ArrayList를 구현하기 전에 잠깐 알아두고 가야할 점이 있다.
ArrayList는 다른 자료구조와 달리 Object[] 배열(객체 배열)을 두고 사용한다는 점이다. 일단은 다른 자료구조는 살펴보지 않았으니 이렇다는 정도만 알고계시면 될 것 같다.
또한 모든 자료구조는 '동적 할당'을 전제로 한다. 가끔 ArrayList를 구현 할 때, 리스트가 꽉 차면 리스트의 크기를 늘리지 않고 그냥 꽉 찼다고 더이상 원소를 안받도록 구현한 경우가 많은데 이는 자료구조를 구현하는 의미가 없다.
동적 할당을 안하고 사이즈를 정해놓고 구현한다면 메인함수에서 정적배열을 선언하는 것과 차이가 없다.
데이터의 개수를 알 수 없는데 배열을 쓰고 싶을 때 여러분은 어떤 방법을 선택하는가? ArrayList, LinkedList 등의 자료구조를 선택할 것이다. 왜냐면 사이즈를 정하지 않고 동적으로 활용할 수 있기 때문이다.
마지막으로 리스트 계열 자료구조는 데이터 사이에 빈 공간을 허락하지 않는다.
아래 예를 들어보자.
Object[] a = {"a", "b", "c", "d"};
이러한 배열이 있고, 만약 "c"라는 데이터를 삭제하려고 한다. (a[2] = null)
그러면 a배열은 다음과 같은 상황일 것이다.
Object[] a = {"a", "b", null, "d"};
이렇게 데이터 사이에 빈 공간이 생길 경우 빈공간을 없애야 한다. 즉, null 뒤에 있는 모든 데이터를 한 칸씩 끌어와야한다는 것이다. 아래와 같이 말이다.
Object[] a = {"a", "b", "d", null};
이렇게 항상 리스트 계열 자료구조는 데이터들이 '연속되어'있어야 한다는 점을 기억하자.
- ArrayList 구현
- 사전 준비
[ArrayList 클래스 및 생성자 구성하기]
ArrayList 이름으로 생성해준 뒤 앞서 작성했던 List 인터페이스를 implements 해준다. implements 를 하면 class 옆에 경고표시가 뜰 텐데 List 인터페이스에 있는 메소드들을 구현하라는 것이다. 어차피 모두 구현해나갈 것이기 때문에 일단은 무시한다.
[ArrayList.java]
import Interface_form.List;
public class ArrayList<E> implements List<E> {
private static final int DEFAULT_CAPACITY = 10; // 최소(기본) 용적 크기
private static final Object[] EMPTY_ARRAY = {}; // 빈 배열
private int size; // 요소 개수
Object[] array; // 요소를 담을 배열
// 생성자1 (초기 공간 할당 X)
public ArrayList() {
this.array = EMPTY_ARRAY;
this.size = 0;
}
// 생성자2 (초기 공간 할당 O)
public ArrayList(int capacity) {
this.array = new Object[capacity];
this.size = 0;
}
}변수부터 먼저 차례대로 설명해주도록 하겠다.
DEFAULT_CAPACITY : 배열이 생성 될 때의 최초 할당 크기(용적)이자 최소 할당 용적 변수로 기본값은 10으로 설정해두었다. (capacity가 용적이라는 의미다)
EMPTY_ARRAY : 아무 것도 없는 빈 배열 (용적이 0인 배열)
size : 배열에 담긴 요소(원소)의 개수 변수 (용적 크기가 아니다. 절대 헷갈리지 말자)
array : 요소들을 담을 배열
그리고 DEFAULT_CAPACITY 변수와 EMPTY_ARRAY 변수는 상수로 쓸 것이기 때문에 static final 키워드를 붙인다.
그리고 보면 생성자가 2개를 두었다.
생성자 1의 경우 사용자가 공간 할당을 미리 안하고 객체만 생성하고 싶을 때, 즉 다음과 같은 상태일 때이다.
ArrayList<Integer> list = new ArrayList<>();이 때는 사용자가 공간 할당을 명시하지 않았기 때문에 array 변수를 EMPTY_ARRAY로 초기화 시켜 놓는다.
반면에 사용자가 데이터의 개수를 예측할 수 있어서 미리 공간 할당을 해놓고 싶을 경우, 즉 다음과 같이 생성할 경우
ArrayList<Integer> list = new ArrayList<>(100);array의 공간 할당을 입력 된 수 만큼 (예제에서는 array = new Object[100]) 배열을 만든다. 그리고 마찬가지로 size 를 0으로 초기화 시켜놓는다.
(size는 요소(원소)의 개수를 의미하는 것이다. 공간을 할당해놓는 것하고는 다른 개념이다.)
[동적할당을 위한 resize 메소드 구현]
앞서 필자가 말했던 것 처럼 우리는 들어오는 데이터에 개수에 따라 '최적화'된 용적을 갖을 필요가 있다. 만약 데이터는 적은데 용적이 크면 메모리가 낭비되고, 반대로 용적은 적은데 데이터가 많으면 넘치는 데이터들은 보관할 수 없게 되는 상황을 마주칠 수 있다.
그렇기 때문에 size(요소의 개수)가 용적(capacity)에 얼마만큼 차있는지를 확인하고, 적절한 크기에 맞게 배열의 용적을 변경해야 한다. 또한 용적은 외부에서 마음대로 접근하면 데이터의 손상을 야기할 수 있기 때문에 private로 접근을 제한해주도록 하자.
private void resize() {
int array_capacity = array.length;
// if array's capacity is 0
if (Arrays.equals(array, EMPTY_ARRAY)) {
array = new Object[DEFAULT_CAPACITY];
return;
}
// 용량이 꽉 찰 경우
if (size == array_capacity) {
int new_capacity = array_capacity * 2;
// copy
array = Arrays.copyOf(array, new_capacity);
return;
}
// 용적의 절반 미만으로 요소가 차지하고 있을 경우
if (size < (array_capacity / 2)) {
int new_capacity = array_capacity / 2;
// copy
array = Arrays.copyOf(array, Math.max(new_capacity, DEFAULT_CAPACITY));
return;
}
}현재 array의 용적(=array 길이)과 데이터의 개수(size)를 비교한다.
조건문 1 : if (Arrays.equals(array, EMPTY_ARRAY))
앞서 생성자에서 사용자가 용적을 별도로 설정하지 않은 경우 EMPTY_ARRAY로 초기화 되어있어 용적이 0인 상태다. 이 경우를 고려하여 이제 새로 array의 용적을 할당하기 위해 최소 용적으로 설정해두었던 DEFAULT_CAPACITY의 크기만큼 배열을 생성해주고 메소드를 종료한다.
또한 주소가 아닌 값을 비교해야 하기 때문에 Arrays.equals() 메소드를 사용하도록 하자.
조건문 2 : if (size == array_capacity)
데이터가 꽉 찰 경우에는 데이터(요소)를 더 받아오기 위해서 용적을 늘려야 한다. 즉, 데이터의 개수가 용적과 같을 경우는 꽉 차있는 경우를 말한다. 이 때는 새롭게 용적을 늘릴 필요가 있으므로 새로운 용적을 현재 용적의 2배로 설정하도록 한다.
또한 기존에 담겨있던 요소들을 새롭게 복사해와야한다. 이 때 편리하게 쓸 수 있는 것이 Arrays.copyOf() 메소드다. Arrays.copyOf() 는 첫 번째 파라미터로 '복사할 배열'을 넣어주고, 두 번째 파라미터는 용적의 크기를 넣어주면 된다.
만약 복사할 배열보다 용적의 크기가 클 경우 먼저 배열을 복사한 뒤, 나머지 빈 공간은 null로 채워지기 때문에 편리하다.
