1 네트워크 애플리케이션의 원리
애플리케이션 계층은 프로그래머의 입장에서 마주하는 부분이다. 그래서 패킷이 애플리케이션을 떠나서 라우터 및 스위치를 거쳐가는 등의 과정은 블랙박스가 되어, 프로그래머가 알 수가 없다. 그리고 신경쓰지 않더라도 하위 계층에서 처리가 되며, 또, 프로그래머의 책임을 떠난 부분이기 때문에 크게 신경쓸 필요는 없다.
-
1.1 네트워크 애플리케이션 구조
애플리케이션 구조는 프로그래머에 의해 설계되어서 종단 시스템(end system)에서 동작된다. 개발자는 주로 널리 알려진 2가지 구조를 이용하여 개발을 한다.
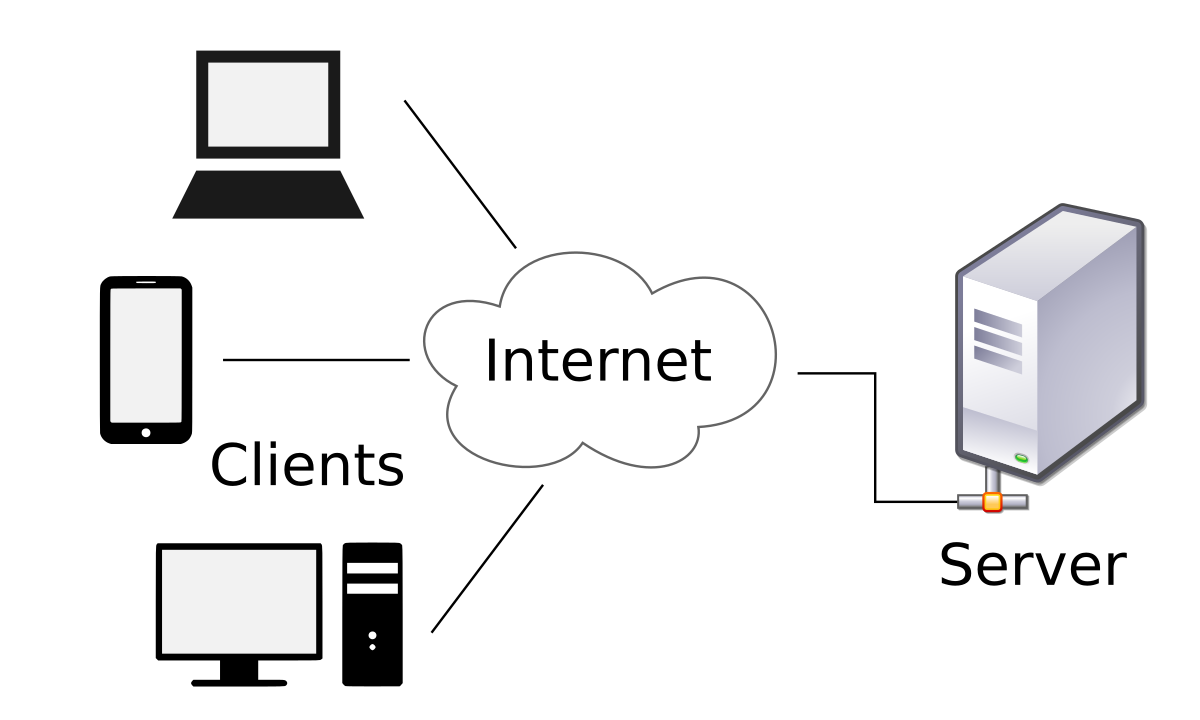
첫 번째는 클라이언트-서버 구조로, 항시 켜져있는 서버가 클라이언트의 요청을 받아서 응답을 하는 것이다.

나머지는 P2P(peer to peer) 구조다. 이 구조에서는 사용자가 서버가 되기도 하고, 클라이언트가 되기도 한다.
1.2 프로세스 간 통신
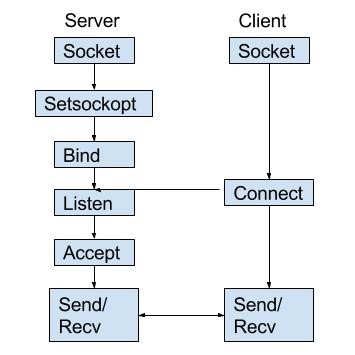
네트워크 통신을 하게 되면 두 프로세스 간의 통신을 하게 된다. 이 과정에서 메세지를 교환함으로써 서로 통신을 하게 된다. 여기서 서버와 클라이언트로 나뉘게 되는데, 두 프로세스간의 통신을 초기화하는 측을 클라이언트라 하고, 세션을 시작하기 위해 접속을 기다리는 측을 서버라고 한다.
