
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
StyleCLIP은 StyleGAN2와 CLIP이 결합한 모델로 2021년 ICCV에 Oral로 발표된 논문이다. 간단하게 latent vector를 text로 제어해서 새로운 이미지를 생성하는 모델이다.
paper : StyleCLIP
본격적인 논분 리뷰에 앞서 CLIP이 뭔지부터 간단하게 살펴보자.
Background
CLIP
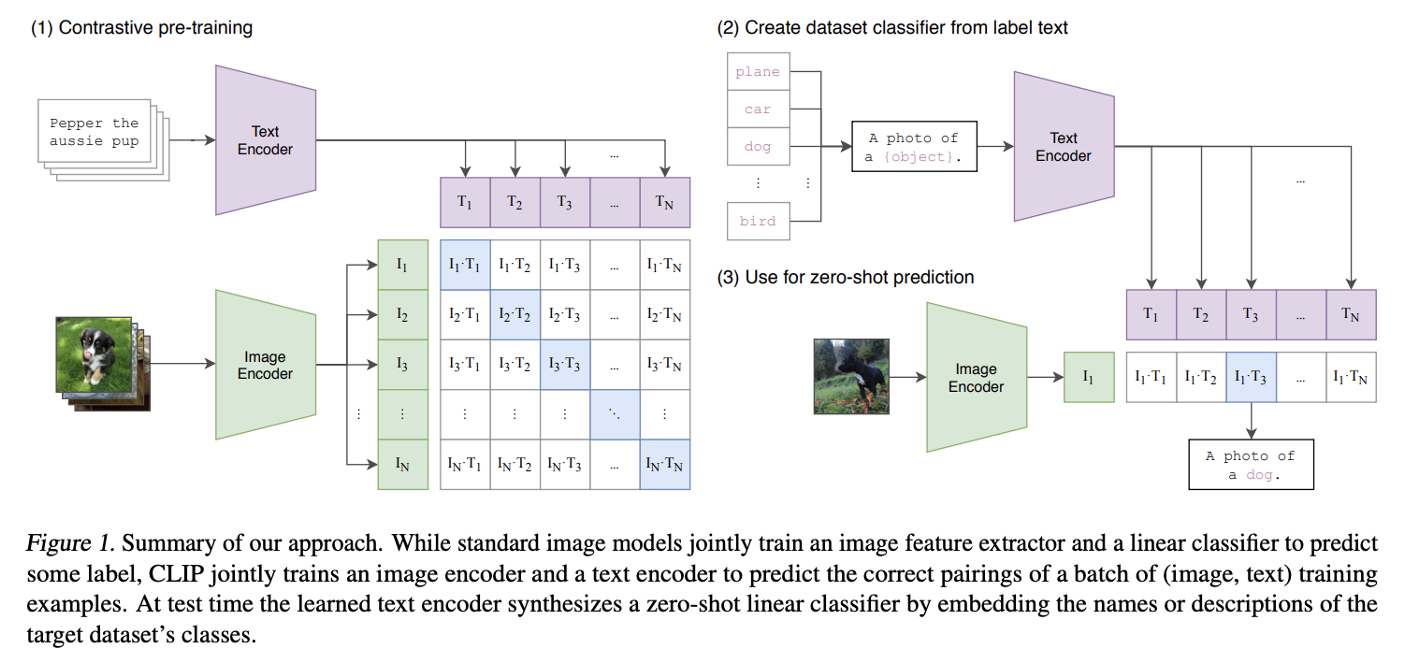
CLIP은 올해 1월 Open API에서 공개한 모델이다. 기존의 CNN은 이미지의 특징을 뽑아내고 분류하고자 하는 클래스의 개수에 맞춰서 그에 맞게 분류를 하는 형태를 가지고 있는 반면에 CLIP은 이미지와 text를 멀티 모달로 동시에 고려한다.
데이터셋을 구성하고 있는 데이터는 웹 크롤링을 사용해 텍스트, 이미지를 한 쌍으로 하고 총 4억개의 데이터로 구성된다.
아키텍처를 살펴보면 resnet과 vision transformer를 사용하는 image encoder와 transformer 구조를 사용하는 text encoder로 구성되어 있다.
각각의 이미지와 텍스트가 주어졌을 때 각각의 encoder를 거쳐 어떤 벡터로 각각 변환이 되고 이 두 벡터 사이의 유사도를 학습하는 방식으로 학습이 진행된다. 결과적으로 학습을 마치게 되면 각각 인코딩 된 텍스트 벡터와 이미지 벡터는 비슷한 latent space 상에 존재하는 모델이 되고 inference를 진행할 때는 학습된 텍스트 encoder에 target 데이터 셋의 class 이름이나 설명을 포함시켜 zero-shot lienar classifier로써 적용이 된다.
Introduction

