
1. 정규분포의 특성
- 정규분포를 이루는 모수 2가지
: 평균과 표준편차만 알면 정확한 분포를 그릴 수 있고, 개별 값의 위치파악이 가능함.
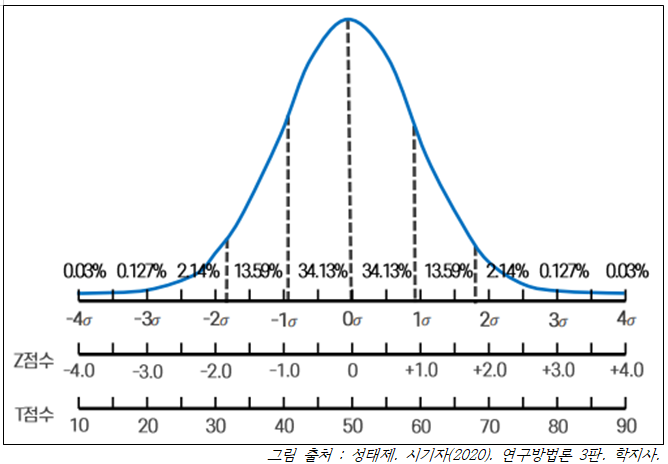
- 표준정규분포
: 평균이 0이고 표준편차가 1인 Z분포 → =
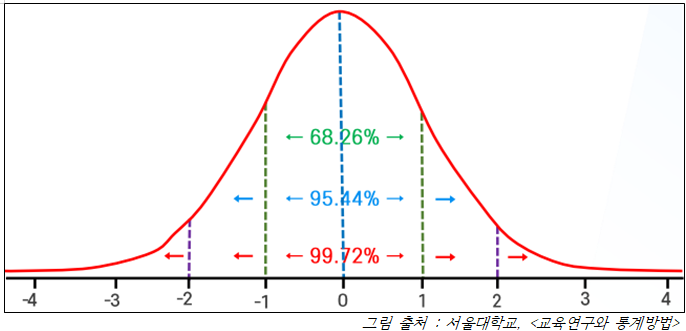
Q1. 자주 사용되는 Z 점수로는 95%일 때 -.--과 99%일 때 -.---가 있다.
2. 표집분포와 가설검증
-
모집단 분포
: 전체 집단의 분포. 일반적으로 정규분포를 가정함. → ~ -
표본 분포
: 모집단에서 추출한 표본의 분포. 표본 크기 작으면 편포일 수 있음. -
표집 분포
: (반복 추출한) 표본에서 구한 통계치들이 이루는 분포.
ex. 표본평균의 분포, 표본분산의 분포🆚 표본분포 : 샘플 한 개 뽑아서 그린 분포
🆚 표집분포 : 여러 샘플 뽑아서, 각 샘플의 평균에 대한 분포를 그린 것 -
평균의 표집 분포
: 무한번 반복추출해서 구한 표본평균들의 분포로, N(표본크기) >30 이면 정규분포 가정.
