완하기 위해서 EXPONENTIAL MOVING AVRAGE라는 방법을 사용하여 RMSProp이 고안되었습니다.
exponential moving average란 간단하게 설명하면 과거의 정보에 가중치를 작게 부여하는 방식입니다. 네 움직임의 평균을 지수함수처럼 다루겠다는 뜻입니다. 지수함수 그래프 모양을 생각해보면 직관적으로 느낄 수 있을겁니다. 하지만 RMSProp도 문제점이 있습니다... 이녀석은 AdaGrad와 반대로 step size가 발산할 수 있습니다. 너무 작아서 문제가 될까봐 방법을 고안했더니 이번엔 발산할 수도 있는 문제가 생긴것이죠... 이를 해결하기 위해서 Adam은 편향에대한 작업에서 moment의 비편향 추정을 계산합니다. (moment는 물리학에서의 momentum이라 생각하세요.)
이런 배경지식을 가지고서 수식을 살펴보면, 모멘트 m을 업데이트할 때, 기울기에 적절한 하이퍼파라미터를 수정한 값을 곱해주고 모멘트에도 그 값을 곱해주는 것을 알 수 있습니다. 네 이 부분이 바로 모멘텀과 유사한 부분이죠.그리고 AdaGrad에서 고안한 방법과 비슷하게 v를 갱신해주고 최종적으로 W를 업데이트하게 됩니다. 코드에 마지막 부분에는 비편향 추정에 대해 어떻게 계산할 것인지도 나오네요. 이 정도면 충분히 이해가 되었을거라 생각하고 좀 더 공부하시고 싶은 분들을 위해 원논문 링크를 달아놓겠습니다.
https://arxiv.org/pdf/1412.6980.pdf 워낙 유명한 논문이다보니 리뷰도 많습니다. 논문을 읽기 힘드시거나 시간이 부족하시면 리뷰만이라도 읽어보는 것을 추천합니다. 참고로 Adam은 Adaptive Moment Estimation의 줄임말입니다. 풀네임을 알고 보니 더욱 와닿지 않나요?
이렇게 딥러닝 및 머신러닝에서는 기존에 나와있는 방식을 융합하여 발전시키곤 합니다. SWA with momentum이런 식으로 이름을 붙여서 짬뽕시켜 모델링하기도 하구요. 이 외에도 앙상블 기법등 성능을 높이기 위한 창의적인 아이디어들이 많이 존재합니다. 아 물론 SGD와 Adam은 벌써 몇년째 그 위치를 공고히하고 있는 알고리즘입니다.
import os
import sys
sys.path.append(os.pardir)
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print( "===========" + "iteration:" + str(i) + "===========")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()코드가 그렇게 어렵진 않습니다. mnist를 불러오고, optimizers를 만든 후 key에는 'SGD', 'MOMENTUM', 'AdaGrad', 'Adam', value에는 각 대응되는 함수들을 담습니다. 그리고 iterator를 만들어 key를 돌리고 각 모델링 기법들을 순서대로 이용합니다. 실행이 되었으면 각 모델링마다 적절한 이름을 붙이고 기호를 넣어 그래프로 나타냅니다.
초기값 문제
신경망 학습에 있어 optimization의 4가지 예시를 살펴보았습니다. Adam과 SGD같은 경우는 지금도 널리 쓰이고 있어 꼭 기억하고 있어야할 기법이죠. 하지만 세상에 공짜 점심은 없듯이 어느 모델이나 기회비용을 가지고 있습니다. 어떤 데이터 셋을 이용하는지, 어떤 문제에 직면했는지 (구체적으로 회귀인지 분류인지 같은 경우가 있겠죠)에 따라 열등할 수도 우수할 수도 있습니다. 경우에 따라 더 적절한 모델이 있을 뿐이죠. 이렇게 적절한 모델을 선택했다하더라도 가중치의 초기값에 설정에 따라 결과물이 달라질 수 있습니다. 너무 터무늬 없는 가중치 선택은 최적화에 실패할 수도 혹은 예상보다 너무 오래 작업할 수도 있습니다. 따라서 이제부터 가중치 초기값을 어떻게 설정할 것인가에 대해 이야기하고자 합니다.
