Azure Blob Storage
클라우드에서 많은 양의 비정형 데이터를 Blob(이진 대형 개체)로 저장할 수 있는 서비스.
Blob은 데이터 파일을 클라우드 기반 스토리지에 최적화된 형식으로 저장하는 효율적인 방법이며, 애플리케이션은 Azure Blob Storage API를 사용하여 데이터를 읽고 쓸 수 있다.
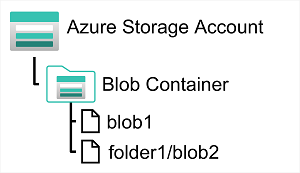
Azure Storage 계정에서 Blob 컨테이너에 저장한다. 관련 Blob을 합께 그룹화하는 방법을 제공한다.
폴더를 가상이므로 폴더 수준 작업을 수행하여 액세스를 제어하거나 대량 작업을 수행할 수 없다.
형식
Block Blob
블록 집합으로 처리된다. 각 블록의 크기는 최대 100MB까지이며 최대 5만개의 블록을 포함할 수 있으며, 최대 4.7TB 이상의 크기를 제공한다. 블록은 개별 단위로 읽거나 쓸 수 있는 가장 작은 데이터 양이며 자주 변경되지 않는 큰 불연속 이진 개체를 저장하는데 가장 적합하다.
Page Blob
고정 크기 512바이트 페이지의 컬렉션으로 구성된다. 임의 읽기 및 쓰기 작업을 지원하는데 최적화 되어 있다. 필요한 경우 단일 페이지의 데이터를 가져오고 저장할 수 있다. 최대 8TB의 데이터를 보유할 수 있다. Azure는 가상 머신의 가상 디스크 스토리지를 구현한다.
Add Blob
추가 작업을 지원하는데 최적화된 블록 Blob이다. 추가 Blob 끝에 블록을 추가만 할 수 있으며, 기존 블록의 업데이트나 삭제는 지원되지 않는다. 각 블록의 크기는 4MB가 최대이며, 최대크기는 195GB가 넘는다.
액세스 계층
핫 계층
기본값이다. 자주 액세스 하는 Blob에 사용한다. 고성능 미디어에 저장된다.
쿨 계층
핫 계층에 비해 성능이 낮고 스토리지 비용이 줄어든다. 자주 액세스하지 않는 데이터에는 쿨 계층에 사용한다. 새로 만든 Blob은 처음에는 자주 액세스하지만 시간이 지나면 액세스가 줄어드는 것이 일반적이다.
이러한 상황에서 핫 계층에 Blob을 만들었다가 나중에 쿨계층으로 마이그레이션 할 수 있다.
보관 계층
스토리지 비용이 가장 저렴하지만 대기 시간이 증가한다. 보관 계층은 손실되면 안되지만 드물게 필요한 기록 데이터를 위한 것이다. 보관 계층은 사실상 오프라인 상태로 저장된다. 보관 계층에서 Blob을 검색하려면 액세스 계층을 핫 또는 쿨로 변경해야 합니다. Blob이 리하이드레이션이 되며 프로세스가 완료되면 Blob을 읽을 수 있다.
Azure DataLake Storage Gen2
Azure Data Lake Store(Gen1)는 분석 데이터 레이크용 계층적 데이터 스토리지를 위한 별도의 서비스로, 파일에 저장된 정형, 반정형 및 비정형 데이터를 사용하는 소위 빅 데이터 분석 솔루션에서 자주 사용된다. Azure Data Lake Storage Gen2는 Azure Storage에 통합된 이 서비스의 최신 버전이며, 이를 통해 계층적 파일 시스템 기능 및 Azure Data Lake Store의 주요 분석 시스템과의 호환성과 결합된 Blob 스토리지의 확장성과 스토리지 계층의 비용 제어를 활용할 수 있다.
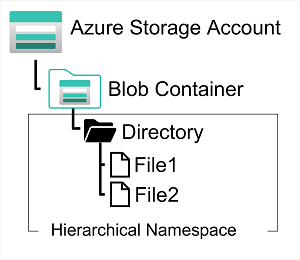
Azure Data Lake Store Gen2 파일 시스템을 만들려면 Azure Storage 계정의 계층 구조 네임스페이스 옵션을 사용해야 한다. 스토리지 계정을 처음 만들 때 이 작업을 수행하거나 Data Lake Gen2를 지원하도록 기존 Azure Storage 계정을 업그레이드할 수 있다. 그러나 업그레이드는 단방향 프로세스이며 Blob 스토리지에 계층 구조 네임스페이스를 지원하도록 스토리지 계정을 업그레이드한 후에는 단일 구조 네임스페이스로 되돌릴 수 없다.
