채식음식점 같은 인증 데이터가 서울시만 가지고 있기 때문에 인증되지는 않았지만 채식 가능 식당으로 '검색'되는 식당 정보를 직접 크롤링하는 방향으로 작성하고 있다.
# 채식 식당 데이터
## 서울시 인증 채식식당
- 채식 가능 음식점
- 채식 음식점
## 채식 가능으로 검색되는 식당
- << 크롤링으로 긁어올 부분 >> 크롤링 사전 조사
참조한 블로그: 자바스크립트로 크롤러 만들기 2편: 웹페이지 크롤링을 위한 배경 지식 알아보기
크롤링이란
- 컴퓨터 프로그램을 작성하여 자동화된 방법으로 웹페이지 전체 또는 일부를 추출하여 정보를 얻는 방법
- 스크래핑이라고도 한다.
크롤러의 필요성
- 내가 원하는 데이터를 대가없이 뿌려주는 공식 API가 있다면 크롤링할 필요가 없다.
- 직접 크롤러를 작성해서 탐색하고자 하는 웹사이트에서 내가 원하는 데이터를 주기적으로 수집할 수 있다.
크롤링 시 주의사항
- 무분별한 크롤링으로 사이트 측에 과도한 트래픽을 유발하지 않도록 한다.
- 정보 제공자가 많은 노력을 들인 데이터를 함부로 크롤링하면 법적 문제가 발생할 수 있다. 크롤링해도 문제가 없는 지 꼭 확인해야 한다.
파이썬 말고 JavaScript 크롤러를 작성하는 이유
- 자바스크립트에서는 JSON 형식을 기본적으로 지원하기 때문에 사용이 편하다.
- 데이터가 웹페이지의 자바스크립트 코드 안에 존재하는 경우 별다른 설정 없이 해당 코드를 읽어들여서 실행하는 것이 가능하다.
- 위 두가지 장점 모두 파이썬에서도 가능하지만 추가 구현이 필요하다고 한다.
puppeteer
- 헤드리스 브라우저를 프로그래밍 방식으로 조작하는 라이브러리다.
- 헤드리스 브라우저는 GUI가 없는 웹 브라우저를 의미한다. 다른 웹 브라우저들과 비슷한 환경에서 웹 페이지의 자동화된 제어를 제공하지만 CLI나 네트워크 통신을 사용하여 실행된다.
- launch() 메서드에서
{ headless: false }를 설정해주면 실제로 크로뮴이 떠서 작동하는 것을 확인할 수 있다. 대신 slowMo 속성까지 써줘야 정확히 확인할 수 있다. 속도가 빠르기 때문에 그렇다.
- 헤드리스 브라우저로 사용되는 최신버전의 크로뮴이 자동으로 node_modules/puppeteer 경로 내부에 기본적으로 설치 된다.
- 크로뮴은 크롬의 기반이 되는 오픈소스 웹 브라우저 프로젝트이다.
- 기본적인 웹 브라우징 기능이 동일하기 때문에 크롤러를 만드는 데 문제가 없다.
import puppeteer from 'puppeteer';
import fs from 'fs';
(async () => {
const browser = await puppeteer.launch({ slowMo: 300 });
const [page] = await browser.pages();
await page.goto(`https://map.kakao.com/?q=채식`);
const totalDom = await page.$('#info\\.search\\.place\\.cnt');
let totalNumForResult = await page.evaluate((em: any) => Number(em.innerHTML.replaceAll(',', '')), totalDom);
let dataInAllPage = new Array();
for (let currentPage = 1; currentPage <= Math.trunc(totalNumForResult / 15) + 1; currentPage++) {
const pageContent = await page.$$eval('.link_name', (elements) => {
let dataInPage = new Array();
for (let element of elements) {
dataInPage.push({
title: element.innerHTML.replace(/[<strong>|</strong>]/g, ''),
category: element.parentElement?...,
rating: element.parentElement?...,
address:
element.parentElement?...,
});
}
return dataInPage;
});
dataInAllPage.push(...pageContent);
if (currentPage === 1) {
await moreButton.evaluate((b: any) => b.click());
} else if (currentPage % 5 === 0) {
const nextButton = (await page.$('#info\\.search\\.page\\.next')) as any;
await nextButton.evaluate((b: any) => b.click());
} else {
const pageNation = (await page.$('#info\\.search\\.page\\.no' + `${(currentPage % 5) + 1}`)) as any;
await pageNation.evaluate((b: any) => b.click());
}
}
fs.writeFileSync('./kakaoMapCrawling.json', JSON.stringify(dataInAllPage));
await browser.close();
})();
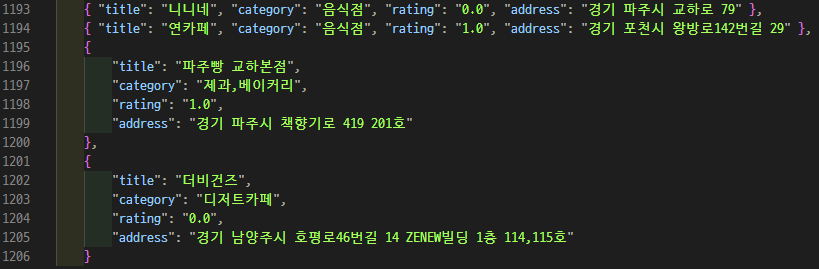
puppeteer 클릭작업이 많을 경우 꿀팁
slowMo 속성 사용해서 전체 속도 줄이기
- 클릭 => 기다림 => 작업
- 카카오맵은 검색어를 쿼리로 접근할 수 있지만 페이지네이션은 불가능했다. 그래서 페이지 링크의 클릭을 많이 해야 했다.
