torch.onnx.export Debugging
def export(model, args, f, export_params=True, verbose=False, training=None,
input_names=None, output_names=None, operator_export_type=None,
opset_version=None, _retain_param_name=None, do_constant_folding=True,
example_outputs=None, strip_doc_string=None, dynamic_axes=None,
keep_initializers_as_inputs=None, custom_opsets=None,
enable_onnx_checker=None, use_external_data_format=None):
if operator_export_type is None:
if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:
operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK
else:
operator_export_type = OperatorExportTypes.ONNXtorch.onnx.export를 디버깅하게 되면 다음과 같이 export 함수를 타게 됩니다. operator_export_type에 따라서 분류가 되는 것으로 보이는데, 일반적으로 OperatorExportTypes.ONNX로 분류됩니다.
ATEN 라이브러리를 사용하거나 CAFFE 형태로 모델이 존재하는 경우에, OperatorExportTypes.ONNX_ATEN_FALLBACK 조건으로 타입이 분류되게 되는데, 파이썬과 C++에서 Tensor를 사용할 수 있는 라이브러리로 보입니다.
if isinstance(model, torch.nn.DataParallel):
raise ValueError("torch.nn.DataParallel is not supported by ONNX "
"exporter, please use 'attribute' module to "
"unwrap model from torch.nn.DataParallel. Try "
"torch.onnx.export(model.module, ...)")이후 모델 객체가 torch.nn.DataParallel 일 경우에는 ONNX로 변환되지 않는다고 합니다. jit 하위 모듈 또는 파이썬 모듈만을 사용할 것을 권장합니다.
중간중간, Onnx 모델 타입을 체크하거나, opset version 체크를 하는 등 다른 부분은 스킵하였습니다.
def _decide_input_format(model, args):해당 함수에서 forward 구문을 inspect 하는 코드가 존재하길래, forward 구문을 확인하는 줄 알았지만 해당 함수에서는 forward 내부 input 타입이 딕셔너리일 경우, tensor로 분리해주는 작업을 진행하는 것으로 보였습니다.
아래 함수가 모델을 Onnx 그래프 형태로 바꿔주는 것으로 보입니다. 가장 바깥쪽 함수부터 차례대로 따라가보았습니다.
graph, params_dict, torch_out = \
_model_to_graph(model, args, verbose, input_names,
output_names, operator_export_type,
example_outputs, val_do_constant_folding,
fixed_batch_size=fixed_batch_size,
training=training,
dynamic_axes=dynamic_axes)graph, params, torch_out, module = _create_jit_graph(model, args)def _create_jit_graph(model, args):
torch_out = None
params: Union[List, Tuple]
if isinstance(model, torch.jit.ScriptModule):
try:
graph = model.forward.graph
torch._C._jit_pass_onnx_function_substitution(graph)
freezed_m = torch._C._freeze_module(model._c, preserveParameters=True)
module, params = torch._C._jit_onnx_list_model_parameters(freezed_m)
method_graph = module._get_method("forward").graph
args_params = tuple(args) + tuple(params)
param_count_list = _get_param_count_list(method_graph, args_params)
in_vars, _ = torch.jit._flatten(args_params)
graph = _propagate_and_assign_input_shapes(
method_graph, tuple(in_vars), param_count_list, False, False)
except AttributeError as e:
raise RuntimeError("'forward' method must be a script method") from e
return graph, params, torch_out, moduletorch.jit.script 를 활용하여 파이썬 기반의 모델을 변환시켜주면 torch.jit.ScriptModule 형태로 wrapping되어 나오게 됩니다. 해당 torch.jit.ScriptModule 형태로 나오게 되면, 다음과 같이 graph, params, torch_out, module을 리턴하게 됩니다.
- graph : 모델 안에서 사용되는 파라미터, 레이어의 가중치,편향정보들이 담겨있습니다.
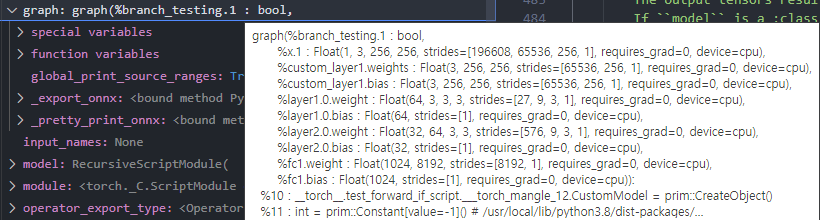
- params: 총 8개로 담겨있습니다.
param_count_list = _get_param_count_list(method_graph, args_params)에서 param 개수 정보를 리스트로 가져오게됩니다. 또한,module, params = torch._C._jit_onnx_list_model_parameters(freezed_m)에서 param을 torch.Tensor꼴로 가져오게되는데, 모델에 포함되어 있는 각 레이어(총 4개)의 가중치와 편향값입니다.- 이후,
params_dict = _get_named_param_dict(graph, params)에서 param name과 Tensor값을 딕셔너리 꼴로params_dict에 담아주게 됩니다.
- 이후,
- torch_out : None
- module : torch._C.ScriptModule 객체입니다.
_create_jit_graph 에서 구한 graph를 optimize하는 부분으로 추측됩니다.
graph = _optimize_graph(graph, operator_export_type,
_disable_torch_constant_prop=_disable_torch_constant_prop,
fixed_batch_size=fixed_batch_size, params_dict=params_dict,
dynamic_axes=dynamic_axes, input_names=input_names,
module=module)그 안에 아래와 같은 코드가 있습니다.
# onnx only supports tensors, so we turn all out number types into tensors
torch._C._jit_pass_erase_number_types(graph)이외에도 C로 wrapping되어있는 많은 최적화 함수들이 존재하는데, Onnx로 변환할 때, 변환되지 않는 부분을 변경해주는 것으로 보입니다.
in _jit_pass_onnx, symbolic functions are called for each node for conversion.
However, there are nodes that cannot be converted without additional context.
For example, the number of outputs from split (and whether it is static or dynamic) is unknown
until the point where it is unpacked by listUnpack node.
This pass does a preprocess, and prepares the nodes such that enough context can be received by the symbolic function.
그리고 번외로 코드를 보다보면 다음과 같이 assert를 사용하여, 한 번만 돌리는 것이 아니라, 데이터의 사이즈를 비교하여 검증하는 코드들이 항상 존재합니다. 앞으로 직접 코드를 구현할 때, 쓰면 좋을 거 같다는 생각이 들었습니다.
assert len(params) + len(flatten_args) == sum(1 for _ in graph.inputs())모델 내부를 들여다보려고했는데, 결국 근본으로 갈수록 모든 코드는 C로 wrapping 되어 있었습니다.
