출처 : KOCW 운영체제-반효경
( )
Demand paging
physical memory 의 주소변환은 운영체제가 관여하지 않는다. 하지만 virtual memory는 OS가 전적으로 관여한다. 앞으로 paging 기법을 사용한다고 가정한다.(실제로 대부분 paging 기법을 사용한다.)
Demand paging 은 실제로 필요할 때 page를 메모리에 올리는 것이다.(빈번하게 사용되는 더 의미 있는 page를 메모리에 올리는 것이다.) 프로그램이라는 것은 상당히 방어적으로 작성되었다. 이상한 사용자가 이상한 짓?을 하는 것 까지 고려해 프로그램의 대부분은 빈번하게 사용되지 않는 부분이다. 그래서 Demand paging 을 쓰게 되면 빈번하게 사용되는 더 의미있는 부분이 메모리에 올라가 I/O 양이 감소하여 더 빠른 응답 시간을 가지고 메모리의 사용량이 감소해서 더 많은 사용자를 수용할 수 있다.
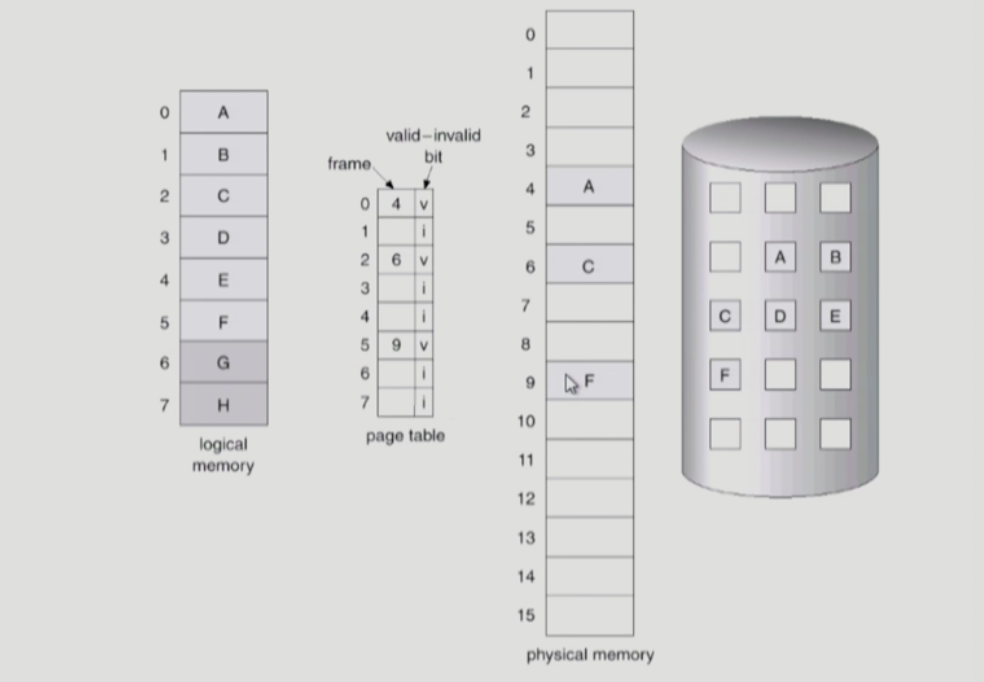
page가 invalid 라는 것은 그 페이지가 사용되지 않는 페이지이거나(주소공간이 지원해주는 용량이 실제 프로세스의 용량보다 클때) swap area인 backing store에 저장되어 있을때를 의미한다. 즉, 주소변환을 통해 물리적 메모리의 프레임 번호를 얻지 못할때 invalid라는 것이다. 처음에는 모든 page entry가 invalid로 초기화 되어 있다. Address translation 시에 invalid bit이 set되어 있으면 page fault 가 일어나게되고 이때 page fault trap 이 일어나 cpu가 운영체제에게 넘어가게 된다.