조건문 3 : if (size < (array_capacity / 2 ))
데이터가 용적에 절반 미만으로 차지 않을 경우다. 이 경우 데이터는 적은데 빈 공간이 메모리를 차지하고 있어 불필요한 공간을 낭비할 뿐이다. 이럴 때에는 사이즈를 적적하게 줄여주는 것이 좋지 않겠는가?
데이터의 개수가 용적의 절반 미만이라면 용적도 절반으로 줄여주도록 하기 위해 새로운 용적(new_capacity)을 현재 용적의 절반으로 둔 뒤, Arrays.coptyOf() 메소드를 통해 새로운 용적의 배열을 생성해주도록 하자.
만약 복사할 배열보다 용적의 크기가 작을경우 새로운 용적까지만 복사하고 반환하기 때문에 예외발생에 대해 안전하다.
[add 메소드 구현]
이제 본격적으로 ArrayList에 데이터를 추가할 수 있도록 해보자. 리스트 인터페이스에 있는 add() 메소드를 반드시 구현해야하는 것이기 때문에 Override(재정의)를 한다고 보면 된다.
add 메소드에는 크게 3가지로 분류가 된다.
- 가장 마지막 부분에 추가 (기본값) - addLast(E value)
- 가장 앞부분에 추가 - addFirst(E value)
- 특정 위치에 추가 - add(int index, E value)
물론 현재 자바에 내장되어있는 ArrayList에서는 addLast() 역할을 add() 메소드가 하고, 특정 위치에 추가는 add(int index, Eelement) 로 오버로딩된 메소드가 하며, addFisrt()는 없다. 하지만 편의상 3가지로 나눠서 보고자 한다.
1. 기본삽입 : add(E value) & addLast(E value) 메소드
먼저 add()의 기본 값은 addLast()라고 했다. 가장 마지막 부분에만 추가하면 되다보니 이 부분 구현 자체는 그리 어렵지 않다.
addLast() 메소드를 구현하자면 이렇다.
(자바 내부에서 add메소드는 boolean을 리턴하기 때문에 boolean 메소드로 구현해주었다)
@Override
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
// 꽉차있는 상태라면 용적 재할당
if (size == array.length) {
resize();
}
array[size] = value; // 마지막 위치에 요소 추가
size++; // 사이즈 1 증가
}addLast 메소드를 보면 된다.
add를 호출하면 자동으로 파라미터로 넘어온 value 는 addLast로 보내진다. 그리고 데이터를 넣기에 앞서 현재 용적이 꽉차있는지를 검사한다.
만약 꽉차있다면 우리가 만들었던 resize() 메소드를 호출해서 array가 더 큰 용적을 갖도록 만들어 준다. 그리고 마지막 위치(size)에 value를 추가해주고 size를 1 증가시켜준다. 그림으로 보자면 다음과 같다.
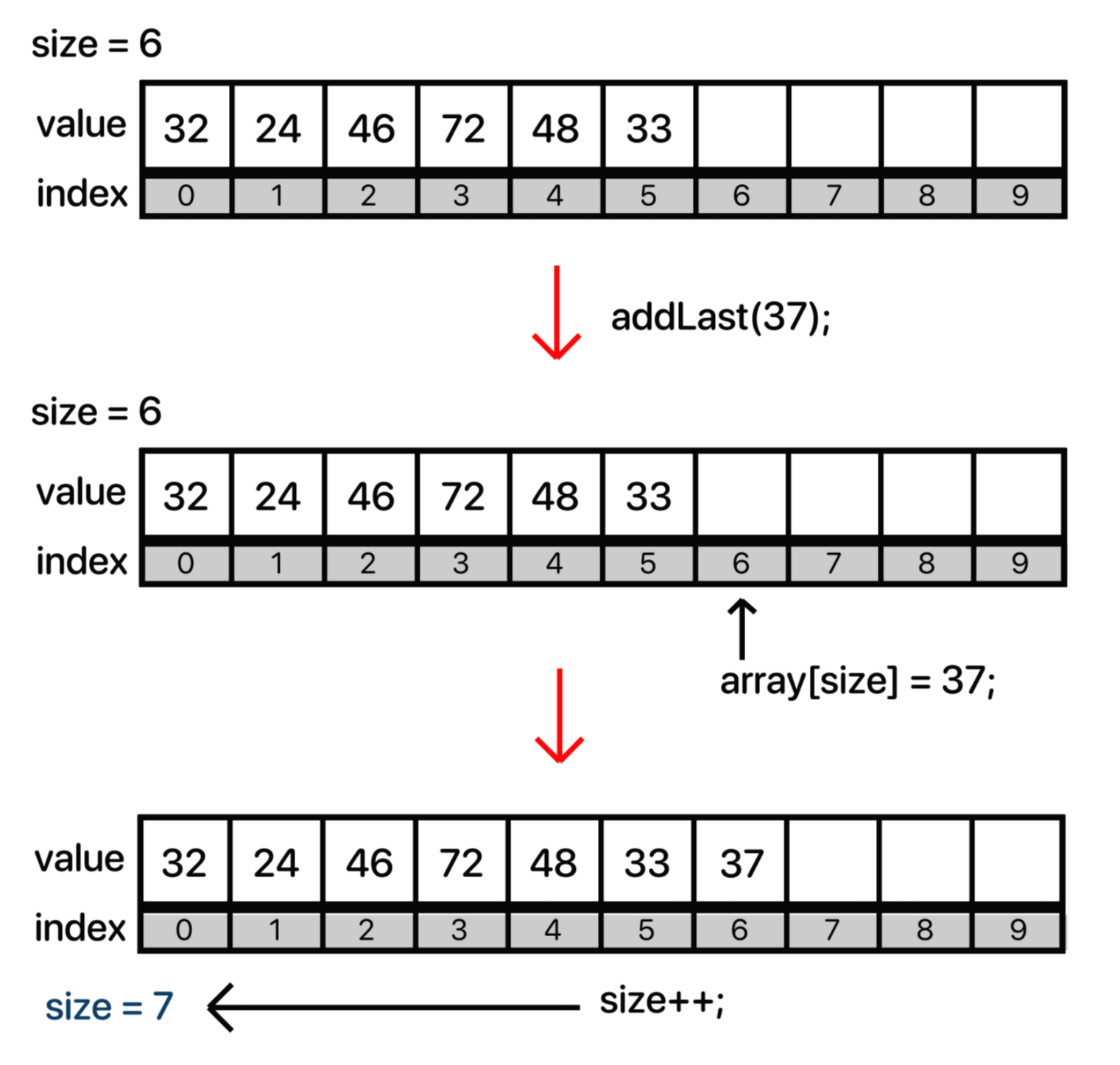
size가 요소의 개수이고, index는 0부터 시작하다보니 array[size] = value; 를 해주면 된다. 이 부분을 헷갈려서 잘못된 인덱스에 참조하는 경우가 많으니 주의할 필요가 있다.
2. 중간삽입 : add(int index, E value)
중간에 추가하는 것은 조금 까다롭다. 우선 index가 범위를 벗어나진 않는지를 확인해야하고, 중간에 삽입할 경우 기존에 있던 index의 요소와 그의 뒤에 있는 데이터들을 모두 한 칸씩 뒤로 밀어야하기 때문이다.
일단 코드를 보기 전에 데이터가 중간에 추가되는 과정을 그린 그림을 먼저 보도록 하자.