이 통신에서 소켓을 통해 메시지를 주고 받는다. 여기서 프로세스는 집이고, 소켓은 출입구로 비유가 된다. 그렇기 때문에 소켓을 통해서 메시지를 밀어내서 전송을 한다. 여기서 개발자는 애플리케이션 계층에서 제어권을 갖지만, 트랜스포트 계층에선 제어권을 가지지 못한다. 그나마 할 수 있는 것은 프로토콜 선택 와 버퍼 및 세그먼트의 크기 설정 정도이다.
이 전송을 위해서는 IP주소가 우선적으로 필요한데, 이를 바탕으로 호스트를 찾아가기 때문이다. 그 다음으로 통신 할 프로세스가 어떤 것인지를 알 필요가 있는데, 그것은 포트 번호를 통해 구분을 할 수 있다.
-
1.3 애플리케이션이 이용 가능한 트랜스포트 서비스
소켓은 애플리케이션과 트랜스포트 계층간의 인터페이스다. 그래서 애플리케이션 입장에서는 트랜스포트 계층에서 제공하는 프로토콜을 선택하여 사용하여야 한다. 그 프로토콜을 선택하는 데에 있어서 트랜스포트 계층이 제공하는 서비스에 차이가 있다.
-
신뢰적 데이터 전송 : 구현하고자 하는 애플리케이션 유형에 따라서 데이터 손실이 어느정도 허용이 되느냐, 아니면 매우 민감하느냐 차이가 있다. 그래서 전송속도가 느려지는 것을 감수하더라도, 신뢰적인 데이터 전송 서비스가 필요 할 수도 있다.
-
처리량 : 트랜스포트 계층에서 처리 할 수 있는 데이터는 한정되어 있기 때문에, 애플리케이션 계층은 이에 맞출 수 밖에 없다. 이 부분은 대역폭 민감 애플리케이션과 관련이 깊다.
-
시간 : 데이터가 전송되는데 최소 몇 초안이다 를 보장하는 것이다. 왜냐하면 온라인 게임이나 실시간 방송과 같은 서비스는 빠른 시간안에 데이터가 전송되야 하기 때문에 시간과 관련하여 민감하다.
-
보안 서비스 : 데이터가 전송 될 때 트랜스포트 프로토콜이 암호화를 한 뒤에, 도착하면 해독을 한다. 그래서 감청 당한다고 해도 노출될 위험이 줄어든다.
-
1.4 인터넷 전송 프로토콜이 제공하는 서비스
인터넷이 제공하는 전송 프로토콜은 2가지로, UDP(user datagram protocol)과 TCP(transmission control protocol) 이다.
TCP는 연결 지향형 서비스와 신뢰적인 데이터 전송 서비스를 제공한다. TCP 전송 프로토콜에서 연결을 시도하면 핸드셰이킹을 통해 준비과정을 거친다. 그리고 TCP 연결이 두 프로세스 간의 소켓 사이에 존재한다고 얘기한다. 신뢰적인 데이터 전송 서비스는 모든 데이터가 오류 없이 올바르게 전달되기 위한 서비스다. 그래서 TCP는 애플리케이션의 스트림을 손실 및 중복없이 소켓으로 전달한다.
이에 반해서 UDP는 비연결지향형 으로 핸드셰이킹 없이 통신을 한다. 그리고 메시지가 수신측에 도착하는 것을 보장하지 않고, 혼잡제어도 없다. 따라서 데이터를 원하는 속도로 네트워크 계층에 보낼 수가 있다.
-
1.5 애플리케이션 계층 프로토콜
애플리케이션 계층은 다른 종단 시스템에서 실행되고, 메세지를 주고 받는다. 여기서 메세지의 타입, 문법, 의미과 같은 정보들을 담고 있다. 여러 애플리케이션 프로토콜은 RFC에 명시되어 있어서, 이 같은 공개된 프로토콜을 사용한다면 서로 다른 프로그램끼리도 통신이 가능하다. 다만. 애플리케이션 계층의 프로토콜은 네트워크 애플리케이션의 한 요소일 뿐이기 때문에 잘 구분해야 한다.