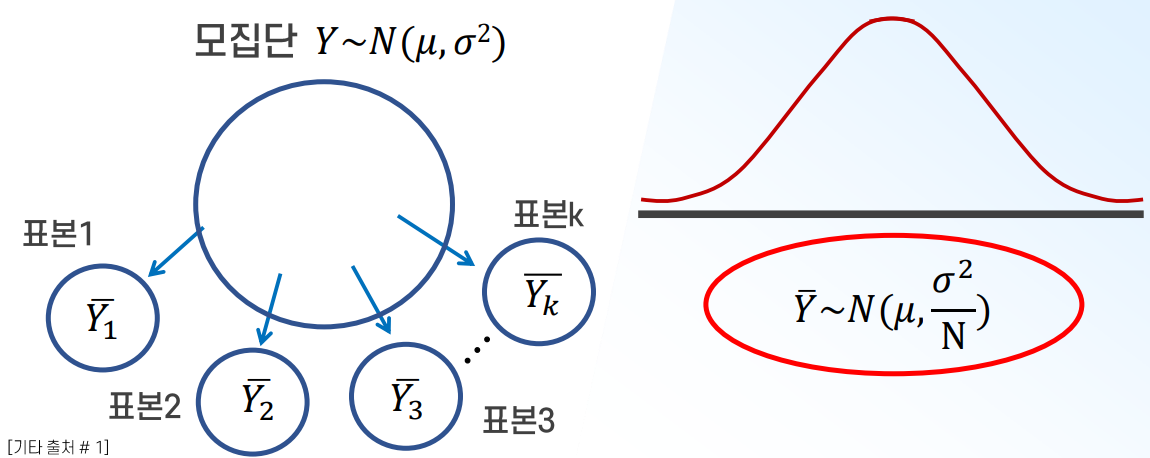
- 표본평균의 평균 : · · · · · · · · · (모집단의 평균과 동일함)
- 표본평균의 표준편차 : · · · · · · · (표준오차 SE 라고 부름)
Q2. 표본의 크기(n)가 --보다 크면 ----를 따른다는 조건은 생각보다 중요하다.
- ⭐통계적 가설검증 과정
: 모집단 특성에 대한 가설 설정 » 표본 추출 » 표집분포로 오차범위 확인 » 가설 판단
ex) '모집단의 평균은 164.12 일 것이다' 라는 가설 검증을 위해 100개의 표본을 추출함
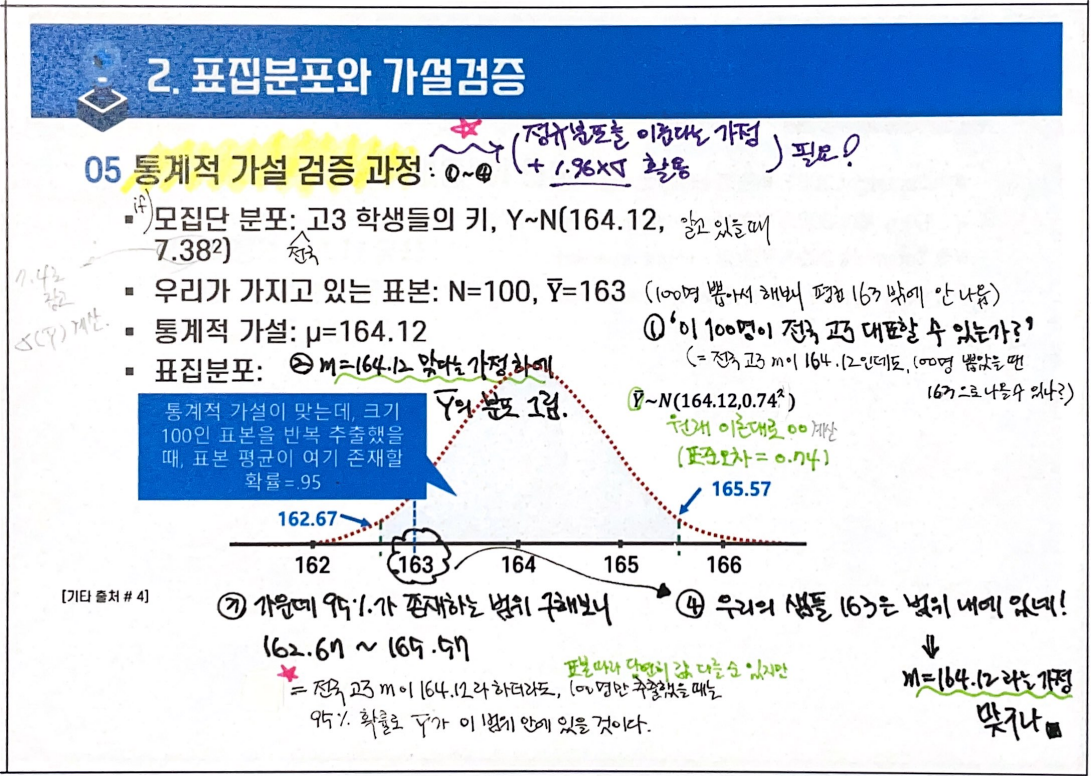
3. 통계적 가설검증의 기본 개념
-
귀무가설
