[간단정리]BOIL: TOWARDS REPRESENTATION CHANGE FOR FEW-SHOT LEARNING(ICLR 2021)

Paper: https://openreview.net/forum?id=umIdUL8rMH
-
굉장히 적은 데이터로 잘 작동할 수 있는 딥러닝 모델을 만들 수 있는 메타러닝(or Few-shot learning)은 광범위하게 연구되는 중.
-
그 중 지배적인 방법은 MAML(Model-Agnostic Meta Learning)인데, 이는 대표적으로 Classifier head(의 gradienet)를 이용한 학습 방법.
- https://velog.io/@sjinu/Few-Shot-Learning
- 이 모델은 주로 inner roop와 outer roop로 나눠서 살펴볼 수 있음.
- inner roop : 주어진 task를 통해 model의 body(즉, extractor)를 학습하는 과정
- outer roop : inner roop에서 얻은 gradient들을 활용해 meta-initialization point를 찾는 과정
-
MAML은 특성상 outer roop(head를 통해 좋은 initialization point를 찾는 것)의 역할이 강조되는데, 이는 실질적으로 extractor의 feature space는 별로 변경시키지 않음
- 이를 representation reuse라 표현
-
다만, 메타러닝의 궁극적인 목표는 결국 성격이 다른 데이터셋에도 잘 적용되는 것이라 할 수 있음(cross-domain)
- 하지만 MAML은 feature(representation)을 크게 변경시키지 않기 때문에 도메인이 급격하게 변할 땐 representation의 차이를 쉽게 따라잡을 수 없음.
- MAML이 인기있었던 이유는 비교적 비슷한 도메인의 데이터들을 이용해 연구가 진행됐기 때문
-
그래서 저자들은 classifier head 의 지배력을 약간 낮추고(freezing head in inner roop) extractor body가 representation을 역동적으로 배울 수 있게끔하는 방법을 고안함(learn representaiton change)
-
이 방법을 BOIL(Body Only update in Inner Loop) algorithm 이라 명명.
- 다른 연구에선 representation change를 rapid learning이라고 표현하기도 함([Raghu et al.(2020)]https://openreview.net/pdf?id=rkgMkCEtPB).
- head : representation reuse, slow learning, meta(outer)
- body : representation change, rapid learning, task(inner)
기존 방식(MAML 등)과 저자들의 방식(BOIL)과의 비교
- 기존(MAML)
- representation : 거의 변하지 않음 (extractor body의 역할)
- decision boundary : 변함 (classifier head의 역할)
- ours(BOIL)
- representation : 아주 잘 변함
- decision boundary : 아예 변하지 않음 (because of freezing head)
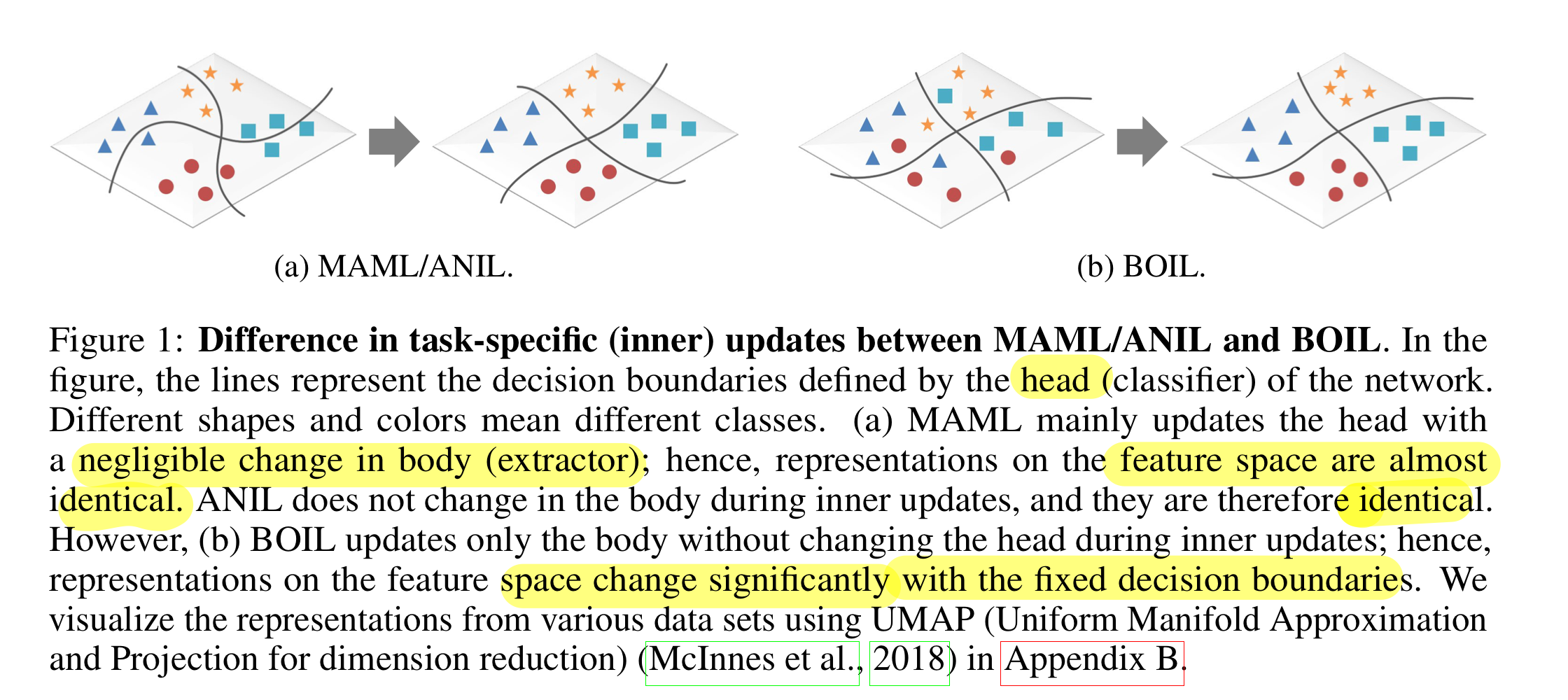

