Session 1. - Build
1. Onnx Runtime Inference Session
OnnxRuntime.InferenceSession 이용
build_onnxrt_session = SessionFromOnnx("identity.onnx")-
backend/onnxrt/loader.py:class SessionFromOnnx(BaseLoader)-
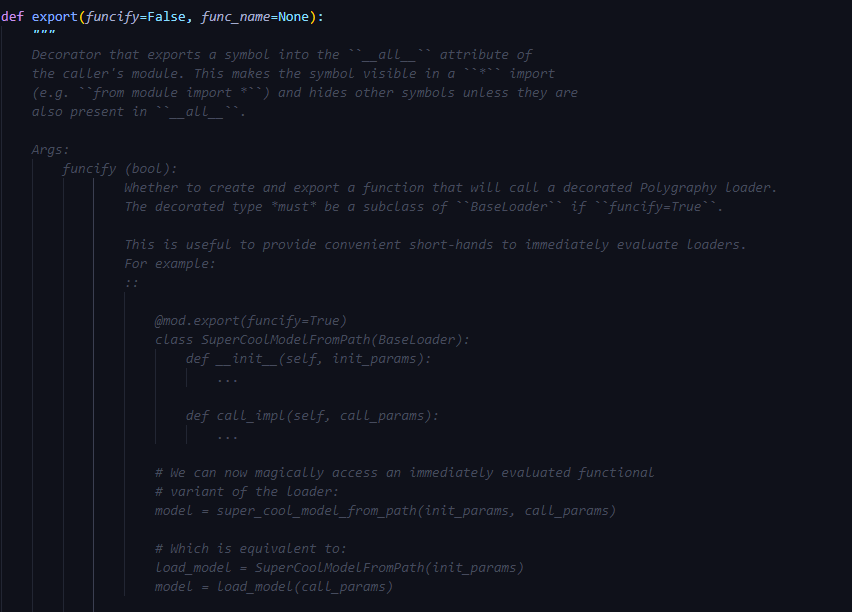
@mod.export(*funcify*=True)역할-
인스턴스 초기화 및 호출을 한 번에 실행
-
-
**__init__과call_impl한 번에 실행 ← provider setting 및 ort InferenceSession 반환**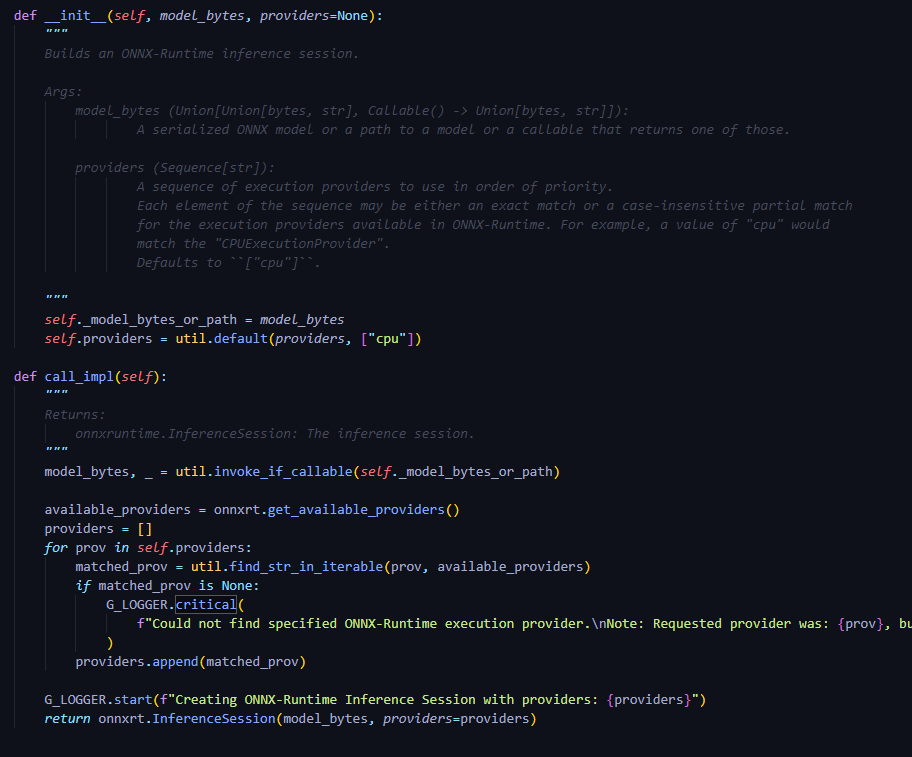
-
2. TensorRT Build Engine
IcudaEngine instance 추출
build_engine = EngineFromNetwork(NetworkFromOnnxPath("identity.onnx"))
cf. “내가 직접 customizing한 onnx to trt의 경우, serialized engine까지 뽑아냈지만, polygraphy의 경우, ICudaEngine 뽑아낸 후에, serialized해서 engine으로 저장하지 않는다.!”
