출처 : KOCW 운영체제-반효경
( )
파일을 저장할때 디스크를 일정한 sector단위(logical block)로 나누어서 저장하게 된다.
contiguous allocation
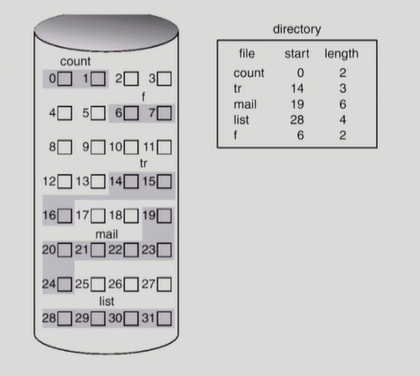
파일을 디스크에 연속적으로 저장하는 방식으로 외부조각이 발생하여 공간효율성이 떨어진다. 디렉토리에 메타데이터인 파일의 주소를 시작위치와 길이를 저장하게 된다. 장점으로는 한번의 seek/rotation으로 많은 바이트를 transfer 할 수 있어 빠른 I/O가 가능하다. 따라서 realtime 용으로, 또는 이미 run 중이던 process의 swapping 용으로 사용할 수 있다. 메타데이터로 파일의 시작위치와 길이를 알고 있고 연속적으로 할당되어 있기때문에 직접접근이 가능하다.
internal fragmentation : 누군가에게 할당되었는데 쓰이지 않는 공간
external fragmentation : 누군가에게 할당되진 않았으나 할당된 공간들에 의해 생기는 조각
linked allocation
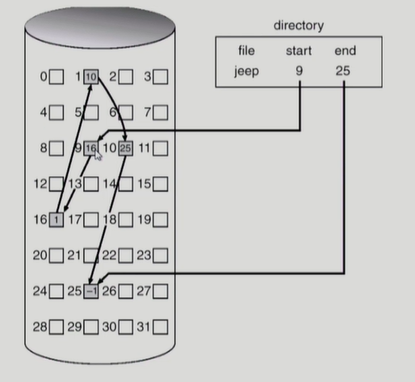
시간효율성을 희생하고 공간효율성을 높인 방법이다. 순차접근만 가능하여 시간효율성이 좋지 못하고 중간에 bad sector가 나면 그 이후를 모두 잃어 reliability 를 보장해주지 못한다. 또한 디스크와 컴퓨터 내부 사이의 데이터를 주고 받는 단위가 보통 512bytes(sector 도 보통 동일한 단위를 가진다) 인데 포인터가 차지하는 공간이 4bytes라고 하면 sector 마다 실제로는 508bytes만 사용할 수 있어 공간 효율성도 그다지 좋지 못하다. 이 방법을 약간 변형한 방법인 FAT 파일 시스템이 있는데 이는 후에 설명할 것이다.
indexed block
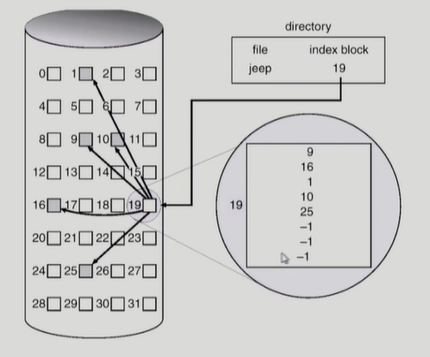
디렉토리에 파일의 주소를 디스크의 특정 sector로 지정하고 그 sector에 파일을 구성하는 sector에 대한 table을 저장한다. 이 방식을 사용하게 되면 외부 조각이 발생하지 않고 임의접근이 가능하다. 하지만 파일이 굉장히 작은 경우, 아무리 작은 파일이라고 하더라도 2개의 sector는 최소한 필요하기 때문에 공간 낭비가 있다. 파일의 크기가 큰 경우에는 하나의 block으로 index를 저장하기 부족할 수 있다. 그럴 경우 linked scheme으로 block에 저장된 table의 마지막 요소에 값이 저장됬을때 그 값은 다른 block의 위치를 가리키는 정보라고 약속하고 가리킨 위치의 block을 통해 이어서 저장하는 방법을 사용해 해결할 수 있다. 다른 방법으로는 multi level paging 처럼 multi-level index를 두어 해결할 수도 있다.