잠시 오버피팅을 억제하는 테크닉인 weight decay에 대해 설명하고자 합니다. overfitting이란 신경망을 학습할 때 훈련데이터를 너무 착실하게 따라 test데이터나 그 외에 out of domain에는 제대로 적응하지 못하는 상태를 의미합니다. 데이터가 너무 적거나 혹은 매개변수가 너무 많고 모델이 표현력이 너무 높으면 훈련데이터에만 치중하게 됩니다. 따라서 매개변수 값을 작아지도록 학습하여 훈련데이터에만 매몰되지 않도록 하는 방법인거죠.
갑자기 웬 오버피팅이고 가중치 감소기법이냐... 바로 초깃값을 설정하는 데 있어 하나의 아이디어를 제공하기 때문입니다. 가중치를 작게하면 오버피팅을 방지할 수 있다면 가중치를 작게하는 초기값을 설정하는 것이죠. 당연하게도 초기값 또한 작은 값에서 시작하는게 정공법입니다. 그렇다고 모두 0으로 만들어 버리면 학습이 올바르게 일어나지 않습니다. 만약 초기값을 0으로 해버리면 순전파 때 모든 뉴런에 같은 값들이 입력될겁니다. 그 말은 즉 역전파를 고려했을 때 가중치가 모두 똑같이 갱신된다는 말입니다. 갱신을 거쳐도 여전히 같은 값을 유지해버리는 상황이 발생합니다. 이럴 바엔 가중치를 여러개로 하는 의미가 없죠. 가중치가 모두 같게 나올거면 하나로 두나 여러 개로 두나 유의미한 성능의 차이를 보일 수 있을까요? 이런 의미에서 초기값은 균일하게 설정하는 것이 아니라 무작위로 설정해야 합니다. 그래서 무작위로 한 번 초기값을 설정하여 후에 가중치들이 어떤 값을 띄는지 그림으로 나타내는 코드를 아래 적어두었습니다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
input_data = np.random.randn(1000, 100)
node_num = 100
hidden_layer_size = 5
activations = {}
x = input_data
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
# z = ReLU(a)
# z = tanh(a)
activations[i] = z
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
if i != 0: plt.yticks([], [])
# plt.xlim(0.1, 1)
# plt.ylim(0, 7000)
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()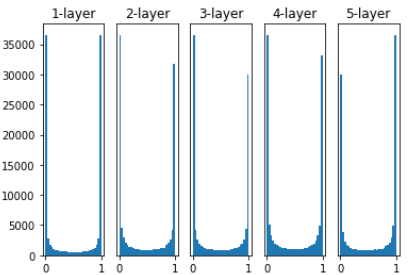
w = np.random.randn(node_num, node_num) * 1 을 보면 알 수 있듯이 가중치의 초기값을 표준편차가 1인 정규분포로 잡았습니다. 그랬더니 양 측에 쏠리는 결과가 나타났는데 여기서 쓰인 시그모이드 함수는 0 과 1을 점근선으로 가지는 함수입니다. 출력값을 0과 1로 뽑아 냈을 때 이 부분에서 기울기 값을 구하는 것도 넌센스이고 미분을 한다쳐도 그 기울기값을 0에 다가갑니다. 즉 역전파의 기울기가 점점 사라지게 되는 겁니다. 이 현상을 기울기 소실이라고 합니다. 꽤 유명한 문제죠. 이를 해결하기 위해서 표준편차를 바꾸면 이번엔 중앙에 쏠리게 되고, 이러면 아까 언급했듯이 뉴런을 여러개 할 필요가 없습니다.
이에 대한 연구도 당연히 활발하게 진행되었고, Xavier Glorot와 Youshua Bengio가 제안한 Xavier 초기값을 한 번 써보겠습니다. 우선 아이디어는 앞 계층의 노드가 n개라면 표준편차를 1/root(n)인 분포를 이용한다는 것입니다. 논문을 읽지 않아 수식적으로 어떻게 이런 결과를 이끌어냈는지는 확인하지 못했습니다.
뭐 어쨌든
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)으로 입력하면 됩니다.
