torch Parser 만드는 부분은 오랜만에 정리하게 되었는데, 우선 torch Parser라는 이름을 정의하게 된 것도 제가 임의로 하게되었습니다.(일단 그전까지는 ‘반말’로 작성했었는데, 이제 다른 분들도 보실거같아서 ‘존댓말’로 작성하겠습니다.)
큰 의미는 없고, torch 모델을 분석하는 과정이기에 다음과 같이 정의하였습니다.
아직 Main(Onnx,TRT Inference)에 기능을 합치지는 못했지만, 일단 torch Parser를 만들면서 참고한 인사이트 여기를 보시면 어떻게 하다가 이지경까지 왔는지 아시게 될 것입니다..!
torch parser 내부 구조는 다음과 같이 구성했습니다.
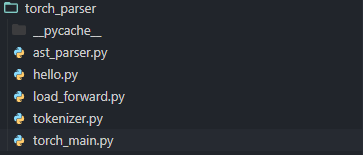
- torch_main.py : 모듈화시킨 다른 기능들을 실행시키는 스크립트,
torch_alert_func에서 모든 기능을 불러와 실행하게 됩니다. - ast_parser.py : 파이썬의 기본 모듈인 AST(Abstract Syntax Tree)를 사용하였는데, 소스코드의 특정 타입을 만나면 Node들을 방문할 수 있는 특징을 활용하였습니다. 컴파일러 중 일종의 Parser로 활용 가능합니다.
-
if 구문
-
호출형함수(call)
위의 두 가지 경우를 체크할 수 있도록 구현하였습니다.
-
- load_forward.py : 파이토치 모델을 불러오는 모듈입니다. 사용자로부터 다음과 같이 입력을 받습니다.
-
파이토치 모델 루트 디렉터리
-
파이토치 모델 Inference 코드가 있는 python 스크립트
-
Inference를 실행해야되는 클래스명
위의 내용들을 argument로 받게되면, 해당 스크립트에서는 절대 경로 및 모듈 형태로 반환해줍니다.
-
- tokenizer.py : ast_parser.py에서 체크해야될 IF 구문과 함수들을 딕셔너리로 반환해주는데, 이를 바탕으로 소스 코드 자체를 토크나이징하여, 몇 번째 줄에 해당 구문이 존재하며, 어떤 Operation이 Onnx로 변환 시, 제대로 변환이 안 될 수 있는지 로그를 띄워줍니다.
Main 실행 구문
- 기능별로 어떻게 모듈화 할 것인지
- 모듈들을 재귀적으로 체크해야되는데, 어떤식으로 처리할지
크게 두 가지를 가장 많이 고민했습니다.
‘1번’의 경우, 위의 패키지 구조를 말씀드리면서, 대충 설명드린거 같고, ‘2번’의 경우가 조금 어려웠습니다.
처음에는 DFS를 활용하여 모듈을 탐색해야된다고 생각했습니다.
DFS든 BFS든 상관은 없겠지만, 구현하다보니, BFS로 구현하게 되었습니다.
항상 시작은 사용자가 입력한 Inference 구문이 담긴 클래스를 기준으로 시작하며, 그 중 forward 구문이 시작점입니다.
