
1. 일원분산분석의 확장
요인의 수에 있어서의 확장
- ① 이원분산분석 (two-way ANOVA)
: 집단의 수가 3개 이상이고, 그 집단을 나누는 요인이 2개일 때 사용
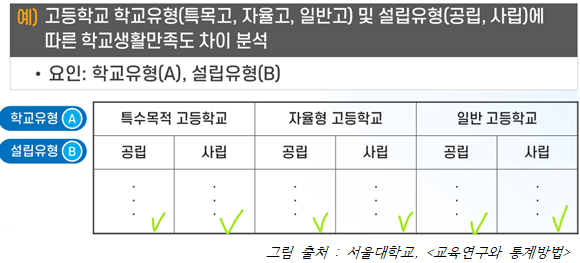
- ② 삼원분산분석 (three-way ANOVA)
: 집단의 수가 3개 이상이고, 그 집단을 나누는 요인이 3개일 때 사용
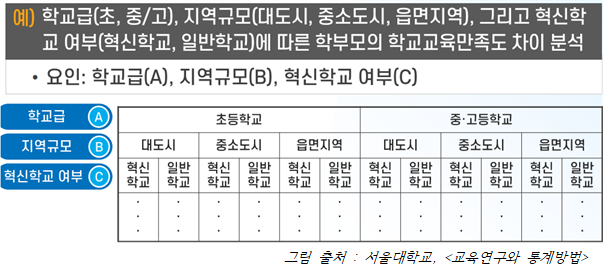
Q1. 이원분산분석, 삼원분산분석처럼 요인의 수가 늘어난 경우는 (독립변수/종속변수)의 개수가 늘어난 것과 같은 의미로 볼 수 있다.
기본가정 위배에 따른 확장
- ③ 반복측정 분산분석
: 독립성 가정 위배 시 사용. (주로 동일 피험자를 반복 측정한 경우)
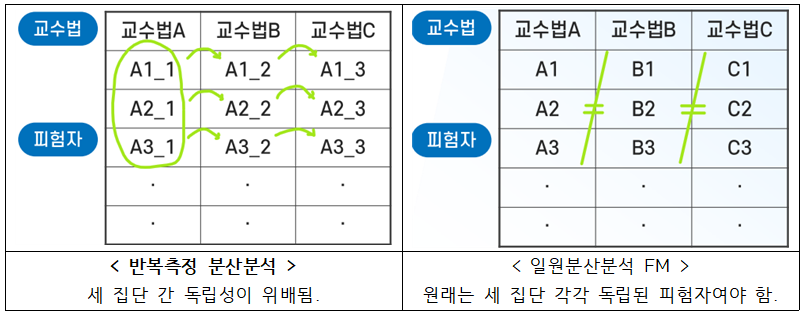
※ 독립성 위배했는데 그냥 일원분산분석 써버린다면 ?
: 측정 대상의 집단 내 분산이 상대적으로 커짐 (집단 간 분산이 작아지니까)
→ F값이 지나치게 작아짐 → p값은 그만큼 커짐 → 1종의 오류가 커짐 ㅠ..
Q2. 반복측정 분산분석의 장점과 단점을 각각 2개씩 말하시오.
분석 내 변수 특성에 따른 확장
- ④ 공분산 분석(ANCOVA)
: 집단 간 평균 차이를 살펴봄에 있어서 '통제변수'를 고려해야할 때 사용.
= 집단간 무선할당이 불완전하게 이루어진 경우 (ex. 교수법 효과를 분석하려고 A반을 실험집단, B반을 통제집단으로 구성했는데, 애초에 A반이 성적 더 좋았었다거나 ...)