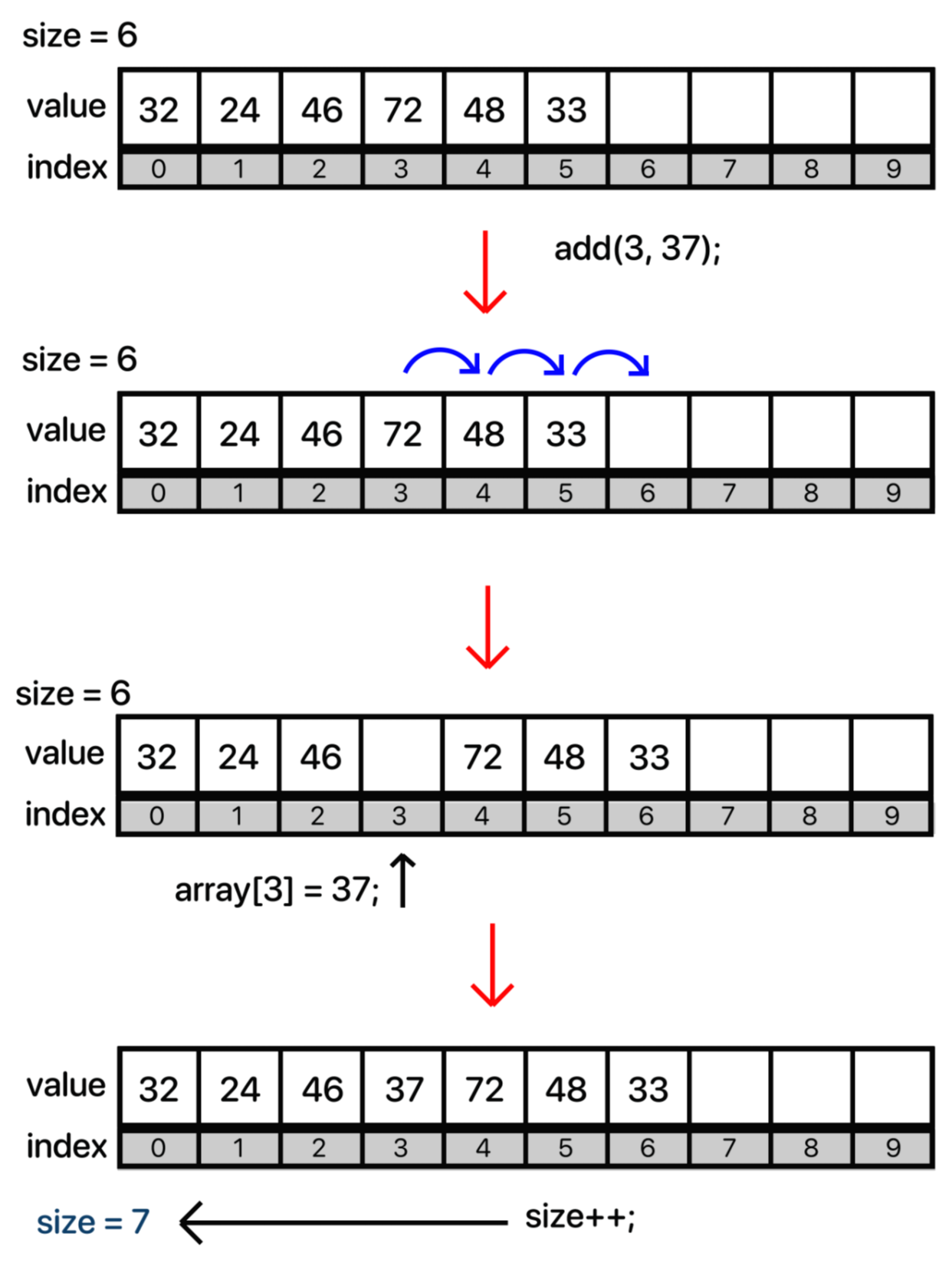
즉, add 에서 index로 들어오는 파라미터에 대해 만약 값이 3이 들어왔다면 원래 있던 배열에서 3을 포함한 뒤에있는 모든 요소들을 모두 한 칸씩 뒤로 옮긴 뒤에 3의 위치에 새로운 데이터를 삽입을 해주는 것이다.
addLast는 단순히 데이터를 추가하는 과정이였다면 중간 삽입은 데이터를 미루는 코드가 추가된 것이다.
코드로 보면 다음과 같다.
@Override
public void add(int index, E value) {
if (index > size || index < 0) { // 영역을 벗어날 경우 예외 발생
throw new IndexOutOfBoundsException();
}
if (index == size) { // index가 마지막 위치라면 addLast 메소드로 요소추가
addLast(value);
}
else {
if(size == array.length) { // 꽉차있다면 용적 재할당
resize();
}
// index 기준 후자에 있는 모든 요소들 한 칸씩 뒤로 밀기
for (int i = size; i > index; i--) {
array[i] = array[i - 1];
}
array[index] = value; // index 위치에 요소 할당
size++;
}
}먼저 index로 들어오는 값이 size를 벗어나는지(빈공간을 허용하지 않으므로), 또는 음수가 들어오는지를 확인한다. 만약에 범위를 벗어나거나 인덱스가 음수가 들어오면 예외를 발생시키도록 한다.
그리고 사용자가 넘겨준 index가 size와 같다는 것은 결국 가장 마지막에 추가하는 것과 같은 의미이므로 이미 만들어두었던 addLast() 메소드로 가도록 한다.
그 외의 경우가 이제 중간에 삽입되는 경우다.
당연하게도 size가 현재 배열의 용적과 같다는 것은 이미 꽉차서 더이상 들어올 공간이 없다는 뜻이므로 resize()메소드를 호출해줌으로써 용적량을 늘리도록 한다. 그리고 그림에서 보듯이 index와 그 후방에 있는 데이터들을 한 칸씩 뒤로 밀어야 하므로 반복문을 통해 뒤로 밀어주도록 한 뒤 array[index] 에는 새로운 요소로 교체해주도록 한다.
3. addFirst(E value)
이 부분은 별달리 할 것이 없다. 생각해보면 기존 데이터가 있다면 어차피 모든 데이터들을 뒤로 밀어야하는 것 아닌가? 즉, 앞서 만들었던 중간 삽입에서 index를 0으로 보내면 되는 것이다.
public void addFirst(E value) {
add(0, value);
}이렇게 기본적인 요소 추가 메소드들을 만들어보았다. 그리고 간혹 만들다보면 size와 index참조 부분을 헷갈려서 배열에서 잘못된 참조를 하는 경우가 많은데, 항상 이 부분을 고려해야한다. 아니면 잘못된 부분을 찾기가 매우 어려워지니..
[add 메소드 묶어보기]
더보기
[get, set, indexOf, contains 메소드 구현]
아마 대부분은 remove() 메소드부터 구현하기 때문에 갑자기 다른 메소드를 구현한다고 하니 당황스러울 수도 있다. 물론 remove 메소드로 바로 구현할 수도 있지만, '좀 더 효율적인' 방법을 선택하는게 누구나 좋을 것 같다.
일단 remove가 아닌 위의 메소드들을 구현하는 이유는 remove 메소드에서 유사한 동작을 필요로 하기 때문에, 비슷한 메소드들을 먼저 구현 한 뒤 remove 구현파트에서 이를 응용하고자 함이다. add() 메소드 전에 resize() 를 먼저 구현한 것과 같은 이유다.
그렇게 어려운 부분은 아니니 같이 빠르게 구현해보도록 하자.
1. get(int index) 메소드
get()은 리스트를 써본 사람이라면 누구나 쉽게 알 것이다. index 로 들어오는 값을 인덱스삼아 해당 위치에 있는 요소를 반환하는 메소드다. 배열의 위치를 찾아가는 것이기 때문에 반드시 잘못된 위치 참조에 대한 예외처리를 해주어야 한다.
@SuppressWarnings("unchecked")
@Override
public E get(int index) {
if(index >= size || index < 0) { // 범위 벗어나면 예외 발생
throw new IndexOutOfBoundsException();
}
// Object 타입에서 E타입으로 캐스팅 후 반환
return (E) array[index];
여기서 @SuppressWarnings("unchecked") 에 대해 잠깐 언급하고 가겠다.
