[혼공머신] 7-2. 심층 신경망
혼공머신

Intro.
지난 시간에는 인공신경망으로 럭키백의 성능을 높여봤음! But, 층이 하나뿐이었음.
홍 선배🗣️ "딥"러닝인 만큼, 층을 더 추가해서 성능을 더 높여보자 ~!
1. 데이터 준비
- 저번이랑 똑같이
.load_data()함수로 데이터 준비함.

- 똑같이 전처리 해줌.

2. 심층 신경망
은닉층 (Hidden layer)
은닉층: 입력층과 출력층 사이에 있는 모든 층 (몇 개든 상관 없음!)
ex) 이번에는 저번 시간보다 밀집층(=은닉층)을 하나 더 추가해봄. 모델의 구조는 대략...
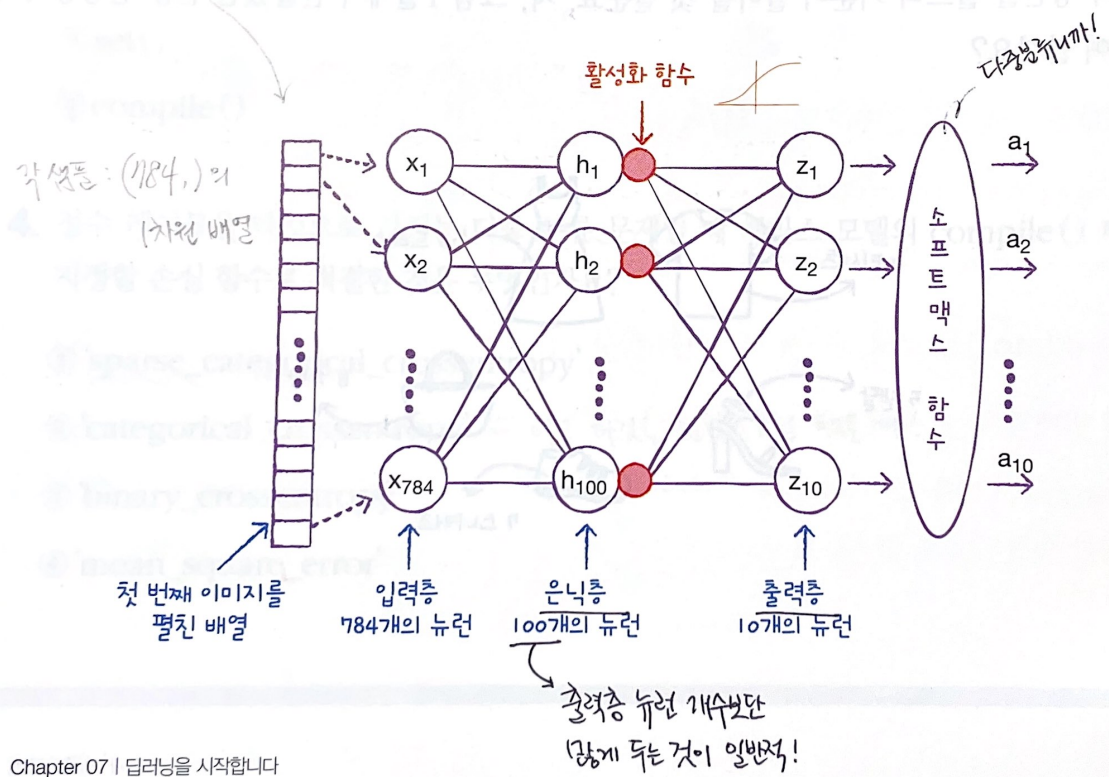
- 출력층과 마찬가지로 활성화함수(🔴)가 적용됨. (⭐이유는 밑에서!)
- 출력층보다는 쓸 수 있는 함수가 비교적 자유로움! ex) 시그모이드 함수, 렐루 함수 등
심층신경망 만들기 (1)
- 저번처럼 밀집층 객체(
Dense)를 만들고,Sequential()로 전달해서 만들 수 있음. - 근데 이번엔 층이 2개라는 점이 다른 것!!
+ 은닉층activation은 가장 대표적인 시그모이드로 일단 해봄.