-
1.6 여기서 다루는 네트워크 애플리케이션
여기서 인기있는 네트워크 애플리케이션인 웹, 파일 전송, 전자메일, 디렉터리 서비스, 비디오 스트리밍, P2P를 다룰 것이다.
2. 웹과 HTTP
-
2.1 HTTP 개요
Hypertext Transfer Protocol의 약자로 웹 문서를 주고받는 것과 관련한 통신 규약이다. 이 프로토콜은 애플리케이션 계층에 속한다. 이 구조에서 서버와 클라이언트로 나뉘며, 웹 브라우저는 클라이언트 측을 담당한다. 이 통신에서 URL을 이용하여 이루어지는데, 서버측에서는 클라이언트가 필요로 하는 객체(html 파일, 오디오 소스 등)를 가지고 있다. 그리고 서버는 요청에 반응하여 클라이언트 측에 소스를 전송한다.
HTTP는 TCP를 전송 프로토콜로 하기 떄문에 먼저 연결 시도부터 한다. 그리고 소켓 인터페이스로 통신을 하고, 응답 메세지를 주고받는다. 서버 측에서 어떠한 상태도 저장하지 않기 때문에, HTTP는 비상태 프로토콜(stateless protocol)이라고도 한다.
-
2.2 비지속 연결과 지속 연결
서버와 클라이언트가 통신을 할 때 개발자는 선택을 해야 한다. 요구와 응답이 분리된 TCP 연결을 할 것이냐, 혹은 요구와 응답이 모두 같은 TCP 연결상에서 이루어 지느냐 하는 것이다. 전자는 비지속 연결(non-persistent connection) 이고, 후자는 지속 연결(persistence connection) 이라고 한다.
-
비지속 연결: 클라이언트와 서버는 종래의 방식대로 3방향 핸드셰이크 를 한다. 요청, 서버응답, 응답확인 방식이다. 그리고 서버측에서는 클라이언트의 요청 메세지를 읽고, 저장장치에서 객체를 추출하여 전송한다. 이 과정에서 클라이언트가 보낸 요청에 회신이 돌아오는 시간이 있는데, 이를 RTT(round-trip time)이라고 한다. 그리고 클라이언트가 서버에서 완전히 파일을 받고나면, TCP 연결을 끊는다. 그렇기 때문에 11개의 요청을 서버에 보내게 되면, 11개의 연결을 수립하게 된다.
-
지속 연결: 비지속 연결에는 몇 가지 단점이 있는데, 각 요청들마다 새로운 연결을 수립한다는 점이다. 그렇기 때문에 과도하게 많은 TCP변수들이 TCP 버퍼에 쌓이게 된다. 두번째 로는 각 객체는 RTT를 가진다는 것이다. 비지속 연결과는 거꾸로, 지속 연결은 TCP 연결을 유지한다. 그래서 서버는 연속된 요청에 응답 과정없이 객체를 연속하여 보낸다. 그리고 일정시간 사용되지 않으면 연결을 끊는다. 언뜻보면 매력적으로 보이지만, 관리를 잘 못하게 될 경우에 불필요한 지속 연결들이 쌓여 자원낭비를 유발 할 수도 있다.
-
2.3 HTTP 메시지 포맷
HTTP는 요청 메시지 및 응답 메시지로 두 가지가 존재한다. 여기서 요청 메시지는 총 5줄로 구성이 되며, 요청라인, 나머지 줄들은 헤더라인이다. 요청라인은 방식(method), URL, HTTP 버전 필드를 나눠가진다. 방식은 GET, POST, PUT, DELETE, HEAD 가 있으며, 대부분은 GET 방식을 이용한다.
헤더라인에서는 서버 호스트의 주소를 명기하며, 지속연결 여부 또한 담을 수 있다. 그리고 User-agent 라고 하여 요청을 보낸 브라우저 타입을 명기한다. 마지막으로 요청하는 언어를 담아 보내는데, 이는 요청일 뿐이기 때문에 해당하는 언어를 서버가 가지고 있지 않다면 소용이 없다.
헤더 이후에는 개체 몸체(entity body)가 있는데, GET 방식일 때에는 비어있고, POST 방식에서 사용된다. 이는 클라이언트가 폼을 채워넣을 때 POST 방식을 사용하여 같이 보내는 것이다. 물론, 꼭 POST를 할 필요는 없고, GET 방식으로도 가능하다. HEAD는 서버에 요청을 보내면 응답만 할 뿐, 객체를 전송하지 않는다. 그래서 주로 디버깅 용도로써 활용된다.
