SCHEMA 관련
CREATE SCHEMA workspace; -- schema 생성
\dt -- 현재 스키마에 속한 테이블
\dn -- 스키마 리스트
SET search_path TO myschema; -- 스카마 변경GROUP BY
- 적용된 필드의 값으로 group을 나누고 aggregation연산을 수행함
- where->group by->select->order by 순으로 적용되며 group by 앞에 order by가 올 수 없음
- aggregation 함수 안에 distinct를 넣어서 사용가능함 count(distinct)
CTAS
- Create Table as Select의 약자
- SELECT INTO 또한 같은 역할을 하지만 CTAS를 쓰는 것을 권장
- CTAS 할때 order by 해줘도 적용안됨
DROP TABLE IF EXISTS table_name ;
CREATE TABLE table_name AS
SELECT * FROM ~;- CTE(Common Table Expression) : WITH로 임시테이블 만드는 것
WITH ds AS (
SELECT DISTINCT *
FROM sale_data
)
SELECT COUNT(1)
FROM ds;데이터 체크하기
- 데이터의 중복 체크
SELECT COUNT(1)
FROM sale_data;
SELECT COUNT(1)
FROM (
SELECT DISTINCT *
FROM sale_data
)a;- 최근 데이터 존재 여부 체크
SELECT MIN(date), MAX(date)
FROM sale_data;- Primary key 만족 여부 체크
SELECT order_id, COUNT(1)
FROM sale_data
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1;- NULL COUNT
SELECT
COUNT(CASE WHEN order_id is NULL THEN 1 END) order_id_null_count,
:
:
FROM
sale_data;JOIN
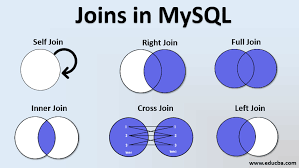
- INNER JOIN, LEFT/RIGHT JOIN, FULL JOIN, CROSS JOIN, SELF JOIN 이 존재
- INNER JOIN은 교집합, LEFT/RIGHT JOIN은 LEFT/RIGHT 기준
- FULL JOIN 은 합집합
- CROSS JOIN은 모든 경우의 수
- SELF JOIN 자기 자신과 JOIN, 그냥쓰진 않고 어떤 조건을 추가해서 쓴다고 함
- JOIN 할때 필드의 관계(one-one,one-many,many-one,many-many,포함관계)를 확인할 필요가 있음
JOIN 할때 포함관계 확인
SELECT distinct field from table_1
minus
SELECT distinct field from table_2;
SELECT distinct field from table_1
minus
SELECT distinct field from table_2;etc
TRUE,FALSE,NULL
is TRUE 와 = TRUE 가 같음
is TRUE 와 is not FALSE 는 다름(NULL이 존재할 수 있음)
NULL은 is,is not 만 쓸 수 있음
Devide by 0 error
ROUND(paidUsers*100.0/NULLIF(uniqueUsers,0),2)
NULLIF(field,value)
field의 값이 value와 같으면 NULL
COALESCE(exp1,exp2,...)
NULL값을 다른 값으로 바꿔주는 함수
COALESCE(value,0) 으로 자주씀, value가 NULL이면 0 아니면 value
공백 혹은 예약키워드를 필드 이름으로 사용하기
CREATE TABLE table_name(
"group" int primary key, -- group은 예약 키워드여서 ""로 싸줘야 필드이름으로 사용가능
"mailing address" varchar(32) -- 공백이 포함된 경우도 동일
);
실습
- 날짜별 처음 팔린 item, 마지막에 팔린 item
%%sql
-- 날짜별 처음,마지막 판매 물품 ROW_NUMBER 써서
SELECT a.date, a.itemcode as first_value, b.itemcode as last_value
FROM
(SELECT date, itemcode, ROW_NUMBER() OVER(partition by date order by order_id) as seq FROM sale_data) a JOIN
(SELECT date, itemcode, ROW_NUMBER() OVER(partition by date order by order_id DESC) as seq FROM sale_data) b
ON a.date=b.date and b.seq=1;
WHERE a.seq=1; -- ON에 넣어도 되는데 FROM table의 조건은 WHERE에 하는 것이 일반적
%%sql
-- 날짜별 처음,마지막 판매 물품 first_value,last_value 써서
SELECT
DISTINCT
date,
first_value(itemcode) over(partition by date order by order_id
rows between unbounded preceding and unbounded following),
last_value(itemcode) over(partition by date order by order_id
rows between unbounded preceding and unbounded following)
FROM sale_data
order by 1
LIMIT 10;rows 는 윈도우함수 적용 범위를 나타내기 위해 사용
range는 rows와 단위가 다름 order by 를 적용했을때 중복되는 것까지 포함하여 하나의 단위를 만든 것이 range, rows는 그냥 한줄을 하나의 단위로 봄
- 날짜별 가장 많이 팔린 상위 10개 item
%%sql
-- 가장 잘팔린 itemcode 상위 10개 group by 써서
SELECT itemcode, ROUND(SUM(amount)/10000.0,2) as Gross_revenue
FROM
sale_data
group by 1
order by 2 DESC
LIMIT 10;
-- DISTINCT 써서
%%sql
-- 가장 잘팔린 itemcode 상위 10개
SELECT DISTINCT itemcode, ROUND(SUM(amount) OVER(partition by itemcode)/10000.0,2) as Gross_revenue
FROM
sale_data
order by 2 DESC
LIMIT 10;- NPS 구하기
%%sql
-- 다 나눠서
SELECT a.mon, ROUND((a.promoter-a.passive)*100.0/NULLIF(a.total_count,0),2) as NPS
FROM
(SELECT
LEFT(ts,7) AS mon,
COUNT(CASE WHEN score BETWEEN 9 AND 10 THEN 1 END) AS promoter,
COUNT(CASE WHEN score BETWEEN 7 AND 8 THEN 1 END) AS passive,
COUNT(CASE WHEN score BETWEEN 0 AND 6 THEN 1 END) AS detractor,
COUNT(1) AS total_count
FROM ~
group by 1)a;
-- 한번에
SELECT LEFT(ts,7) AS MON,
ROUND(SUM(CASE WHEN score>=9 THEN 1 WHEN score<=6 -1 END)::float/NULLIF(COUNT(1),0)*100,2) AS NPS
FROM
~
group by 1
order by 1;