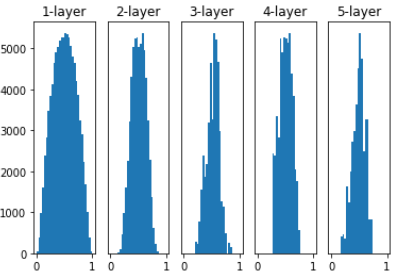
형태는 조금 일그러졌지만 확실히 넓게 분포하네요. 방금 사용한 초기값은 활성화 함수가 선형인 경우를 전제로 이끌어낸 결과입니다. 많이 사용하는 ReLu함수 같은 경우에는 2/root(n)을 표준편차로 이용한다고 합니다. 이 정도면 된 것 같습니다. 이제 배치 정규화에 대해서 알아봅시다.
배치 정규화 (Batch Normalization)
가중치의 초깃값을 잘 설정하면 각 층의 분포가 잘 퍼지면서 학습에 원활함을 알 수 있었습니다. 그런데 굳이 초기값에 얽매이지 않고도 훨씬 성능 좋은 방법이 하나 있습니다. 바로 각 층의 활성화 값을 퍼뜨리도록 강제하는 것입니다. 아 우선 머신러닝에서 자주 등장하는 표현인 normalization과 regularization의 차이를 잠시 설명해드리겠습니다.
우선 normalization이란 데이터의 분포를 정규화 하는 것입니다. 각 층에 들어가는 데이터들을 원하는 평균과 분산을 가진 정규분포를 따르도록 정규화 시키는 것이죠. 네 학습 전에 하곤 합니다. Batch Normalization(https://arxiv.org/abs/1502.03167)뿐 아니라 layer normalization (https://arxiv.org/abs/1607.06450), group normalization (https://arxiv.org/abs/1803.08494) 등 다양한 아이디어들이 있습니다. 그리고 regularization이란 데이터가 아닌 weight를 건드리는 것입니다. 좀 더 와닿게 표현하자면 '테스트 단계 때 발생하는 에러를 줄이기 위해 학습 알고리즘을 수정하는 기법'이라고 할 수 있겠습니다. 크게 L1, L2 regularization 두가지가 있는데 자세한 내용은 조금만 검색해도 나오니 참조하시기 바랍니다. 별로 어렵지 않습니다. 보통은 일반적으로 L2를 더 선호하긴합니다. 그리고 L2는 weight decay를 가능하게 해줘 둘이 같은 것으로 취급하곤 합니다. 정확히는 weight decay가 L2에 속하는 것입니다. 일단 여기까지만 설명하겠습니다.
다시 설명으로 돌아오면, 배치 정규화는 학습 속도, 초기값 문제, 오버피팅 억제 크게 이 세가지 문제점에서 큰 효과를 보입니다. 그래서 사실상 성능을 높이기 위해서 데이터를 Batch Normalization하는 것은 거의 당연시되어 쓰이고 있습니다. 
위는 논문에 나와 있는 batch norm의 알고리즘입니다. 사진 사이즈를 조절 못하겠어서 일단은 저렇게 냅뒀습니다. 이 점은 죄송합니다... 알고리즘은 매우 간단합니다. mini-batch의 평균과 분산을 저장하고, 그것을 이용해 정규화 합니다. 그리고 이 정규화한 값을 적절하게 이동변환을 하거나 그 값을 확대하여 사용하곤 합니다. 감마와 베타는 일반적으로 1과 0으로 설정하고(사실상 변하는게 없죠. 이럼 즉 원본으로 시작한다는 뜻입니다.) 학습하면서 적합한 값으로 찾아갑니다. 이는 개발자의 몫이겠죠. 아 참고로 평균을 0 분산을 1이 되겠금 정규화하는 것을 whitening이라고 부릅니다. 관련 논문을 보면 저 표현이 자주 등장하니 알려드렸습니다.
