paper link: https://arxiv.org/pdf/2309.03905.pdf
CVPR 2023에 Meta에서 낸 논문
0. Abstract
- image, text, audio, depth, thermal, IMU data 등 6가지 다른 modality의 joint embedding을 학습하는 IMAGEBIND 제안
- cross-modal retrieval, composing modalities with arithmetic, cross-modal detection/generation을 포함한 새로운 응용 프로그램을 즉각적으로 가능하게 함
- ImageBind는 vision, non-vision task에 대한 vision model을 평가하는 새로운 방법으로 사용될 수 있음
1. Introduction
- 딥러닝 모델: latent space에 data를 embedding하는 func로 볼 수 있음
- 아직까지 세 가지 이상의 다른 modality의 데이터들을 하나의 embedding space로 묶는 것은 아직까진 어려운 일
- ImageBind
- 6가지 modality를 하나의 joint embedding space로 embedding하는 모델
- 학습 데이터에 포함되지 않은 데이터에 대한 task인 cross-modal zero0shot recognition task에서 ImageBind는 일부 supervised specialist model을 뛰어넘음

- Cross-Modal Retrieval
- 기존에는 cross-modal retrieval을 학습시키기 위해 image-to-text retrival의 경우 (image, text) 쌍이, audio-to-image retrieval이면 (audio, image) 쌍이 필요했음
- ImageBind에서 데이터는 modality에 관계없이 같은 공간에 embedding되므로 이를 이용하여 다른 modal 간의 검색 수행 가능
- Embedding-Sapce Arithmetic
- embedding된 데이터의 벡터를 사용해 산술 연산 수행 가능
- 새 사진 + 파도 소리 ⇒ 바닷가에 있는 새의 이미지 검색한 결과
- Audio to Image Generation
- ImageBind의 embedding vector를 다른 생성 모델과 결합해 콘텐츠 생성에 활용 가능
2. Related Work
- Language Image Pre-training
- CLIP, ALIGN, Florence같은 모델은 대규모의 image-text pair를 수집해 contrastive learning을 활용해 같은 공간에 임베딩하여 좋은 zero-shot performance를 보임
- CoCa, Flamingo, LiT 같은 모델은 contrastive learing을 통해 다른 modality들을 묶어 좋은 성능 보임
- 이러한 모델들은 대부분 image-text에 집중했지만 ImageBind는 더욱 다양한 모델에서 zero-shot recognition 수행 가능
- Multi-Modal Learning
- 기존 연구는 각 다른 modality 간의 학습을 supervised learning, self-supervised learning의 방법으로 해결함
- ImageBind는 명시적인 multimodal data pair 없이 이미지를 활용하여 다양한 modality를 통합
- Feature Alignment
- pre-trained CLIP
- 다양한 모델들의 teacher model로 사용됨
- image-text의 joint embedding은 detection, segmentation, mesh animation등 다양한 분야에서 성공 거둠
- PointCLIP
- pre-trained CLIP encoder에 3D point cloud를 2D Depth map 형식으로 입력해 3D Recognition에 사용할 수 있음을 보였다
- 신경망 기반 language translation
- 각 언어들 모두 같은 공간에 embedding해 각 언어 간의 pair 없어도 번역이 가능함을 보임
- pre-trained CLIP
3. Method

