Hadoop 이란
- Software platform : pc 한대가 아닌
cluster of computers라는 의미 Distributed storage: cluster of computers에 나눠 저장,redundant(백업용으로 반복해서 저장)Distributed processing: cluster of computers의 자원을 통해- hadoop은 구글이 발표한 GFS(Google File System), MapReduce로 시작(2003~2004)
- GFS는 분산저장에 대한 것이고 MapReduce는 분산처리에 대한것
- Yahoo는 GFS,MapReduce를 통해 Hadoop을 발표함
- hadoop은 원래 batch processing을 위해 개발됨
- Hadoop의
Horizontal scaling은 그 이외의 많은 이점을 가져옴- disk seek time 감소 (cluster of computers 를 활용하므로 여러개의 hard disk를 사용)
- hardware failures 가 일어나도 backup한 내용을 가져오면됨
- processing time(cluster of computers 자원을 병렬 처리함)
Hadoop ecosystem
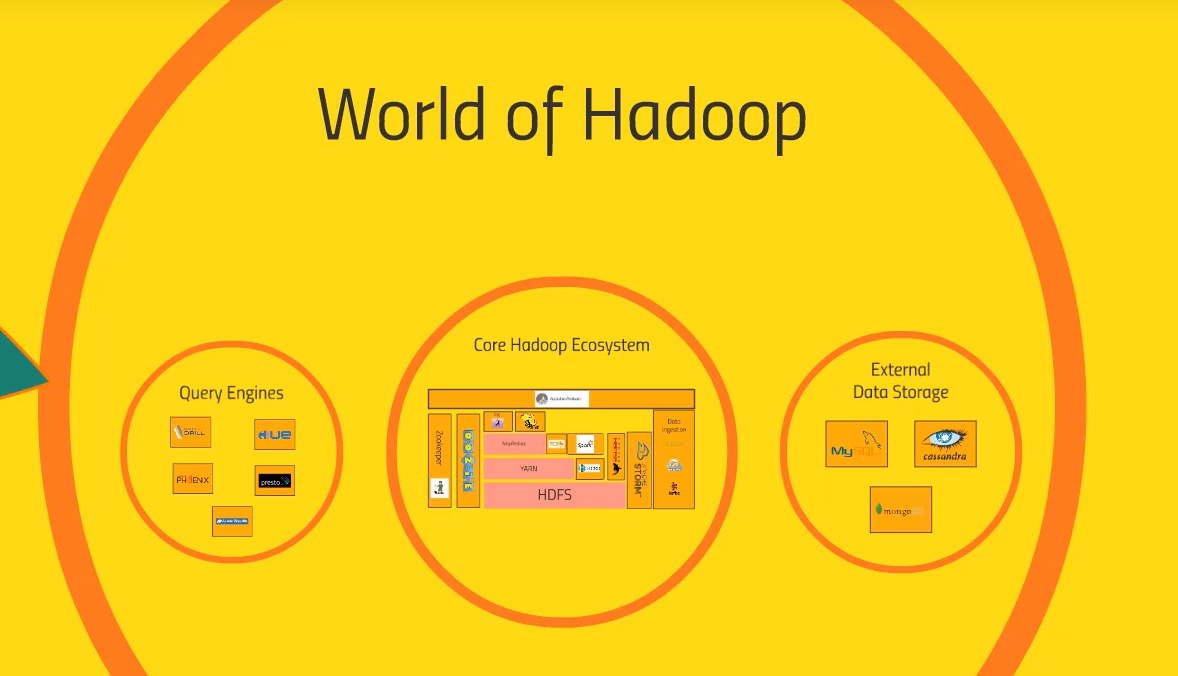
Hadoop의 생태계는 Hadoop에 관련된 application의 집합이다. 원래 하둡의 구성요소는 HDFS, YARN+MapReduce 였다. 하지만 특정 문제에 대한 더 효율적인 처리가 요구됨에 따라 많은 application이 등장했다. 원래 YARN과 MapReduce도 합쳐져있었는데 MapReduce와는 다른 방식으로 문제를 푸는 application이 요구됨에 따라 YARN과 MapReduce가 분리되었다. 이렇게 Hadoop의 생태계는 계속 발전하고 있다.
