YARN
What is YARN
- Yet Another Resource Manager의 준말
- Hadoop version 1 까지는 MapReduce와 resource manager가 monolithic이였다. 그러다 version 2 부터 MapReduce와 YARN으로 분화됨
- YARN위에 직접적으로 코딩할 필요가 없을정도로 많은 기술이 존재한다.
- YARN은 HDFS위에서 동작하며 특정 job, task, application chunk를 실행시킨다.
- YARN은 cluster전체의 computation 자원을 나누는 역할을 한다.
- YARN은 data locality를 고려하여 data를 소유하고있는/가까운 node에게 작업을 할당한다.
- YARN applications으로 Tez, Spark, MapReduce가 존재한다.
- Application에 scheduling option을 선택할 수 있다.
- 동시에 많은 application을 수행할 수 있음
- FIFO : First In First Out
- Capacity : 남는 capacity가 충분하다면 application을 병렬적으로 실행
- Fair schedulers : 큰 작업이 실행중인 상황에 작은 작업이 요청되면 작은 작업이 필요로 하는 만큼의 자원을 양보
- 만약X100 엄청난 아이디어가 떠올라 YARN application을 새로 만들어야 한다면 Apache Slider , Apache Twill 와 같은 높은 추상화를 지원하는 framework를 사용하는 것을 추천
How YARN works?
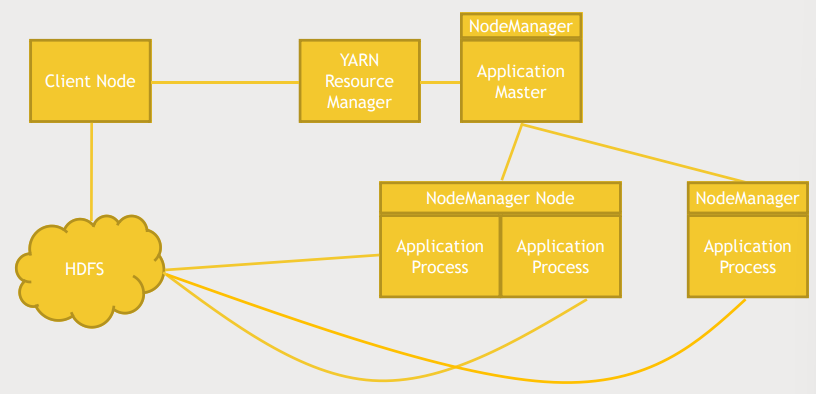
- YARN에게 MapReduce job을 실행할 것을 알림, 동시에 HDFS에 접근
- YARN은 적당한 node의 Nodemanager에게 Application master 실행명령을 내림
- Application master
- Application Process를 감시함
- Resource manager와 협업해 job을 클러스터에 분배함
- Nodemanager
- job을 실행하는 모든 노드들은 nodemanager에 의해 추적됨
- 노드가 무엇을 하고 있고 사용 가능한지, 작업 중인지 등을 추적함
TEZ
What is TEZ?
- Job을 더욱 효율적으로 처리하기위해 DAG의 형태로 Job을 재구성한다.
- MapReduce가 Job을 순차적으로 실행하는데 반해 TEZ는 Job을 더 전체적으로 보고 필요없는 과정을 제거한다.
- 물리적인 data flow를 최적화한다. 필요없는 데이터의 움직임을 최소화한다.
- Hive, Pig 는 MapReduce, Tez 모두 사용가능
- Tez를 활용하면 Hive, Pig가 요구하는 job을 MapReduce보다 빠르게 실행할 수 있다.
Directed Acyclic Graphs
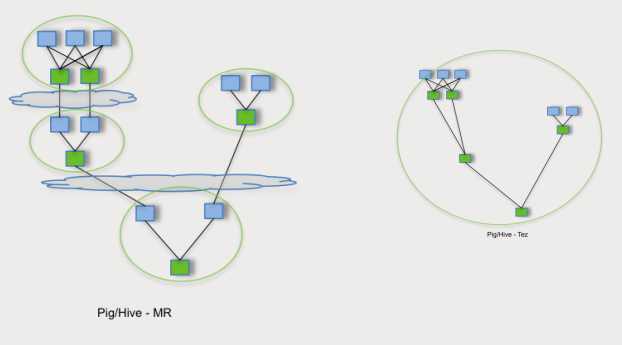
- MapReduce에서는 Map, Reduce를 순차적으로 실행
- TEZ를 활용하면 Reuducer를 거친 데이터를 바로 Reducer로 보내는 방법과 같이 필요없는 중간 단계를 제거하여 더 빠르게 데이터를 처리할 수 있다.
MESOS
What is MESOS
- MESOS는 Twitter가 개발한 application으로 Twitter에서 운영하는 data center(s)의 computing resource를 관리하기 위해 만들었다.
- MESOS는 Hadoop과 직접적인 연관이 없다.
- Myriad package를 이용해 YARN과 MESOS를 통합할 수 있음
- data center와 Hadoop cluster의 computing resource를 통합하여 사용할 수 있다.