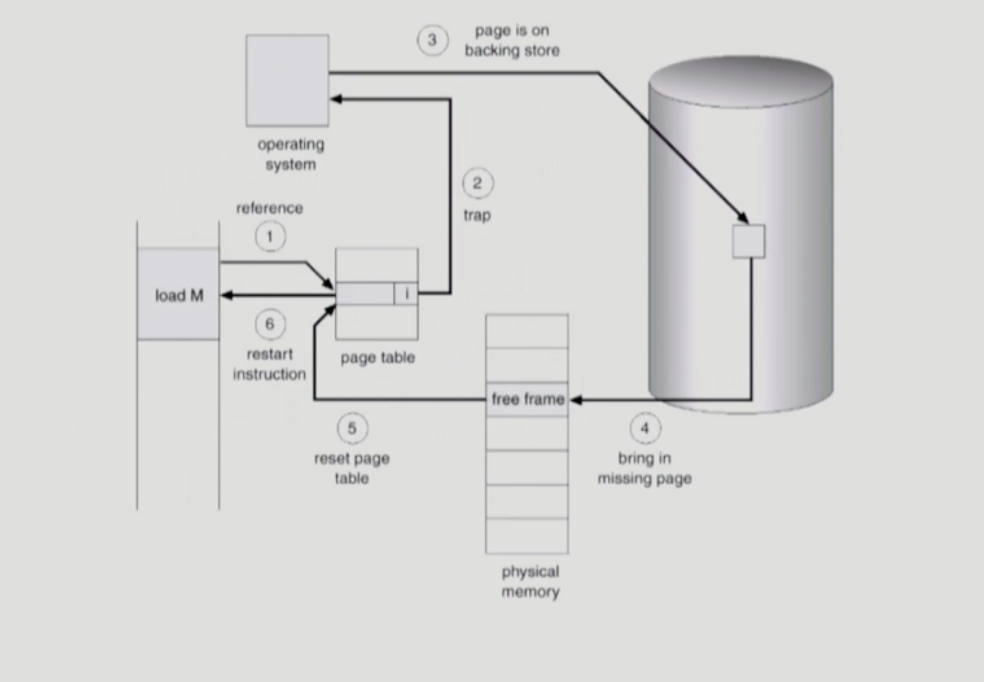
invalid page에 접근하면 MMU가 trap을 발생시킨다. 그러면 프로세스는 커널 모드에들어가고 page fault handler가 실행된다. 다음과 같은 순서로 page fault를 처리한다.
1. Invalid reference (eg. Bad address, protection violation) 일 경우 abort process 한다.
2. 빈 프레임을 얻는다.(없으면 뺏어온다:replace)
3. 해당 페이지를 DISk에서 memory로 읽어온다.
1. Disk I/0가 끝나기까지 이 프로세스는 CPU를 preempt 당한다.(block)
2. Disk read 가 끝나면 page tables entry 기록한다. Valid/invalid=‘valid’
3. Ready queue에 process 를 insert -> dispatch later
4. 이 프로세스가 cpu를 잡고 다시 running
5. 아까 중단되었던 instruction을 재개한다.

Page fault가 일어나면 OS에게 cpu가 넘어가 HW적으로 page fault를 처리하는 일, physical memory에 빈 공간이 없다면 어떤 page를 swap out 하는 일, 필요한 page 를 swap in 하는 일, 다시 OS가 page table을 수정하고 나중에 cpu를 얻어 restart를 하는 overhead가 들게된다.
page replacement algorithm
physical memory에 빈 공간이 없을때 page fault가 일어나게되면 page replacement가 일어나게된다. Swap out 될 page를 정해야하고 이에 대한 기준이 필요하다. Page fault rate을 최소화하는 것이 목표이기 때문에 가장 먼 미래에 사용될 page를 쫓아내는것이 이상적이다.
