
정점 표현 학습이란?
그래프의 정점들을 벡터의 형태로 표현하는 것입니다.
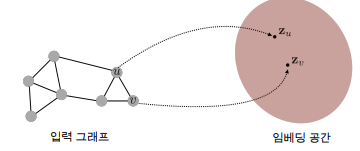
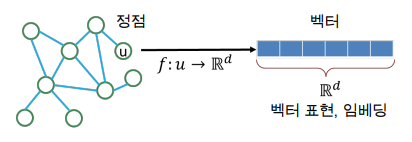
왜 그래프를 정점으로 표현해야하는가?
대다수의 기계학습 알고리즘은 입력으로 벡터의 형태를 요구합니다. ex) 군집 분석 알고리즘(K-Means, DBSCAN 등), 분류기(로지스틱 회귀분석, 다층 퍼셉트론 등)
정점 표현 학습의 목표
그래프에서의 정점간의 유사도를 임베딩 공간에서도 보존하는것을 목표로 합니다.
인접성 기반 접근법
인접성(Adjacency) 기반 접근법에서는 두 정점이 인접할 때 유사하다고 간주합니다.
인접행렬(Adjacency Matrix) A 의 u행 v열 원소 Au,v 는 u와 v가 인접한 경우 1 아닌 경우 0입니다.
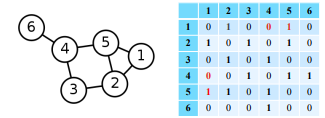
인접성 기반 접근법의 손실함수는 아래와 같습니다.
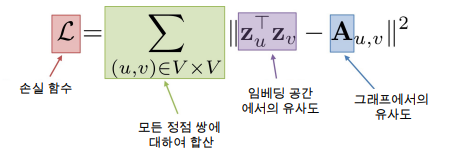
하지만 인접성 기반 접근법의 경우 서로 인접한 경우에만 유사하다고 가정하여 유사도가 있을 만한 충분한 거리내의 정점의 유사도를 0으로 간주한다는 문제점이 있습니다.
거리/경로/충첩 기반 접근법
거리 기반 접근법
거리 기반 접근법에서 두 정점 사이의 거리가 충분히 가까운 경우 유사하다고 간주합니다. 아래의 경우 충분히의 기준을 2로 가정하였습니다.
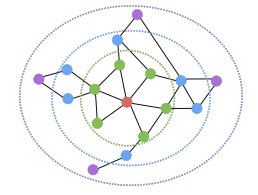
따라서 빨간색 정점과 파란색, 초록색 정점의 유사도는 1, 그 외의 정점과의 유사도는 0 입니다.
경로 기반 접근법
경로 기반 접근법에서는 두 정점 사이의 경로가 많을 수록 유사하다고 간주합니다. 두 정점 u 와 v 사이의 경로 중 거리가 k인 것의 수는 Aku, v와 같습니다. 즉, 인접행렬을 k번 곱하여 얻을 수 있습니다.
중첩 기반 접근법
중첩 기반 접근법에서는 두 정점이 많은 이웃을 공유할 수록 유사하다고 간주합니다.
아래 그림에서 빨간색 정점과 파란색 정점은 2개의 이웃을 공유하기 때문에 유사도가 2가 됩니다.
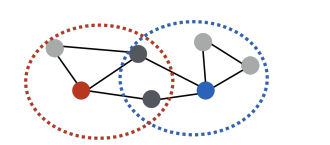
S 의 u행 v열 원소 Su,v 는 u와 v의 공통된 이웃의 수 입니다.
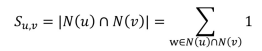
공통 이웃 수를 대신 자카드 유사도 혹은 Adamic Adar 점수를 사용할 수도 있습니다.
자카드 유사도(Jaccard Similarity) 는 공통된 이웃의 수 대신 비율을 계산하는 방식입니다.
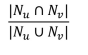
Adamic Adar 점수는 공통 이웃 각각에 가중치를 부여하여 가중합을 계산하는 방식입니다.
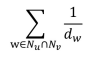
임의보행 기반 접근법
임의보행 기반 접근법에서는 한 정점에서 시작하여 임의보행을 할 때 다른 정점에 도달할 확률을 유사도로 간주합니다.
임의보행이란 현재 정점의 이웃 중 하나를 균일한 확률로 선택하는 이동하는 과정을 반복하는 것을 의미합니다.
임의 보행을 사용할 경우 시작 정점 주변의 지역적 정보와 그래프의 전역 정보를 모두 고려한다는 장점이 있습니다.
임의보행 기반 접근법의 단계
(1) 각 정점에서 시작하여 임의보행을 반복 수행합니다.
(2) 각 정점에서 시작한 임의보행 중 도달한 정점들의 리스트를 구합니다.
이때, 정점 u에서 시작한 임의보행 중 도달한 정점들의 리스트를 NR(u)라고 하고 한 정점을 여러번 도달한 경우, 해당 정점은 여러번 포함될 수 있습니다.
(3) 다음 손실함수를 최소화 하는 임베딩을 학습합니다.
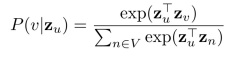
유사도에 Softmax를 취한 값을 확률로 사용합니다.

임의보행의 방법에 따라 DeepWalk와 Node2Vec으로 구분됩니다.
DeepWalk의 경우 다른 정점으로 이동할때 각 이웃에 동일한 확률을 부여합니다.
반면에 Node2Vec의 경우 2차 치우친 임의 보행(Second-order Biased Random Walk)를 사용합니다.
직전 정점의 거리를 기준으로 경우를 구분하여 차등적인 확률을 부여합니다.
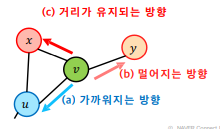
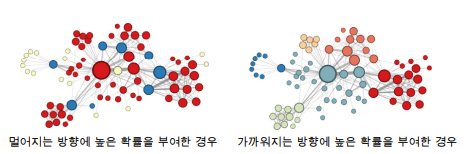
Node2Vec에서는 부여하는 확률에 따라서 다른 종류의 임베딩을 얻습니다.
임의보행 기법의 손실함수는 계산에 정점의 수의 제곱에 비례하는 시간이 소요됩니다.
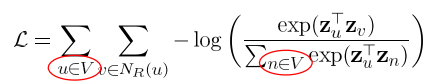
따라서 많은 경우 근사식을 사용합니다.
연결성에 비례하는 확률로 네거티브 샘플을 뽑으며, 네거티브 샘플이 많을 수록 학습이 더욱 안정적입니다.
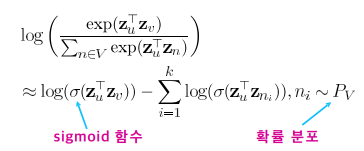
위 근사식의 자세한 설명은 블로그, arxiv
변환식 정점 표현 학습의 한계
변환식(Transductive) 방법은 학습의 결과로 정점의 임베딩 자체를 얻는 특성이 있습니다. 변환식 임베딩 방법은 여러 한계를 갖습니다.
(1) 학습이 진행된 이후에 추가된 정점에 대해서는 임베딩을 얻을 수 없습니다.
(2) 모든 정점에 대한 임베딩을 미리 계산하여 저장해 두어야합니다.
(3) 정점이 속성(Attribute) 정보를 가진 경우에 이를 활용할 수 없습니다.