- 컴퓨팅 리소스를 더 효율적으로 사용할 수 있다.
YARN vs MESOS
- YARN
- Hadoop task에 국한되어 있다.
- Hadoop cluster의 resource manage
- monolithic scheduler
- 모든 작업의 스케줄링, 할당, 및 감시가 중앙에서 이루어지기 때문에 클러스터 전체의 리소스 사용률과 작업 간의 리소스 공유에 대한 관리가 단일 지점에서 처리됩니다.
- 중앙집중적인 방식으로 리소스를 관리
- big data나 Hadoop cluster에서 의미를 추출해내는 긴 분석 작업에 최적화되어 있음
- MESOS
- 더 일반적인 resource manager이다.
- data center의 resource manage
- dual tiered system
- 상위 계층에서는 클러스터 수준의 리소스 관리를 담당하고, 이를 클러스터 내의 다양한 프레임워크(예: 맵리듀스, 스파크, 도커 등)에게 제공합니다.
- 하위 계층에서는 프레임워크 내에서 작업 간의 리소스 관리를 처리합니다.
- 클러스터의 리소스 사용을 더 유연하게 관리할 수 있고, 다양한 프레임워크 간의 리소스 공유와 격리를 효과적으로 처리할 수 있습니다.
- 만약 거대 computing resource를 가지고 a massive amount of different kinds of jobs 를 수행햐아한다면 MESOS가 좋은 선택
- 계속 실행되는 서버와 같은 장기간 실행되는 프로세스뿐만 아니라 짧은 수명을 가진 프로세스들도 잘 처리함. 다양한 주기, 작업유형을 처리하는데 더 최적화되어 있음
- Kubernetes / Docker 는 이러한 작업의 대안이 되기도 함
- Spark 와 Strom을 사용해 분석작업을 한다. → MESOS
- 데이터가 HDFS에 적제되어 있다. → YARN
- Spark on YARN
- 한 노드에 여러 개의 executor를 실행할 수 있다. 이는 YARN이 노드에 대한 자원 관리와 작업 스케줄링을 독립적으로 수행하기 때문이다.
- 노드에 여러 개의 Spark executor가 동시에 실행될 수 있습니다. 이는 노드의 자원을 효율적으로 활용하고, 동시에 다양한 Spark 작업을 처리하는 데 유리합니다.
- Spark on MESOS
- 한 노드에 하나의 executor만 실행될 수 있습니다. 이는 Mesos 자체의 디자인 철학에 따라, 각 노드에 할당된 자원을 그 노드에서 실행되는 작업에 전담하여 사용하도록 하는 것입니다.
Zookeeper
What is Zookeeper?
- cluster에 동기화되어야하는 정보를 추적하는 역할
- master node는 누구인가?
- 어떤 worker node에 어떤 일을 할당하였는가?
- 어떤 worker가 놀고 있는가?
- application에 발생한 partial failure를 recover해줌
- failure modes
- Master crashes
- Master가 다운된것을 감지하고 Master 후보자중 하나를 Master로 지정
- Worker crashes
- 해당 worker가 하던 일을 다른 worker에게 재분배
- Network trouble
- 네트워크 문제로 cluster가 둘로 나뉘어 서로 소통할 수 없는 상태
- 둘 중 하나만 동작해야함
Primitive operation in a distrbuted system
- Master election
- master는 하나만 존재하며, 해당 master는 data에 lock을 건다.
- 해당 lock이 release되기 전에는 다른 node들은 master가 될 수 없다.
- lock을 동시에 두 node가 가지는 것은 불가능하다.
- Crash detection
- node의 연결이 끊어지면 node의 "Emphemeral" data가 자동으로 소멸됨
- Group management
- Metadata
- 아직 완료되지 않은 작업, 작업할당에 대한 정보를 유지할 필요가 있음
Zookeeper API
- API like "choose a master," "who is the master," or "tell me who's in this worker group" 와 같은 specific API를 제공하는 대신 어떠한 application이던지 read/write를 할 수 있는 일관성이 강한 작은 분산 파일 시스템을 제공한다.
- 그리고 이러한 분산 파일 시스템을 이용하여 각각의 application은 알아서 failure를 처리한다.
- 분산 파일 시스템에는 여러개의 znode가 존재하며 znode에는 누가 master인지, 특정 job을 어떤 worker가 수행하고 있는지 등을 나타낸다.
- Notification
- znode client는 어떤 znode에 대한 notification을 구독할 수 있다.