3.1. Preliminaries
- Aligning specific pairs of modalities
- contrastive learning은 연관된 sample(positive)와 연관되지 않은 sample(negative)들의 pair를 이용해 임베딩 공간을 학습하는 대표적인 방법
- 이를 활용해 모델은 (image, text), (audio, text), (image, depth) 등 다양한 modality pair를 align할 수 있음
- 그러나 이러한 방법은 modality pair가 존재하는 경우에만 joint embedding을 학습할 수 있어서 (video, audio)에서 학습된 embedding은 (image, text)에 바로 사용할 수 없음
- Zero-shot image classification using text prompts
- CLIP은 aligned된 (image, text) embedding space에서 zero-shot classification 문제로 인기를 얻음
- 데이터셋에 포함된 클래스에 대한 텍스트 설명이 주어지면 입력된 이미지가 어떤 설명에 해당하는지 분류하는 것 → 입력 이미지의 embedding vector와 유사한 text 설명을 찾는 것으로 수행됨
3.2. Binding modalities with images
- ImageBind는 이미지 와 다른 modality 의 pair 을 사용하여 joint embedding을 학습
- 가장 큰 비율을 차지하는 것은 (image, text) pair: data size 가장 많고, 많은 연구 통해서 성능 이미 검증됨
- 이미지 와 다른 modality sample 가 주어졌을 때 각각 , 로 embedding
- 는 각 modality를 encoding 하기 위한 network
- 이후 InfoNCE loss 계산
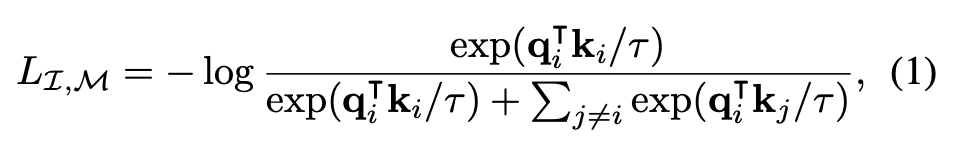
- : positive pair로 같은 의미를 갖는 image embedding 와 다른 modality의 embedding 의 내적으로, 두 임베딩 유사하면 1에 가까움
- : negatibe pair로 mini batch 안에서 와 pair를 이루지 않는 다른 modality의 embedding과의 내적
- symmetric loss 를 활용해 각 modality와 image 간의 joint embedding space를 학습
- Emergent alignment of unseen pairs of modalities
- ImageBind는 각 modality를 image 기준으로 align함. 즉, pair는 modality 을 image와 align하는 데 사용됨
- 저자는 과 를 통해 를 통해 각각 image와 align하는 것이 두 modality도 algin하는 것을 발견
- 이를 통해 ImageBind는 별도의 학습 없이 다양한 zero-shot, cross-modal retrieval task를 수행할 수 있게 됨
- 특히 저자들은 zero-shot text-audio classification에서 (audio, text) data pair를 사용하지 않고 SOTA 달성
3.3. Implementation Details
- Image, Video: ViT
- Audio: 128 mel-spectorgram으로 변경 후 ViT
- Thermal image, Depth image: 1-channel image로 처리 후 ViT
- IMU signals: 영상에서 5초간 gyroscope 측정 후 1D convolution 처리하여 얻어진 sequence를 Transformer로
- Text: CLIP의 text encoder
4. Experiments
- 자연스럽게 짝지어지는(Naturally paired) 모달리티 쌍의 데이터셋을 사용
4.1. Emergent zero-shot classification
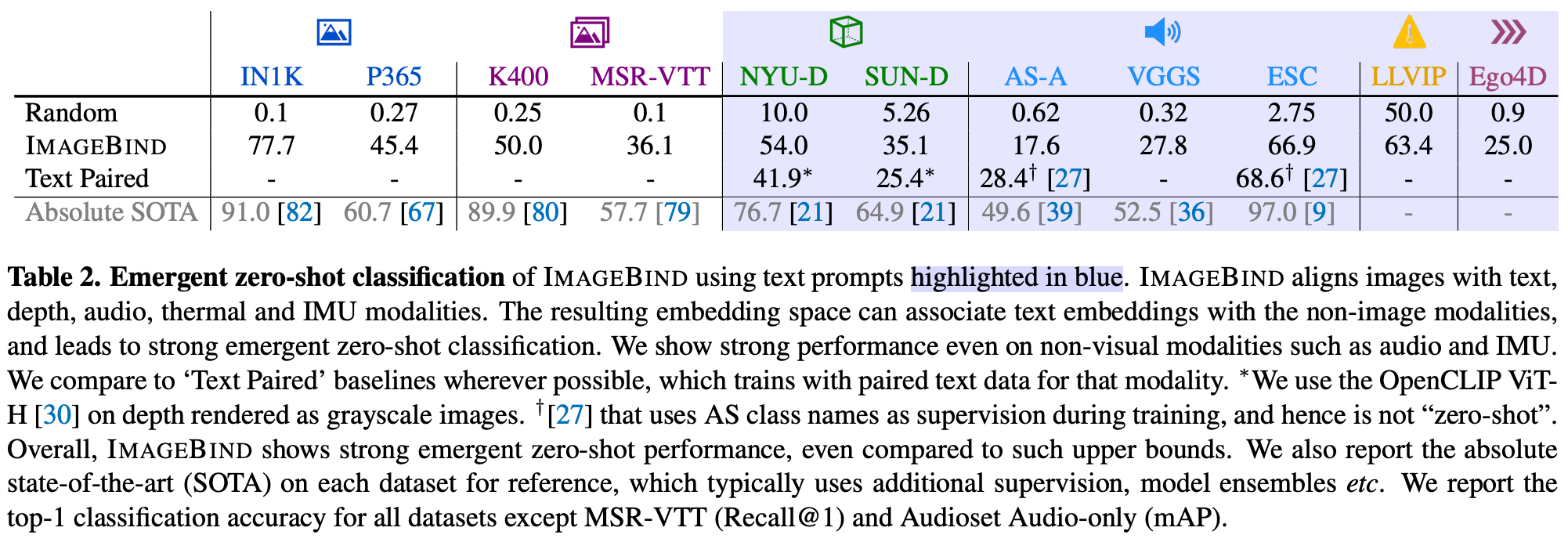
- ImageBind가 학습 과정에서 보지 못한 modality pair를 연관짓는 능력 평가 → 새로운 분야라 baseline X
- 저자는 text, modality pair를 활용해 학습된 모델과의 비교, 지도학습을 통해 얻어진 성능과의 비교를 수행
- 각 벤치마크에서 ImageBind는 강력한 emergent zero-shot classification 성능을 보임
- 일부에서는 supervised model에 가까운 성능
- 특히 audio, IMU 같은 분야에서 높은 성능
4.2. Comparison to prior work