다음 그림을 보면 배치 정규화를 신경망 층에서 어느 부분에서 행할지 알 수 있습니다. 사실 그림까지 갈 것도 없이 배치 정구화가 무엇을 원하는 것인지 생각해보면 간단하게 알 수 있습니다. 활성화 값이 적당히 분포되기 바라는 것이니, affine 변환 이후 활성화 함수 이전에 배치하면 되겠죠. 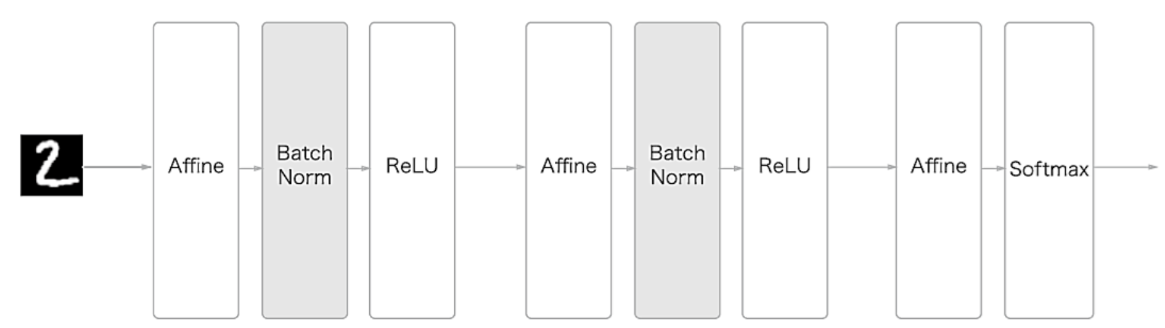
어떤 아이디어로 이루어지는지 알아봤으니 그 성능을 눈으로 확인할 차레입니다. 사실 batch normalization에 대해 이야기할 것들은 책에 나온 것보다 훨씬 많습니다. 어떤 기법이나 논문을 읽든간에 이것이 무슨 배경에서 출발했는지는 우리가 사고하는데 있어 큰 도움을 줍니다. 사실 활성화 값을 적당히 퍼지도록 강제한다는 설명은 약간은 당위성이 부족하니다. covariate shift라는 문제점이 있거든요! 그 외에도 드롭아웃을 대체하는 기능을 보이지만 완벽히 대체할 수는 없고, 배치단위로 정규화하다보니 배치 사이즈에 따라 약점을 보이기도 합니다. RNN과 같은 구조에서는 적용하기 어렵기도 하구요 아예 논문에서는 CNN에 적용시키는 방법을 하나의 챕터로 설명하기도 합니다. 그리고 regularization과 무슨 관계가 있는 것인지 등등 장점도 더 많고 단점도 생각보다 존재합니다. 그에 대응하여 앞서 소개한 normalization 방법이 고안된 것이구요.
하지만 하나 확실한건 엄청나게 획기적인 아이디어이자, 약간의 제약만 극복할 수 있다면 거의 모든 모델링에서 데이터를 정규화하곤 합니다. 사소한 부가적인 효과나 단점들은 차차 머신러닝을 공부하면서 알아보는 걸로 하고 (솔직히 지금 단계에서 그렇게 중요하지 않은 내용이라 뺀 것도 있습니다. 논문을 제대로 진득하게 한 번 읽어보시는 것이 좋겠습니다. 머신러닝에 대해 공부를 계속 진행해 나가신다면 언젠가는 보게 될겁니다.) 다음 코드를 실행시켜 효과를 확인해 보겠습니다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.optimizer import SGD, Adam
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train = x_train[:1000]
t_train = t_train[:1000]
max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
def __train(weight_init_std):
bn_network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std, use_batchnorm=True)
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std)
optimizer = SGD(lr=learning_rate)
train_acc_list = []
bn_train_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch)
optimizer.update(_network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
bn_train_acc = bn_network.accuracy(x_train, t_train)
train_acc_list.append(train_acc)
bn_train_acc_list.append(bn_train_acc)
print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - " + str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
print( "============== " + str(i+1) + "/16" + " ==============")
train_acc_list, bn_train_acc_list = __train(w)
plt.subplot(4,4,i+1)
plt.title("W:" + str(w))
if i == 15:
plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)
plt.plot(x, train_acc_list, linestyle = "--", label='Normal(without BatchNorm)', markevery=2)
else:
plt.plot(x, bn_train_acc_list, markevery=2)
plt.plot(x, train_acc_list, linestyle="--", markevery=2)
plt.ylim(0, 1.0)
if i % 4:
plt.yticks([])
else:
plt.ylabel("accuracy")
if i < 12:
plt.xticks([])
else:
plt.xlabel("epochs")
plt.legend(loc='lower right')
plt.show()바른 학습을 위해 (with overfitting)
오버피팅
앞서 설명한 내용이지만 간략하게 다시 짚고 넘어갑시다. 매개변수가 많고 표현력도 높은 경우 학습을 진행시키면서 훈련데이터에서 얻어진 매개변수가 많다보니 훈련데이터에 치중하는 경우가 발생할 수 있습니다. 표현력도 마찬가지로 너무 잘 표현하다보니 훈련데이터만 표현하게 되는 거죠. 그리고 훈련 데이터가 적은 경우에 역시 실전에 적응하지 못하는 모습을 보입니다.