응답 메시지의 경우에는 상태 라인, 6개의 헤더 라인, 개체 몸체로 구성되어 있다. 상태 라인은 버전, 상태 코드, 해당 상태 메시지로 구성이 된다. 헤더 라인은 다음과 같이 구성이 된다.
- Connection: 클라이언트에게 메세지를 보내고 닫는지 여부를 나타낸다.
- Date: 응답이 생성되고 보낸 날짜를 의미한다.
- Server: 메시지가 어떤 웹 서버에 의해 만들어 졌는지를 나타낸다(예: 아파치, nginx).
- Last-Modified: 객체가 생성되거나, 마지막으로 수정된 날짜를 나타낸다.
- Content-Length: 송신된 객체의 바이트 수를 뜻한다.
- Content-Type: 개체 몸체 내부의 객체가 어떤 타입인지 나타낸다. 파일 확장자가 아니라, 이 헤더에서 표시하는 것이다.
상태 코드의 내용은 다음과 같다.
-
200 OK: 요청이 성공했고, 정보가 응답으로 보내짐
-
301 Moved Permanently: 요청 객체가 영원히 이동했다. 새로운 URL은 응답메시지에 나와있다. 따라서 클라이언트는 자동으로 URL을 추출한다.
-
400 Bad Request: 서버가 요청을 이해하지 못함.
-
404 Not Found: 요청 문서가 존재하지 않음.
-
505 HTTP Version Not Supported: 요청 HTTP 프로토콜 버전을 서버가 지원하지 않음.
-
2.4 사용자와 서버간의 상호작용: 쿠키
앞서 언급했듯이, HTTP는 서버에서 상태를 저장하지 않는다. 그러나 웹 사이트의 사용자를 확인해야 할 때가 있기 때문에, HTTP에 쿠키 라는 개념이 도입되었다. 이를 통하여 사용자를 추적 할 수가 있다. 쿠키는 다음과 같은 요소를 지니고 있다.
-
HTTP 응답 메세지 쿠키 헤더 라인
-
HTTP 요청 메세지 쿠키 헤더 라인
-
사용자의 브라우저에 사용자 종단 시스템과 관리를 지속하는 쿠키 파일
-
웹 사이트의 백엔드 데이터베이스
실제 쿠키의 동작은 서버에서 클라이언트 측 브라우저가 지니고있는 쿠키를 조회하고, 만약에 없다면 id값을 부여하고 새로 생성한다. 그리고 생성된 쿠키 id는 서버의 데이터 베이스에 저장되고, 클라이언트 측에서는 브라우저가 파일로 저장을 한다.
-
2.5 웹 캐싱
웹 캐시 , 혹은 프록시 서버(proxy server) 라고도 한다. 웹 캐시는 자체의 저장 디스크를 가지고 있어, 여기에 최근 호출된 객체의 사본을 저장한다. 대부분의 웹 캐시는 ISP에 존재하여서, 요청받은 파일이 웹 캐시에 존재한다면 이를 클라이언트에게 다시 반환한다. 만약에 이것이 존재하지 않는다면, 서버로 다시 요청을 보내서 객체를 캐시에 저장한다.
이를 통해서 응답 시간을 줄일 수가 있고, 트래픽을 대폭줄여주는 효과가 있다. 그래서 대학이나 회사같은 기관은 대역폭 개선을 할 필요가 없어져, 경제적 효과를 얻을 수 있다. 이로 인해서 콘텐츠 전송 네트워크(Content Distribution Network) 의 역할이 점점 더 중요해지고 있다.
-
2.6 조건부 GET
웹 캐싱으로 응답시간을 개선할 수 있겠지만, 최신본이 아닐 경우 문제가 생긴다. 다행히도, 이런 문제를 해결하는 방법이 있는데, HTTP는 객체들이 최신 상태임을 확인하면서 캐싱을 하도록 한다. 이것을 조건부 GET이라고 한다. HTTP 요청 메세지가 GET이고, 헤더에 If-Modified-Since:를 포함하면, 이것이 조건부 GET이다. 이 내용을 통해서 최신화 여부를 평가하여, 캐시에 저장된 사본을 갱신 여부를 따진다.
3. 인터넷 전자메일
전자메일은 비동기적인 통신 매체다. 이 애플리케이션은 사용자 에이전트 , 메일 서버 , SMTP(Simple Mail Transfer Protocol) 라는 3가지의 큰 요소로 구성되어 있다. 에이전트는 MS 아웃룩이 대표적인 예다. 그리고 메일 서버는 메일박스를 가지고있다. 이 메일박스에 메일이 보관되고, 관리된다. SMTP는 애플리케이션 계층의 프로토콜로, TCP와 같은 신뢰적 전송 서비스를 이용한다.