Core Hadoop Ecosystem
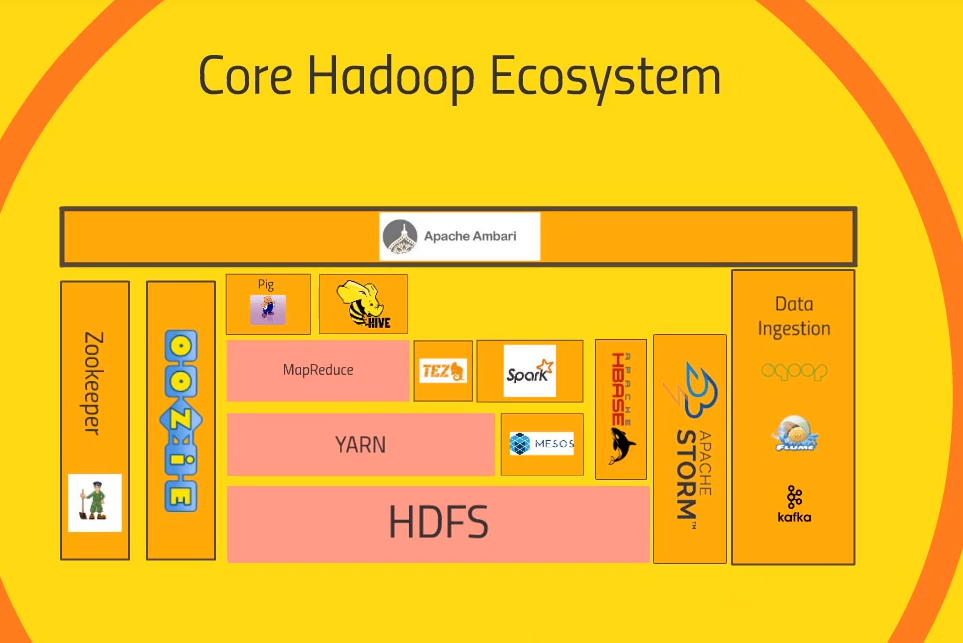
HDFS(Hadoop Distributed File System)
- GFS의 Hadoop 버전, 즉 Data Storage
- Cluster내의 File System을 하나의 거대한 File System으로 사용
- 백업을 자동으로 수행하기 때문에
Reliable함
YARN(Yet Another Resource Negotiator)
- Data Processing이 시작되는 부분
- Computing Cluster의
Resource를 관리하는 역할 - 어떤 node가 일을 처리할지
- 언제, 어떤 node를 사용할 수 있는지 등등
Resource manager,Node manager를 통해 자원을 관리
MapReduce
- 전체 클러스터를 이용해 데이터를 처리하게 해주는 programming metaphor/model
Mapper와Reducer로 구성, 만약 MapReduce 프로그램을 작성한다면 Script를 각각 작성해야함- Mapper : data를
parallel하게 처리해줌 - Reducer : Mapper의 처리 결과를
Aggregate해줌
Pig
- Java, Python 을 통해 MapReduce 코드를 작성하는 대신 사용자가
SQL과 유사한 Script를 작성하면 이를MapReduce가 해석할 수 있는 코드로 변환해주는 application - 따라서 High level API라고 할 수 있음
Hive
- 역시 MapReduce 위에서 동작하며 Pig와 유사한 역할을 함
Pig에 비해 더 SQL스러움- 실제로 SQL 쿼리를 받아 분산 데이터베이스를 SQL DB처럼 취급
- Shell client or ODBC로 연결 가능
Ambari
- Cluster에 대한 Dashboard를 제공(System별 Resource 사용량..)
- Hive/Pig query를 실제로 실행하거나 DB를 import할 수도 있음
- Ambari는 Hortonworks 제품(Hortonwroks는 Cloudera에 2019년에 합병됨)이며 이와 유사한 긴으을 하는 솔루션이 어려개 있음
- ex) Cloudera의 MapR
MESOS
- MESOS는 Hadoop의 부분이라고 보기는 적절치 않지만
YARN의 대안이 될 수 있음(역시 Resource Negotiator) - YARN과는 다른 방식으로 문제를 해결하며 YARN과 함께 사용되기도 한다.