이때까지 이론적인 이야기 실제적으로 어떻게 쓰이는가를 이야기하려고 한다.
UNIX 파일시스템의 구조
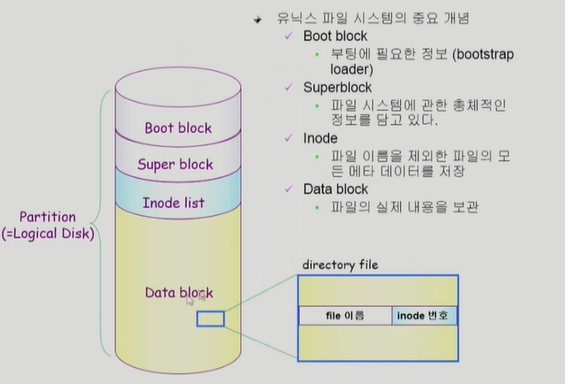
수 많은 운영체제의 부모격인 운영체제인 UNIX에서 사용하는 파일 시스템이다. 이 파일시스템 구조는 boot block, super block, inode list, data block 4개가 순차적으로 구성된다.
먼저 boot block 은 unix 뿐만아니라 모든 파일시스템이든 존재하는 block이다. 컴퓨터의 전원을 켜게되면 boot block의 bootstrap loader가 실행되어 파일 시스템 내에서 운영체제의 kernel의 위치가 어디인지를 찾아 메모리에 올려 컴퓨터가 작동이 되게 하는 역할을 한다.
super block은 이 파일 시스템에 대한 정보를 담고있다. 구체적으로 어디가 빈 블럭이고 어디가 실제로 파일이 저장된 블럭인지 Inode list가 어디까지인지에 대한 정보를 담고있다
디렉토리에는 실제로 메타데이터에 대한 모든 정보를 담고 있지 않다. Inode(index node) list 에는 file에 대응되는 inode가 하나씩 있고 inode에 파일에 대한 메타데이터를 담고있다. file의 이름은 inode 말고 디렉토리 파일이 가지고 있으며 디렉토리 파일에는 file에 해당하는 inode 번호를 담고있다. inode가 차지하는 공간은 가변적으로 변하는것이 아니고 미리 할당이 되어 있는 것이기 때문에 파일의 크기가 커지게 되면 direct block(데이터를 가리키는 포인터를 저장하는 테이블)으로는 부족할 수 있다. 그럴땐 single indirect,double indirect, triple indirect(몇개의 DATA BLOCK을 거쳐 포인터를 저장하게 되는지에 따라 나뉨) 에 나머지 포인터에 대한 테이블을 담는 DATA BLOCK의 위치를 가리켜 해결할 수 있다.
data block
FAT(file allocation table) file system
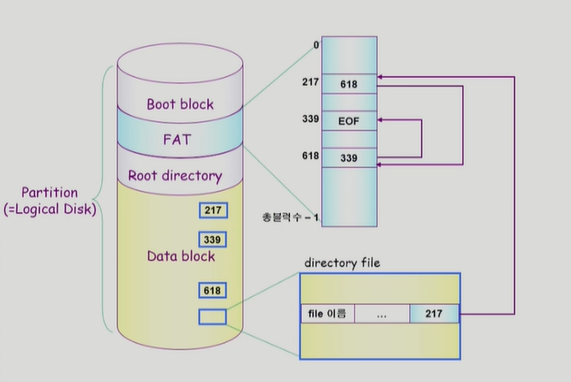
FAT은 각각의 블럭의 다음 블럭이 어디인지를 저장한 TABLE이다. FAT을 통해 각각의 블럭이 어떤 파일에 속하는 지는 알 수 없으나 블럭들간의 연결성에 대한 정보를 담고 있다. 파일의 시작위치를 포함한 나머지 메타데이터는 디렉토리가 가지고 있다.