➕ 참고로, 여기서 은닉층의 뉴런 개수를 100개로 정한 건 특별한 기준이 있는 게 아니라, 경험적으로 본인이 판단해야 하는 부분입니다... 대신, 정보손실이 없도록 하려면 적어도 출력층의 유닛 개수보다는 많게 만들어야겠죠!

.summary()로 모델에 대한 유용한 정보를 확인 가능.- 'Output Shape' : (경사하강법 배치크기, 출력 유닛 개수)를 보여줌. 훈련을 몇 개의 배치로 할지 모르니까, 유연하게 받을 수 있도록 None으로 되어있음.
- 'Param' : 모델 파라미터, 즉 각 층의 가중치&절편의 개수를 보여줌.
1st 층 = 784 * 100 (가중치) + 100(절편) = 78,500
2nd 층 = 100 * 10 (가중치) + 10(절편) = 1,010
심층신경망 만들기 (2)
- 층을 여러 개 추가하는 다른 방법도 있음 = 따로 층 객체 만들어서 전달하지 않고,
Dense()클래스를 아예Sequential()안에서 바로!

name으로 층 이름도 설정해놓을 수 있음 (영문 only!summary에서 그대로 나옴)

- 한 번에 다 쓰니까 편하긴 한데, 층 많아지면 한 문장이 너무 길어져버릴 수 있음 ㅠ
심층신경망 만들기 (3)
- 그래서 실제로 젤 많이 쓰는 건 이 세 번째 방법! = 모델에
.add()로 원하는 만큼 추가 - 이러면
add()속에 if문 등을 활용해서 조건에 따라 층을 추가할 수도 있음!
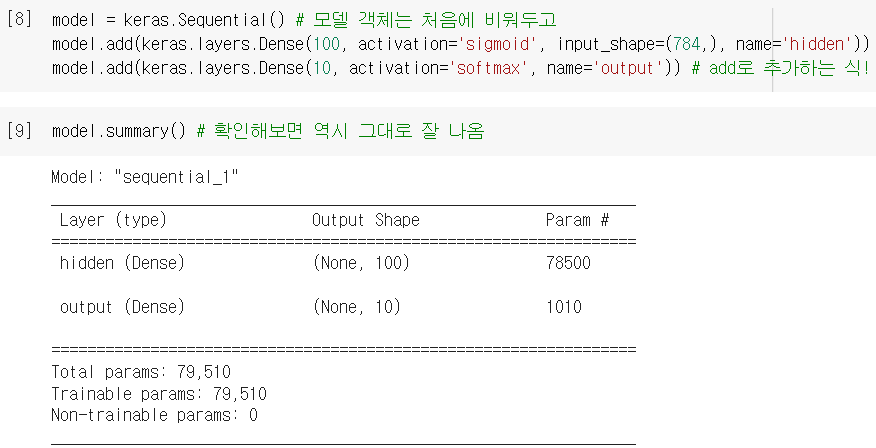
- 이후에
.compile()로 설정하고,.fit()으로 훈련하는 과정은 동일하게 하면 됨!

3. 활성화 함수
⭐은닉층에 활성화함수를 적용하는 이유
- 2개의 선형 계산식이 연속된 형태로 있으면 중간 미지수가 사라지듯이, 신경망에서도 연속으로 쌓는 층이 그냥 선형적인 계산으로만 구성되면, 사실상 중간에 낀 은닉층들의 존재 의미가 사라져버리게 됨.

- 그래서 은닉층의 결과값을 비선형적으로 비틀어주는 계산이 필요함!

