관계형 데이터베이스
프로덕션 데이터베이스
- MySQL,PostgreSQL, Oracle ...
- OLTP(OnLine Transaction Processing)
- 빠른 속도에 집중, 서비스에 필요한 정보를 저장
- 빠른 속도에 집중한 만큼 빠른응답을 필요로하는 백엔드, 프론트엔드에서 사용
데이터 웨어하우스
- OLAP(OnLine Analytical Processing)
- 처리 데이터 크기에 집중, 더이터 분석 혹은 모델 빌딩등을 위한 데이터 저장
- 보통 프로덕션 데이터 베이스를 복사해서 데이터 웨어하우스에 저장
- 많은 데이터를 요구해서 data 직군에서 주로 사용
프로덕션 데이터베이스만 쓸때 발생하는 문제점
보통 회사가 작은 경우 프로덕션 데이터베이스만 존재한다. 프로덕션 데이터베이스은 서비스와 연동되어 사용되어진다. 만약 이러한 데이터베이스에 큰 쿼리를 날리게되면 서비스의 속도가 느려지게되는 문제가 발생할 수 있다. 그래서 서비스에 영향을 주지 않는 데이터 웨어하우스가 필요하다. (프로덕션 데이터베이스는 메모리, 데이터웨어하우스는 디스크와 비슷한역할을 하는듯?)
관계형 데이터베이스의 구조
보통 관계형 데이터베이스는 2단계로 구성된다. 테이블들은 가장 및단에 존재하며, 테이블은 데이터의 목적, 특징 등에 맞게 여러 폴더에 나뉘어 저장된다. 이러한 폴더를 데이터베이스 or 스키마(데이터베이스에 따라 다르게 부름)라고 부른다.
기본적으로 각 테이블은 테이블의 각 열에 대한 정보를 담는 테이블 스키마를 가지고 있다. 테이블 스키마는 이름, 타입, 속성으로 구성된다. 이때 속성에 해당하는 Primary key는 하나이상의 필드로 구성되며 그 필드의 조합으로 유일성을 보장해준다. 즉, Primary key로 지정된 필드에 테이블에 이미 존재하는 값을 저장하려고 하면 테이블에서 reject한다.
SQL
Structured Query Language 라고 불리며, 관계형 데이터베이스에 있는 데이터(테이블)를 질의하거나 조작해주는 언어이다. SQL은 두 종류의 언어로 구성된다.
DDL(Data Definition Language): 테이블의 구조를 정의하는 언어DML(Data Manipulation Language): 테이블에서 원하는 레코드들을 (읽어오는 질의 언어/추가,삭제,갱신해주는 언어)
SQL은 구조화된 데이터를 다루는한 데어터 규모와 상관없이 쓰인다. 모든 대용량 데이터 웨어하우스는 SQL기반이다.(Redshift, Snowflake, BigQuery, Hive) Spark(SparkSQL), Hadoop(Hive) 에도 SQL이 쓰인다.
SQL의 단점 또한 존재한다. 구조화된 데이터를 다루는데 최적화되어 있다는 점이다.
- 정규표현식을 통해 비구조화된 데이터를 어느정도 다루는 것은 가능하나 제약이 심하다.
- 많은 관계형 데이터베이스들이 플랫한 구조만 지원한다.(no nested like JSON)
- 구글 빅쿼리는 nested structure(field 안에 field가 들어가는 구조)를 지원한다. - 비구조화된 데이터를 다르는데 Spark, Hadoop과 같은 분산 컴퓨팅 환경이 필요해졌다.
- 즉, SQL만으로는 비구조화 데이터를 처리하지 못함 - 관계형 데이터베이스마다 SQL 문법이 조금씩 상이함.
데이터를 어떻게 표현할 것인가에 관한 것이 데이터 모델링이다. 데이터 모델링을 하는 방법은 크게 2가지가 있다. Star schema, Denormalized schema 가 있다. Star schema는 데이터를 논리적인 단위로 나누어 포멧을 만들어 데이터를 관리하는 형태이다. 스토리지 낭비가 덜하고 업데이트가 쉬운 장점이있다. 보통 production database에서 많이 사용한다. Denormalized schema 는 반대로 단위 테이블로 나눠 저장하지 않아 별도로 조인이 필요 없는 형태를 말한다. 이는 스토리지를 더 사용하지만 조인이 필요 없기에 빠른 계산이 가능하다는 장점이 있다. 데이터 웨어하우스에서 사용하는 방식이다.
데이터 웨어하우스
데이터 웨어하우스는 큰 쿼리로 인한 서비스 장애를 막기 위해 생겨난 데이터베이스이다. 여전히 SQL 기반의 관계형 데이터베이스이며 회사에 필요한 모든 데이터를 저장하는 곳이며 고객이 아닌 내부 직원을 위한 데이터베이스이다.