fat은 작은 테이블이여서 메모리에 올라가 동작한다. 따라서 disk head가 직접 움직이며 메타데이터를 확인하지 않고 fat을 확인하여 disk로의 직접접근이 가능하다. 그리고 fat은 중요한 정보이기때문에 disk에 2copy이상을 저장하고 있다. 따라서 linked allocation와 달리 reliability가 보장되고 512byte 중 4byte가 포인터로 공간 낭비와 같은 것도 없다.
이것외에도 파일시스템의 종류는 굉장히 많다.
free sapce management
빈공간은 어떻게 관리할까?
bit map
부가적인 공간 필요 UNIX의 경우 super block에 저장, 연속적인 n개의 free block을 찾는데 효과적이다.(disk 의 head가 일일이 이동할 필요없어서)
linked list
빈 블럭끼리 linked list를 만들어 관리하는 방법이다. 어차피 빈 공간이므로 공간적인 낭비는 없다. 하지만 연속적인 공간을 찾으려면 disk head가 실제로 움직여야 해서 굉장히 비효율적인 방법이다. 그래서 실제로 쓰기 어렵다.
grouping
linked list 방법의 변형으로 첫번째 free block이 n개의 pointer를 가지고 그 중 n-1개 는 free dat ablock 마지막 pointer가 가리키는 block은 또다시 n pointer를 가지게 된다. 빈 공간을 한번에 찾는 것은 효율적이더라도 연속적인 빈 공간을 찾기는 마찬가지로 쉽지 않다.
counting
프로그램들이 여러 개의 연속적인 block을 할당하고 반납한다는 성질에 착안하여 만들어진 방법으로 빈 블럭의 첫번째 위치와 몇개가 연속적으로 존재하는지를 쌍으로 관리한다.
디렉토리의 구현
하위 파일의 메타데이터를 관리하는 파일

linear list
파일의 이름과 메타데이터를 순차적으로 저장며 이름과 메타데이터에 일정한 공간을 할당한다. file 을 찾기위해서 linear search 필요하다. (time-consuming)
hash table
hash 함수를 사용하면 어떤 입력이 들어오더라도 결과가 범위 내에 분포, collision이 발생할 수 있지만 해결할 수 있다.(운영체제 범위를 넘어섬) file name에 대한 hash 값을 통해 원하는 파일을 직접접근이 가능해져 linear list의 time-consuming 문제가 해결되었다.
file의 metadata 보관 위치
디렉토리 내에 직접 보관하거나 디렉토리에는 포인터를 두고 다른 곳에 보관(inode, FAT)할 수 있다.
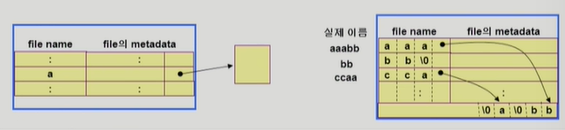
long file name 의 지원
file의 메타데이터는 보통 길이가 정해져있지만 file의 이름은 들쑥날쑥하다. file name이 고정 크기의 entry보다 길어지면 entry의 마지막 부분에 이름의 뒷부분이 위치한 곳의 포인터를 두는 방법을 쓸 수 있다.
