HiFi-GAN 논문 리뷰
VOCODER
- 음성인식은 두 단계로 이루어져 있음
- Text → Mel-spectrogram
- Mel-spectrogram → waveform
- vocoder는 두 번째 단계를 실행함

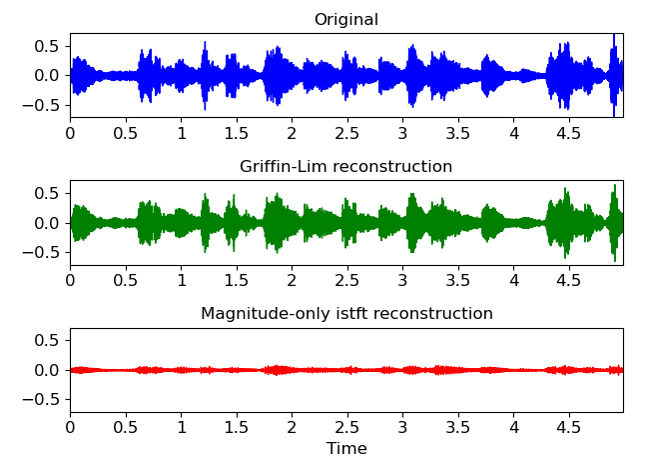
**Griffin-Lim**
**Neural Vocoder**
Auto-Regressive Generative model - WaveNet
학습과 추론 시간이 오래 걸림
Flow-based Generative model
Parallel WaveNet,WaveGlow
모델의 파라미터의 개수가 많이 필요함
Generative Adversarial Network model (GAN)
MelGAN, GAN-TTS, HiFi-GAN
속도, 파라미터 개수, 음성의 퀄리티
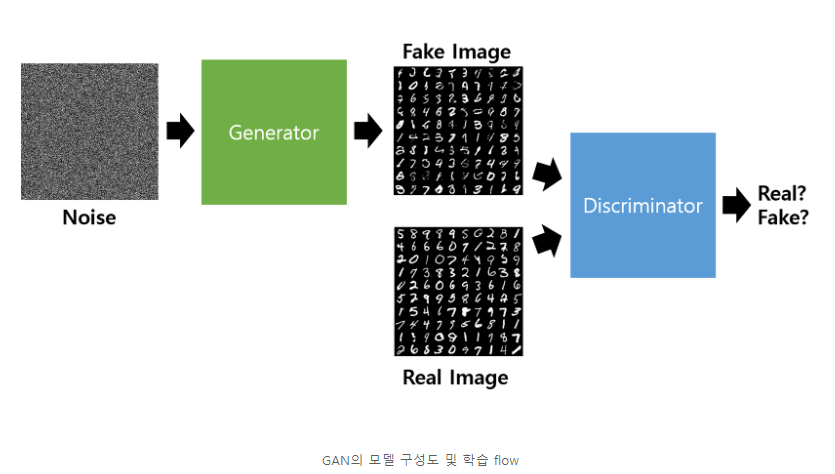
GAN
HIFI-GAN
-
핵심 특징
- 발화 음성이 다양한 주기의 신호로 이루어져 있기 때문에 discriminator를 여러 개의 sub-discriminator로 구성했다.
- Generator는 MRF, discriminator는 MPD와 MSD로 이루어져 있다.또한, 성능을 높이기 위해 3가지 종류의 loss function을 사용했다.
-
Vocoder 모델의 key point
- 발화 음성은 다양한 주기의 sinusoidal 신호로 이루어져 있기 때문에 realistic 한 발화 음성을 만들기 위해서는 periodic pattern을 생성하는 것이 중요하다.
- HIFI-GAN에서는 raw waveform에서 각각 특정한 periodic 부분을 맡는 sub-discriminator로 구성된 discriminator를 제안한다.
-
Hifi-GAN Structure
- HiFi-GAN은 generator 한 개와 discriminator 두 개로 이루어져 있다.
- Generator와 discriminators는 additional loss 두 개를 이용해서 adversarial 하게 학습된다.
