ImageNet Classification with Deep Convolutional
Neural Networks (2012)
Abstract
2012년도 LSVRC의 우승 알고리즘인 토론토 대학교 슈퍼비전팀의 AlexNet에 대한 논문입니다. 기존 알고리즘보다 오류율을 약 10%p 가량 낮춘 것으로 유명합니다.
We trained a large, deep convolutional neural network to classify the 1.2 million
high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes.
Introduction
2012년 당시, 객체 인식(Object Recognition)은 머신러닝 접근 방식을 필수적으로 사용하기 시작했습니다. 저자는 성능을 향상시키기 위해 더 많은 데이터셋의 수집과, 더 강력한 모델과(learn more powerful models), 과적합을 방지하기 위한 더 나은 기술이 필요하다는 점을 깨달았습니다.
그러나 문제는 NORB나 Caltech-101/256, CIFAR-10/100 같은 기존의 데이터셋은 크기가 너무 작았다는 점입니다. MNIST 인식 작업 같은 경우에는 오류율은 낮지만 데이터셋이 너무 작아서 현실적인 환경에 적용이 어려왔습니다. 그런데 2010년도 내외가 되어서야 이 논문에 사용된 ImageNet과 같은 대형 데이터셋이 구축되기 시작합니다.
이런 큰 데이터셋을 학습하려면 큰 학습 능력(Capacity)을 가진 모델이 필요했습니다. 심지어 ImageNet을 통해서도 커버할 수 없는 부분을 커버하기 위해, 단순히 데이터셋이 가진 그 이상의 것을 스스로 학습하는 모델이 필요했습니다. 이때 필요한 것이 사전지식(prior knowledge)을 가진 모델인데, 바로 Convolutional neural network, 즉 CNN입니다.
이 논문은 저자가 CNN을 도입해 ILSVRC 사상 가장 크고 또 성능 좋은 컨볼루션 신경망을 훈련시켰다는 점을 입증하고 있습니다.
+) 이때 당시에는 AlexNet 훈련에 5~6일이 걸렸다고 하네요!
The Dataset
ImageNet입니다.
22,000개의 category, 1500만 개 이상의 label이 부여된 가변크기의 이미지 데이터셋입니다.
이 ImageNet을 가지고 LSVRC가 열리는데, 지금은 ViT이 (아마?) 선두를 달리는 것으로 알고 있습니다.

저자들은 고정된 크기의 256*256 이미지로 다운샘플링했다고 밝히고 있습니다.
The Architecture
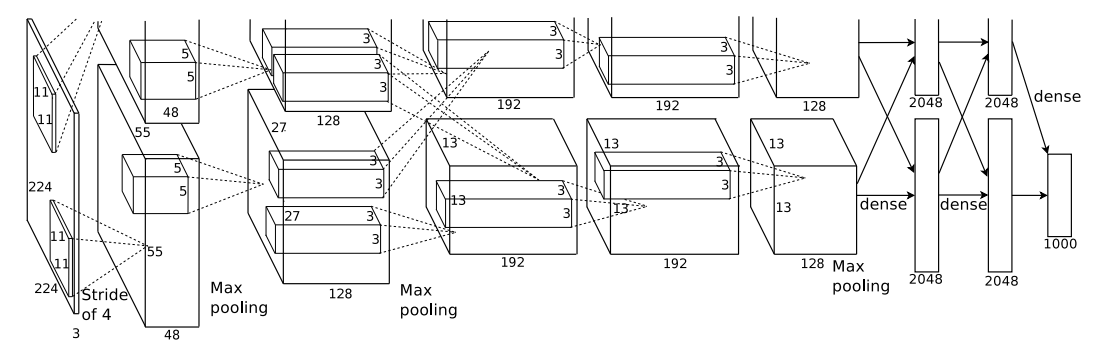
ImageNet의 아키텍처입니다.
총 8개의 레이어 중, 5개가 Convolutional Layer, 3개가 Fully-Connected Layer입니다.
저자들은 AlexNet 아키텍처에 특이한 점 네 가지가 있다고 밝히고 있는데, 하나씩 알아보도록 하겠습니다.
1. ReLU Nonlinearity : 전통적인 뉴런 모델보다 빠른 훈련을 위해 채택되었습니다.
2. Training on Multiple GPUs : 다중 GPU를 사용해 메모리의 한계를 극복하고자 했습니다. 병렬처리하되, 특정 레이어에서만 정보를 교환합니다.
3. Local Response Normalization : 각 뉴런의 활성화 정도를 조절합니다.
4. Overlapping Pooling : 같은 커널 맵의 인접한 뉴런 그룹의 출력을 요약합니다.
Reducing Overfitting
과적합 방지를 위해서 두 가지 방법을 사용했습니다.
하나는 흔히 말하는 Data Augmentation이고, 나머지 하나는 Dropout입니다.