➡️ 집단 간 차이를 초래하는 통제변수를 '공변인'으로 잡고, 이 공변인이 같은 수준으로 종속변수의 평균을 조정하여 분석! ("일단 요정도만 알고 넘어갑시다,,")

- ⑤ 다변량 분산분석(MANOVA)
: 관심을 둔 종속변수가 여러 개인 경우에 사용. (주로 종속변수끼리 상관 있는 경우)
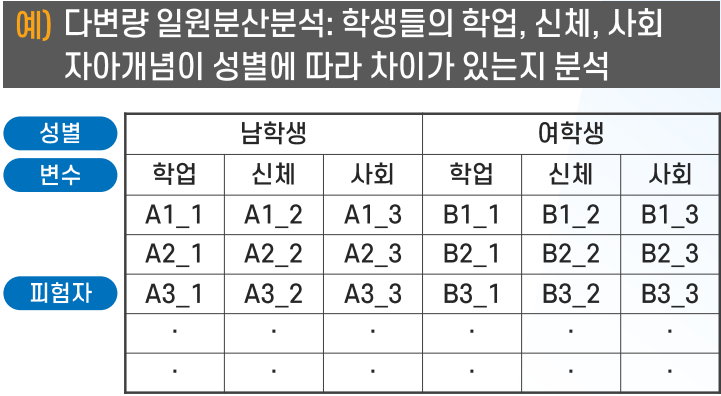
Q3. 다변량 분산분석(⑤)이 ③, ④와 다른 점을 각각 말하시오.
2. 이원분산분석의 개념
요인의 수개 2개일 때는 일원분산분석 말고 이원분산분석을 사용한다.
- 이원분산분석을 적용하는 이유 2가지
: 일원분산분석을 2번 하면 1종의 오류가 커지기 때문 (t검증 반복 안 했듯이)
: 이원분산분석을 하면 상호작용효과까지 검증할 수 있기 때문⭐
주효과와 상호작용효과
- 주변평균
: 두 요인 중 한 요인이랑만 관계 있는 평균 (교차표 그렸을 때 행평균 & 열평균)