-
3.1 SMTP
SMTP는 HTTP보다 훨신 전에 나온 프로토콜로, 낡은 특성들을 가진 오래된 기술이다. 그 특징들 중 하나가 헤더가 7bit 아스키 코드로 구성이 되어야한다는 점이다. 그래서 멀티 미디어를 전송하는 오늘 날의 환경과 맞추기 위한 과정이 필요하다.
SMTP에서 메일 전송 절차는 다음과 같다.
- 메세지를 작성하고, 에이전트를 통해 메일을 전송함
- 에이전트는 메일을 전송측의 메일 서버로 보내고, 메일 서버는 이것을 메시지 큐에 놓는다.
- 메일 서버는 수신 측과 TCP 연결을 시도한다.
- 수신측에서 메시지를 수신한 뒤에 해당 메시지를 수신측의 메일박스에 놓는다.
- 만약에 연결이 수립되지 못하면, 메시지 큐에 전송이 완료될 때까지 일정주기로 반복한다.
이 과정에서는 메세지를 주고 받으면서 메일을 전송하는데, HELO, MAIL FROM ,RCPT TO, DATA, CRLF.CRLF, QUIT으로 구성 되어 있다. 이에 대한 자세한 설명은 여기에서 확인할 수 있다.
-
3.2 HTTP와의 비교
HTTP는 웹 서버에서 브라우저로 객체를 전달한다. SMTP는 한 메일서버로부터 다른 메일 서버로 메일을 전송한다. 둘다 지속 연결을 사용하는데, 그렇기 때문에 두 프로토콜은 닮은 데가 있다. 그러나 큰 차이가 있는데, HTTP는 pull 프로토콜 로 서버에서 정보를 가지고 오는 서비스다. 반대로 SMTP는 push 프로토콜 로 사용자가 수신 메일 서버측으로 메일을 보낸다.
앞서 언급 했듯이, SMTP는 매우 오래된 프로토콜이기 때문에 ascii 코드로 인코딩 할 것을 요구한다. 그래서 SMTP는 모든 메시지를 ascii 코드로 인코딩하여 전송을 하며, 또, HTTP에서는 객체를 하나하나 캡슐화 하여서 보내지만, SMTP는 모두 묶어서 1개의 메시지로 보낸다.
-
3.3 메일 접속 프로토콜
앞서 설명했듯이, 각 개인은 메일 서버를 가지고 있고, 이를 통해서 메일을 관리하고, 받는다. 이런 방식은 90년대 초까지는 일반적이었다. 하지만 여기에 큰 문제가 있는데, 메일을 수신하기 위해 컴퓨터를 항시 켜놓아야 한다는 것이다. 이 점은 일반적인 인터넷 사용자에게는 비현실적이다.
그래서 이런 일을 대신해줄 공유 메일 서버를 이용하는 쪽으로 변했다. 그렇지만 SMTP에서는 푸쉬 동작을 다루고 있지만, 자원을 요청하는 풀 동작에 대해서는 다루고 있지 않다. 이에 대해서 다루는 것이 POP3, IMAP과 같은 프로토콜이다. 먼저, POP3에 대해서 다루어 보겠다.
POP3는 3단계의 과정으로 진행된다. 인증, 트랜잭션, 갱신이다. 인증 단계에서 사용자의 이름과 비밀번호를 입력한다. 트랜잭션에서 메시지를 가져오거나, 삭제를 할 수가 있다. 마지막으로 갱신 단계에서는 세션을 끝내느 quit 명령을 내린후에 일어난다. 이때 서버에서 삭제 표시된 메시지를 삭제한다.
IMAP은 POP3와는 다르게, 폴더에 메시지를 연결한다. 그래서 사용자가 폴더를 생성하거나, 다른 곳으로 옮기거나 하는 명령도 제공한다. 그래서 사용자의 상태 정보도 유지한다.
그렇지만 앞서 이야기 한 것들은 좀 옛날 이야기가 되었고, 오늘날은 HTTP를 통해 메일을 주고받는 일이 대부분이다. 그래서 브라우저가 에이전트가 되며, HTTP를 타고 브라우저를 통해서 전달이 된다. 다만 메일 서버는 여전히 SMTP를 통해 메일을 주고 받는다.