최근에는 다양한 분야에서 StyleGAN의 disentangle한 latent space를 사용해서 image manipulation을 하려는 많은 연구가 진행되고 있다. 이전 연구에선 latent space에서 원하는 image 변형을 위한 latent vector를 발견하는 것은 latent vector를 하나씩 변형해보면서 사람이 직접 검수하거나 annotation된 이미지를 사용하는 방식으로 진행되었다. 그러나 이러한 방식은 노동이 필요하고 추가 데이터가 필요할 때마다 다시 작업을 해야할 뿐만 아니라 이러한 모델을 통한 컨트롤은 기존에 학습되어있는 semantic direction에서만 컨트롤할 수 있기 때문에 사용자의 창의성이나 상상력이 크게 제한된다고 언급한다.
본 논문에서는 수동적인 작업이 필요하지 않고 텍스트에 의해 직관적으로 image control을 가능하게 하기 위해 styleGAN과 CLIP모델을 활용하여 텍스트에 기반한 이미지를 변형시키는 인터페이스를 개발했다.
본 논문에서는 Stylegan과 clip을 combine하는 세가지 테크닉을 소개하는데 각각 Latent optimization, latent mapper, global direction이다.

Method
Latent Optimization

위 식에서 는 StyleGAN의 generator이고 은 와 text 의 embedding vector의 cosine distance를 계산하는 부분이다. cosine distance를 줄이는 방향으로 optimize시켜 manipulation을 진행하기 위한 term이다. 나머지 term인 L2 distance와 identity loss는 w vector를 w source vector와 유사하게 입력 이미지를 embedding 시키는 부분이다.
는 identity loss를 의미한다. 은 pretrained된 arcface를 사용해서 w source와 w의 cosine similarity를 구하고 이를 optimization시키는 term이다. 이 optimization은 gradient descent 방식으로 manipulation을 해결한다.