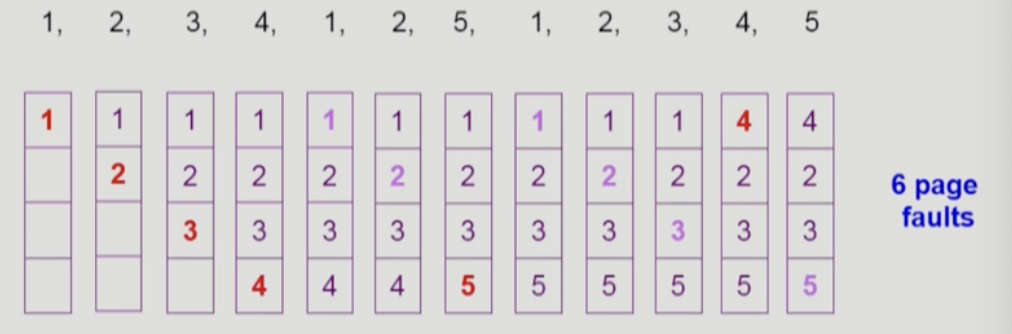
가장 이상적인 알고리즘은 Belady’s optimal algorithm(MIN,OPT로도 불림)이다. 이 알고리즘은 가장 먼 미래에 참조되는 page를 replace한다. 가장 이상적인 알고리즘이므로 다른 알고리즘 성능에 대한 upper bound를 제공한다. 하지만 미래의 상황을 모두 안다는 것을 가정을하는 offline algorithm이므로 실제 상황에선 사용할 수 없다.
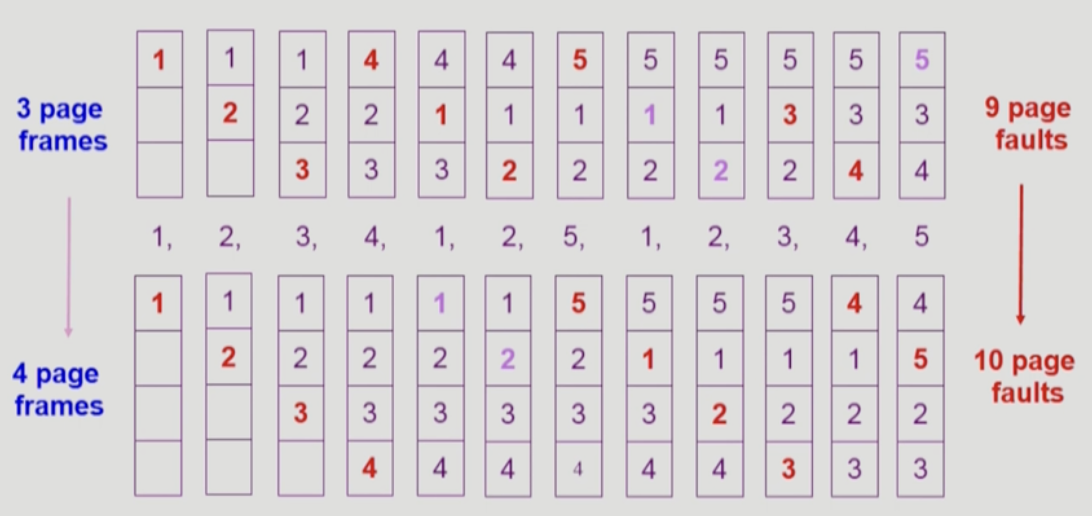
FIFO 알고리즘은 먼저 들어온 것을 먼저 쫓아내는 알고리즘이다. 보통 최근에 참조된 page는 미래에도 사용될 가능성이 높다는 것이 일반적이다. 그리고 먼저 들어온 page는 최근에 참조된 page일 가능성이 있다. FIFO 알고리즘은 그다지 합리적인 알고리즘이 아니다. 또한 FIFO 알고리즘은 frame의 수가 적은 page fault를 보장하지 못한다. 이를 FIFO Anomaly(Belay’s Anomaly)라고한다.