- n초 기다림을 주는 이 방법을 해도 통하지 않으면 slowMo가 방법이다. puppeteer의 속도가 빨라서 아무리 코드에서 지연을 시켜도 중복되거나 정확한 자료가 나오지 않았는데, sloMo로 해결됐다. 이 속성은 디버깅할 때도 매우 유용하다.
// 인위적인 시간 지연을 주는 방법
new Promise(() => setTimeout((r) => r, 3000));
// 전체 작업을 Xms 만큼 늦추는 방법
const browser = await puppeteer.launch({ slowMo: 200 });slowMo 숫자가 커질수록 전체 작업이 느려진다. 적당한 시간을 할당해줘야 하는데, 카카오맵에 직접 적용했을 때 100ms 지연은 너무 빨랐고 250ms 지연은 너무 느렸다. 200ms으로 데이터가 중복없이 잘 수집되어서 200ms로 결정했다.
DOM의 id 속성에 .이 있는 경우
이 경우에는 두 개의 백슬래시로 이스케이프해야 한다.
const result2 = await page.$('#info\\.search\\.place\\.cnt');
let total = await page.evaluate((em: any) => em.innerHTML, result2);
console.log(total); // 273실제 동작 확인하기
처음 puppeteer를 사용할 때는 브라우저 콘솔에다가 코딩하는 기분이었다. 직접 실행되는 모습을 보고 개발자 도구도 키고 싶다면 아래 설정을 주면 된다.
const browser = await puppeteer.launch({ headless: false, devtools: true });트러블 슈팅
카카오맵 장소 갯수와 페이지네이션 계산이 안맞다.
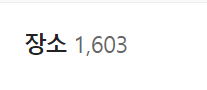
이 1603을 기준으로 총 페이지수를 계산했을 때 총 107페이지가 나와야 하는데, 실제로는 34페이지밖에 안나온다...
Math.trunc(1603 / 15) + 1 = 107 인데 왜이렇게 금방 끝나나 했다.
그래서 1603을 기준으로 계산돼서 for문을 돌고 있는 currentPage와 페이지 버튼 중 active되어 있는 버튼의 숫자를 비교해서 다르면 for문을 빠져나오도록 했다.
const activeButton = (await page.$('#info\\.search\\.page > .pageWrap > .ACTIVE')) as any;
const activeNumber = await page.evaluate((a: any) => a.innerHTML, activeButton);
if (currentPage === 1) {
const moreButton = (await page.$('#info\\.search\\.place\\.more')) as any;
if (moreButton) {
await moreButton.evaluate((b: any) => b.click());
} else break;
} else if (currentPage % 5 === 0) {
const nextButton = (await page.$('#info\\.search\\.page\\.next')) as any;
if (Number(activeNumber) === currentPage) {
await nextButton.evaluate((b: any) => b.click());
} else break;
} else {
if (Number(activeNumber) === currentPage) {
const pageNation = (await page.$('#info\\.search\\.page\\.no' + `${(currentPage % 5) + 1}`)) as any;
await pageNation.evaluate((b: any) => b.click());
} else break;
}
Frontend Engineer