책에서는 억지로 이 두가지 상황을 동시에 만족하는 모델을 보여주는데 코드나 그림에 대해 딱히 설명할 필요가 없어 넘어가겠습니다. 코드도 해석하는데 어렵지 않을겁니다.
오버피팅을 피하는 방법으로 앞서 weight decay가 있다고 말씀 드렸었습니다. 거기에 더해 우리는 드롭아웃 이라는 방법을 공부하겠습니다.

네 다시 한 번 앞선 블로그에서 퍼왔습니다. L1과 L2를 동시에 담아 두었기에 이용 안 할 수가 없네요. 네 앞서 설명했던 L1, L2 regularization이 나왔습니다. 손실함수를 설정할 때 오차제곱합(가장 많이 쓰이는 손실함수라 그냥 이것으로 이야기하겠습니다.)에 각각의 norm을 더한 것으로 설정합니다. 그러면 W를 업데이트할 때, 손실함수의 W에 대한 gradient가 더 커질 것이고, 따라서 W는 작은 값으로 갱신되는 것입니다. SGD를 수식으로 표현한 식과 연관지어 생각하면 좋겠네요. 네 란다와 같은 우리가 설정해줄 하이퍼 파라미터는 이제 더 이상 설명해드리지 않아도 될 것이라 생각합니다. 아 책에서는 1/2를 곱했던데 사실 큰 차이는 없습니다. 어차피 란다를 설정하기도 하고 미분때문에 1/2를 주로 쓰지만 특정 논문에서는 1/N으로 쓰기도 하니까요. 다음 코드를 돌려 그 결과를 확인해 봅시다.
import os
import sys
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train = x_train[:300]
t_train = t_train[:300]
weight_decay_lambda = 0.1
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10,
weight_decay_lambda=weight_decay_lambda)
optimizer = SGD(lr=0.01)
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
optimizer.update(network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("epoch:" + str(epoch_cnt) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()MINIST를 불러오고, 람다 설정하고, 네트워크 불러오고, 옵티마이저로 SGD 이용하고, 에포크와 사이즈들을 설정하고, 리스트를 불러온 후 착실하게 수행했습니다. 이 코드에 weight decay가 어딨냐구요? 람다를 0.1로 설정한 부분입니다. MultilayerNet코드를 살펴보면 기본값이 0입니다. 즉 람다를 설정하지 않으면 0이 곱해지니 손실함수에 norm을 더할 일이 없어 가중치 감소를 사용하지 않고 람다를 설정하면 비로소 가중치 감소를 사용할 수 있는 것이죠. 궁금하신 분은 한 번 코드를 찾아 살펴보시기 바랍니다.