: 직접적인 검증의 대상. "효과가 없다" "차이가 없다"는 의미에서 영가설이라고도 부름. -
대립가설
: 실제 연구자의 관심 내용. 영가설을 기각해야 대안으로 받아들여질 수 있음. -
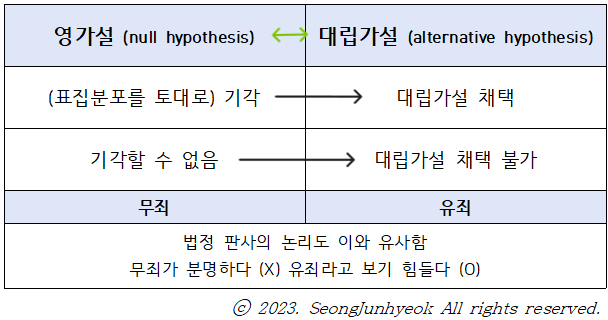
가설 검증의 기본 논리
: 기준은 영가설! 판사의 '무죄추정의 원칙'과 유사한 논리.
-
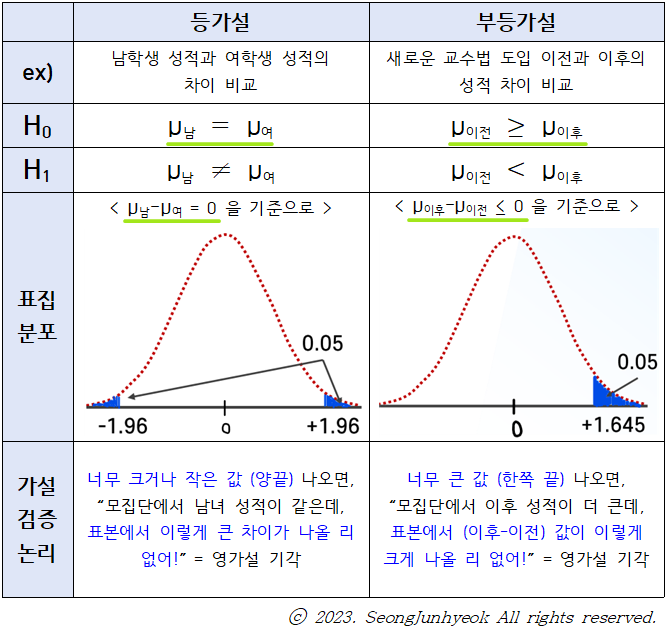
등가설과 부등가설
: 등가설은 ㅇㅊ검증, 부등가설은 ㄷㅊ검증
-
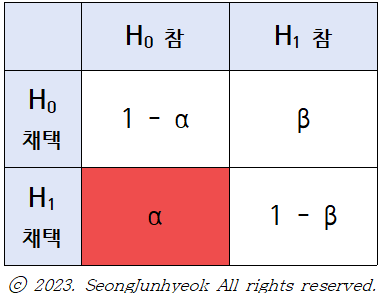
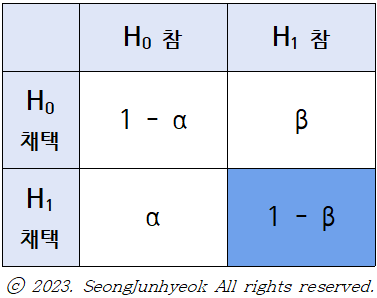
1종의 오류 (α)
: 영가설이 참인데, 영가설 기각하고 대립가설 채택하는 오류.