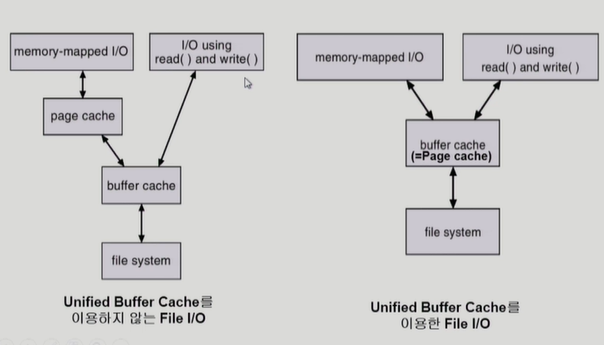
VFS(virtual file system)
서로 다른 다양한 file system에 대해 동일한 시스템 콜 인터페이스(API)를 통해 접근할 수 있게 해주는 OS의 layer이다.
Network File System(NFS)
분산 시스템에서는 네트워크를 통해 파일이 공유될 수 있다. NFS는 분산 환경에서의 대표적인 파일 공유방법 이다.
page cahce & buffer cache
page cache
page frame을 caching의 관점에서 설명하는 용어이다.memory mapped i/o를 쓰면 file의 i/o에서도 page cache 사용한다.(read(),write()와 같은 시스템 콜 없이 프로세스가 독자적으로 사용 가능하다. 파일에도 반영이 된다.)
unified buffer cache
buffer cache도 페이지 단위로 관리한다. 요즘은 버퍼 캐쉬의 크기가 페이지 크기랑 같다.
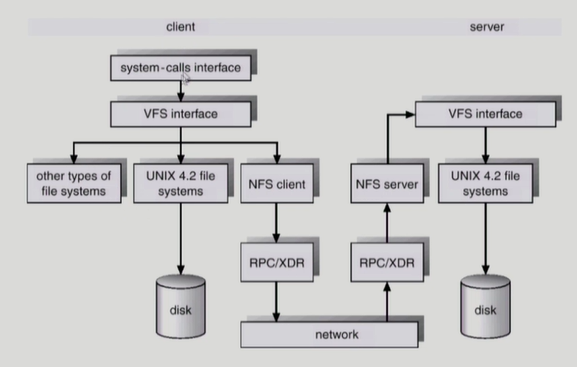
page cache의 경우 mmap(), read/write()모두 buffer cache에 저장하고 mmap()의 경우 다시 자신의 메모리 공간에 복사해오는 방식이었다면 unified buffer cache 방식에서mmap() 은 파일을 가상 메모리에 mapping 시키고 바로 해당 프로세스에 파일을 올린다.
swap area는 기본적으로 page 단위로 묶어두게 되고 더 큰 단위로 묶을 수도 있다.(속도효율성을 위해서)
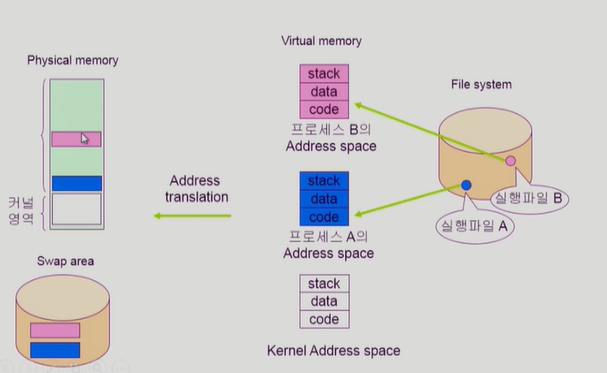
실행파일의 형태가 프로세스의 가상 메모리의 code부분으로 올라갈때 mmap() 을쓴다. 그리고 이 code 부분의 일부분이 메모리에서 쫓겨날때 read only인 영역이기 때문에 swap area로 가지않고 그냥 버려진다. 다시 읽어야하면 file system에 접근하면된다.
