분산 데이터베이스 환경에서 AbstractRoutingDataSource 사용하여 데이터소스 관리하기
이번 데이터베이스 샤딩을 하는 미션을 수행하기 위해서 많은 구글링을 통해 관리하는 방법들을 모색하기 시작했습니다.
그 중에서 AbstractRoutingDataSource 이용하여, 사용할 DataSource를 라우팅 테이블과 같이 Map 형태로 저장을 해놓고,
들어오는 데이터의 Key값에 따라 적절한 DataSource를 연결해주는 방법을 선택하게 되었습니다.
AbstractRoutingDataSource 란?
위의 방법을 찾는데 가장 먼저 발견한 키워드는 "AbstractRoutingDataSource" 였습니다. 그런데 과연 이 AbstractRoutingDataSource 는 무엇이고, 어떤 역할을 하게 되는 것인가
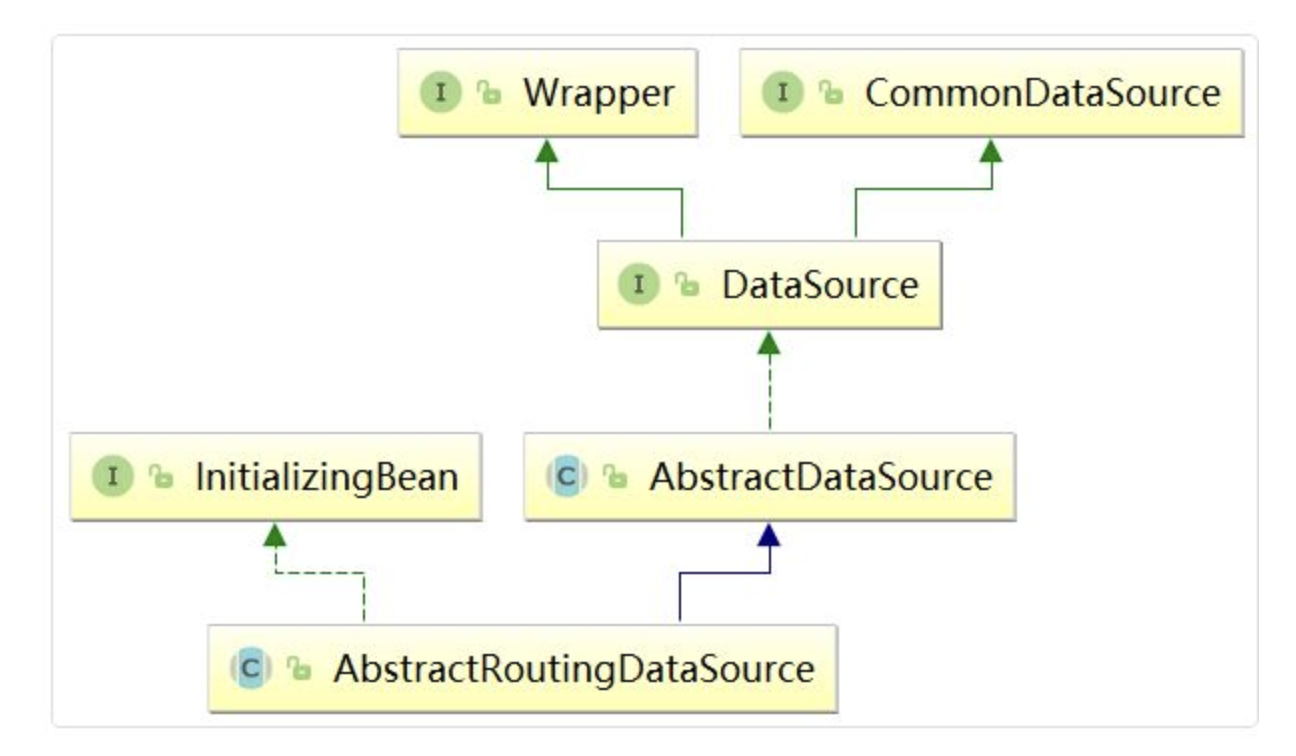
AbstractRoutingDataSource는 아래 그림에서 확인할 수 있듯이 InitializingBean을 구체화하고 DataSource를 구체화한 AbstractDataSource를 상속하고 있습니다.
