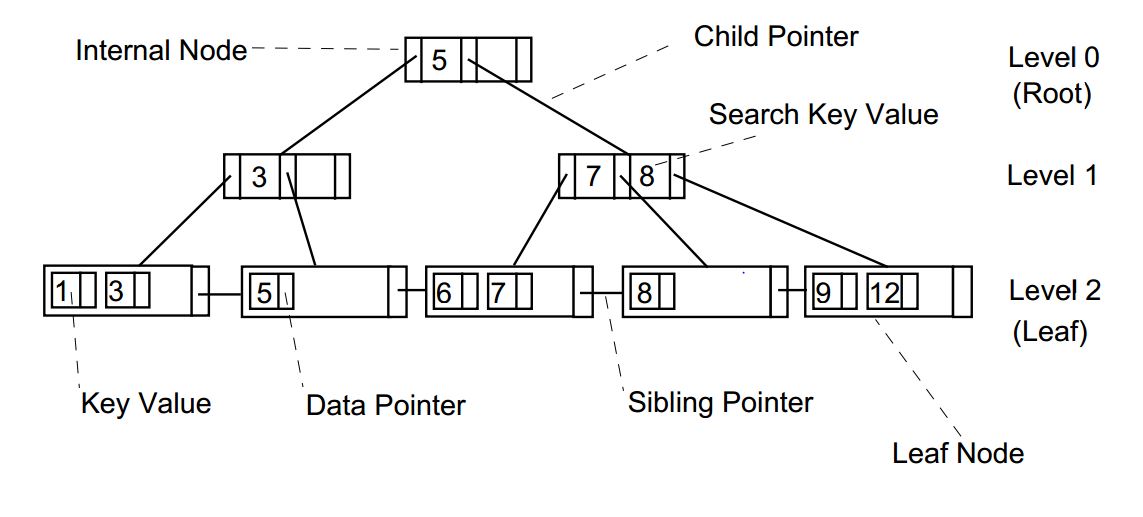
https://blog.sysbot32.com/entry/DB%EC%97%90%EC%84%9C-Index%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%B4-%EB%8D%B0%EC%9D%B4%ED%84%B0%EC%97%90-%EC%A0%91%EA%B7%BC%ED%95%98%EB%8A%94-%EA%B3%BC%EC%A0%95