- Zero-shot text to audio retrieval and classification
- ImageBind는 emergent zero-shot model임에도 불구하고, Clotho와 AudioCaps 데이터셋에서 un-supervised based model 중 SPTA 달성
- ESC data에서는 AudioCLIP에 밀리지만, AudioCLIP은 학습 과정에서 AudioSet dataset의 class name을 사용하기 때문에 supervised model임을 고려하면 높은 성능

- Text to audio and video retrieval
- 저자는 MSR-VTT 1k-A benchmark를 수행해 성능 평가
- 오디오만 사용했을 때 ImageBind는 MIL-NCE와 유사한 높은 emergent zero-shot 성능을 보임
- audio, video modality를 함께 사용한 경우 기존 모델을 앞서는 훌륭한 retrieval 성능 보여줌
4.3. Few-shot classification

4.4. Analysis and Applications

- embedding vector 간의 산술 연산 가능
- text based detector를 audio based로 업그레이드 가능
- text vased diffusion model을 audio based로 업그레이드 가능
5. Ablation Study
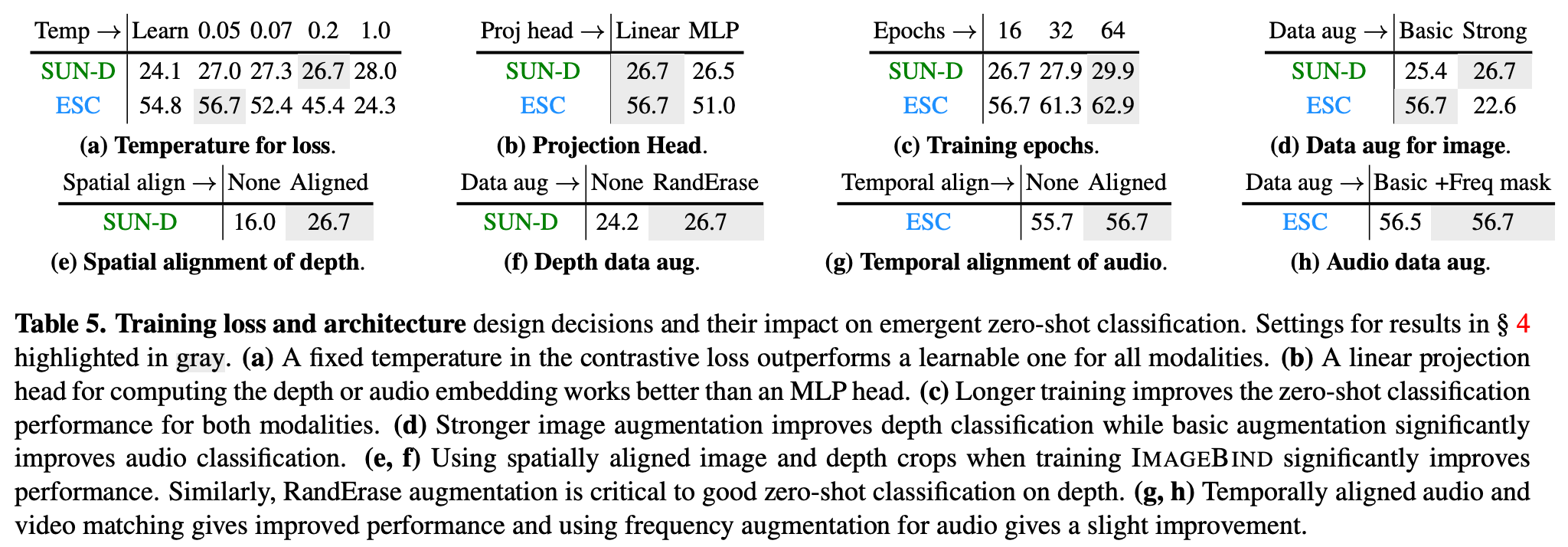
- Contrastive loss에 적용된 temperature : learnable or fixed
- 각 modality의 projection head: linear or 768 hidden MLP
- Data augmentation: crop, color jitter or RandAugment, RandErase
6. Discussion and Limitations
- ImageBind는 여러 modality의 joint embedding space를 학습하는 간단하면서도 실용적인 방법
- 이를 통해 cross-modal retrieval, text-based zero-shot task 등의 emergent alignment task 수행할 수 있게 됨
- multi modality가 조합된 task를 수행하거나, Detic, DALLE-2 같은 일반적인 vision model을 이러한 multi-modal model로 업그레이드 하는 방법을 제시
- emergent zero-shot이라는 새로운 evaluation tool 제안
- 개선 사항
- image alignment loss를 text와 같은 modal 간의 조합 데이터셋(text, IMU) 활용하여 강화
- ImageBind가 별다른 downstream task와 함께 학습되지 않아 specialist model에 비해 성능이 떨어지는 문제 해결
- 각 task를 위한 general purpose embedding 추가 연그
- 새로운 벤치마크 제시(emergent zero-shot task를 새로 정의하였으나, 이에 대한 벤치마크 없음)