Latent Mapper
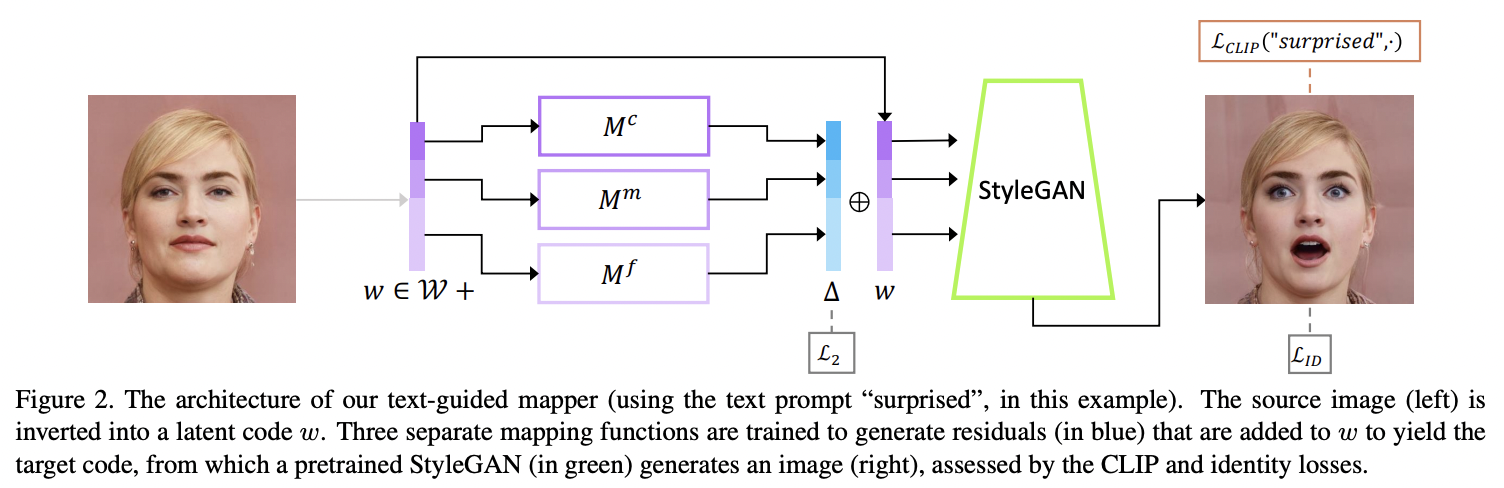
앞의 latent optimization의 단점은 단일 이미지를 편집하는 데 몇 분의 최적화가 필요하며 이 방법은 매개변수 lambda l2나 lambda id 값에 민감하다는 것이다. 그래서 논문에서는 보다 효율적인 latent mapper를 소개한다.
latent mapper는 Auxiliary mapping network를 사용해 이미지에서 원하는 속성을 control한다. mapper는 세가지 다른 정도의 정보에 해당하는 FC Layer로 구성된다. (위의 그림에서 , , 이며 각각 Corse, Medium, Fine style을 의미한다.) 이 mapping network 구조는 기존의 StyleGAN의 mapping network와 동일하지만 8개의 FC layer가 아닌 4개의 FC layer로 구성된다.
Figure2 에서 입력 이미지를 놀라는 표정의 이미지로 변형하고 싶다면 surprise 텍스트를 CLIP 텍스트 인코더를 통해 벡터를 구하고 마찬가지로 놀라는 이미지를 StyleGAN으로 만들어서 이를 StyleCLIP 이미지 인코더에 넣어 벡터를 구한다. 그리고 두 벡터의 코사인 similarity로 loss를 정의한다. 그러면 StyleGAN의 이미지와 텍스트가 서로 매칭이 되도록 학습이 진행된다.
입력 이미지의 latent code는 일 때 mapper는 로 정의된다. latent code는 먼저 mapper로 특정 텍스트 프롬프트 t에 대해 훈련된 다음 manipulation step 를 만드는 데 사용된다. 여기서 는 입력 이미지의 latent embedding이다.
Loss는 다음과 같이 정의된다.

Manipulation의 type과 세부적으로 어떻게 변화하고 싶은지에 따라 세가지 매핑 네트워크의 subset을 훈련하도록 선택할 수 있다.


Global Direction
Global Direction 방식은 텍스트 프롬프트를 styleGAN의 스타일 공간 S에서 global direction으로 매핑한다. 이전의 latent mapper는 추론 시간이 빨라지지만 세밀하게 disentangle한 control이 부족한 모습을 보인다고 이야기 하면서 global direction을 설명한다. 이 테크닉을 사용하면 style space가 다른 Latent space보다 더 많이 disentangle 되기 때문에 세밀한 control이 가능하다고 주장한다.