AWS 의 Redshift, Google Cloud의 Big Query, Snowflake등이 대표적이다. 참고로 Redshift보다 Big Query, Snowflak가 더 scalable하고 좋은 데이터 웨어하우스이다. Redshift는 고정비용, Big Query Snowflake는 가변비용이다. 가변비용의 경우 사용량에 따른 비용이 청구되어 지나친 사용을 하게되면 큰 비용이 청구되는 위험이 있다. 하지만 이러한 비용관리를 잘 하게 되면 Big Query, Snowflake를 쓰는 것이 더 좋은 방법이다. 하지만 사용법 자체에는 큰 차이가 없다.
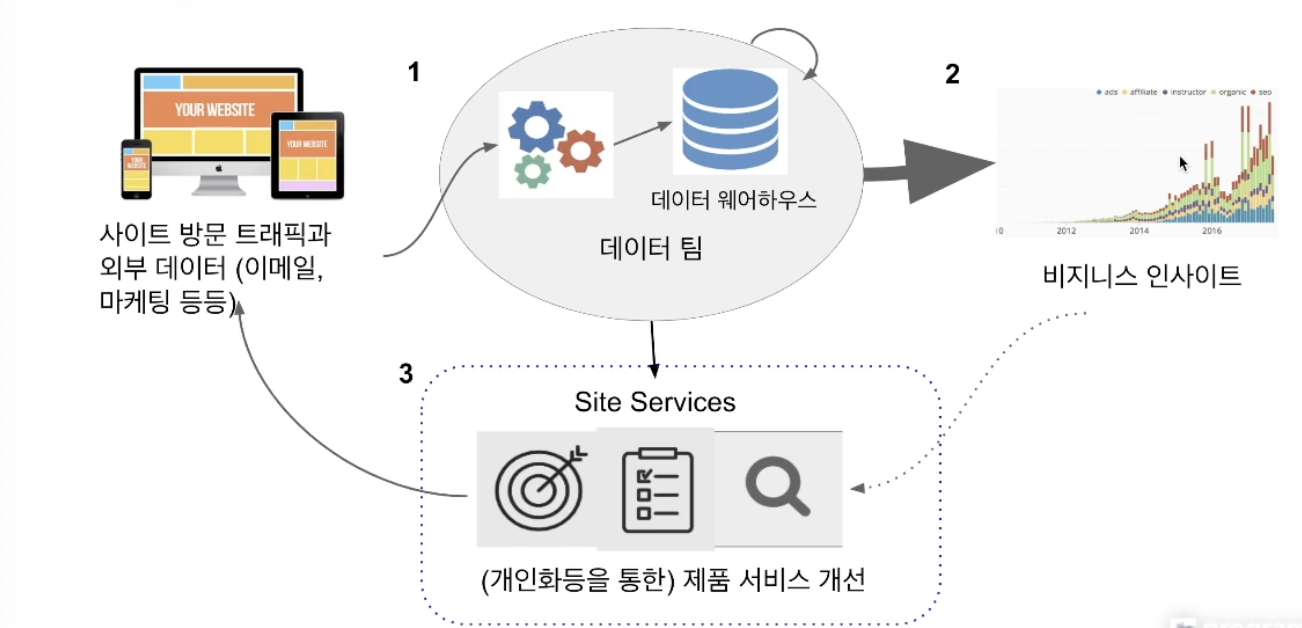
외부에 존재하는 데이터를 읽어다가 데이터 웨어하우스로 저장해주는 과정이 필요해지는데 이를 ETL혹은 데이터 파이프라인이라고 부른다. 이러한 과정은 데이터 엔지니어가 관리하며 시스템이 발전하게되면 비구조화된 데이터들이 생겨 Spark와 같은 대용량 분산처리 시스템이 추가될 수 있다.
Redshift
- 2PB 까지 지원(그 전에 문제가 생김, 64TB까지는 괜찮았는데 그 이후는 문제가 생겼다더라)
- 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용불가
- Columnar storage
: 대부분의 데이터베이스는 레코드별로 저장을 하는데 Redshift와 같은 데이터 웨어하우스들은 컬럼별로 저장을 한다. 따라서 컬럼을 추가하거나 삭제하는 것이 아주 빠르고 컬럼별 압축이 가능하다. - 벌크 업데이트를 지원한다.
: SQL의 INSERT로 한번에 추가할 수 있는 데이터수가 정해져있다. 데이터를 대용량으로 저장하는 데이터웨어하우스와 맞지않다. Json이나 csv와 같은 레코드가 들어있는 파일을 웹 스토리지(S3)에 복사한 후 COPY 커맨드로 Redshift로 일괄 복사하게 된다. - 다른 데이터 웨어하우스처럼 primary key uniqueness를 보장하지 않는다.(레코드가 추가될때마다 중복성을 체크하게되면 저장하는 속도가 느림)
- Postgresql 8.x 와 SQL이 호환됨, 하지만 모든 기능을 지원하지는 않음 (eg. text타입이 Redshift엔 없음)
- postgresql 8.x를 지원하는 툴이나 라이브러리로 액세스 가능
: SQL Workbench(Mac, Window), Postico(Mac), Python(psycopg2 모듈), 시각화/대시보드 툴(Lookcer, Tableau, Power BI, Superset)등에서 연결 가능