-
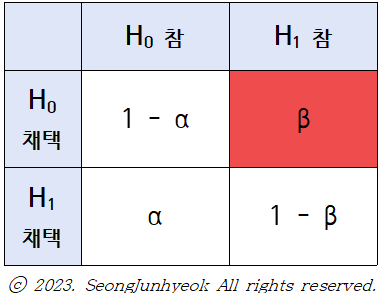
2종의 오류 (β)
: 대립가설이 참인데, 영가설을 그대로 채택하는 오류.
-
통계적 검증력 (1-β)
: 대립가설이 참일 때, 영가설 기각하고 대립가설 채택할 확률! (당연히 높을수록 good)
-
⭐유의수준
: "1종의 오류(=더 심각한 오류)를 범할 확률"을 어디까지 수용할 것인가?
↪ 주로 0.05 , 0.01 , 0.001을 많이 사용함 -
⭐유의확률
: 영가설 표집분포에서 얻은 값보다 더 극단적인 값이 나올 확률.
➡️ 유의수준과 비교하여 영가설 기각 판단의 기준이 됨! (... in next chapter) -
연구자의 딜레마
: 적절한 유의수준(α)과 표본 크기를 설정하기가 쉽지 않음.
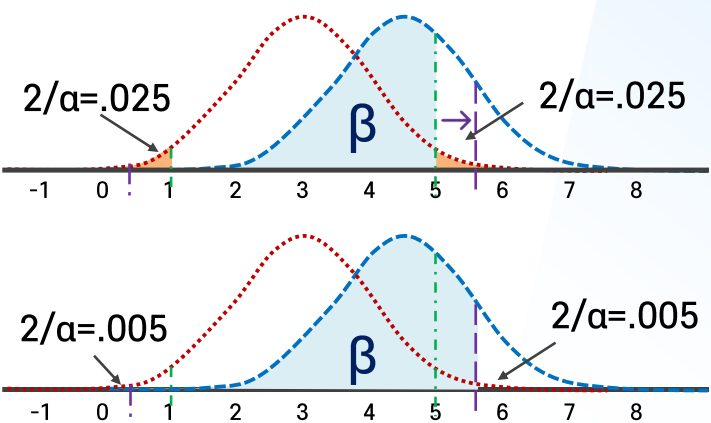
Q3. 1종의 오류 ↓ = 2종의 오류 (↑/↓) = 통계적 검증력 (↑/↓)
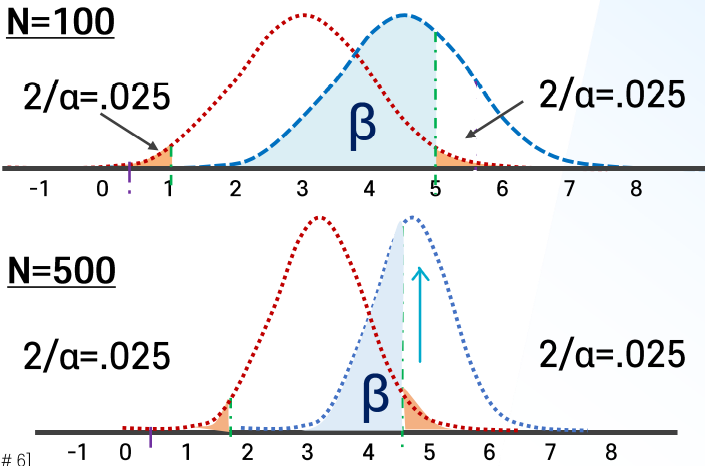
Q4. 만약 1종의 오류를 고정 시, 표본의 크기 ↑ = 2종의 오류 (↑/↓) = 통계적 검증력 (↑/↓)
but, 표본 너무 키워도 안 됨...
💯퀴즈 정답💯
A1. 1.96 / 2.575
A2. 30 / 정규분포
A3. ↑ , ↓
A4. ↓ , ↑
ⓒ 2023. SeongJunhyeok All rights reserved.