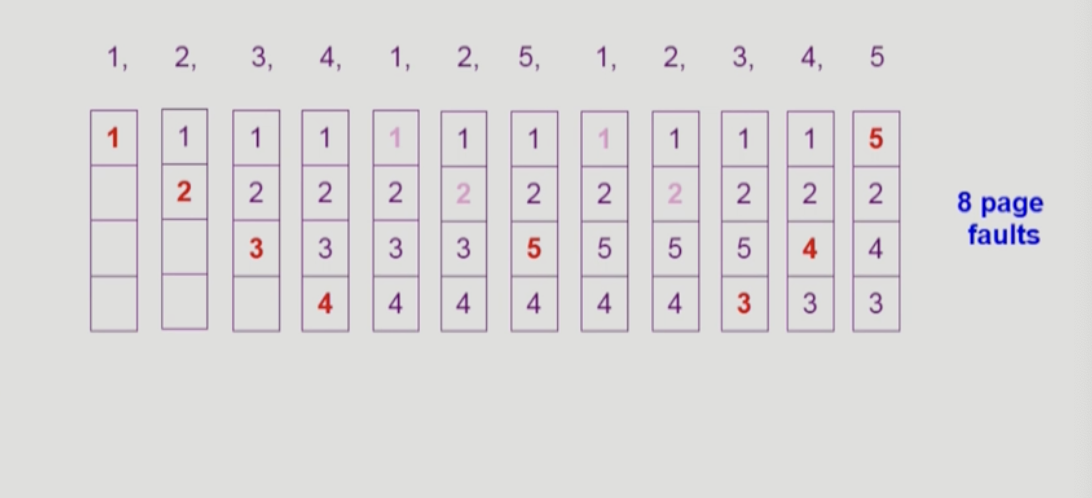
다음 알고리즘은 LRU(Least Recently Used) algorithm이다. 이것은 가장 오래전에 참조된 page를 쫓아낸다. 가장 오래전에 참조된 페이지가 사용될 가능성이 낮으므로 합리적이다. 하지만 빈도에 대한 정보는 사용하지 않아 인기도를 반영하지 못한다.
LFU(Least Frequently Used) 알고리즘은 참조횟수가 가장 적은 페이지를 쫓아낸다. 최저 참조횟수가 여럿인 경우에는 별도로 정해놓은 규칙은 없다. (구현하는 사람 마음) 임의로 선정할 수도 있고 성능 향상을 위해 가장 오래 전에 참조된 page를 지우게 구현할 수도 있다. LRU처럼 직전 참조 시점만 보는 것이 아니라 장기적인 규모로 보기때문에 인기도를 좀 더 정확히 반영할 수 있다. 하지만 참조시점을 반영하지 못하고 구현이 LRU에 비해 복잡하다.
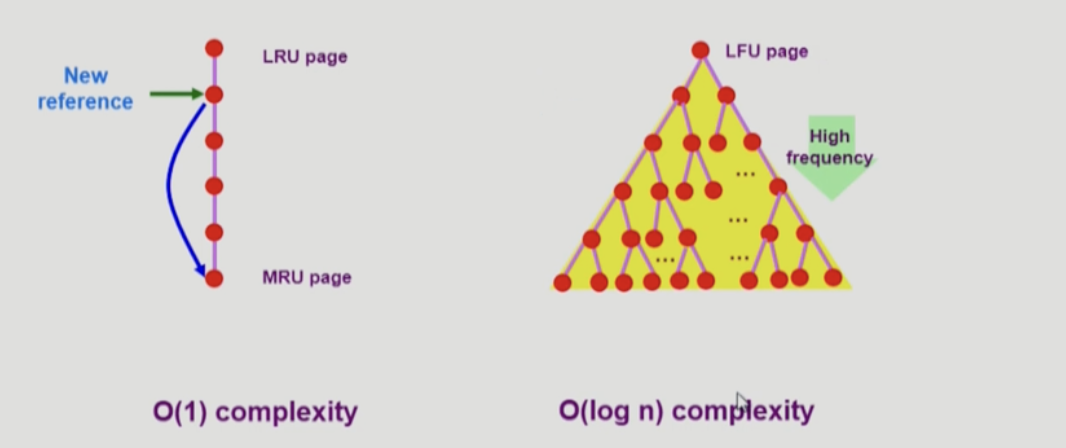
page를 참조할때마다 LRU는 linked list를 사용하여 정보를 수정하여 O(1)의 시간 복잡도를 가지며 LFU는 최소 힙을 사용해 정보를 수정하여 O(log n)의 시간 복잡도를 가진다.
