트라이(접두사 트리)
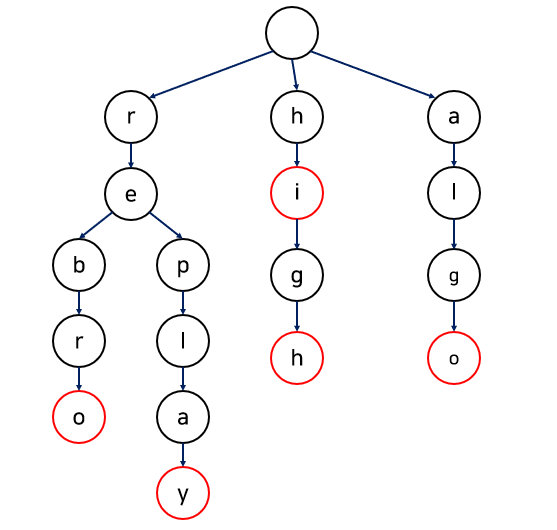
트라이(trie)는 문자열을 검색해 저장된 문자열 중 일치하는 문자열이 있는지 확인하는 데 주로 사용되는 특별한 종류의 트리입니다. 특히 자연어 처리(NLP)분야에서 문자열 탐색을 위한 자료구조로 널리 쓰입니다.트라이는 검색을 뜻하는 'retrieval'의 중간 음절에서 용어를 따왔습니다.
트라이의 사용 목적
사용하는 이유는 문자열의 탐색을 하고자할 때 시간복잡도를 보면 알 수 있습니다. 단순하게 하나씩 비교하면서 탐색을 하는것보다 훨씬 효율적입니다. 단, 빠르게 탐색이 가능하다는 장점이 있지만 각 노드에서 자식들에 대한 포인터들을 배열로 모두 저장하고 있다는 점에서 저장 공간의 크기가 크다는 단점도 있습니다.
구현 방식
트라이는 중첩 객체를 사용해 구현됩니다. 이때 각 노드는 자신과 직접 연결된 자식들을 지니는데 이 자식들은 키 역할을 합니다. 다음 코드에서 보듯이 트라이에는 루트 노드가 존재하는데, 루트 노드는 Trie 클래스의 생성자에서 초기화됩니다.
function TrieNode () {
this.children = {};
this.endOfWord = false;
}
function Trie() {
this.root = new TrieNode();
}트라이에 신규 노드를 삽입할 때 해당 노드가 루트의 자식으로 존재하지 않는 경우 해당 노드를 루트의 자식으로 생성해야 합니다.
Trie.prototype.insert = function (word) {
let current = this.root;
for (let i = 0; i < word.length; i ++) {
let ch = word.charAt(i);
let node = current.children[ch];
if (node === undefined) {
node = new TrieNode();
current.children[ch] = node;
}
current = node;
}
current.endOfWord = true;
}트라이에서 어떤 단어가 존재하는지 검색하기 위해서는 단어의 각 문자를 확인해야 합니다. 이를 위해서 임시 변수 current를 루트에 설정해야 합니다. 검색하고자 하는 단어의 각 문자를 확인함에 따라 current 변수가 갱신됩니다.
Trie.prototype.search = function (word) {
let current = this.root;
for (let i = 0; i < word.length; i ++) {
let ch = word.charAt(i);
let node = current.children[ch];
if (node === undefined) {
return false
}
current = node;
}
return current.endOfWord;
}
let trie = new Trie();
trie.insert("sammie");
trie.insert("simran");
trie.search("simran");
trie.search("fake");
trie.search("sam");트라이로부터 항목을 삭제하기 위해서는 검색 알고리즘이 루트 노드로부터 삭제하고자 하는 단어의 마지막 문자에 도달할 때까지 트라이를 순회해야합니다. 그러고 나서 삭제하고자 하는 단어의 문자에 해당하는 자식 외의 다른 자식을 지니지 않은 각 노드를 삭제해야 합니다.
Trie.prototype.delete = function (word) {
this.deleteRecursively(this.root, word, 0)
}
Trie.prototype.deleteRecursively = function (current, word, index) {
if (index === word.length) {
if (!current.endOfWord){
return false
}
current.endOfWord = false;
return Object.keys(current.children).length == 0;
}
let ch = word.charAt(index),
node = current.children[ch];
if(node === undefined) {
return false
}
let shouldDeleteCurrentNode = this.deleteRecursively(node, word, index + 1);
if (shouldDeleteCurrentNode) {
delete current.children[ch];
return Object.keys(current.children).length === 0;
}
return false;
}
let trie1 = new Trie();
trie1.insert("sammie");
trie1.insert("simran");
trie1.search("simran");
trie1.delete("sammie");
trie1.delete("simran");
trie1.search("sammie");
trie1.search("simran");시간 복잡도: O(W)
공간 복잡도: O(N*M)
모든 연산(삽입, 검색, 삭제)에 대해 시간 복잡도는 O(W)입니다. 여기서 W는 검색하고자 하는 문자열의 길이입니다.
공간 복잡도는 O(N*M) 입니다. 여기서 N은 트라이에 삽입된 단어의 개수이고, M은 가장 긴 단어의 길이 입니다. 따라서 공통 접두어를 지닌 다수의 문자열이 있는 경우에 트라이는 효율적인 자료구조로 작용할 수 있습니다.
하나의 특정 문자열에서 하나의 특정 문자열 패턴을 검색하는 경우 트라이는 효율적이지 않습니다.