SPARK
MESOS 소개한것은 SPARK를 설명하기위해가져왔다고 할정도로 SPARK가 대단한 기술(Spark는 MESOS위에 있음)- MapReduce와 유사하게 데이터 처리에 관한것이며 YARN, MESOS위에서 동작가능
- MapReduce와 마찬가지로 어느정도 프로그래밍이 요구됨(python, scala, java | 이중 scala가 가장 선호됨)
- 클러스터의 데이터
고속/효율/안정적인 처리지원 - Spark는 매우 versatile(다재다능)함, 그 중 MLlib(Machine Learining Library) 은 쉽고 확장성 있게 머신러닝 파이프라인을 개발할 수 있게 도와줌
- Realtime streaming data 처리도 지원, 이외에도
다양한 기능 지원
TEZ
- Spark와 유사한 기술을 사용하면서
directed acyclic graph로 query 계획을 더효율적으로 설계함 - DAG는 MapReduce가 하는 일에 대해 TEZ에게 leg up을 제공함
- 보통
Hive와 함께 사용됨(Hive는 TEZ위에 있기도 하다고 볼 수 있음) - Hive가 MapReduce를 사용할지 TEZ를 사용할지는 문제상황에 잘 맞게 사용하면됨
HBase
- Transactional platform에 cluster의 데이터를 노출시켜주는 역할을함 (NoSQL)
- Columnar data store임(transaction rate가 굉장히 빠른 데이터베이스)
- Web site, Web application 등 large transaction rate이 요구되는 곳에 적절함
- HBase는 클러스터에 저장된 데이터를 보여주며 그러한 데이터들이 Spark이나 MapReduce와 같은 것들에 의해 transform되면 빠르게 그 결과를 다른 시스템에 보여줌 (
consistency)
Apache Storm
- streaming data(sensor, web log와 같은 데이터) 처리 application
- Spark streaming도 실시간 데이터 처리, 작동 방식이 다름
- data transform의 실시간 처리, 실시간 데이터를 통해 실시간 머신러닝 모델 학습도 가능
Oozie
- cluster의 job을 scheduling하는 역할
- task가 복잡한 단계와 수많은 시스템을 이용한다면 job schuduling을 해서 reliable, consistent하게 실행되게 해줌
Zookeeper
- 클러스의 모든 것을 조직화하는 기술
- node의 up, down 여부를 감시 (reliablity)
- shared states 에 대한 추적을 한다. (consistency)
- 여러 응용 프로그램이 동시에 실행될 때, 이들은 서로간에 데이터 또는 상태를 공유해야 할 수 있습니다. 예를 들어, 여러 응용 프로그램이 동일한 데이터에 대한 접근을 조율하거나, 클러스터 내에서 작업이 완료된 상태를 추적하는 등의 상황
- 많은 application들이 zookeeper에 의존
- 외에도 많은 기능을 함
Data Ingestion
- external source로 부터 cluster, HDFS에 정제하는 다양한 방법이 존재
Sqoop- Hadoop database와 ODBC,JDBC와 통신이 가능한 데이터베이스 연결해주는 역할을 한다.
- 즉 Scoop을 통해 Hadoop과 legacy database와 연결을 할 수 있다.
Flume- 대량의 Web log를 reliable하게 운반해주는 역할
- 대량의 Web servers를 운영한다면 Flume을 통해 Web log를 listen하고 Spark streaming 혹은 Strom을 통해 실시간처리하여 cluster에 적제하는 것을 고려할 수 있다.