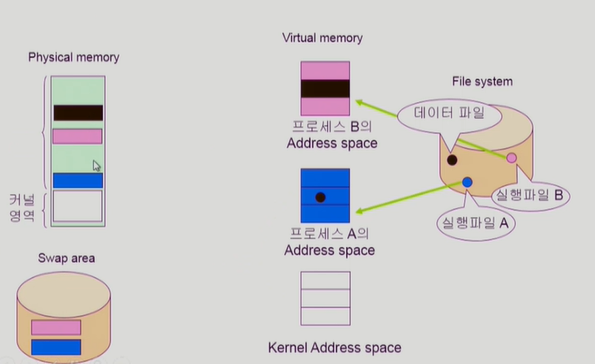
프로세스 B가 특정 파일에대한 mmap() 요청을 하게되면 자신의 가상메모리 공간에 할당하고 쫓아낼땐 swap area가 아닌 file system 에 write하게 된다. 이 상황에서 프로세스 A가 read() 요청을 하게되면 kernel에게 cpu가 넘어가 unified buffer cache의 경우 해당 내용이 buffer cache에 이미 존재하므로 바로 메모리로 부터 복사해 온다. memory mapped i/o의 경우 운영체제의 중재없이 파일을 수정할 수 있기때문에 일관성이 깨지는 문제에 주의할 필요가 있다.
disk scheduling
disk 를 읽어올때 logical block 단위로 읽어오게 되고 물리적인 disk에 데이터를 저장하는 단위는 sector이다. physical foramtting은 디스크를 컨트롤러로 읽고 쓸 수 있도록 섹터들을 나누는 과정이다. 각 섹터는 header + 실제 data + trailer로 구성되며 header 와 trailer는 sector number, ECC(error-correcting code) 등의 정보가 저장되며 ECC를 통해 정보가 잘 저장되었는지 확인할 수 있다.
partitioning은 디스크를 하나 이상의 실린더 그룹으로 나누는 과정이고 OS는 이것을 독립적 disk로 취급한다. partition 된 disk에는 파일시스템이 저장되며 FAT,inode,free space 등의 구조를 포함한다.
컴퓨터가 켜지면 CPU는 booting을 해야한다. CPU는 메모리 접근만 가능한데 RAM은 휘발성 저장 매체이다. 그래서 비휘발성인 ROM에 small bootstrap loader를 저장해두고 booting과정에 이를 실행한다. 이것이 실행되면 sector0 의 full bootstrap loader program을 실행하여 OS를 디스크에서 load하여 실행한다.
disk scheduling(seek time을 줄이기 위한)
FCFS: 먼저온 것을 처리한다.
SSTF(shortest seek time first) : seek time 최소화 ,but starvation 문제
SCAN: sector 0 -> sector-1 -> sector 0 ... 을 탐색하며 실행(엘레베이터 시스템) disk header 가 지나간 직후에 들어온 요청은 대기시간이 길다.
C-SCAN : sector 0 -> sector-1 을 반복 (돌아오는 과정에서는 요청을 처리하지 않음) 균일한 대기시간을 보장해줄 수 있다.
LOOK : SCAN 방식에서 더이상 갈 길에 요청이 없으면 방향을 꺽는 방법
C-LOOK : C-SCAN 방식에서 더이상 갈 길에 요청이 없으면 시작점으로 돌아오는 방법
swap area : 공간효율성보다 시간효율성이 더 중요하다. 따라서 block의 크기 및 저장 방식이 일반 파일 시스템과 다르다. sector 단위가 일정하지 않을 수 있다.
RAID(Redundant Array of Independent Disks)
여러개의 디스크를 묶어서 사용하는 방식을 말한다. 여러 디스크에 block의 내용을 분산저장해 읽을때는 병렬적으로 읽어 디스크 처리 속도를 향상 시킬 수 있다.(interleaving:병렬읽기,striving:병렬쓰기) 동일 정보를 여러 디스크에 중복저장할 수 도 있는데 하나의 디스크가 고장시 다른 디스크에 읽어올 수 있어 신뢰성(reliability) 향상을 가져올 수 있다.(Mirroring,shadowing) 단순한 중복 저장이 아니라 일부 디스크에 parity를 저장하여(eg.hash함수를 적용한 값) 공간 효율성을 높일 수 있다.