InitializingBean은 빈 객체의 라이프 사이클과 관련된 인터페이스로 bean 객체를 생성하고 프로퍼티를 초기화하고, 설정을 완료한 후 호출되는 메서드를 정의하고 있습니다.
참조 : http://www.manongjc.com/article/13402.html
DataSource란?
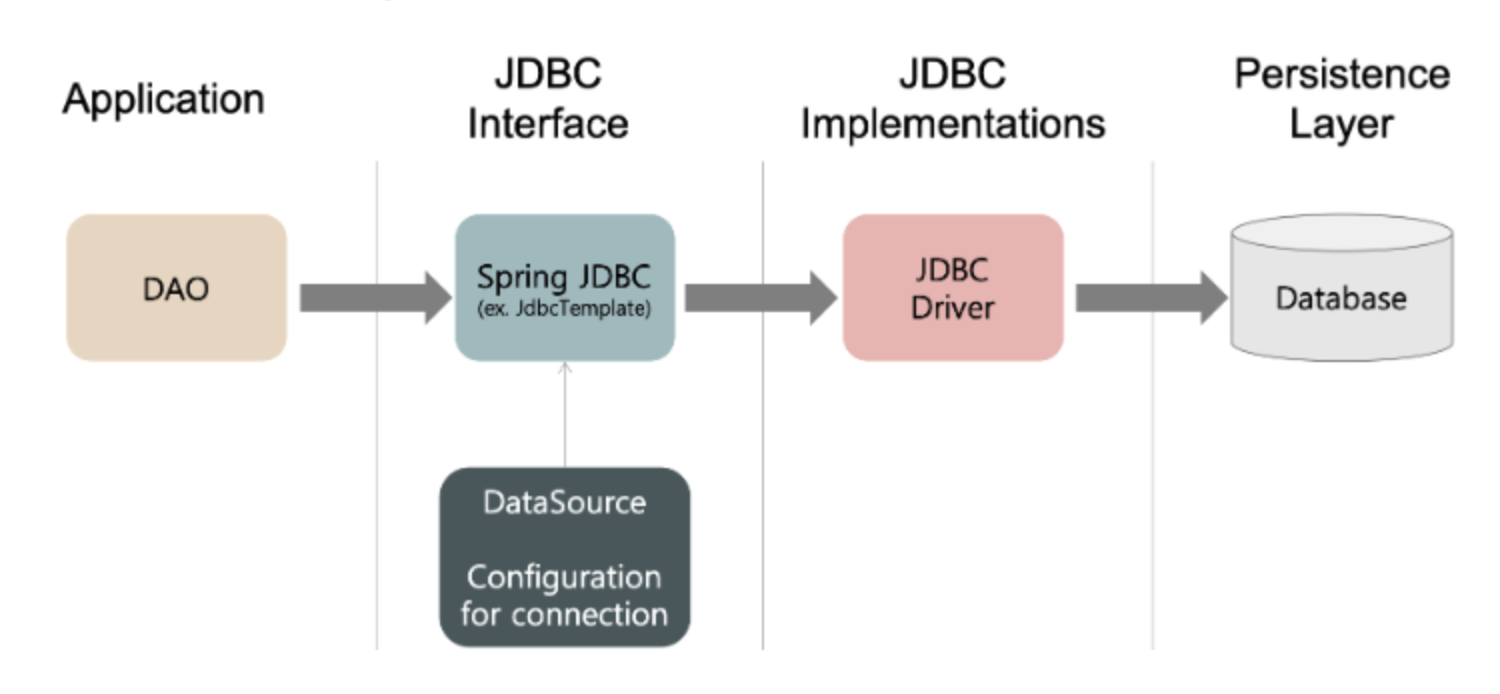
AbstractDataSource는 DataSource 인터페이스를 구체화한 것으로, JDBC 명세의 일부분이면서 일반화된 연결 팩토리입니다.