Azure Files
Azure Files는 기본적으로 온-프레미스 조직에서 여러 사용자가 문서 및 기타 파일을 사용할 수 있도록 하는 것과 같이 클라우드 기반 네트워크 공유를 만드는 방법. 조직은 Azure에서 파일 공유를 호스트하여 하드웨어 비용 및 유지 관리 오버헤드를 제거하고 파일에 대한 고가용성 및 확장 가능한 클라우드 스토리지를 활용할 수 있다.
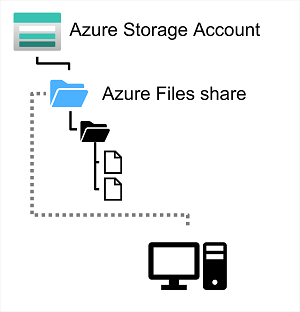
스토리지 계정에서 Azure File Storage를 만든다. Azure Files를 사용하면 단일 스토리지 계정에서 최대 100TB의 데이터를 공유할 수 있다. 이 데이터는 계정의 여러 파일 공유에 분산할 수 있다. 단일 파일의 최대 크기는 1TB이지만 할당량을 설정하여 각 공유의 크기를 이 수치 이하로 제한할 수 있다. 현재 Azure File Storage는 공유 파일당 최대 2,000개의 동시 연결을 지원한다.
Azure Files는 두 가지 일반적인 네트워크 파일 공유 프로토콜을 지원한다.
- SMB(서버 메시지 블록) 파일 공유는 여러 운영 체제(Windows, Linux, macOS)에서 일반적으로 사용된다.
- NFS(네트워크 파일 시스템) 공유는 일부 Linux 및 macOS 버전에서 사용됩니다. NFS 공유를 만들려면 프리미엄 계층 스토리지 계정을 사용하고 공유에 대한 액세스를 제어할 수 있는 가상 네트워크를 만들고 구성해야 한다.
Azure table
Azure Table Storage는 키/값 데이터 항목이 포함된 테이블을 사용하는 NoSQL 스토리지 솔루션입니다. 각 항목은 저장해야 하는 데이터 필드의 열이 포함된 행으로 표현
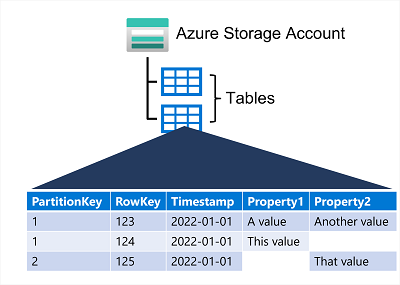
Azure 테이블을 사용하면 반정형 데이터를 저장할 수 있다. 테이블의 모든 행에는 고유한 키(파티션 키 및 행 키로 구성됨)가 있어야 하며, 테이블에서 데이터를 수정하면 타임스탬프 열에 수정한 날짜 및 시간이 기록된다.
반적으로 비정규화되며, 각 행은 논리적 엔터티의 전체 데이터를 보유한다.
빠르게 액세스할 수 있도록 테이블을 파티션으로 분할한다. 분할은 공통 속성 또는 파티션 키를 기준으로 관련 행을 그룹화하는 메커니즘이다. 동일한 파티션 키를 공유하는 행은 함께 저장된다.
- 파티션은 서로 독립적이며, 파티션에 행이 추가되거나 제거됨에 따라 확장 또는 축소될 수 있다. 테이블은 원하는 수만큼 파티션을 포함할 수 있다.
- 데이터를 검색할 때 검색 조건에 파티션 키를 포함할 수 있다. 이렇게 하면 검사할 데이터 볼륨의 범위를 좁히는 데 도움이 되고, 데이터를 찾는 데 필요한 I/O(입력 및 출력 작업 또는 읽기 및 쓰기)의 양이 줄어들어 성능이 향샹된다.
Azure Cosmos DB
개발자가 여러 종류의 일반적인 데이터 저장소 프로그래밍 의미 체계를 사용하여 Cosmos DB의 데이터로 작업할 수 있도록 하는 여러 API를 지원한다. 내부 데이터 구조가 추상화 되었기 때문에 개발자는 Cosmos DB를 사용하여 이미 익숙한 API를 통해 데이터를 저장하고 쿼리할 수 있다.
사용하는 경우
확장성이 뛰어난 DB 관리 시스템이며 컨테이너에 파티션 공간을 자동으로 할당하며, 각 파티션의 크기는 최대 10GB까지 늘릴 수 있습니다.인덱스는 자동으로 생성 및 유지 관리 된다.
- IoT 및 텔레매틱스. 이러한 시스템은 일반적으로 자주 버스트되는 작업을 통해 많은 양의 데이터를 수집한다. Cosmos DB는 이 정보를 빠르게 받아 저장할 수 있다. 그런 다음 Azure Machine Learning, Azure HDInsight, Power BI와 같은 분석 서비스에서 데이터를 사용할 수 있다. 또한 데이터가 데이터베이스에 도착할 때 트리거되는 Azure Functions를 사용하여 실시간으로 데이터를 처리할 수 있다.
