Preprocessing
- 데이터 정제 : 결측치, 이상치, 입력오류 등을 수정
- 데이터 통합 : 데이터를일관된 형태로 정리
- 데이터 변환 : 정규화(normalization), 일반화(generalization) 등
- 데이터 축소 : 중복되거나 불필요한 데이터 최소화. 차원축소 등
실습 데이터 :

기본 내장함수
sub()
- 처음 등장하는 특정 표현을 다른 표현으로 교체
code in R

result

gsub()
- 모든 특정 표현을 다른 표현으로 교체
- 바꾸려는 단어가 텍스트의 다른 부분에 더 없는지 확인 필수!
code in R

result

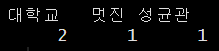
table(), strsplit()
strsplit(): split 기준으로 텍스트를 분할해줌table(): 요인별 도수를 출력해줌code in R

result ; 띄어쓰기 기준으로 빈도 수를 출력해줘
sum()과 함께 사용하면, 텍스트 내 단어 개수를 셀 수 있음code in R

result ; 문서 내 단어(띄어쓰기 기준) 개수를 출력해줘

gsub()에서under_bar로 두 단어를 합칠 수 있음 (단어 개수 변화 확인)code in R

result

정규표현식
gregexpr()
- 정규표현식을 활용해 텍스트를 다룰 수 있음
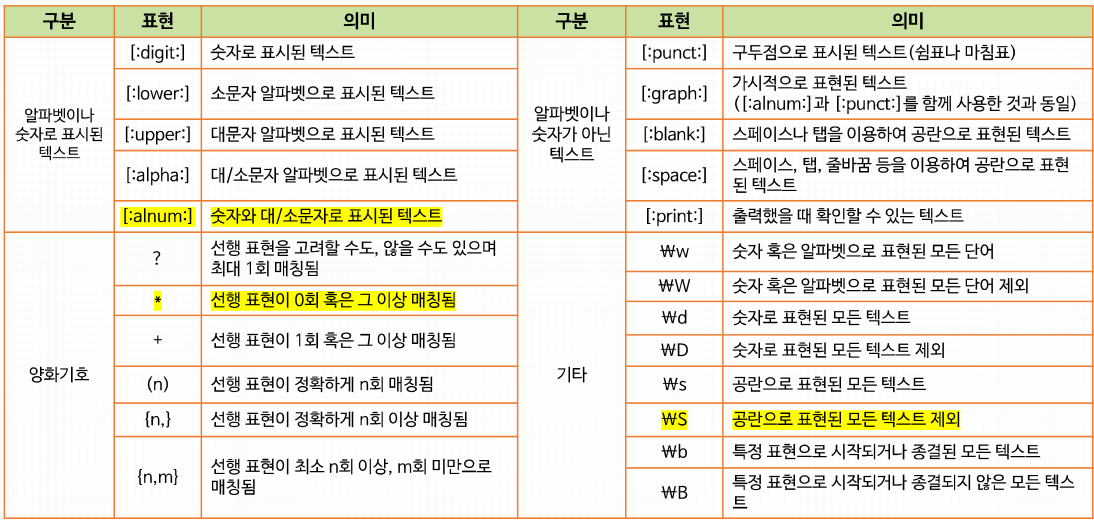
regmatches()
- 특정 패턴(직접 생성)을 지닌 텍스트를 추출해볼 수 있음
code in R

result ; '~~ _ ~~역량' 이라고 된 것만 출력해줘

stringr 패키지
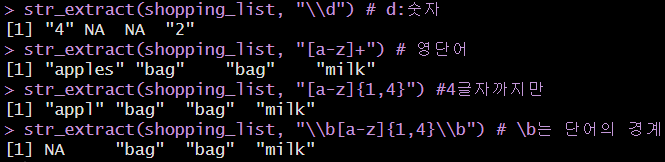
str_extract(), str_extract_all()
- 패턴에 맞는 문자를 추출함 (패턴은 문자열로 지정해줘야 함)
str_extract()는 하나만,str_extract_all()은 전부 출력함code in R

result
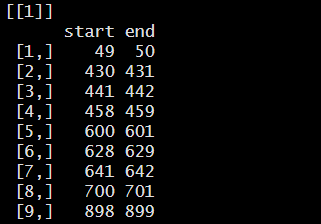
str_locate(), str_locate_all()
- 특정 표현의 위치정보를 알려줌
code in R

result ; '역량' 관련 단어가 9번 출현했음을 알 수 있네
str_replace(), str_replace_all()
- 특정 표현을 다른 표현으로 교체함 (
gsub()과 동일)code in R

result

str_split()
- 기준에 따라 문자열을 분할함
- 🚨온점(.)으로 구분 시,
\\.으로 표현해야 함!! (regex와 겹침 방지) - 한 리뷰가 너무 길어서 여러 리뷰처럼 인식시킬 때 사용 가능
code in R

result

str_count()
- 특정 표현의 출현 수를 카운트함
code in R

result ; '정보' 로 시작하는 단어 다 뽑아줘

내용 추가 예정...

생각은 그만