- 해당 znode가 go away되거나 변경되면 zookeeper는 znode client에게 이를 알림
- Persistent znode
- Client가 crash 혹은 zookeeper와 연결이 끊어져도 데이터를 유지하는 znode
- master가 crash되도 workers에게 할당된 task가 무엇인지 유지해야함
- Ephemral znode
- Client가 crash 혹은 zookeeper와 연결이 끊어지면 데이터를 날리는 znode
- master가 crash되면 새로운 master가 해당 znode를 차지하기위해 znode의 data를 날려야함
Zookeeper Arichitecture
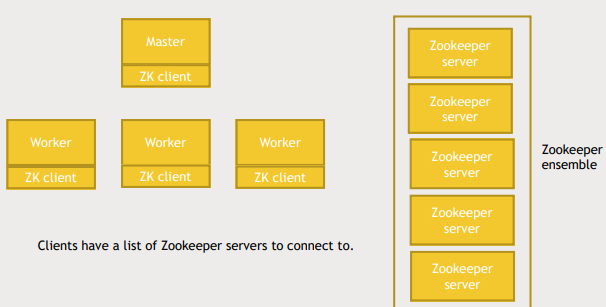
- zookeeper server는 consistency를 보장하기위해 여러개여야함
- zookeeper server의 묶음을 zookeeper ensemble이라고함
- zookeeper 의 consistence level을 지정할 수 있고 이를 quorums라고함
- quorums가 만약 3으로 설정되어 있다면 zookeeper ensemble은 5개의 server를 가져야함
- 만약 network partition이 일어나 5개의 server가 3,2로 나눠지면 둘 중 하나만 작동해야하기 때문이다.
- 만약 quorums가 2로 설정되어 있었다면 두개 모두 작동하는 split brain이 일어난다.
실습(Znode 생성해보기)
$ cd /usr/hdp/current/zookeeper-client/bin/
$ ./zkCli.sh
# zookeeper 에게 관리되는 application list
[zk: localhost:2181 (CONNECTED) 0] ls /
# emphemeral znode 생성
[zk: localhost:2181 (CONNECTED) 1] create -e /testmaster "127.0.0.1:2223"
[zk: localhost:2181 (CONNECTED) 2] get /testmaster
[zk: localhost:2181 (CONNECTED) 3] quit
$ ./zkCli.sh
[zk: localhost:2181 (CONNECTED) 0] get /testmaster
Node does not exist: /testmaster
[zk: localhost:2181 (CONNECTED) 1] create -e /testmaster "127.0.0.1:2225"
[zk: localhost:2181 (CONNECTED) 2] create -e /testmaster "127.0.0.1:2225"
Node already exists: /testmaster
[zk: localhost:2181 (CONNECTED) 3] quit
Oozie
What is Oozie
- Hadoop task들을 schedule 하는 역할
- Elephant keeper 를 뜻하는 미얀마어
- task들을 dependency에 따라 DAG로 scheduling하고 이를 XML 파일로 표현함
- 다양한 종류의 node로 DAG를 표현함
- start, end node : workflow의 시작과 끝을 알리는 node
- action node : 작업을 명시하는 node
- fork, join node : workflow가 분기와 join을 알리는 node
- kill node : task를 강제 종료하는 node
- workflow 를 나타내는 xml파일은 hdfs에 저장된다.
- oozie server에 workflow에 사용될 변수를 지정한는 .properties파일이 존재하며 해당 변수는
${} 형태로 xml파일에서 활용된다.
nameNode=hdfs://sandbox.hortonworks.com:8020
jobTracker=http://sandbox.hortonworks.com:8050
queueName=default
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/maria_dev
- oozie server에서
oozie job -oozie http://localhost:11000/oozie -config job.properties –run 와 같은 형태의 명령어를 입력하면 oozie 서버 활성화 가능
--oozie : Oozie 서버의 URL을 지정하는 옵션-config : Oozie 서버내의 .properties 파일의 위치를 지정
- Oozie Coordinator : oozie job을 periodic하게 실행하거나 어떤 event가 일어나면 job을 실행하는 것을 가능하게 함
- Oozie bundles
- collection of coordinators
- 동시에 관리되어야할 coordinator를 지정할 수 있다.
- eg. 같은 source를 활용하는 coordinator
실습
- movielens database를 mysql에 업로드
$ wget http://media.sundog-soft.com/hadoop/movielens.sql
$ mysql -u root -p
mysql> set names 'utf8';
mysql> set character set 'utf8';
mysql> create database movielens;
mysql> use movielens;
mysql> source movielens.sql;
mysql> grant all privileges on movielens.* to ''@'localhost';
mysql> quit
- Hive script file 다운로드
$ wget http://media.sundog-soft.com/hadoop/oldmovies.sql
- workflw.xml, job.properties 파일 다운로드
$ wget http://media.sundog-soft.com/hadoop/workflow.xml
$ hadoop fs -put workflow.xml /user/maria_dev
$ hadoop fs -put oldmovies.sql /user/maria_dev
$ wget http://media.sundog-soft.com/hadoop/job.properties
- mysql 과 sqoop을 연결하기위해 sql connector를 hdfs에 저장
$ hadoop fs -put /usr/share/java/mysql-connector-java.jar /usr/oozie/share/lib/lib_20161025075203/sqoop
- ambari-services-oozie-service actions-restart all
- oozie 실행 및 확인
oozie job -oozie http://localhost:11000/oozie -config /home/maria_dev/job.properties –run