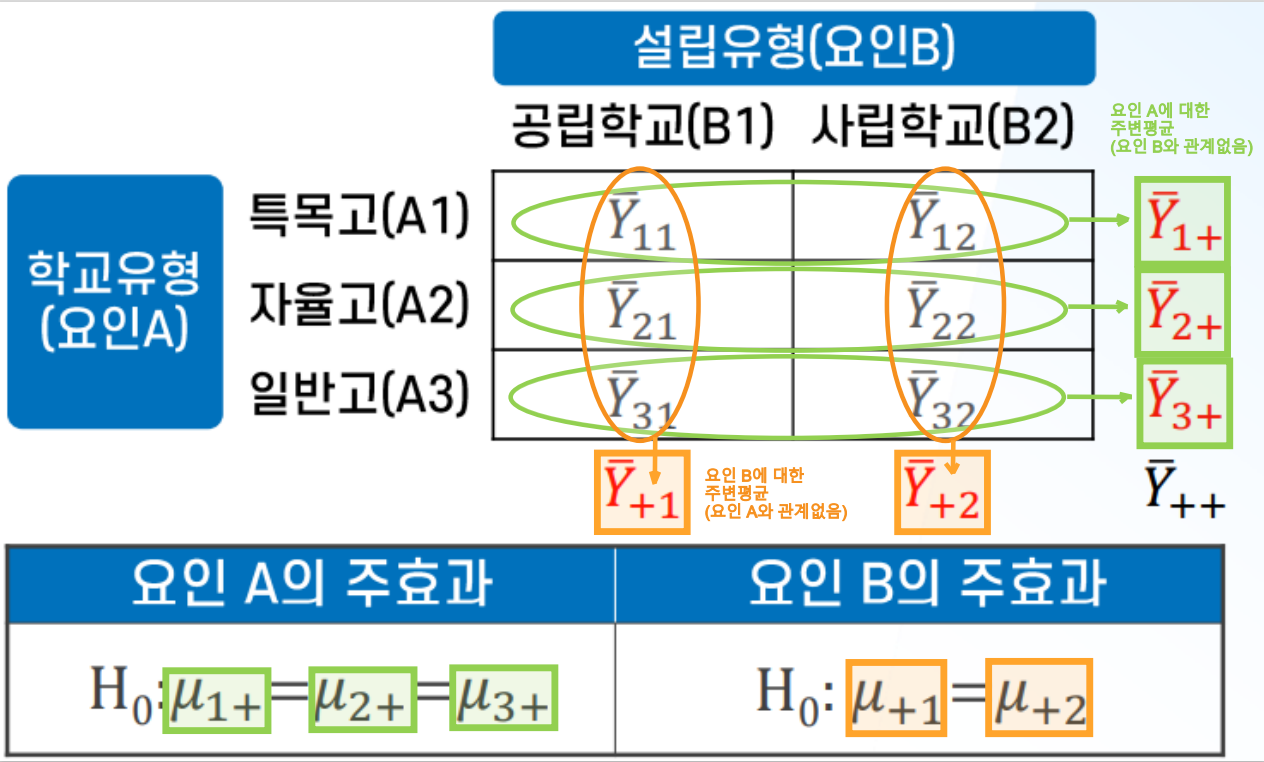
-
주효과
: 요인별로 분리된 각각의 효과 (사실상 전에 배웠던 개별 검증과 동일)
➡️ 요인A 주변평균에 대한 ANOVA , 요인B 주변평균에 대한 t검증으로 (각각) 확인 가능 -
상호작용효과
: "요인A의 효과가 요인B의 각 레벨에서 다르게 나타나는가?"
➡️ 각 행or열의 셀 평균 간 차이가 다르게 나타나면 상호작용효과가 있는 것!
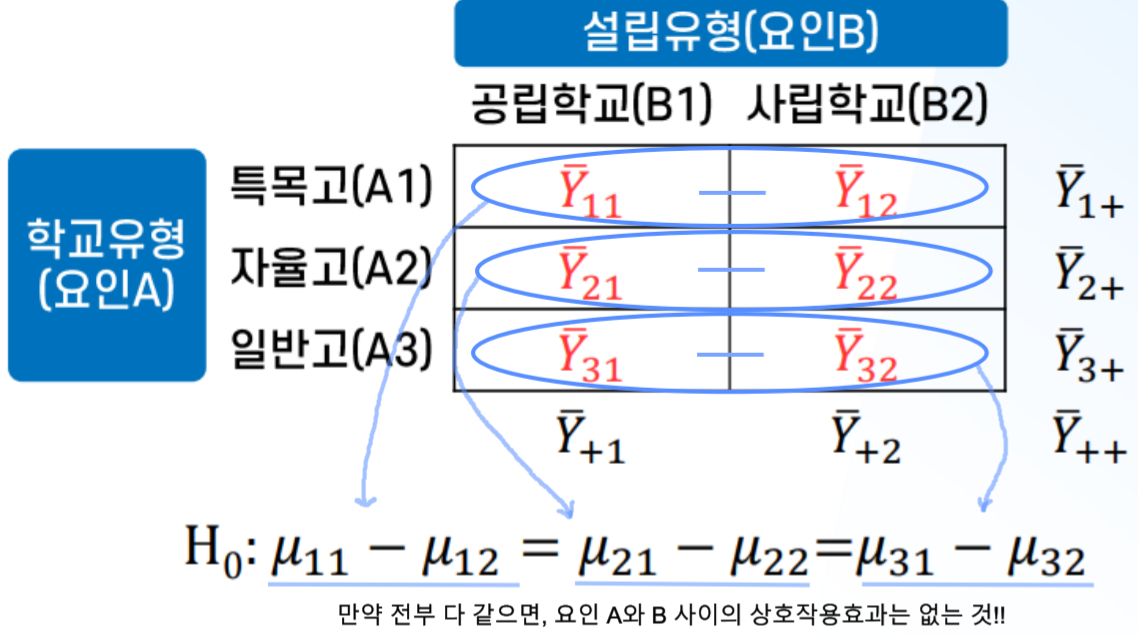
-
평균도표
: 상호작용효과의 해석을 시각적으로 보여주는 그래프
(표 구성 || y축: 종속변수 / x축: 집단 수 더 많은 요인 / 선: 집단 수 더 적은 요인)- 상호작용효과 X · · · · · 평행한 직선으로 나타남
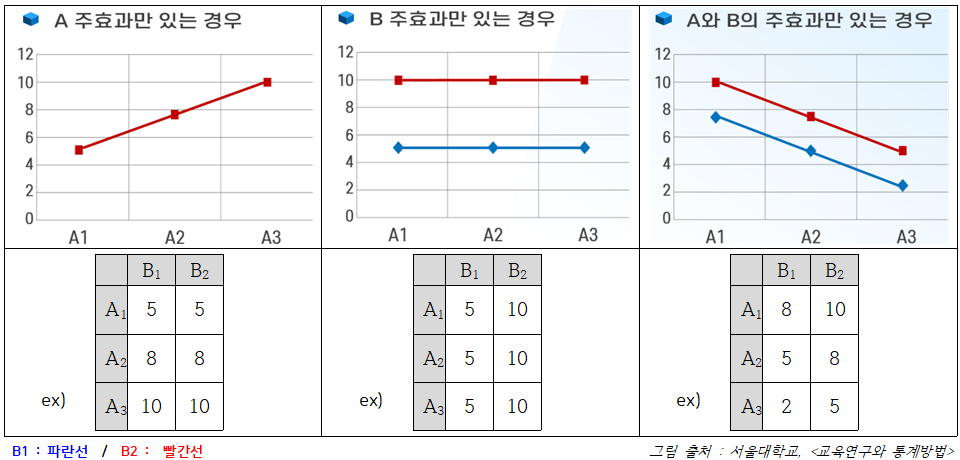
- 상호작용효과 O · · · · · 직선들이 평행하지 않고 교차지점 생김