@SuppressWarnings("unchecked")을 붙이지 않으면 type safe(타입 안정성)에 대해 경고를 보낸다. 반환되는 것을 보면 E 타입으로 캐스팅을 하고 있고 그 대상이 되는 것은 Object[] 배열의 Object 데이터다. 즉, Object -> E 타입으로 변환을 하는 것인데 이 과정에서 변환할 수 없는 타입을 가능성이 있다는 경고로 메소드 옆에 경고표시가 뜨는데, 우리가 add하여 받아들이는 데이터 타입은 유일하게 E 타입만 존재한다.
그렇기 때문에 형 안정성이 보장된다. 한마디로 ClassCastException이 뜨지 않으니 이 경고들을 무시하겠다는 것이 @SuppressWarnings("unchecked") 이다. 물론 절대 남발하면 안되고, 형 변환시 예외 가능성이 없을 확실한 경우에 최소한의 범위에서 써주는 것이 좋다. 그렇지 않으면 중요한 경고 메세지를 놓칠 수도 있기 때문이다.
get 메소드에서도 마찬가지로 index가 음수이거나, size와 같거나 큰 수가 들어올 경우 잘못된 참조를 하고 있기 때문에 IndexOutOfBoundsException() 예외를 발생시킨다.
만약 index가 정상적인 참조가 가능한 값일 경우 해당 인덱스의 요소를 반환해준다. 이 때 원본 데이터 타입으로 반환하기 위해 E 타입으로 캐스팅을 해준다.
2. set(int index, E value) 메소드
set 메소드는 기존에 index에 위치한 데이터를 새로운 데이터(value)으로 '교체'하는 것이다. add메소드는 데이터 '추가'인 반면에 set은 '교체'라는 점을 기억해두도록 하자.
결과적으로 index에 위치한 데이터를 교체하는 것이기 때문에 get이랑 메소드가 유사하다. 다만 get은 해당 인덱스의 값을 반환하는 것이였다면 set은 데이터만 교체해주면 된다.
@Override
public void set(int index, E value) {
if (index >= size || index < 0) { // 범위를 벗어날 경우 예외 발생
throw new IndexOutOfBoundsException();
}
else {
// 해당 위치의 요소를 교체
array[index] = value;
}
}마찬가지로 잘못된 인덱스를 참조하고 있진 않은지 반드시 검사가 필요하다. 그냥 index로 참조하는 모든 메소드들은 반드시 검사해야한다고 생각하면 편하다.
3. indexOf(Object value) 메소드
indexOf 메소드는 사용자가 찾고자 하는 요소(value)의 '위치(index)'를 반환하는 메소드다.
그러면 이러한 질문이 들어올 수 있다. "찾고자 하는 요소가 중복된다면 어떻게 반환해야 하나요?" 이에 대한 답은 가장 먼저 마주치는 요소의 인덱스를 반환한다는 것이다. (실제로 자바에서 제공하는 indexOf 또한 동일하게 구현된다.)
"그럼 찾고자 하는 요소가 없다면요?" 이러한 경우 -1 을 반환한다.
그리고 중요한 점은 객체끼리 비교할 때는 동등연산자(==)가 아니라 반드시 .equals() 로 비교해야 한다. 객체끼리 비교할 때 동등연산자를 쓰면 값을 비교하는 것이 아닌 주소를 비교하는 것이기 때문에 잘못된 결과를 초래한다..
@Override
public int indexOf(Object value) {
int i = 0;
// value와 같은 객체(요소 값)일 경우 i(위치) 반환
for (i = 0; i < size; i++) {
if (array[i].equals(value)) {
return i;
}
}
// 일치하는 것이 없을경우 -1을 반환
return -1;
}3 - 1. LastindexOf(Object value) 메소드
indexOf 메소드는 index가 0부터 시작했다면 반대로 거꾸로 탐색하는 과정도 있는 것이 좀 더 좋다. 예로들어 사용자가 찾고자 하는 인덱스가 뒤 쪽이라고 예상 가능할 때 굳이 앞에서부터 찾아 줄 필요가 없기 때문이다. 또한 이후에 구현 할 Stack에서도 이용 가능하므로 만들어 두는 것이 좀 더 좋다.
public int lastIndexOf(Object value) {
for(int i = size - 1; i >= 0; i--) {
if(array[i].equals(value)) {
return i;
}
}
return -1;
}4. contains(Object value) 메소드
indexOf 메소드는 사용자가 찾고자 하는 요소(value)의 '위치(index)'를 반환하는 메소드였다면, contains는 사용자가 찾고자 하는 요소(value)가 존재 하는지 안하는지를 반환하는 메소드다.
찾고자 하는 요소가 존재한다면 true를, 존재하지 않는다면 false를 반환한다.
음? 그러면 indexOf와 기능이 비슷하니깐 이를 쓸 수 있을 것 같은데? 라는 생각이 들었다면 매우 정답이다.
어차피 해당 요소가 존재하는지를 '검사'한다는 기능은 같기 때문에 indexOf 메소드를 이용하여 만약 음수가 아닌 수가 반환되었다면 요소가 존재한다는 뜻이고, 음수(-1)이 나왔다면 요소가 존재하지 않는다는 뜻이다. 즉, 아래와 같이 contains 메소드를 만들 수 있다.
@Override
public boolean contains(Object value) {
// 0 이상이면 요소가 존재한다는 뜻
if(indexOf(value) >= 0) {
return true;
}
else {
return false;
}
}이렇게 서로 메소드들을 연결하여 사용하면 다른 사람이 코드를 보았을 때도 훨씬 이해가 잘 되고, 무엇보다 코드가 간결하면서 깔끔해진다.
이렇게 get, set, indexOf, contains 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[remove 메소드 구현]
드디어 사람들이 구현하는데 있어 가장 많이 어려워하고, 가장 많이 에러가 나고, 가장 때려치고싶게 만드는 삭제 부분이다. 필자도 처음으로 자료구조를 구현해보는 과제에서 항상 많이 막혔던 부분이 바로 삭제 부분이다. (그나마 ArrayList는 양반이다.)
remove 메소드의 경우 크게 2가지로 나눌 수 있다.
- 특정 index의 요소를 삭제 - remove(int index)
- 특정 요소를 삭제 - remove(Object value)
물론 자바에 내장되어있는 ArrayList도 remove() 메소드는 없다. remove(int index)와 remove(Object value) 메소드만 존재한다. 하지만 이후에 다룰 Stack이나 LinkedList, Queue 등 다양한 자료구조들은 remove()메소드가 존재하니 조만간 다룰 일이 생길 것이다.
만약 remove()기능을 넣어 가장 앞 또는 뒤의 요소를 제거하는 기능을 넣고싶다면 밑에서 다룰 remove(int index)을 호출하여 파라미터로 0 또는 size-1 을 넘겨주면 된다.
그래도 우리가 자주 다뤄왔던 배열을 다루는 것이기 때문에 다른 자료구조에 비해 어렵지는 않을 것이다. 한 번 하나씩 보도록 하자.
1. remove(int index) 메소드
remove(int index) 는 '특정 위치에 있는 요소를 제거'하는 것이다.
앞서 add(int index, E value)를 했던 방식을 거꾸로 하면 된다는 의미다.
쉽게 생각해서 index에 위치한 데이터를 삭제해버리고, 해당 위치 이후의 데이터들을 한 칸씩 '당겨오는 것'이다. 이해하기 쉽도록 이미지로 보자.