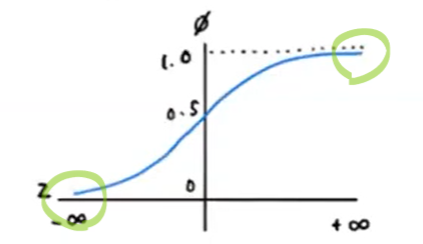
🆕렐루 함수
- 기존에 많이 쓰던 시그모이드 함수의 단점
: 출력값(z)이 너무 크거나 작을 땐 함수값의 차이가 너무 미미함 → 변화에 빠르게 대응하지 못하니까 결국 층을 깊게 쌓기가 힘듦.
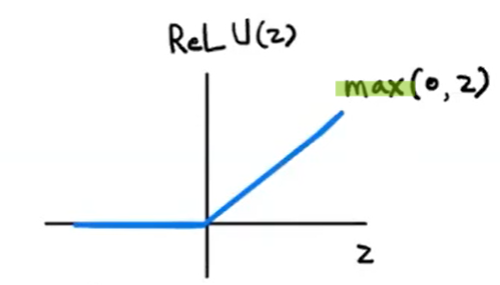
- 그래서 새롭게 제안된 게 바로 렐루 함수!!
: z가 0보다 작으면 0으로 출력하고, z가 0보다 크면 그대로 z를 출력함.
(이미지 처리에 좋은 성능을 내는 것으로 알려져 있음)
심층신경망 만들기 (4)
➕ "렐루 함수를 쓴 모델을 만들어 보기 전에 층도 하나 더 알려드리죠"
Flatten(): 입력데이터를 1차원으로 펼쳐주는 유틸리티 층. (그냥 편의를 위한 층)
➡️ 이러면 좋은 게,summary출력해보면 입력값 개수를 바로 알 수 있음! (걍 전처리 과정을 점점 모델 내에 포함시키는 추세의 연장선이라 보면 될 듯)

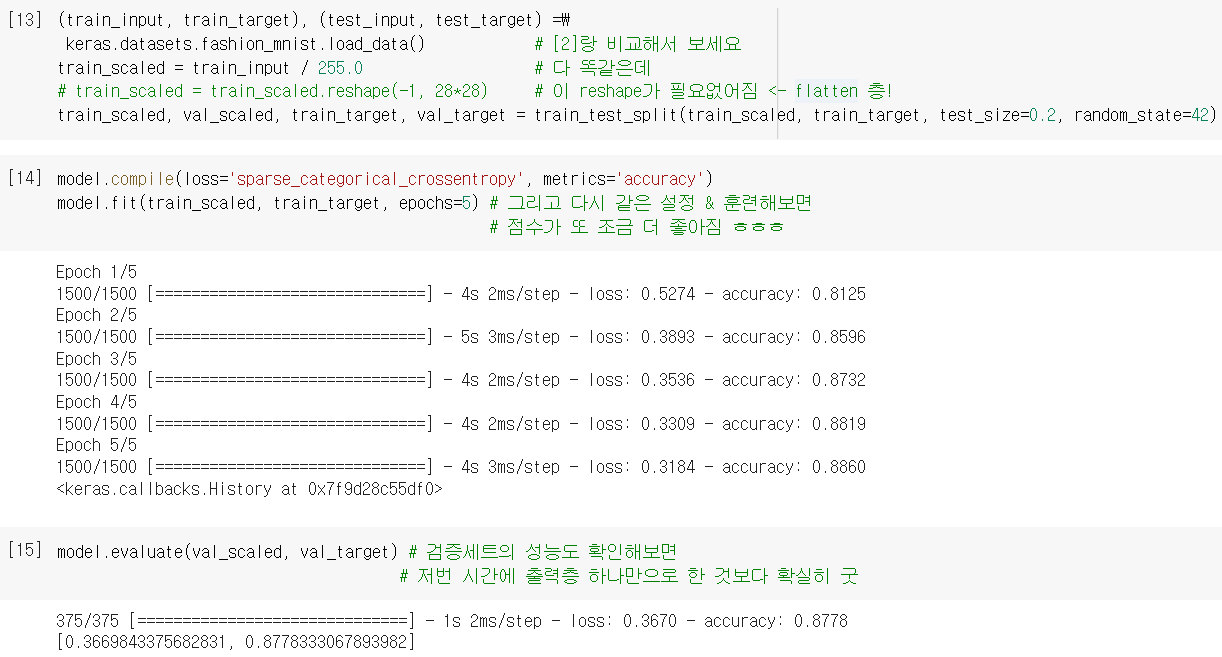
- 자 이렇게 만든 새로운 모델로 다시 훈련해보자.
=.reshape()필요없어짐. + 렐루 함수 덕분에 성능 조금 더 좋아짐.
4. 옵티마이저
신경망의 하이퍼파라미터
- 신경망에는 특히 하이퍼파라미터(모델 학습 X 지정 필요 O)가 많음.
- ex) 은닉층 뉴런 개수
100, 활성화함수activation, 층의 종류DenseFlatten, 배치크기batch_size, 반복횟수epochs등이 있었음.
옵티마이저 설정
- 옵티마이저도 하이퍼파라미터 중 하나로, 경사하강법의 종류에 대한 설정임.
ex)SGD(): 이름은 그냥 SGD인데 실제로는 미니배치 경사하강법 (기본 배치크기=32) - 설정(compile) 단계에서
optimizer로 지정할 수 있으며, [16]처럼 문자열로 호출하거나, [17]처럼 객체로 만들어놓고 호출할 수도 있음