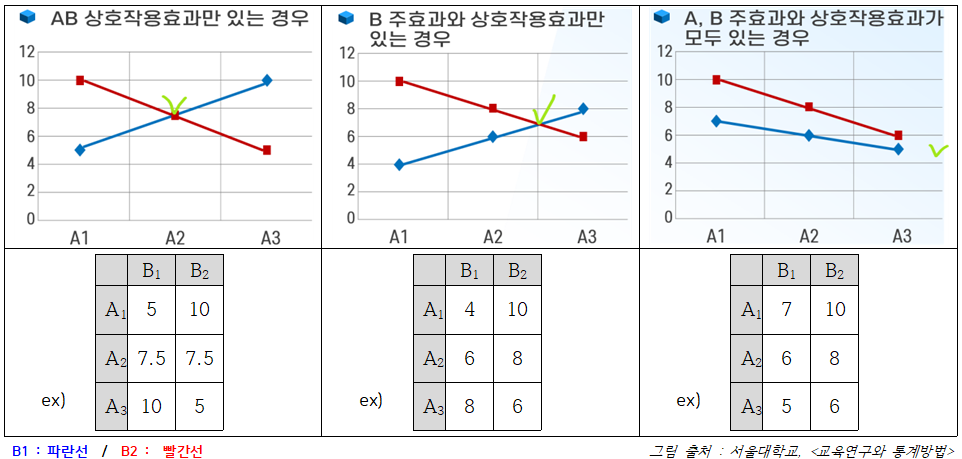
- 상호작용효과 X · · · · · 평행한 직선으로 나타남
수리적 논리 및 검증 절차
- 이론적 논리
: 일원분산분석과 마찬가지로 제곱합의 분할 & 자유도의 분할
→ ‘집단 간 분산’ (A, B, AxB)과 ‘집단 내 분산’으로 분리
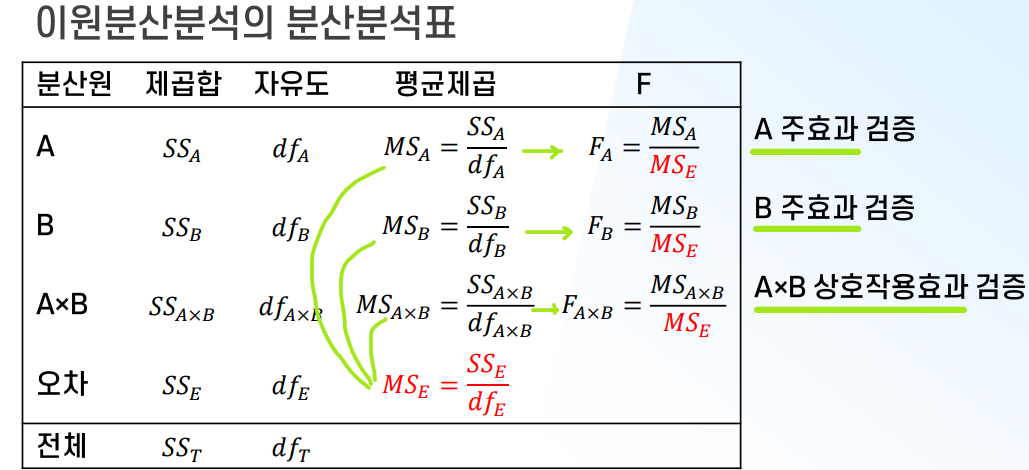
- 가설 검증 절차
① 영가설 설정
② 기술통계 분석 (with Graph)
③ 기본 가정(독,정,등) 확인
④ 주효과 2개와 상호작용효과 1개에 대한 F분포 상정
⑤ 표본평균을 F값으로 변환 & 분포상 위치 확인
⑥ 유의확률(p값)과 유의수준(α)을 비교하여, 영가설 기각여부 결정!!
⑦ 🆕상호작용효과 유의하면, 평균도표 제시&해석!
⑦ 🆕주효과 유의하면, 필요에 따라 사후비교 실시!
기본 가정 3가지