-
forward 구문부터 탐색 시작
-
앞의 구문안에 다른 호출형 함수(python,torch 기본 함수 제외)가 존재할 경우, 큐(do_dict)에 저장 ←
function_checker에서 업데이트- 딕셔너리에서
popitem()하면서 탐색 importlib.util.find_spec(name): pytorch,python 기본 모듈인지 여부 체크name in visited: 이전에 방문했던 모듈(노드)인지 체크
- 딕셔너리에서
-
‘2번’ 조건에 걸리지 않는 경우, 소스코드로 변환(string)
function_parser(AST 탐색) 결과 if_list에 담아줌- if 구문 로그 띄워줌 :
goto_tokenizer(module,if_list)
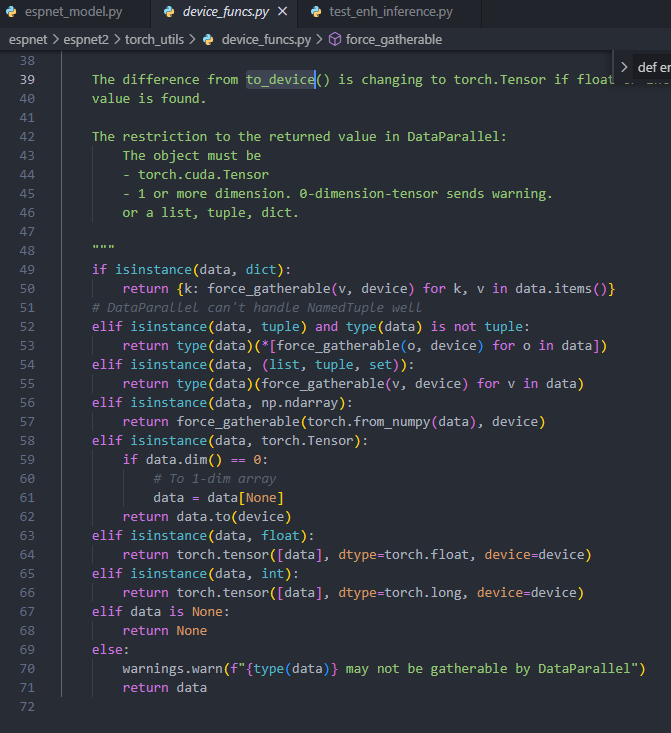
def torch_alert_func(model_root_dir,model_dir,class_name): # get packaage(module) and model class pkg,working_cls = load(model_root_dir,model_dir,class_name) do_dict = {'forward':working_cls.forward} visited = [] while do_dict: name,module = do_dict.popitem() if importlib.util.find_spec(name) or name in visited: continue code = textwrap.dedent(inspect.getsource(module)) if_list = function_parser(code) # alert if syntax goto_tokenizer(module,if_list) # update new function inside do_dict.update(function_checker(pkg,working_cls,if_list)) visited.append(name)
AST활용 노드 방문 구문
토크나이징 구문(로그 띄워주는)
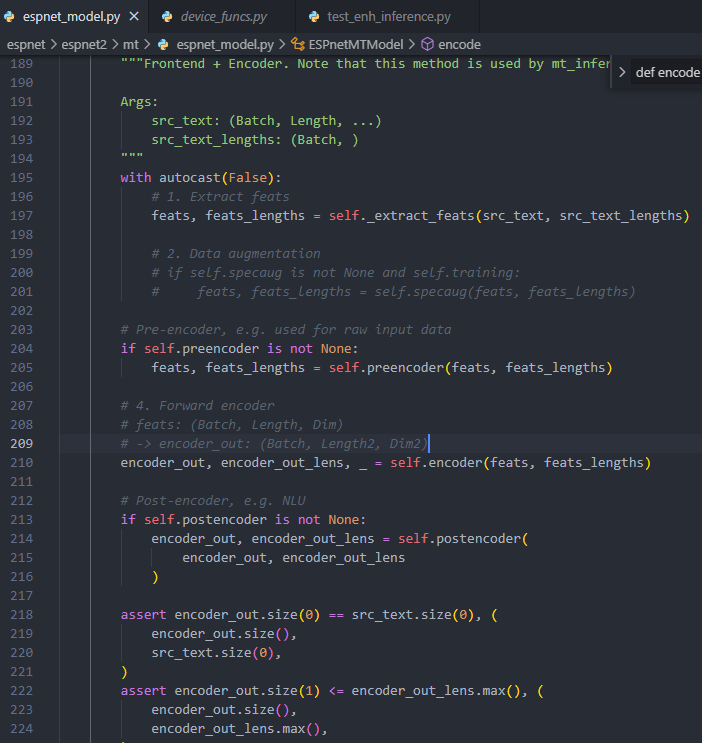
만약, if self.postencoder is not None: 이라는 구문을 토크나이징한다면, 아래와 같이 됩니다.

generate_tokens 함수를 활용하여 토크나이징해주게 되는데, 인자값으로 readline 형태만 들어갈 수 있습니다. 따라서 소스코드가 string 형태로 존재한다고 할 때, StringIO 형태로 형변환해줘야합니다.
def tokenize_source_code(module):
source_dir = inspect.getsourcefile(module)
source_file = load_from_tokenizer(source_dir)
source_code = textwrap.dedent(inspect.getsource(source_file))
f_code = StringIO(source_code)
file_name = os.path.basename(source_dir)
source_tokens = tokenize.generate_tokens(f_code.readline)
return file_name,source_tokens토크나이징 했을 때, 토크나이징 특정 소스 코드의 한 함수 부분이 아니라, 전체 소스코드입니다. 만약 원하는 함수 구문만 토크나이징 했을 때, start와 end에 코드 라인정보가 담기는데, 실제 소스코드 라인 정보가 담기는 것이 아니라 함수 내에서 몇번째 줄에 위치해있는지에 대한 라인정보만 담겨있습니다. 따라서 어쩔 수 없이 전체 소스코드를 토크나이징 했습니다.