즉 DB와 관계된 connection 정보를 담고 있으며, Bean으로 등록되어 필요한 정보를 넘겨주게 됩니다. 이 과정을 이용하여 Spring Application은 DataSource로 DB와의 연결을 획득하게 되는 것입니다.
참조: https://gmlwjd9405.github.io/2018/05/15/setting-for-db-programming.html
DataSource는 아래 코드와 같이 DatasourceBuilder를 이용해서 간단하게 생성할 수 있습니다.
public DataSource datasource() {
return DataSourceBuilder
.create()
.url(dateSourceURL)
.username(userName)
.password(password)
.build();
}AbstractRoutingDataSource 구체적 사용법
AbstractRoutingDataSource는 Target이 되는 DataSource를 Map<key(Object), datasource(DataSource)> 형태로 가질 수 있고, 원하는 key를 넣게 된다면 key에 맞는 Datasource가 할당되는 형태의 class 입니다.
조금 더 구체적으로 살펴보자면 AbstractRoutingDataSource를 상속받은 class는 determineCurrentLookupKey라는 메소드를 Override하여 어떤 key를 리턴하게하면, 자신이 가지고 있는 TargetDataSource Map에서 지정된 key에 맞는 DataSource 객체를 resolveSpecifiedDataSource 메소드를 통해 결정하게 됩니다.
실제 코드
구현상으로 보자면, 먼저 AbstractRoutingDataSource를 상속받는 class를 생성하고, determineCurrentLookupKey 함수를 정의합니다.
public class CustomDataSourceRouter extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return CustomDataSourceContextHolder.getDatabase();
}
}이 후 Configuration을 이용하여, 원하는 Datasource를 생성하여 RoutingDataSource에 targetDataSource Map을 넣어줍니다.
@Configuration
public class DataSourceRoutingConfiguration {
@Bean
public DataSource datasource() {
Map<Object, Object> targetDataSources = new HashMap<>();
DataSource aDatasource = ADatasource();
DataSource bDatasource = BDatasource();
//DataSourceKey 는 구분을 위한 Key로 Enum 값입니다.
targetDataSources.put(DataSourceKey.A, aDatasource);
targetDataSources.put(DataSourceKey.B, bDatasource);
CustomDataSourceRouter routingDatasource = new CustomDataSourceRouter();
routingDatasource.setTargetDataSources(targetDataSources);
routingDatasource.setDefaultTargetDataSource(aDatasource);
return routingDatasource;
}여기서 특이한 점은 ContextHolder라는 class를 구현하여 ThreadLocal를 이용하여, Context를 저장한다는 것입니다.
ThreadLocal를 이용하여 Data Access가 여러 DataSource와 transaction을 이용하더라도 신뢰성을 보장할 수 있도록, Thread-safe하게 해주는 것입니다.
ThreadLocal이란?
Thread는 알겠는데, ThreadLocal은 무엇이고, 뭐가 다를까
ThreadLocal을 Thread-Local 변수를 제공한다. Thread-local Thread 영역에 변수를 설정하는 것으로,
각 Thread 마다 독립적으로 초기화된 복사본을 가지고 있다는 점이 특징입니다.
이러한 특징 때문에 한 쓰레드에서 실행되는 코드가 동일한 객체를 사용할 수 있도록 해 주기 때문에
쓰레드와 관련된 코드에서 파라미터를 사용하지 않고 객체를 전파하기 위한 용도로 주로 사용됩니다.
구현 방법도 굉장히 간단하다.