- 우리가 배웠던 SGD 이외에도 더 개선된 방법들이 많음! (p.382)
- 적응적 학습률 : 최적점에 가까워질수록 학습률을 낮추는 효율적인 방식
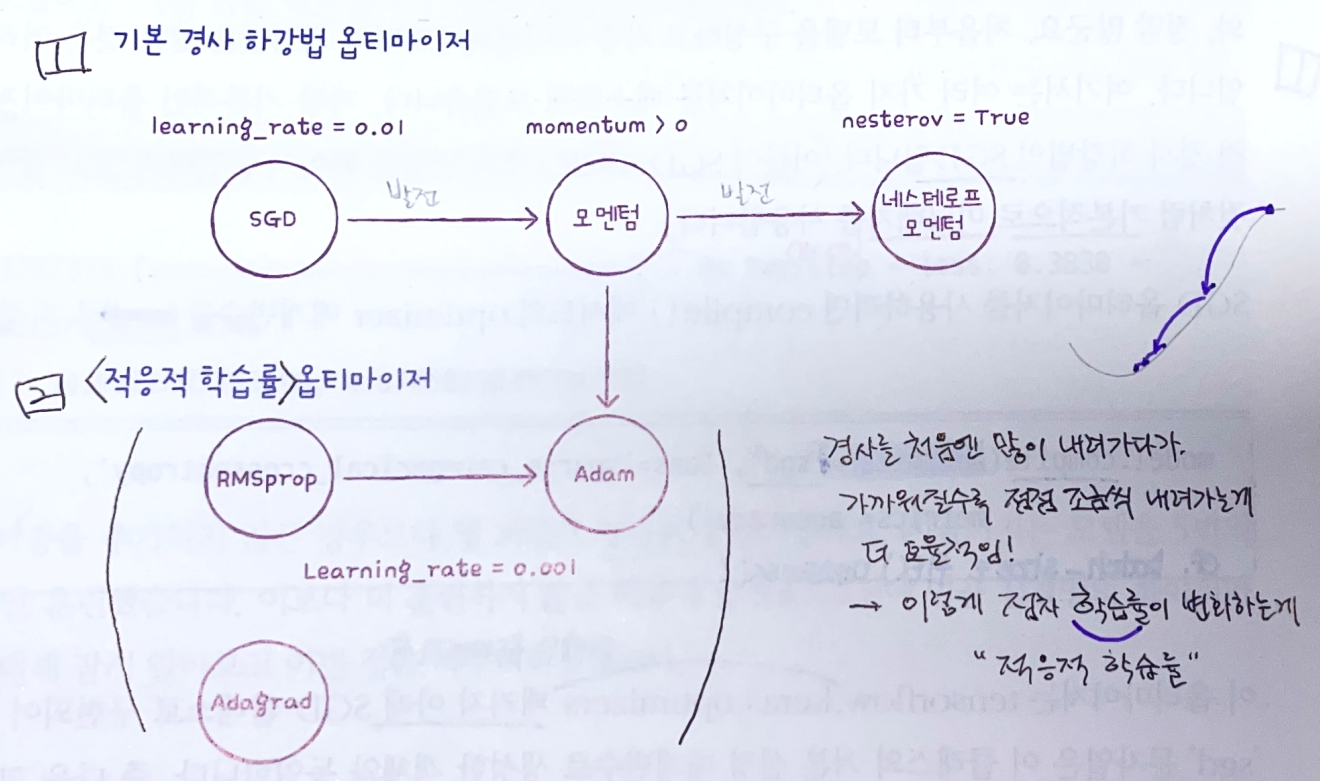
- "이 옵티마이저들이 어떻게 최적화하는지에 대한 자세한 내용은 중급자 교재로...^^"