- 우측의 그림을 보면, 좌측 두 개보다 domain 간의 representation을 잘 나누는 것을 확인할 수 있음.
- 즉, 적은 데이터로도 feature representation을 빠르게, 그리고 알맞게 변경시킬 수 있다.
Contribution
- Representation change를 통한 Cross-domain setting에서 좋은 모습을 보임
- BOIL Algorithm과 다른 방법(preconditioning gradients(Flennerhag et al.(2020))을 같이 사용할 수 있고, 성능 역시 약간 상승했음(양립 가능성).
- low-/mid- level의 레이어에서는 비교적 representation reuse를 활용하며, high-level의 레이어에서는 representation change를 활용하는 것을 보여줌
- 이는 CNN의 근본적인 특성에서 예상할 수 있음. domain이 변해도 low-level의 feature는 크게 변하지 않는 반면, high-level의 feature는 더욱 semantic한 정보를 담고 있기 때문에 다채롭게 형성될 필요가 있음.
- Resnet에서 마지막 skip connection을 삭제(disconnection trick을 활용해 high-level layer(body)에서의 *representation change***를 강화함.
- skip connection
- disconnection trick
- (얘를 없앰)
- 해당 방법은 feature 를 도메인에 따라 빠르게 변경시킬 필요가 있음.
- 그렇기 때문에 마지막 레이어의 (보다 안정적인 학습을 야기하는) skip connection의 gradient를 삭제한듯함.
- 이런 disconneciton이 어느 정도 representation change를 강화하는 데에는 도움이 될 거라 생각이 들지만, (그리고 실제로도 도움이 됐지만), 이로부터 얻는 이득이 skip connection으로부터 얻는 이득보다 항상 좋을지는 따져볼 필요가 있을듯(residual block 좋아..).
- 역으로 생각하면 representation reuse를 강화할 필요가 있을 땐 residual block이 좋은 견인을 해줄 수 있음을 암시함.
- skip connection

-