caching 기법
한정된 빠른 공간(=캐쉬)에 요청된 데이터를 저장해 두었다가 후속 요청시 캐쉬로부터 직접 서비스하는 방식을 말한다. Paging system(physical memory) 외에도 cache memory(메모리와 cpu 사이에 있는 빠른 계층, 메인 메모리에 접근하기전에 확인 eg. TLB), buffer caching(file system 에서 read/write 요청을 메모리에서 빠르게 처리하는 기법), web caching(web page를 띄우기 위해선 멀리있는 web server에서 정보를 받아와 web browser 화면에 display 동일한 url을 다시 요청할 수 있으니 임시저장, 다른 기법과 달리 매체의 속도차이에 의해 필요한것이아니라 지리적인 거리에 의해 일어남) 등 다양한 분야에서 사용된다.
교체 알고리즘으로 인한 시간적 overhead가 page fault를 줄여 얻는 이득보다 크게 되면 해당 교체알고리즘을 사용할 수 없다. Buffer caching 이나 web caching의 겨우 O(1)~O(log n) 정도까지 허용한다. Paging system 인 경우 page fault인 경우에만 OS가 관여한다. 페이지가 이미 메모리에 존재하는 경우 참조시각 등 정보를 OS가 알 수 없다. 따라서 O(1)인 LRU조차 사용할 수 없다.
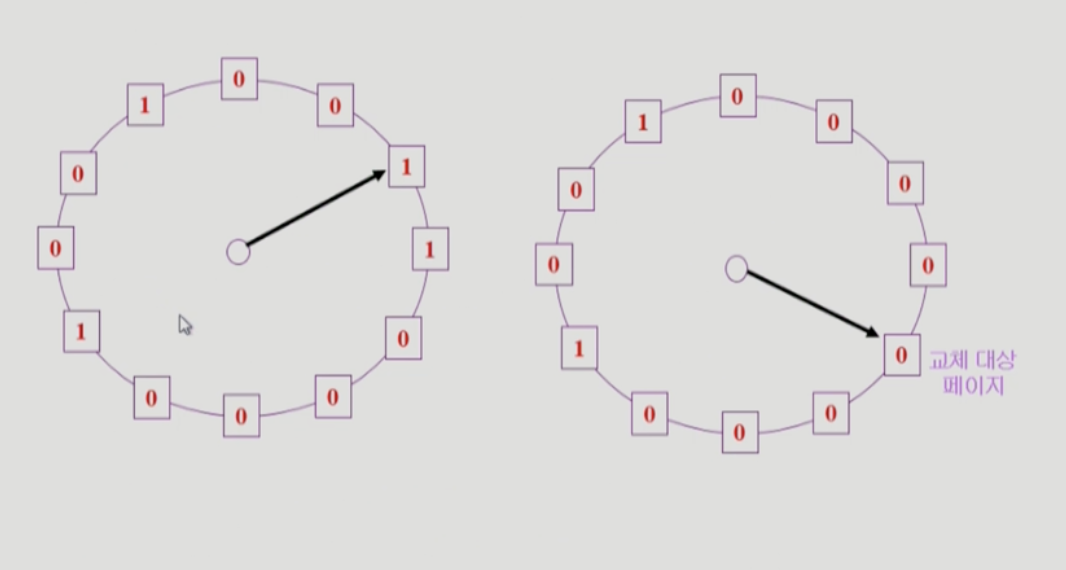
대안으로 clock algorithm을 사용한다. Clock algorithm은 LRU의 근사 알고리즘이다. Second chance algorithm, NUR(not used recently), NRU(not recently used) 라고도 불린다. 이 알고리즘은 reference bit을 참고하여 동작한다. Reference bit은 하드웨어에 의해 기록되는 bit로 어떤 페이지를 참조하면 reference bit이 1이된다. Page fault가 나게되면 clock algorithm은 Page frame으로 구성된 circular list를 돌면서 reference bit을 확인하여 1이면 0으로 바꾸고 다음 프레임으로 이동하고 0인 page를 만나면 해당 page 를 swap out한다. 한 바퀴 되돌아와서도 0이면 그때에는 replace 당한다.(=second change) 자주 사용되는 페이지라면 second chance가 오더라도 1일 가능성이 높다. Modified bit(dirty bit)를 통해 page가 수정된 적이 있는지 없는지를 저장한다. 수정된 적이 있다면 swap out 할때 disk에 반영해줘야하기때문에 더 많은 작업을 요구한다. 따라서 modified bit 이 0 인 것을 우선적으로 쫓아내는 방식으로 clock algorithm을 개선할 수 있다.