하지만 전체 소스코드를 토큰으로 두고 보았을 때, 필요하지 않은 부분까지 탐색하기 때문에, 정보가 필요한 함수(모듈) 구문만을 따로 토크나이징하였습니다. 이후, 해당 함수 구문의 시작 라인 정보를 갖고, 해당 라인이 전체 소스코드에서 몇 번째 줄에 위치하였는지 정보를 넘겨주었습니다.
이후, 그 라인 아래와 소스코드만을 분석하고 로그를 띄워줄 수 있도록 처리하였습니다.
def print_log(module,if_list):
_branch_op = ['if','elif','else']
_plist = if_list['if']
chk_startline = False
pstate = None
start_line = math.inf
if not _plist:
return
file_name,source_tokens = tokenize_source_code(module)
module_start_line = get_module_start_line(module)
for token in source_tokens:
if token.line.lstrip() == module_start_line and chk_startline == False:
start_line = token.start[0]
chk_startline = True
if token.start[0] >= start_line:
if token.type == 1 and token.string in _branch_op:
for param in _plist:
if param in token.line:
line_num = token.start[0]
if pstate != line_num:
pstate = line_num
logging.warning("""File "%s", line %s
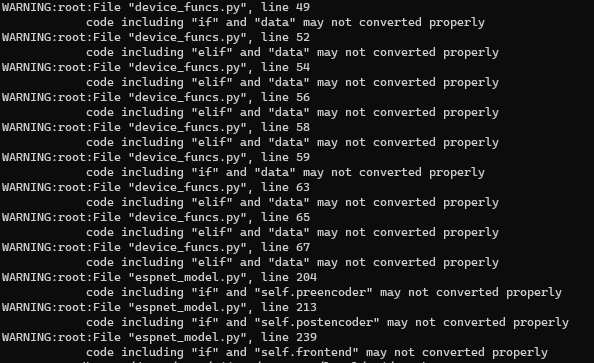
code including "%s" and "%s" may not converted properly""" %(file_name,line_num,token.string,param))최종적으로 간단하게 코드를 실행해보면, 다음과 같이 모델 Conversion 과정에서 IF구문이 사용되면 위치 정보를 로그로 띄워주게 됩니다.

참고 자료
- 소스 코드 자체를 분석하고 싶을 때 https://docs.python.org/3/library/inspect.html https://stackoverflow.com/questions/12848507/getattr-vs-inspect-getmembers
- 다른 모듈을 Import 하는데 dot 연산자를 사용하지 않고 import 할 때 https://csatlas.com/python-import-file-module/ https://docs.python.org/ko/3/library/os.path.html https://realpython.com/run-python-scripts/ https://light-tree.tistory.com/8 https://www.pythonpool.com/import-classes-from-another-file-in-python/ https://stackoverflow.com/questions/19044163/how-to-import-object-of-a-class-in-python https://stackoverflow.com/questions/1911281/how-do-i-get-list-of-methods-in-a-python-class https://www.tutorialspoint.com/How-to-retrieve-source-code-from-Python-objects
- AST 관련 Ref. https://docs.python.org/3/library/ast.html
- Python 인덴트 죽이고 싶을 때 https://www.w3resource.com/python-exercises/string/python-data-type-string-exercise-27.php
- 테스트용 Inference Code(ESPNet) https://github.com/espnet/espnet/blob/master/espnet2/mt/espnet_model.py
- DFS https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
- 딕셔너리 관련 https://geuninote.tistory.com/96 https://stackoverflow.com/questions/23177439/python-checking-if-a-dictionary-is-empty-doesnt-seem-to-work
- 파이썬 기본 모듈인지 아닌지 여부 체크 https://stackoverflow.com/questions/14050281/how-to-check-if-a-python-module-exists-without-importing-it
- 파이썬 소스코드 토크나이징 관련 https://docs.python.org/ko/3/library/tokenize.html#examples