1. Data Augmentation : Image Translation/Horizontal Reflection, RGB Channel 강도 변경
2. Dropout : 훈련 중에 50% 확률로 뉴런을 그냥 꺼버리는 것입니다. 신경망이 매번 다른 구조로 데이터를 처리할 수 있게 합니다.
Results
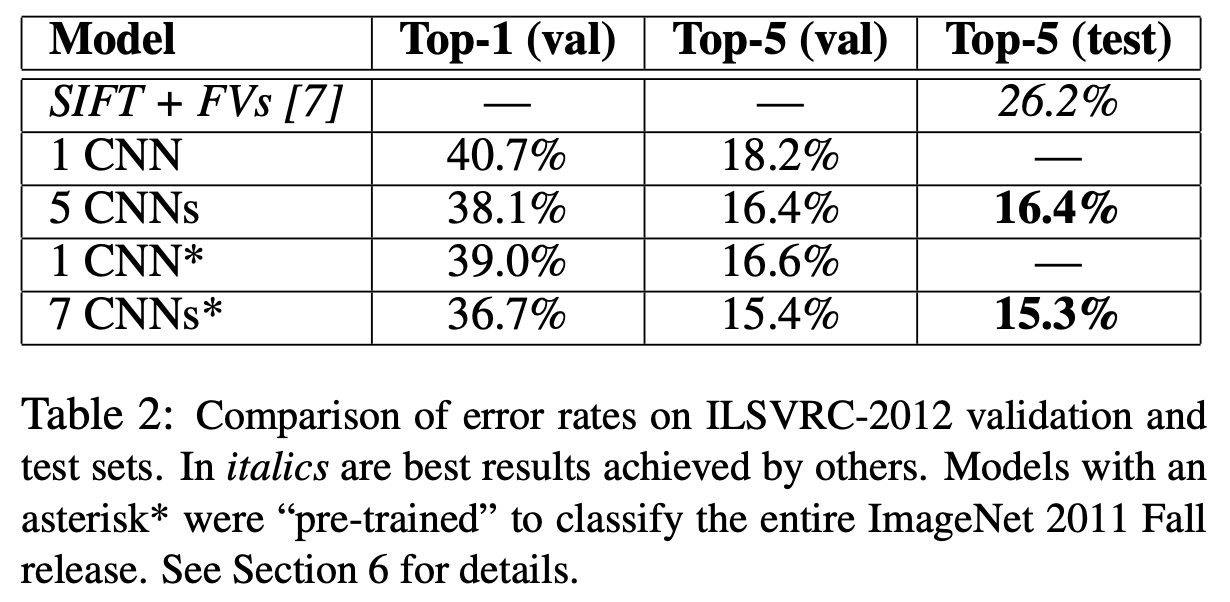
모델의 error rate입니다. Top 1의 경우에는 생각보다 오류율이 높은데, 이것은 아래 정성평가 결과를 보면 이유를 알 수 있습니다.

정성평가 결과를 담은 이미지입니다.
- 오른쪽의 경우 모델이 반환한 top 5 레이블을 보여줍니다. 대부분 잘 반환하고 있으며 mite와 같이 중심에서 벗어난 경우에도 잘 인식하고, grille과 cherry 케이스의 경우 초점이 어디에 맞춰져있느냐에 따라 다르게 해석될 수 있음을 주장합니다.
+) 제가 보기엔 dalmatian이 정답 레이블로 보이는데, ImageNet은 단일 레이블을 채택하고 있는 걸까요? 같습니당 궁금하네요 - 왼쪽의 경우 모델이 가장 인접한 이미지라고 반환하는 이미지들이 사실, 픽셀상으로는 인접하지 않다는 것을 보여줍니다. 이것이 뜻하는 바는 모델이 단순히 픽셀 값 뿐만 아니라 이미지의 진정한 의미를 이해하고 있다는 것입니다.
Discussion
Takeaways
-
대규모 심층 신경망의 성능: 저자는 순수 지도 학습을 사용하여 뛰어난 성과를 달성할 수 있는 크고 깊은 컨볼루션 신경망의 능력을 입증했습니다.
-
신경망 깊이의 중요성: 신경망에서 단 하나의 컨볼루션 층을 제거하면 성능이 저하되며, 특히 중간 층을 제거할 경우 top 1 성능이 약 2% 감소하는 것으로 나타났습니다. 이는 신경망의 깊이가 성능에 중요한 역할을 한다는 것을 보여줍니다.
Discussions
-
비지도 훈련의 부재: 저자는 실험을 단순화하기 위해 비지도학습 사전 훈련을 사용하지 않았으나, 사전 훈련이 도움이 될 것이라고 생각하고 있습니다.
-
Human Visual System까지! : 인간의 시각 시스템을 따라잡기까지 갈 길이 멀다고 언급하고 있습니다. 다음으로 다룰 ResNet부터는 인간의 능력을 뛰어넘었다고 평가받고 있습니다.