드롭아웃
자 이제 거의 끝을 향해 가고 있습니다. 바로 드롭아웃입니다. 아이디어는 간단합니다. 훈련 때 무작위로 히든 레이어의 뉴런을 삭제합니다. 훈련 때는 삭제하지만 테스트 때는 모든 뉴런을 제대로 사용하니 훈련 데이터에 치중하지 않을 수 있습니다. 간단하고 효과적이며 이 또한 사랑받는 오버피팅 방지 방법입니다. 가중치 감소보다 효과가 좋습니다. 신경망이 복잡할수록요.
class Dropout:
"""
http://arxiv.org/abs/1207.0580
"""
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:간단하게 설명하면 순전파시에 drop ratio보다 크면 흘려보내고 그렇지 않으면 흘려보내지 않는 것입니다. x와 같은 배열에 self.mask를 만들고, if 조건문을 이용하여 self.mask가 ratio보다 큰 경우만을 참값으로 남겨둡니다. 그 후 참이면 x와 self.mask를 곱해서 참값인 부분만 남겨두고 아니면 x와 1-self.mask (이러면 참이 아닌 부분이 0값을 갖겠죠!)를 곱해 없애버리고 역전파시에도 마찬가지로 행동합니다.
하이퍼 파라미터 찾기!
적절한 하이퍼 파라미터를 찾기 위해 우리는 크게 두 가지 방식에 대해 생각해 볼 필요가 있습니다. 어떻게 최적화하지? 그리고 내가 구한게 정말 잘 구한 것인가? 이렇게 두가지로 말이죠. 후자에 경우에 검증 데이터를 새로 만들어 (일반적으로 훈련 데이터와 테스트 데이터로 나누는데 훈련이 끝난 후 테스트를 하기 전 하이퍼 파라미터를 조정하기 위한 검증데이터를 새로 만드는 것입니다.) 적절한지 살펴봅니다. 학습을 시킬 때 하이퍼 파라미터는 애초에 정하고 시작하는 것이니 학습시에 적절한 값을 찾아주는 것이 아닙니다. 따라서 훈련이 적절히 끝난 모델에 하이퍼 파라미터 값을 미세하게 수정해서 조금씩 성능을 평가하는 것이죠.
후자에 대해선 나름 괜찮은 아이디어로 해결했지만, 솔직히 하이퍼 파라미터의 최적값...은 그 누구도 알 수 없다는게 맞다고 저는 생각합니다. 그냥 범위를 설정하는게 우리가 할 수 있는 최선이에요. 책에서 나온 하이퍼 파라미터 최적화도 같은 맥락입니다. 베이지안 네트워크 (BNN)은 요새 딥러닝에서 활발하게 연구되고 있는 분야입니다. 베이즈 정리에서 기반한 베이지안 통계학을 조금 공부해야 이해가 가능한 부분인데 간단하게 이야기하자면 베이즈 정리를 이용하면 사후확률과 사전확률에 대해 이야기할 수 있습니다. 이 사후확률의 분포를 베이즈 정리를 이용하여 좀 더 잘 찾아보자가 베이지안 딥러닝의 핵심입니다. 흔히 머신러닝에서 분류작업에 있어 좋은 효과를 보이고 있습니다. 사후분포가 사전분포와 우도의 곱에 비례한다는 것을 시작으로 매개변수 설정에까지 이른다는 것인데 이를 이해하기 위해선 헤시안 계산부터 이해되지 않는 수식까지 솔직히 베이지안을 이용해 어떻게 최적화할것인가에 대해 설명하기엔 제가 너무 역부족이라 자세한 설명은 더 하지 않겠습니다.
최적화가 쉽지 않은 것은 맞지만 대략적으로는 가능하다고 말씀 드렸습니다. 그에 대해 책에서 소개한 아이디어를 소개해드리면, 하이퍼 파라미터의 범위를 로그스케일로 제한해서 생각합니다. 10의 배수차이로 범위를 나타내는 것을 의미합니다. 가중치와 학습률의 범위 설정에 대해 구체적으로 언급이있는데 왜 저런 값이 나왔는지는 잘 모르겠으나 제가 논문을 읽을 때마다 많은 논문들에서 학습률을 0.01로 시작해 점차 낮추는 방식으로 많이들 이용했던 것을 기억합니다. 0.005 부근에서 좋은 효과를 내곤했는데, 아마 경험적으로 대부분 범위내에서 좋은 효과를 나타낸 결과가 많았으니 쓰지 않았을까 싶네요.
참고자료: 밑바닥부터 시작하는 딥러닝, https://blog.naver.com/tlsfkaus4862/222344225931