이미지는 먼저 CLIP의 이미지 encoder를 사용해 style code로 encoding된다. 이렇게 이미지를 encoding한 style code를 로 표시한 후 위 그림과 같이 를 해당 생성된 이미지로 지정하고 텍스트 프롬프트 가 주어졌을 때 StyleCLIP은 형태를 띄게 된다. 여기서 는 이러한 변형의 강도를 결정하고 이 과정에서 다른 측면을 변경하지 않고 원하는 속성이 향상되거나 추가되는 이미지를 생성하도록 하는 것이 global direction의 핵심이다.
이제 를 찾아보자.
style space vector s에서 생성된 이미지 를 latent embedding 라고 하고 조작된 이미지 를 latent embedding 라고 할 때, 여기서의 두 latent vector의 차이 는 CLIP의 텍스트 encoder 로 encoding된 텍스트 프롬프트 latent code의 특정 차이에 일치해야한다는 것을 기반으로 한다. 그래서 두 개의 latent space 사이의 간격을 메우기 위해 latent space 에서 neutral과 속성이 있는 텍스트의 차이를 먼저 프롬프트 엔지니어링을 통해 얻는다. 그 후 embedding된 텍스트와 이미지가 colinearity를 갖는다고 가정하면 이제 목표는 style space에서 control하는 를 찾는 것이 된다.



β는 manipulation에서 disentanglement의 정도를 제어하는 데 사용할 수 있고 threshold가 높으면 control이 더 disentangle해지지만 동시에 control의 시각적 효과가 감소하게끔 한다.
연령과 같은 다양한 상위 수준의 속성은 여러 하위 수준의 속성(회색 머리카락, 주름, 피부색 등)의 조합을 포함하므로 여러 채널이 이와 관련된 이러한 경우 threshold를 낮추는 것이 바람직하다. 이러한 방식으로 disentanglement의 정도를 control하는 능력은 해당 접근 방식에 고유하다. α는 얼마나 많은 변화를 줄지에 관한 것(manipulation strength)이고 β는 채널별 threshold다. β가 높으면 특정한 채널 스타일만 변경되고 낮으면 추가적인 특징도 같이 변경되는 것을 볼 수 있다.
Comparisons & Evaluation
Comparisons & Evaluation

Latent mapper 및 global direction 방법은 TediGAN과 비교했다. 복잡한 속성으로는 trump, 덜 복잡하고 덜 구체적인 속성으로는 모히칸 헤어, 더 단순하고 일반적인 속성은 ‘주름이 없는’것으로 설정해 실험을 진행했다. 실험 결과 latent mapper가 복잡한 속성에 적합하고, global direction은 더 간단하거나 더 일반적인 속성에 충분하다고 결론지었다.
Limitation
해당 논문에서는 한계점을 styleGAN의 generator와 pretrained모델에 의존적인 모습을 보인다고 설명한다. 그에 따라 이미지가 pretrained된 generator의 도메인에 벗어난 것까지 이미지를 control할 수 없다고 설명한다.
마찬가지로 이미지로 채워지지 않은 CLIP 공간 영역에 매핑되는 텍스트 프롬프트는 프롬프트의 의미를 충실히 이행하지 못한다는 한계점이 있다.

Conclusion
해당 논문에서는 stylegan과 CLIP의 latent space 간의 격차를 해소하는 3가지 방법을 제안했다.
-
Latent optimization은 이미지 한 장당 최적화를 수행하기 때문에 특정 이미지, 텍스트마다 몇 분 정도의 시간이 걸리지만 별도의 학습 과정은 필요가 없고
-
Latent mapper는 하나의 텍스트에 대하여 학습이 진행되고 학습이 완료되면 어떤 이미지에도 바로 적용할 수 있다.
하지만 하나의 텍스트에 대해 학습이 되기 때문에 꽤 긴 시간의 학습이 필요하다. -
Global direction은 한 번 direction vector를 찾아놓으면 어떤 이미지가 들어오더라도 바로 그 direction vector를 더하기 혹은 빼기 연산을 하여 결과를 빠르게 구할 수 있다. 하지만 하나의 텍스트에 대해 global direction을 찾기 위해서 3-4시간 가량 소요된다고 한다.

Global direction에서 s는 CLIP Image embedding이 아니라 stylegan2 network의 style parameter를 지칭하는 벡터입니다. 오류가 있는 듯 하여 댓글 남깁니다