- ThreadLocal 객체를 생성
- ThreadLocal.set() 현재 Thread-Local 변수에 값 저장
- ThreadLocal.get() 현재 Thread-Local 변수 값 조회
- ThreadLocal.remove() 현재 Thread-Local 변수 값 삭제
public class CustomDataSourceContextHolder {
private static ThreadLocal<DataSourceKey> CONTEXT = new ThreadLocal<>();
public static void set(DataSourceKey databaseKey) {
CONTEXT.set(databaseKey);
}
public static DataSourceKey getDatabase() {
return CONTEXT.get();
}
public static void clear() {
CONTEXT.remove();
}
}DataSourceKey를 Enum 객체를 생성하여 관리하도록 구현했습니다.
Routing Key 설정
위와 같이 설정하게 된다면, 이제 언제 Context의 값을 설정해주고, 무엇을 가지고 설정해줄 것인가에 대한 고민만 남았습니다.
저는 Key를 설정하는 책임이 Mapper에 있는 것이 좋다고 생각되었습니다.
결국 어떤 DB에 접근하여 SQL문을 실행시킬까에 대한 내용은 Mapper와 밀접하게 연관되어있고
그 결정이 Mapper에서 이루어진다면, 어떤 Service에 의존하지않는 독립적인 Mapper를 작성할 수 있을 것 같았기 때문입니다.
그렇다면 Mapper에서 SQL문을 실행시킬 때 Routing Key를 설정하자
위와 같이 결심했다면 Aspect를 이용해야한다는 것을 알 수 있었습니다. 물론 각 Mapper에 모든 로직 코드를 삽입하여 해결할 수도 있겠지만, AOP(Aspect Oriented Programming)을 이용한다면 코드의 반복을 줄이고, 효율적으로 관리할 수 있습니다.
AOP 관련 참고 : https://velog.io/@sincewhen/Spring-AOP
AOP를 이용하여 Routing Key 설정하기
위의 AOP 개념을 이용하여 Mapper에 정의된 모든 Method가 실행될 때, Routing Key를 설정하고자 하였습니다.
각 Mapper에 Routing Key로 사용할 변수를 찾기 위해 @RoutingKey라는 Annotation을 정의하여 아래와 같이 지정하였습니다.
@Mapper
@RoutingMapper
public interface TestMapper {
Contents selectContents(@RoutingKey @Param("contentsId")String contentsId);
int insertContents(@RoutingKey @Param("contentsId")String contentsId, @Param("mail")Mail mail);
}그 후 Aspect를 생성하여, Around Advice와 execution을 이용하여 Mapper의 어떠한 함수가 실행될 때 수행할 코드를 작성했습니다.
@RoutingKey로 설정된 Parameter를 찾고 해당 Parameter를 해싱하여 나온 값을 이용해 Context에 등록을 하게된다면, 해당 Key에 맞는
DataSource를 AbstractRoutingDataSource가 결정해줄 것이고, 해당 Datasource에 Mapper가 해당 SQL을 수행할 것 입니다.
여기서 해싱을 하는 이유는 contentsId의 값을 특정 개수의 Key 값으로 나눠야하기 때문입니다.
@Around("execution(* com.test.mapper..*(..))")
public Object aroundTargetMethod(ProceedingJoinPoint thisJoinPoint) {
MethodSignature methodSignature = (MethodSignature) thisJoinPoint.getSignature();
Class<?> mapperInterface = methodSignature.getDeclaringType();
Method method = methodSignature.getMethod();
Parameter[] parameters = method.getParameters();
Object[] args = thisJoinPoint.getArgs();
RoutingMapper routingMapper = mapperInterface.getDeclaredAnnotation(RoutingMapper.class)
if (routingMapper != null) {
//parameter, args 에서 RoutingKey 어노테이션 찾기
String Id = findRoutingKey(parameters, args);
//얻은 Key를 hash하여 DB 선택할 인덱스 생성
Integer index = determineRoutingDataSourceIndex(Id);
CustomDataSourceContextHolder.set(getDataSoruce(index));
}
CustomDataSourceContextHolder.clear();
}참고자료
https://d2.naver.com/helloworld/5812258
https://www.baeldung.com/spring-abstract-routing-data-source
http://closer27.github.io/backend/2017/08/03/spring-aop/