page frame 에서 allocation
프로세스에 얼마만큼의 page frame을 할당할 것인가? 메모리 참조 명령어 수행시 명령어, 데이터 등 여러 페이지를 동시에 참조하게 된다. 즉 명령어를 수행하기 위해 최소한 할당되어야 하는 frame의 수가 있다. 또한 loop를 구성하는 page들은 한꺼번에 allocate 되는 것이 유리하다. 만약 최소한의 allocation이 없으면 매 loop마다 page fault가 일어나게 된다. Allocation 방식에는 equal allocation(동일하게), proportional allocation(프로세스의 크기에 비례하여), priority allocation(process의 priority에 따라) 등이 있다.
global replacement 방식은 다른 process의 frame을 빼앗아올 수 있는 방식이다. Working set,PFF 방식을 사용하게 되면 process 할당의 효과를 볼 수 있다.
local replacement 방식은 자신에게 할당된 frame내에서만 Replacement 하는 방식이다. FIFO,LRU,LFU 등의 알고리즘을 프로세스별로 운영하는 것을 생각하면된다. process에게 frame을 사전에 할당해주는 방식이라고 볼 수 있다.
Thrashing -> working-set model,PFF
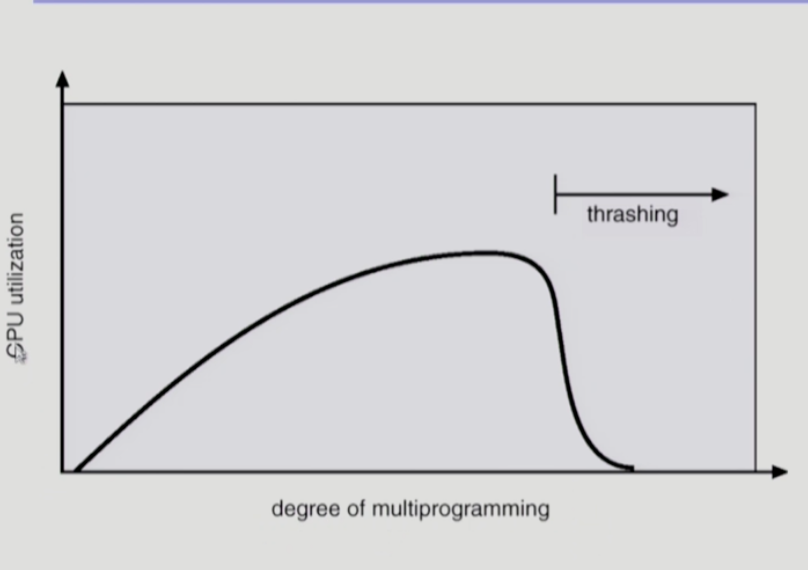
degree of multiprogramming이 증가할때 cpu 이용률이 오히려 떨어지는 구간을 말한다. 각 프로세스의 원활한 수행에 필요한 최소한의 page frame 수를 할당 받지 못한 경우 빈번한 page fault가 원인이 된다. OS 입장에서는 MPD를 높여야한다고 판단하고 그렇게 되면 page fault가 더욱 빈번해지는 악순환이 반복된다.