- 소매 및 마케팅. Microsoft는 Windows 스토어 및 Xbox Live의 일부로 실행되는 자체 전자 상거래 플랫폼에 CosmosDB를 사용한다. 소매 업계의 경우 카탈로그 데이터 저장에, 주문 처리 파이프라인의 경우 이벤트 소싱에도 사용된다.
- 게임. 데이터베이스 계층은 게임 애플리케이션의 중요한 구성 요소다. 오늘날의 게임은 모바일/콘솔 클라이언트에서 그래픽 처리를 수행하지만 게임 내 통계, 소셜 미디어 통합 및 고득점 순위표와 같은 사용자 지정되고 개인 설정된 콘텐츠를 제공하기 위해 클라우드에 의존한다. 매력적인 인게임 환경을 제공하기 위해서는 몇 밀리초 단위의 읽기 및 쓰기 대기 시간이 필요한 경우가 많다. 게임 데이터베이스는 속도가 빨라야 하며 신규 게임 출시 및 기능 업데이트 동안 요청 속도의 대량 스파이크를 처리할 수 있어야 한다.
- 웹 및 모바일 애플리케이션. Azure Cosmos DB는 일반적으로 웹 및 모바일 애플리케이션 내에서 사용되며 소셜 상호 작용을 모델링하여 타사 서비스와 통합하고 풍부한 개인 설정 환경을 빌드하는 데 적합하다. Cosmos DB SDK는 인기 있는 Xamarin 프레임워크를 사용하여 다양한 iOS 및 Android 애플리케이션을 빌드하는 데 사용할 수 있다.
API 식별
PostgreSQL, MongoDB 및 Apache Cassandra를 비롯한 선호하는 오픈 소스 데이터베이스 엔진을 사용하여 애플리케이션을 빠르게 빌드하고 마이그레이션할 수 있다.
Azure Cosmos DB for NoSQL
문서 데이터 모델 작업을 위한 Microsoft의 네이티브 비관계형 서비스, JSON 문서 형식의 데이터를 관리하며 NoSQL 데이터 스토리지 솔루션임에도 불구하고 SQL 구문을 사용하여 데이터를 사용
Azure Cosmos DB for MongoDB
데이터가 BSON(Binary JSON) 형식으로 저장되는 인기 있는 오픈 소스 데이터베이스. 개발자가 MongoDB 클라이언트 라이브러리를 사용하여 Azure Cosmos DB의 데이터로 작업하고 코드를 사용할 수 있다.
Azure Cosmos DB for PostgreSQL
확장성 있는 앱을 빌드하는 데 도움이 되도록 데이터를 자동으로 분할하는 전역으로 분산된 관계형 데이터베이스인 네이티브 PostgreSQL. PostgreSQL은 데이터의 관계형 테이블을 정의하는 RDBMS(관계형 데이터베이스 관리 시스템).
Azure Cosmos DB for Table
Azure Table Storage와 유사한 키-값 테이블의 데이터로 작업하는 데 사용.Azure Table Storage보다 뛰어난 확장성과 성능을 제공.
Azure Cosmos DB for Apache Cassandra
열 패밀리 스토리지 구조를 사용하는 인기 있는 오픈 소스 데이터베이스인 Apache Cassandra와 호환된다. 열 패밀리는 관계형 데이터베이스의 테이블과 유사하며 모든 행에 동일한 열을 포함해야 하는 것은 아니다.
Azure Cosmos DB for Apache Gremlin
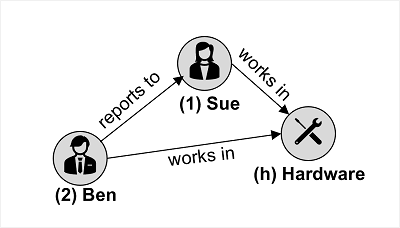
그래프 구조의 데이터와 함께 사용되며 엔터티가 연결된 그래프에서 노드를 형성하는 꼭짓점으로 정의된다.
이미지의 예제에서는 두 종류의 꼭짓점(직원 및 부서)과 이를 연결하는 에지(직원 “Ben”은 직원 “Sue”에 보고하고 두 직원 모두 “하드웨어” 부서에서 근무)를 보여 준다.
Gremlin 구문에는 꼭짓점 및 에지에서 작동하는 함수가 포함되어 있어 그래프에서 데이터를 삽입, 업데이트, 삭제 및 쿼리할 수 있다. 예를 들어 다음 코드를 사용하여 ID가 1(Sue)인 직원에게 보고하는 Alice라는 새 직원을 추가할 수 있다.

뛰어난 글이네요, 감사합니다.