Kafka- Flume보다 더 일반적인 목적을 가짐
- a cluster of web servers, a cluster of PCs .. any sort 에서 data 를 collect
External Data Storage
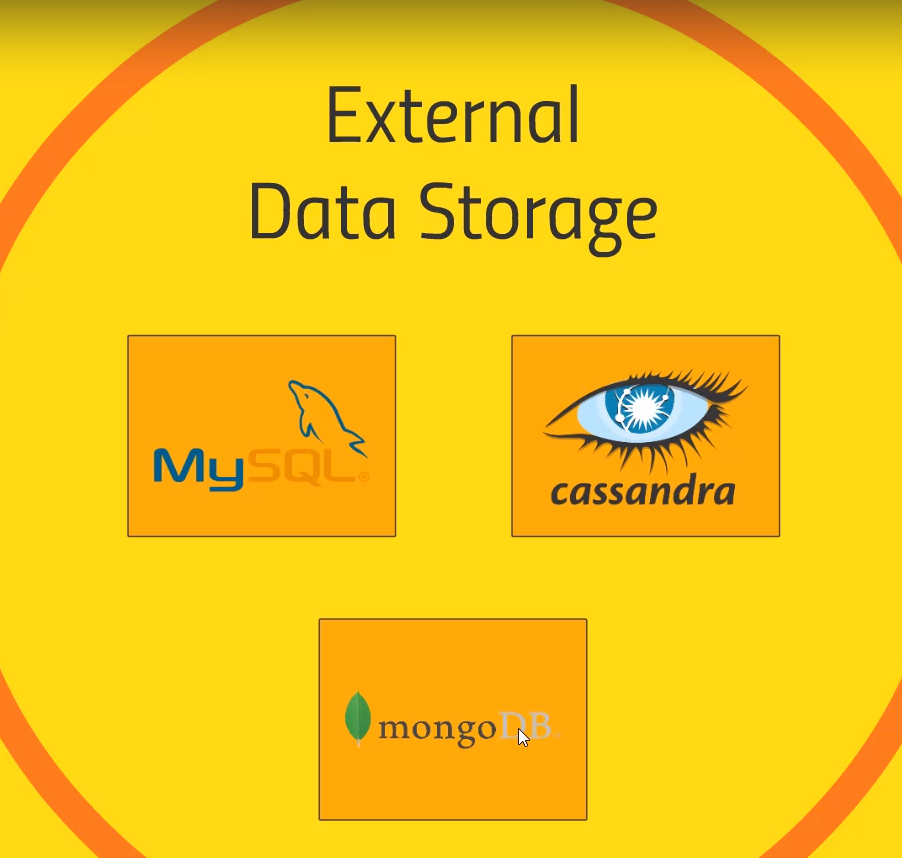
- 사실 HBase도 여기 포함되어야하지만 HBase는 다른것에 비해 Hadoop에 더 밀접하게 관련이 있어서 따로 설명함
SQL DB- Sqoop으로 data를 cluster로 가져올 수 도 있고, 반대로 Spark으로 any JDBC or ODBC database data를 다시 SQL DB로 export 할 수도 있다.
Cassandra, MongoDB- 모두 NoSQL로 Web application에서 데이터를 실시간으로 노출하는데 활용 가능
- 그래서 realtime application과 cluster사이에 mongodb나 Cassandra와 같은 것을 활용하여 layer를 생성하는 것이 좋다.
- 모두 대용량 트랜잭션 처리가 가능한 간단한 key-value data store로 매우 인기 있는 선택지
- cluster에서 이러한 external data storage를 요긴하게 쓸 수 있다.
Query Engines

- Hive도 이 범주에 속하지만 Hive는 Hadoop과 굉장히 밀접한 관련이 있음
- 여기서 소개될 query engine은 다른 범주의 것과 호환이 안될 수도있다.
Apache Drill- 다양한 NoSQL에게 SQL query를 날릴 수 있게해줌
- HBase, Cassandra, MongoDB 등에 query를 날릴 수 있음
- 하나의 query로 다양한 NoSQL 데이터베이스에 query를 날려서 결과를 합칠 수 있음
Hue- Hive, HBase에 잘 작동하는 쿼리를 대화형으로 생성할 수 있다.
- Cloudera에서는 HUE가 Ambari의 역할을 담당하여 모든 것을 내려다볼 수 있도록 시각화하고 전체 Hadoop 클러스터에 쿼리를 실행
Apache Phonix- Apache Drill과 유사하게 전체 데이터 스토리지 기술에 걸쳐 SQL 스타일의 쿼리를 할 수 있음
- 한 단계 더 나아가 ACID, OLTP를 제공함
- ACID가 보장되서 RDB가 아닌 Hadoop data store를 RDB와 매우 유사해짐
Presto,Apache Zeppeline: 역시 전체 클러스터에 쿼리를 날릴 수 있게 해줌Apache Zeppeline은 UI 접근과 cluster의 상효작용을 notebook type 으로 제공