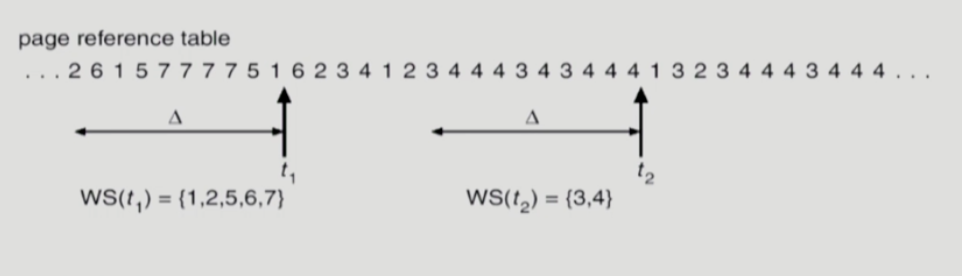
프로세스가 특정 시간 동안 일정 장소만을 집중적으로 참조한다. 이것을 locality of reference라고 한다. 집중적으로 참조되는 해당 page들의 집합을 locality set(working set)이라고 한다. 이 특성을 고려한 replacement 방식이 working set algorithm이다. Working set 모델에서는 process의 working set 전체가 메모리에 올라와 있어야 수행되고 그렇지 않을 경우 모든 frame을 반납한 후 swap out(suspended)된다. 미래에 참조할 page를 알지 못하기 때문에 과거를 참고하여 working set을 생성한다. 현재부터 특정 Time interval 만큼의 시간동안 참조된 page들의 집합으로 정의하고 time inteval을 working set window 라고 한다. Working set에 포함되는 page는 메모리에 유지하고 속하지 않는 것은 버린다.
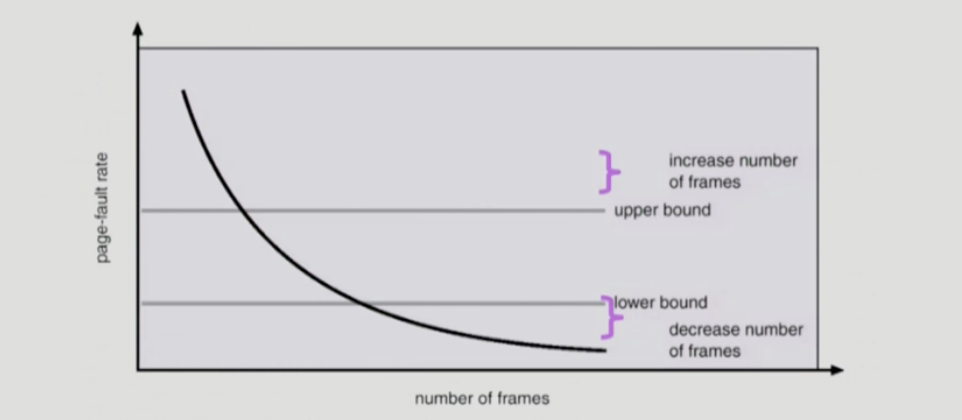
PFF(page-fault frequency) 는 working set 알고리즘과 달리 직접 page fault rate을 관찰한다. Page fault rate 이 특정 수준보다 높으면 더 많은 frame을 할당해주고 너무 작다면 frame을 빼앗긴다. 그리고 빈 frame이 없으면 일부 프로세스를 swap out 한다.
page size의 결정
page size를 감소시키면 internal fragmentation이 감소하고 필요한 정보만 메모리에 올라와 메모리 이용이 효율적이다. 하지만 page size 를 증가시키면 어떤 함수를 실행하게 되면 코드가 순차적으로 참조가 되기때문에 page fault 가 났을때 page를 통째로 올려놓게되면 locality 측면에서 더 효율적이다. 또한 disk transfer의 효율성이 증가한다.(seek/rotation time> transfer time 한번 seek 하면 많은 양을 가져오는게 좋음) 메모리 주소체계가 32->64로 바뀌고 메모리크기도 점점 커지기때문에 Lager page size가 trend 이다.