-
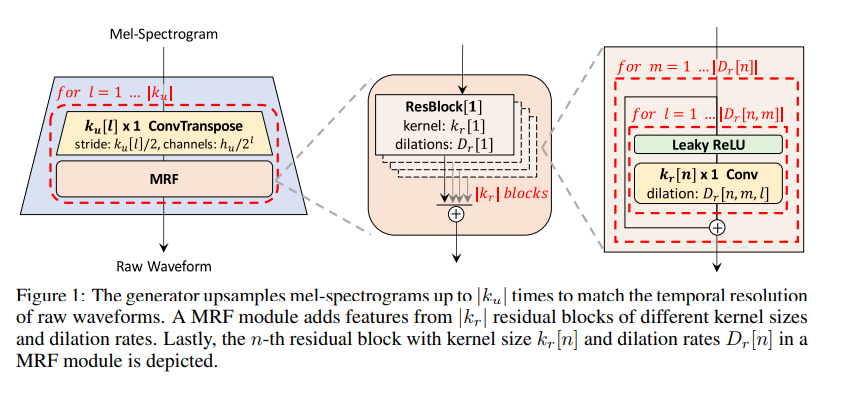
Generator
- Fully connected CNN 구조
- Input : Mel-spectrogram
- 합성곱을 통해 raw waveform의 resolution값까지 upsampling함.
- 합성곱 이후 MRF(multi-receptive field fusion)을 함.
- Multi-Receptive Field Fusion
-
MRF는 병렬적으로 다양한 길이의 패턴을 관찰한다.
-
이유(추측) : phase를 모르니깐
-
Output: multiple residual block의 출력의 합
-
-
Discriminator
-
Realistic한 발화 음성을 만들기 위해서 long-term dependency를 아는 것은 중요
-
이 문제는 generator와 discriminator의 receptive fields를 증가하는 방식으로 해결
-
또 다른 문제는, 발화 음성은 다양한 주기를 가진 sinusoidal 신호들로 구성되기 때문에 음성 데이터의 기저에 있는 다양한 주기의 패턴을 아는 것
-
Structure
- 음성의 periodic signal을 나눠 각각 다루기 위해 여러 개의 sub-discriminator로 이루어진 multi-period discriminator(MPD)를 사용
- 연속되는 패턴과 long-term dependency를 잡기 위해 MelGAN에서 사용된 multi-scale discriminator(MSD)도 사용
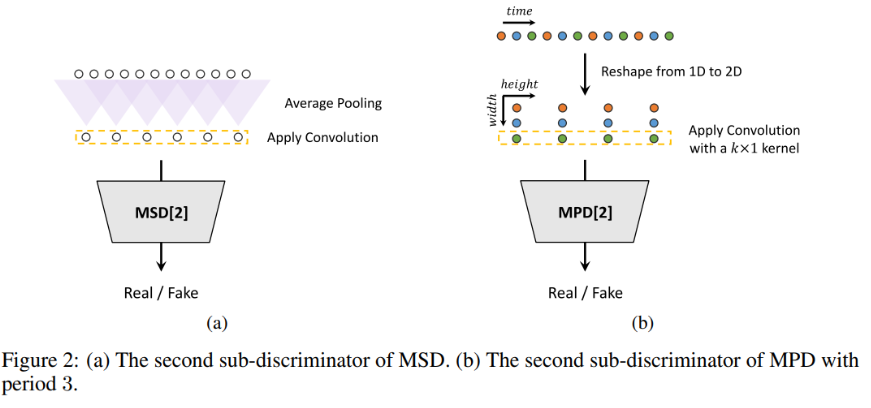
- Multi-Period Discriminator
-
MPD는 p주기로 일정하게 나뉜 입력 음성을 다루는 sub-discriminators로 이루어짐
-
Sub-discriminator들은 각각 입력 음성의 다른 부분을 맡아 다른 implicit 구조를 찾기 위해 설계됨.
-
- Multi-Scale Discriminator
- MPD의 각 sub-discriminator는 분해된 sample만 사용하기 때문에 연속된 음성을 평가하기 위해 MSD를 추가
- MSD의 구조는 MelGAN에서 가져왔는데, 다른 input scale(×1,×1/2,×1/4)에서 동작하는 sub-discriminator 3개로 이루어짐
-
-
Trainning Loss Function
- GAN Loss
- Mel-Spectrogram Loss
- Feature Matching Loss

특 : 미친듯한 게으름과 부지런한 생각이 공존하는 사람