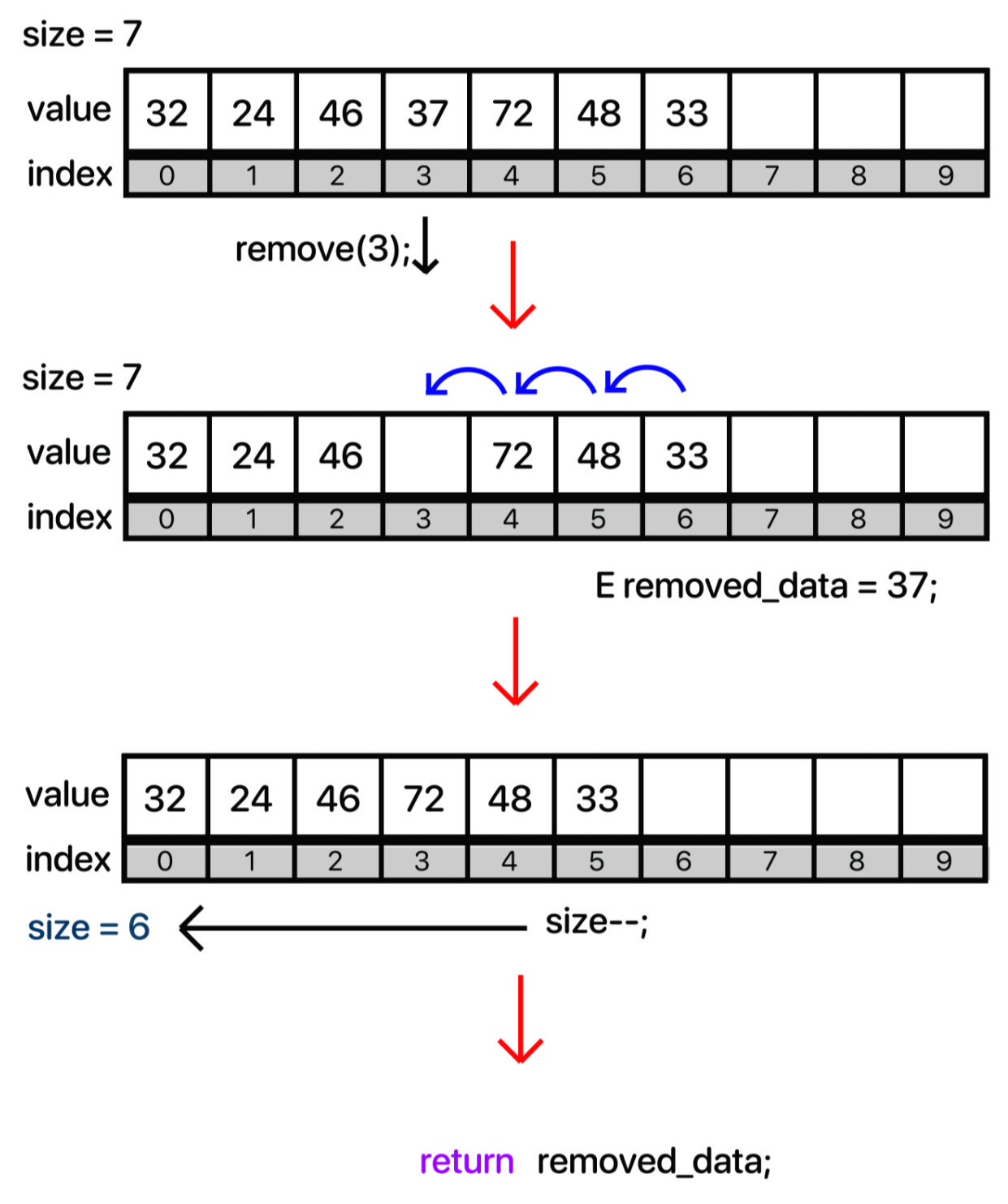
위와 같이 단계별로 나눌 수 있다. 즉, index의 요소를 임시변수에 담고 배열에서는 지운다. 그 다음 이후의 데이터들을 한 칸씩 당여온다. 그렇게 데이터 사이에 빈 공간을 매꿨으면 size값을 줄여주면 된다. 물론 삭제되면서 데이터가 일정 이상 비워진 경우 용적을 줄이기 위해 resize() 메소드를 가장 마지막에 추가해주면 된다.
@SuppressWarnings("unchecked")
@Override
public E remove(int index) {
if (index >= size || index < 0) {
throw new IndexOutOfBoundsException();
}
E element = (E) array[index]; // 삭제될 요소를 반환하기 위해 임시로 담아둠
array[index] = null;
// 삭제한 요소의 뒤에 있는 모든 요소들을 한 칸씩 당겨옴
for (int i = index; i < size; i++) {
array[i] = array[i + 1];
array[i + 1] = null;
}
size--;
resize();
return element;
}마찬가지로 삭제된 원소를 반환해야하는지라 Object 타입을 E 타입으로 캐스팅을 해주면서 경고창이 뜬다. 하지만 get()메소드에서 설명했듯이 삭제되는 원소 또한 E Type 외에 들어오는 것이 없기 때문에 형 안정성이 확보되므로 경고표시를 무시하기 위해 @SuppressWarnings("unchecked")을 붙인다.
그리고 잘 생각해야 할 것이 항상 마지막 원소의 인덱스는 size 보다 1 작다. 그렇기 때문에 범위 체크와, 이후의 배열 요소들을 한 칸씩 당겨울 때 시작점과 끝 점을 잘 생각하면서 참조해야한다.
또한 명시적으로 요소를 null로 처리해주어야 가비지컬렉터에 의해 더이상 쓰지 않는 데이터의 메모리를 수거(반환)해주기 때문에 최대한 null 처리를 하는 것이 좋다.
(물론 명시적으로 안해도 크게 문제는 없지만 그럴경우 가비지컬렉터가 쓰지 않는 데이터더라도 나중에 참조될 가능성이 있는 데이터로 볼 가능성이 높아진다. 이는 결국 메모리를 많이 잡아먹을 수 있는 가능성이 있다는 것이고 결과적으로 프로그램 성능에도 영향을 미친다는 것이다.)
만약 index가 정상적인 참조가 가능한 값일 경우 해당 인덱스의 요소를 반환해준다. 이 때 원본 데이터 타입으로 반환하기 위해 E 타입으로 캐스팅을 해준다.
2. remove(Object value) 메소드
remove(Object value) 메소드는 사용자가 원하는 특정 요소(value)를 리스트에서 찾아서 삭제하는 것이다. IndexOf 메소드와 마찬가지로 리스트안에 특정 요소와 매칭되는 요소가 여러개 있을 경우 가장 먼저 마주하는(가장 앞부분에 있는) 요소만 삭제한다.
결과적으로 이 메소드에서 필요한 동작은 value와 같은 요소가 존재하는지, 만약에 존재한다면 몇 번째 위치에 존재하는지를 알아야 하는 것 하나. 그리고 그 index의 데이터를 지우고 나머지 뒤의 요소들을 하나씩 당기는 작업 하나. 이렇게 총 두가지의 동작이 필요하다.
그러면 우리는 그동안 만들었던 메소드들을 이용하여 매우 간단하게 만들 수 있다.
리스트에 특정 요소와 같은 요소의 index를 찾는 작업은 우리가 만들어놓았던 indexOf() 메소드가 있다.
그리고 index를 통해 삭제하는 작업은 앞선 remove(int index) 메소드가 있다. 이 두 가지를 조합하면 되지 않겠는가?
즉, 하나하나 다시 짤 필요 없이 기존에 있던 메소드를 재활용 하는 것이다.
@Override
public boolean remove(Object value) {
// 삭제하고자 하는 요소의 인덱스 찾기
int index = indexOf(value);
// -1이라면 array에 요소가 없다는 의미이므로 false 반환
if (index == -1) {
return false;
}
// index 위치에 있는 요소를 삭제
remove(index);
return true;
}보면 indexOf 메소드를 통해 해당 value와 일치하는 요소를 찾아온다. 만약 -1 이라면 일치하는 요소가 없다는 의미이므로 false를 반환하고, 아닐경우 index에 해당하는 요소를 제거해주고 true를 반환하면 끝이 난다.
이렇게 요소를 삭제하는 remove 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[size, isEmpty, clear 메소드 구현]
이제 나머지 List 인터페이스에 있던 size, isEmpty, clear를 만들 차례다.
다른 메소드 구현에 비해 매우 쉬운지라 바로바로 넘어가도록 하겠다.