- INetworkDefinition :
- Builder가 활용할 수 있게 기존 Onnx Network를 변경해 준 network
- Model Network에 대한 구조 정보를 담고 있음
- IBuilderConfig와 결합해서 IBuilder에 사용
- IBuilderConfig : Int8로 quantizing 가능 여부 flag list
- 암묵적인 배치 사이즈(차원), 런타임, 전체 dimensions 정보들이 담겨 있음
- batch size의 경우, execute/enqueue에 한 번 정해짐, 이후 전체 network에 처음으로 정해진 dimension이 broadcasting됨. 따라서 divergent한 batch size는 지원되지 않음
- INetworkDefinition 함수 TensorRT: nvinfer1::INetworkDefinition Class Reference
-
TensorRT Engine을 구성하기 위한 객체 :
1번의 “INetworkDefinition”을 포함하여, “IBuilder”, “OnnxParser” 들을 대표적으로 생각해 볼 수 있다.
- Object Definition
-
trt.Logger : logging을 어떻게 활용할 것 인지에 대한 객체, 직접 customizing도 가능
-
builder 객체를 생성할 때 담아줘서 사용함
TRT_LOGGER = trt.Logger(trt.Logger.WARNING) builder = trt.Builder(TRT_LOGGER)
-
-
builder : immutable한 network properties
- Network, Config와 같은 다른 객체들을 만들어 낼 수 있는 객체, 어떻게 Engine을 빌드할 것 인지에 대한 모든 정보(?)를 담는다고 생각하면 됨(=Builds an engine from a network definition.)
- 대표적으로 담겨있는 정보(config,network,profile 이 나눠서 역할을 한다 생각)
- max batch size (기본 GPU, DLA+GPU)
- 자료형 : tf32, fp16, int8
- DLA Cores
- error reporting(error_recorder)
- GPU 할당
- logger(ILogger 에서)
- max threads
-
config : (=IbuilderConfig)
-
Int8로 quantizing 가능 여부 flag list 등등
-
optimize 된 profile을 config에 추가할 수 있음
cf. profile은 보통 input,ouptut shape에 대한 optimizing 정보를 담으려고 함
IOptimizationProfile - NVIDIA TensorRT Standard Python API Documentation 8.4.1 documentation
profile.set_shape("image", (1,3, 416, 416),(1,3, 416, 416),(1,3, 416, 416)) config = builder.create_builder_config() config.add_optimization_profile(profile) config.max_workspace_size = 8 << 30
-
-
network : network에 대한 정보들(==INetworkDefinition)
- num layers,inputs,outputs, name정보들
- explicit 한 batch dimension 및 precision이 있는지 boolean으로 체크 가능
- operation 추가 가능(customizing)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) network = builder.create_network(EXPLICIT_BATCH) -
parser : Onnx 모델을 parsing 해주는 역할 (=trt.OnnxParser)
-
parser.parse(onnx모델) : parsing된 network definition을 network에 써줌
Onnx Parser - NVIDIA TensorRT Standard Python API Documentation 8.4.1 documentation
parser = trt.OnnxParser(network, TRT_LOGGER) parser.parse(onnx모델) -
-
- Object Definition
-
IcudaEngine Instance :
- built network에서 inference 하기 위한 engine
- binding name으로 indexing이 가능함. []
- 바인딩 개수, max 배치 사이즈, layer 개수, IcudaEngine workspace size, device memory, network에 구성되어 있는 name, optimization profiles 개수 등을 알 수 있음. ICudaEngine - NVIDIA TensorRT Standard Python API Documentation 8.4.1 documentation
- IcudaEngine 함수 TensorRT: nvinfer1::ICudaEngine Class Reference
Session 2. - Inference
1. Onnx Runtime run
ort_session.run(None, ort_inputs)
#customizing
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)#[polygraphy]
for node in self.sess.get_inputs():
dtype = ONNX_RT_TYPE_TO_NP[node.type] if node.type in ONNX_RT_TYPE_TO_NP else None
meta.add(node.name, dtype=dtype, shape=node.shape)
return meta
def infer_impl(self, feed_dict):
start = time.time()
inference_outputs = self.sess.run(None, feed_dict)
end = time.time()
out_dict = OrderedDict()
for node, out in zip(self.sess.get_outputs(), inference_outputs):
out_dict[node.name] = out
self.inference_time = end - start
return out_dict2. TensorRT Runner
cuda stream 활용하여 async inference

- context :
- ICudaEngine Inference 하기 위해 사용.
- 여러 개의 IExecutionContext 일 경우에도, ICudaEngine 인스턴스가 한 개만 존재하기 때문에, 병렬적으로 여러 batch들을 동시에 실행시킬 수 있도록 도와줌.
- 지금 내가 Testing 하는 과정에서는 Dynamic shape가 아닌 Batch 1로 testing, 따라서 create_execution_context() 메서드 활용해서 생성해 줌.
self.context = self.engine.create_execution_context()-
cuda.Stream() :
-
정의 - 호스트(CPU) 코드에서 기술된 순서대로 디바이스(GPU)에서 동작하는 일련의 연속된 연산을 의미
-
순차적 실행을 보장하지만, 다른 스트림의 연산과는 함께 동작이 가능
-
Inference 과정에서 context의 메서드인
execute_async_v2를 활용하여 비동기적으로 추론을 여러 스트림에서 진행하기 위해 사용 -
추론을 위해서 호스트 버퍼와 디바이스 버퍼의 사이즈를 정해줘야 함. 이는 일반적으로 input shape 크기만큼 할당해주면 됨.
IExecutionContext - NVIDIA TensorRT Standard Python API Documentation 8.4.1 documentation
-