일원분산분석과 동일한데, 분석 단위가 모든 '셀'이라는 차이가 있음!
- 독립성
- 위배 시, 반복측정 이원분산분석 적용
- 정규성
- 히스토그램, 박스플롯, QQ플롯으로 확인
- 위배 시, 종속변수 재코딩하여 정규성 확보 노력
- 등분산성
- Levene test ( )
- 위배 시, Brown-Forsythe F 사용 (
Welch F없음)
+ 당연히 주효과 사후비교 시에 Tukey나 Bonferroni도 못 씀 ㅇㅇ
3. 이원분산분석의 실제
- [사례1] 요인A : 부모와의 관계 / 요인B : 학생 성별 / 종속변수 : 학업성취도
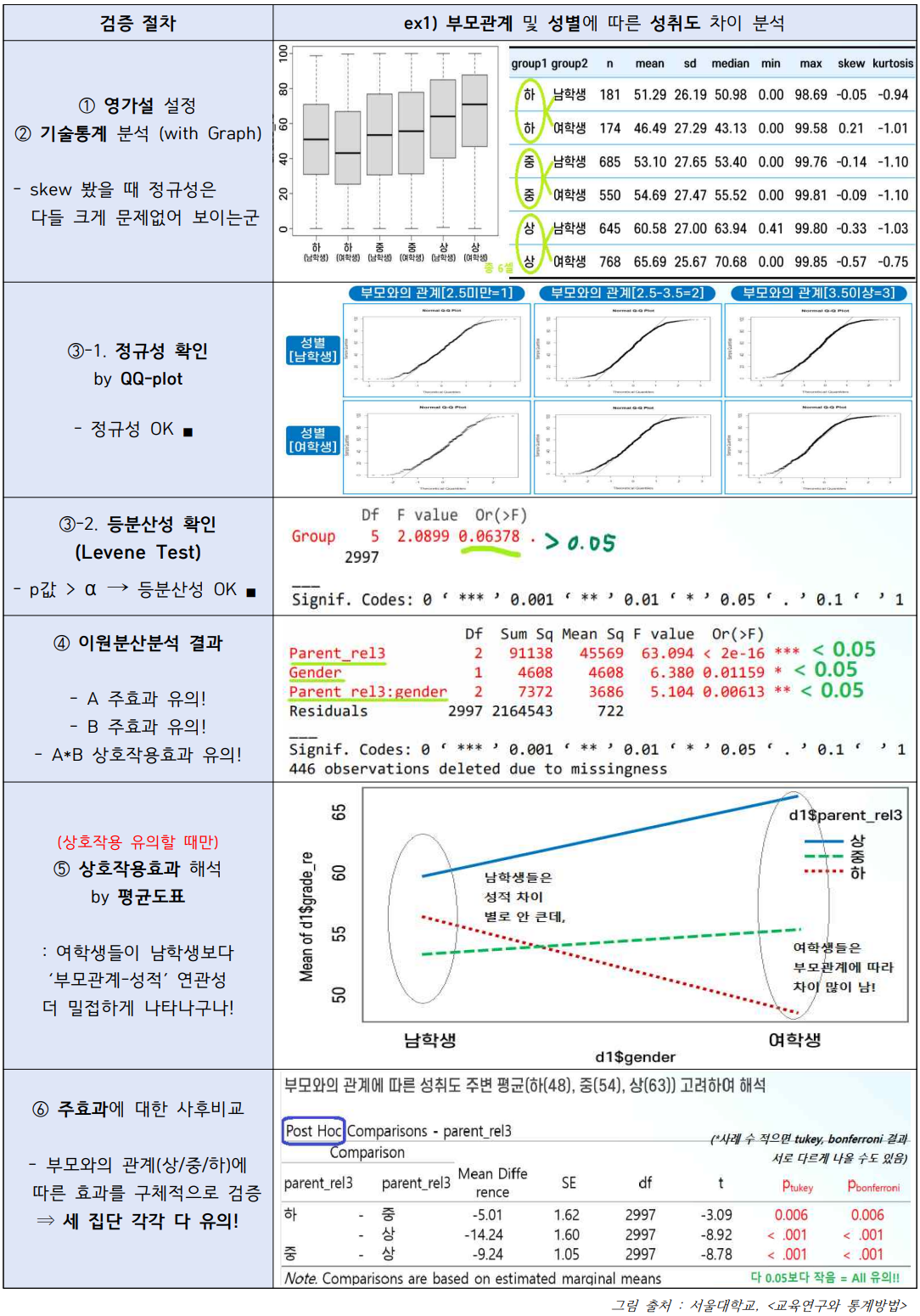
Q4. [사례1] ⑥에서 '성별' 변수에 대해서는 왜 사후비교를 실시하지 않았을까?
💯퀴즈 정답💯
A1.
독립변수
A2.
- 장점
1) 더 적은 사례 수로도 분석할 수 있다. (피험자 한 집단만 있으면 되니까)
2) 처치조건 외에 다른 특성이 알아서 통제되니까 처치효과 해석이 더 쉽다. - 단점
1) 피험자 섭외가 더 어려울 수 있다. (여러 번 실험받기 부담스러울 수 있으니)
2) 순서효과를 고려해야 해서 연구설계가 더 복잡해질 수 있다. (ex. 교수법 A-B-C 순서로 할 때랑 C-B-A 순서로 할 때랑 결과가 다를 수도 있음...)
A3.
다변량 분산분석은 반복측정 분산분석, 공분산 분석과 아예 다른 상황에 쓴다.
- 반복측정 분산분석은 반복해서 여러 시점에 수집한 데이터인 반면, 다변량 분산분석은 단일 시점에 수집한 여러 종속변수의 데이터이다.
- 공분산 분석은 특정 변수를 통제하고 관심변수에 집중하는 반면, 다변량 분산분석은 여러 변수들 중 어떤 것도 통제되지 않고 전부 연구자의 관심대상이다.
A4.
성별은 어차피 집단 2개(남/녀)니까 사후비교를 할 필요가 없다.
ⓒ 2023. SeongJunhyeok All rights reserved.

생각은 그만