1. size() 메소드
ArrayList가 동적으로 할당되면서 요소들을 삽입, 삭제가 많아지면 사용자가 리스트에 담긴 요소의 개수가 몇 개인지 기억하기 힘들다. 더군다나 ArrayList에서 size 변수는 private 접근제한자를 갖고 있기 때문에 외부에서 직접 참조를 할 수 없다. (왜냐하면 size를 접근할 수 있게 될 경우 size에 사용자가 고의적으로 데이터를 조작할 수 있기 때문이다.)
그렇기에 size 변수의 값을 반환해주는 메소드인 size() 를 만들어줄 필요가 있다. size만 반환해주면 되기 때문에 매우 간단하다.
@Override
public int size() {
return size; // 요소 개수 반환
}2. isEmpty() 메소드
isEmpty() 메소드는 현재 ArrayList에 요소가 단 하나도 존재하지 않고 비어있는지를 알려준다.
리스트가 비어있을 경우 true를, 비어있지 않고 단 한개라도 요소가 존재 할 경우 false를 반환해주면 된다. 즉, 이 말은 size가 요소의 개수였으므로 size == 0 이면 true, 0 이 아니면 false 라는 것이다. 굳이 배열을 모두 순회하여 데이터가 존재하는지 검사해줄 필요가 없다.
@Override
public boolean isEmpty() {
return size == 0; // 요소가 0개일 경우 비어있다는 의미이므로 true반환
}3. clear() 메소드
clear()는 단어에서 짐작 할 수 있듯 모든 요소들을 비워버리는 작업이다. 예로들어 리스트에 요소를 담아두었다가 초기화가 필요할 때 쓸 수 있는 유용한 존재다. 또한 모든 요소를 비워버린다는 것은 요소가 0개라는 말로 size 또한 0으로 초기화해주고, 배열의 용적 또한 현재 용적의 절반으로 줄일 수 있도록 해준다.
왜 초기 값이 아니라 절반이죠? 라고 질문할 수도 있다. 물론 초기값으로 초기화 해주어도 되나 생각해보면 현재 배열의 용적은 결국 데이터를 해당 용적에 만족하는 조건만큼 썼다는 의미가 된다.
예로들어 데이터가 1500개였다고 가정해보자. 그럼 용적량은 10부터 2씩 곱해지므로 2560이었을 것이다.
요소들을 모두 초기화 했더라도 앞으로 들어올 데이터들 또한 데이터가 1500개일 가능성이 높다. 즉, 현재 용적량의 기대치에 근접할 가능성이 높기 때문에 일단은 용적량을 일단 절반으로만 줄이는 것이다.
(또한 그만큼 데이터를 쓰지 않더라도 삭제 과정에서 용적량을 줄이기 때문에 크게 문제되진 않는다.)
@Override
public void clear() {
// 모든 공간을 null 처리 해준다.
for (int i = 0; i < size; i++) {
array[i] = null;
}
size = 0;
resize();
}모든 배열을 명시적으로 null로 처리해주는 것이 좋다.
이렇게 size, isEmpty, clear 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[clone, toArray 메소드 구현]
이 부분은 굳이 구현하는데 중요한 부분은 아니라 넘어가도 된다. 다만 조금 더 많은 기능을 원할 경우 추가해주면 좋은 메소드들이긴 하다. clone은 기존에 있던 객체를 파괴하지 않고 요소들이 동일한 객체를 새로 하나 만드는 것이다. 그리고 toArray는 리스트를 출력할 때 for-each문을 쓰기 위해 만들어보았다.
원래는 Iterable을 implement하여 구현해주면 되지만 이 걸 설명하면 본 글의 취지하고는 많이 엇나가기도 하고 내용이 조금 어렵다. 그래서 다른 대안으로 toArray를 만든 것이다.
1. clone() 메소드
만약 사용자가 사용하고 있던 ArrayList를 새로 하나 복제하고 싶을 때 쓰는 메소드다.
단순히 = 연산자로 객체를 복사하게 되면 '주소'를 복사하는 것이기 때문에 복사한 객체에서 데이터를 조작할 경우 원본 객체까지 영향을 미친다. 즉 얕은 복사(shallow copy)가 된다는 것이다.
ArrayList<Integer> original = new ArrayList<>();
original.add(10); // original에 10추가
ArrayList<Integer> copy = original;
copy.add(20); // copy에 20추가
System.out.println("original list");
for(int i = 0; i < original.size(); i++) {
System.out.println("index " + i + " data = " + original.get(i));
}
System.out.println("copy list");
for(int i = 0; i < copy.size(); i++) {
System.out.println("index " + i + " data = " + copy.get(i));
}
System.out.println("original list reference : " + original);
System.out.println("copy list reference : " + copy);[결과]
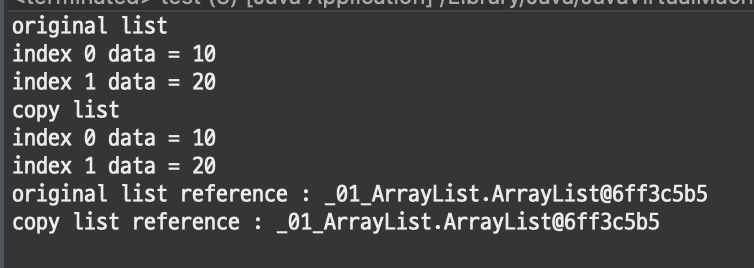
보다시피 객체의 주소가 복사되는 것이기 때문에 주소와 데이터 모두 같아져버리는 문제가 발생한다.
이러한 것을 방지하기 위해서 깊은 복사를 하는데, 이 때 필요한 것이 바로 clone()이다. Object에 있는 메소드이지만 접근제어자가 protected로 되어있어 우리가 만든 것 처럼 사용자 클래스의 경우 Cloneable 인터페이스를 implement 해야한다.
즉, public class ArrayList implements List 에 Cloneable도 추가해주어야 한다.
그리고나서 clone()을 구현하면 되는데, 다음과 같이 재정의를 하면 된다.
@Override
public Object clone() throws CloneNotSupportedException {
// 새로운 객체 생성
ArrayList<?> cloneList = (ArrayList<?>)super.clone();
// 새로운 객체의 배열도 생성해주어야 함 (객체는 얕은복사가 되기 때문)
cloneList.array = new Object[size];
// 배열의 값을 복사함
System.arraycopy(array, 0, cloneList.array, 0, size);
return cloneList;
조금 어려워 보일 수 있는데, 이해하지 못해도 된다. ArrayList에서 중요한 부분은 아니니...
그래도 설명을 덧붙이자면, super.clone() 자체가 생성자 비슷한 역할이고 shallow copy를 통해 사실상 new ArrayList() 를 호출하는 격이라 제대로 완벽하게 복제하려면 clone한 리스트의 array 또한 새로 생성해서 해당 배열에 copy를 해주어야 한다.
위와같이 만들고 나서 clone()한 것 까지 포함해서 테스트를 해보자.
ArrayList<Integer> original = new ArrayList<>();
original.add(10); // original에 10추가
ArrayList<Integer> copy = original;
ArrayList<Integer> clone = (ArrayList<Integer>) original.clone();
copy.add(20); // copy에 20추가
clone.add(30); // clone에 30추가
System.out.println("original list");
for(int i = 0; i < original.size(); i++) {
System.out.println("index " + i + " data = " + original.get(i));
}
System.out.println("\ncopy list");
for(int i = 0; i < copy.size(); i++) {
System.out.println("index " + i + " data = " + copy.get(i));
}
System.out.println("\nclone list");
for(int i = 0; i < clone.size(); i++) {
System.out.println("index " + i + " data = " + clone.get(i));
}
System.out.println("\noriginal list reference : " + original);
System.out.println("copy list reference : " + copy);
System.out.println("clone list reference : " + clone);[결과]
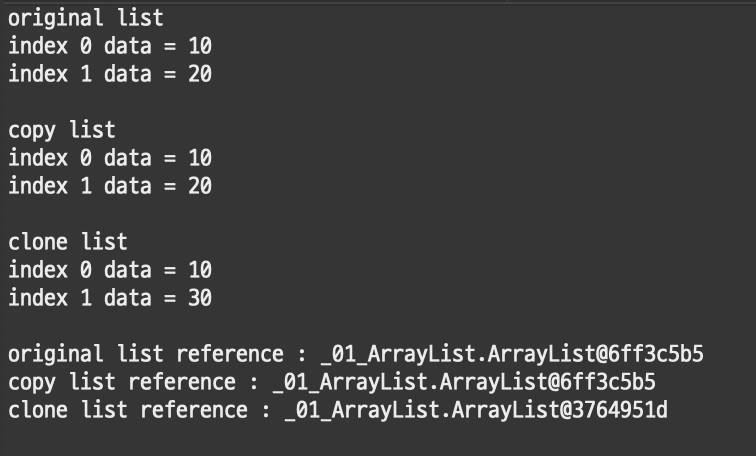
결과적으로 clone으로 복사한 ArrayList는 원본 배열에 영향을 주지 않는다.
2. toArray() 메소드
toArray()는 크게 두 가지가 있다.
하나는 아무런 인자 없이 현재 있는 ArrayList의 리스트를 객체배열(Object[]) 로 반환해주는 Object[] toArray() 메소드가 있고,
다른 하나는 ArrayList를 이미 생성 된 다른 배열에 복사해주고자 할 때 쓰는 T[] toArray(T[] a) 메소드가 있다.
즉 차이는 이런 것이다.
ArrayList<Integer> list = new ArrayList<>();
// get list to array (using toArray())
Object[] array1 = list.toArray();
// get list to array (using toArray(T[] a)
Integer[] array2 = new Integer[10];
array2 = list.toArray(array2);1번의 장점이라면 ArrayList에 있는 요소의 수만큼 정확하게 배열의 크기가 할당되어 반환된다는 점이다.
2번의 장점이라면 객체 클래스로 상속관계에 있는 타입이거나 Wrapper(Integer -> int) 같이 데이터 타입을 유연하게 캐스팅할 여지가 있다는 것이다. 또한 리스트에 원소 5개가 있고, array2 배열에 10개의 원소가 있다면 array2에 0~4 index에 리스트에 있던 원소가 복사되고, 그 외의 원소는 기존 array2배열에 초기화 되어있던 원소가 그대로 남는다.
두 메소드 모두 구현해보자면 다음과 같다.
public Object[] toArray() {
return Arrays.copyOf(array, size);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) {
// copyOf(원본 배열, 복사할 길이, Class<? extends T[]> 타입)
return (T[]) Arrays.copyOf(array, size, a.getClass());
}
// 원본배열, 원본배열 시작위치, 복사할 배열, 복사할배열 시작위치, 복사할 요소 수
System.arraycopy(array, 0, a, 0, size);
return a;
}Object[] toArray() 메소드의 경우 원본배열(array)를 요소 개수(size)만큼 복사하여 Object[] 배열을 반환해주는 메소드다. 이 것을 그대로 써서 반환해주면 되기 때문에 크게 어렵지 않다.
두 번째 T[] toArray(T[] a) 메소드를 보자.
이 부분은 제네릭 메소드로, 우리가 만들었던 ArrayList의 E타입하고는 다른 제네릭이다. 예로들어 E Type이 Integer라고 가정하고, T타입은 Object 라고 해보자.
Object는 Integer보다 상위 타입으로, Object 안에 Integer 타입의 데이터를 담을 수도 있다. 이 외에도 사용자가 만든 부모, 자식 클래스 같이 상속관계에 있는 클래스들에서 하위 타입이 상위 타입으로 데이터를 받고 싶을 때 쓸 수 있도록 하기 위함이다.
즉, 상위타입으로 들어오는 객체에 대해서도 데이터를 담을 수 있도록 별도의 제네릭메소드를 구성하는 것이다.
그리고, 들어오는 배열(a)가 현재 array의 요소 개수(size)보다 작으면 size에 맞게 a의 공간을 재할당 하면서 array에 있던 모든 요소를 복사한다.
쉽게 이해해보면 ArrayList의 array의 요소가 4개 {1, 2, 3, 4} 있다고 치자. 그리고 Object[] copy = new Object[1]라는 배열을 하나 만들었는데, 공간이 한 개 밖에 없다.
그러면 array의 요소 1개만 복사하는 것이 아니라 copy 배열의 사이즈가 1에서 4로 증가하여 copy배열에 {1, 2, 3, 4}가 모두 담기게 되는 것이다.
또한 앞서 상위타입에 대해서도 담을 수 있도록 하기 위해 copyOf메소드에서 Class라는 파라미터를 마지막에 넣어준다.(a.getClass()) 그런다음 Object[] 배열로 리턴 된 것을 T[] 타입으로 캐스팅하여 반환해주면 된다.
반대로 파라미터로 들어오는 배열의 크기가 현재 ArrayList에 있는 array보다 크다면 앞 부분부터 array에 있던 요소만 복사해서 a배열에 넣고 반환해주면 된다.
- 전체 코드
import Interface_form.List; // List 인터페이스가 있는 패키지다.
import java.util.Arrays;
/**
*
* @author ST_ (st-lab.tistory.com)
*
* @param <E> the type of elements in this list
*
*/
public class ArrayList<E> implements List<E>, Cloneable {
private static final int DEFAULT_CAPACITY = 10; // 최소(기본) 용적 크기
private static final Object[] EMPTY_ARRAY = {}; // 빈 배열
private int size; // 요소 개수
Object[] array; // 요소를 담을 배열
// 생성자1 (초기 공간 할당 X)
public ArrayList() {
this.array = EMPTY_ARRAY;
this.size = 0;
}
// 생성자2 (초기 공간 할당 O)
public ArrayList(int capacity) {
this.array = new Object[capacity];
this.size = 0;
}
private void resize() {
int array_capacity = array.length;
// if array's capacity is 0
if (Arrays.equals(array, EMPTY_ARRAY)) {
array = new Object[DEFAULT_CAPACITY];
return;
}
// 용량이 꽉 찰 경우
if (size == array_capacity) {
int new_capacity = array_capacity * 2;
// copy
array = Arrays.copyOf(array, new_capacity);
return;
}
// 용적의 절반 미만으로 요소가 차지하고 있을 경우
if (size < (array_capacity / 2)) {
int new_capacity = array_capacity / 2;
// copy
array = Arrays.copyOf(array, Math.max(new_capacity, DEFAULT_CAPACITY));
return;
}
}
@Override
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
// 꽉차있는 상태라면 용적 재할당
if (size == array.length) {
resize();
}
array[size] = value; // 마지막 위치에 요소 추가
size++; // 사이즈 1 증가
}
@Override
public void add(int index, E value) {
if (index > size || index < 0) { // 영역을 벗어날 경우 예외 발생
throw new IndexOutOfBoundsException();
}
if (index == size) { // index가 마지막 위치라면 addLast 메소드로 요소추가
addLast(value);
}
else {
if(size == array.length) { // 꽉차있다면 용적 재할당
resize();
}
// index 기준 후자에 있는 모든 요소들 한 칸씩 뒤로 밀기
for (int i = size; i > index; i--) {
array[i] = array[i - 1];
}
array[index] = value; // index 위치에 요소 할당
size++;
}
}
public void addFirst(E value) {
add(0, value);
}
@SuppressWarnings("unchecked")
@Override
public E get(int index) {
if(index >= size || index < 0) { // 범위 벗어나면 예외 발생
throw new IndexOutOfBoundsException();
}
// Object 타입에서 E타입으로 캐스팅 후 반환
return (E) array[index];
}
@Override
public void set(int index, E value) {
if (index >= size || index < 0) { // 범위를 벗어날 경우 예외 발생
throw new IndexOutOfBoundsException();
}
else {
// 해당 위치의 요소를 교체
array[index] = value;
}
}
@Override
public int indexOf(Object value) {
int i = 0;
// value와 같은 객체(요소 값)일 경우 i(위치) 반환
for (i = 0; i < size; i++) {
if (array[i].equals(value)) {
return i;
}
}
// 일치하는 것이 없을경우 -1을 반환
return -1;
}
public int lastIndexOf(Object value) {
for(int i = size - 1; i >= 0; i--) {
if(array[i].equals(value)) {
return i;
}
}
return -1;
}
@Override
public boolean contains(Object value) {
// 0 이상이면 요소가 존재한다는 뜻
if(indexOf(value) >= 0) {
return true;
}
else {
return false;
}
}
@SuppressWarnings("unchecked")
@Override
public E remove(int index) {
if (index >= size || index < 0) {
throw new IndexOutOfBoundsException();
}
E element = (E) array[index]; // 삭제될 요소를 반환하기 위해 임시로 담아둠
array[index] = null;
// 삭제한 요소의 뒤에 있는 모든 요소들을 한 칸씩 당겨옴
for (int i = index; i < size; i++) {
array[i] = array[i + 1];
array[i + 1] = null;
}
size--;
resize();
return element;
}
@Override
public boolean remove(Object value) {
// 삭제하고자 하는 요소의 인덱스 찾기
int index = indexOf(value);
// -1이라면 array에 요소가 없다는 의미이므로 false 반환
if (index == -1) {
return false;
}
// index 위치에 있는 요소를 삭제
remove(index);
return true;
}
@Override
public int size() {
return size; // 요소 개수 반환
}
@Override
public boolean isEmpty() {
return size == 0; // 요소가 0개일 경우 비어있다는 의미이므로 true반환
}
@Override
public void clear() {
// 모든 공간을 null 처리 해준다.
for (int i = 0; i < size; i++) {
array[i] = null;
}
size = 0;
resize();
}
// 부록 메소드
@Override
public Object clone() throws CloneNotSupportedException {
// 새로운 객체 생성
ArrayList<?> cloneList = (ArrayList<?>)super.clone();
// 새로운 객체의 배열도 생성해주어야 함 (객체는 얕은복사가 되기 때문)
cloneList.array = new Object[size];
// 배열의 값을 복사함
System.arraycopy(array, 0, cloneList.array, 0, size);
return cloneList;
}
public Object[] toArray() {
return Arrays.copyOf(array, size);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) {
// copyOf(원본 배열, 복사할 길이, Class<? extends T[]> 타입)
return (T[]) Arrays.copyOf(array, size, a.getClass());
}
// 원본배열, 원본배열 시작위치, 복사할 배열, 복사할배열 시작위치, 복사할 요소 수
System.arraycopy(array, 0, a, 0, size);
return a;
}
}- 정리
ArrayList에 대한 기본적인 메소드를 구현해보았다. 물론 이 방법이 항상 정답은 아니지만, 최대한 고급지면서도(?) 이해하기 쉽게 메소드를 구현하려고 노력했다.
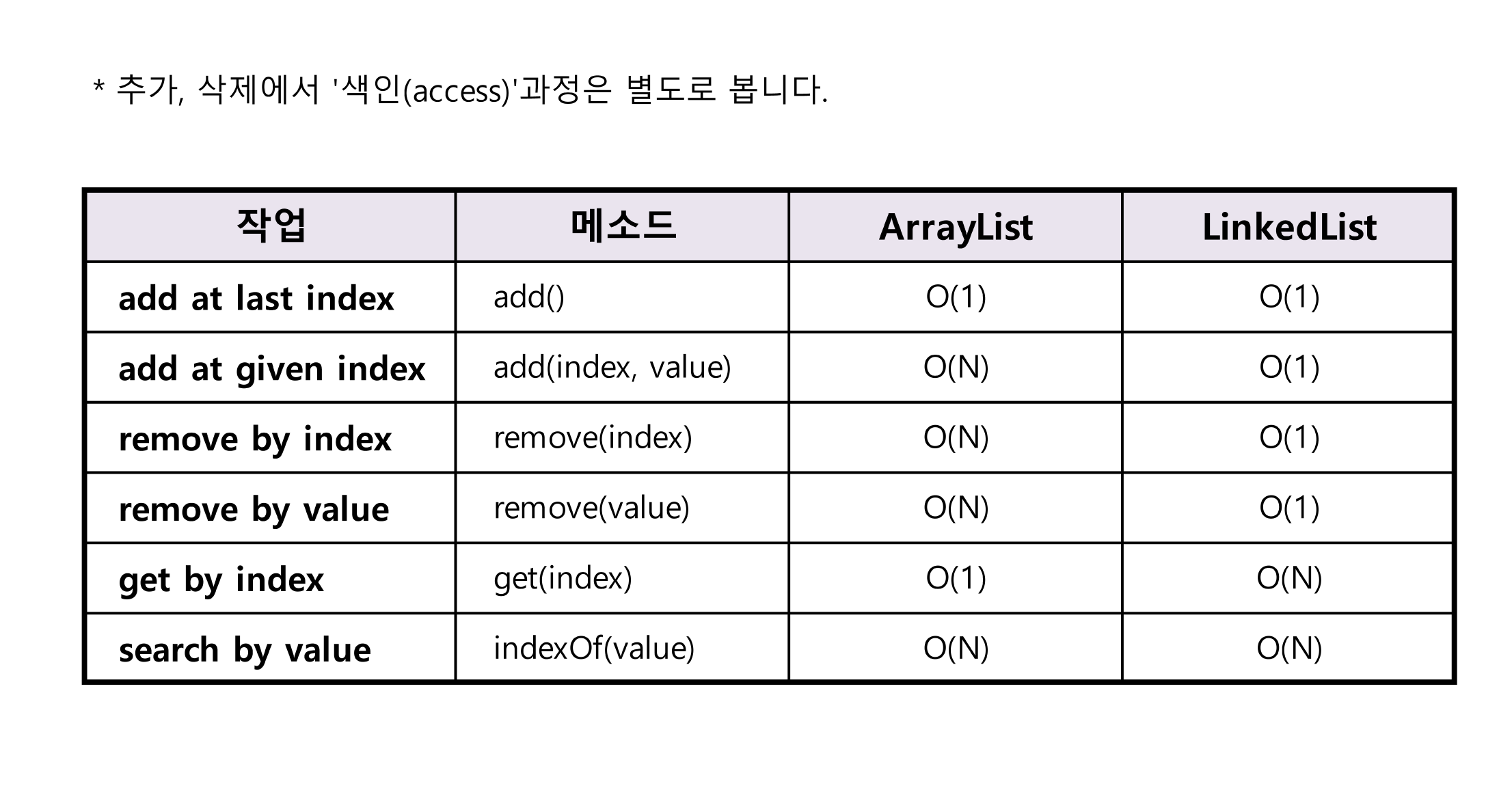
또한 보면 구현해보면서 알곘지만, index를 통해 요소에 접근하는 작업은 매우 빠르다. 반대로 중간 삽입, 삭제의 경우 후자의 요소들을 모두 밀어내거나 당겨와야 하기 때문에 삽입, 삭제는 비효율적이라는 것을 느낄 수 있었을 것이다.
다음은 ArrayList와 앞으로 구현할 LinkedList의 시간 복잡도다.
아마 자료구조를 처음 접하는 분들은 제네릭에 대한 이해가 없을경우 어려울 수도 있다. 하지만 그렇다고 byte형, int형, double형 등등.. 수많은 타입에 대해 하나하나 만들 수는 없지 않은가.. 약간 어떤 느낌이냐면, 1부터 100을 더하라고 할 때 101 × 50 으로 해결할 수 있는 것을 1 부터 하나하나 모두 더해간다는 느낌이다. 즉 불필요한 작업을 요한다는 것.