심층신경망 만들기 (5)
- 자 그럼 우리는, Adam 옵티마이저를 사용한 모델로 최종 모델을 만들어보겠음!
( 역시 Sequential & add → compile → fit → evaluate 순서대로~ )
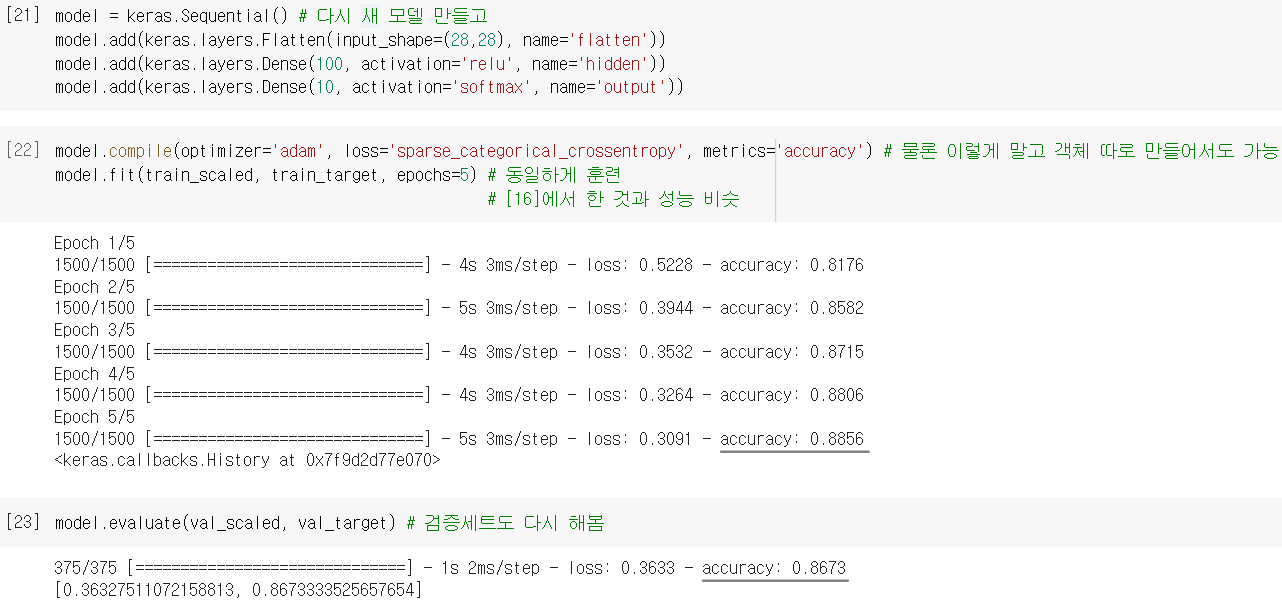
이제 여러 개의 층을 추가한 다층 인공 신경망까지 터득 완-료!
➕플러스 알파
➊ 회귀 신경망 모델의 활성화함수❓
- 우리는 럭키백 문제를 다루니까 계속 인공신경망으로 '분류 모델'을 만들었다. 그렇다면, 회귀 문제에서는 어떤 활성화 함수가 쓰일까?
- 대답은 "필요 없다" 이다. 분류 모델에서 활성화 함수(ex. sigmoid, softmax)를 썼던 이유는, (알다시피) 확률로 출력하기 위해서였다. 그런데 회귀의 출력값은 그냥 임의의 숫자값이 그대로 나오는 것이므로,
activation에 아무것도 지정해주지 않으면 된다!
➋ Flatten 층
- 뭔가 의미 있는 연산을 하는 게 아니라 그냥 편의를 위한 기능뿐이라서 '층'이라고 하기도 좀 애매하지만, 그래도
keras.layers모듈 아래에 있어서 '층'이라고 한다. - 케라스 API는 입력 데이터에 대한 전처리 과정을 최대한 모델 내에 포함시키려는 추세인데, 그러한 일환으로 보면 되겠다.
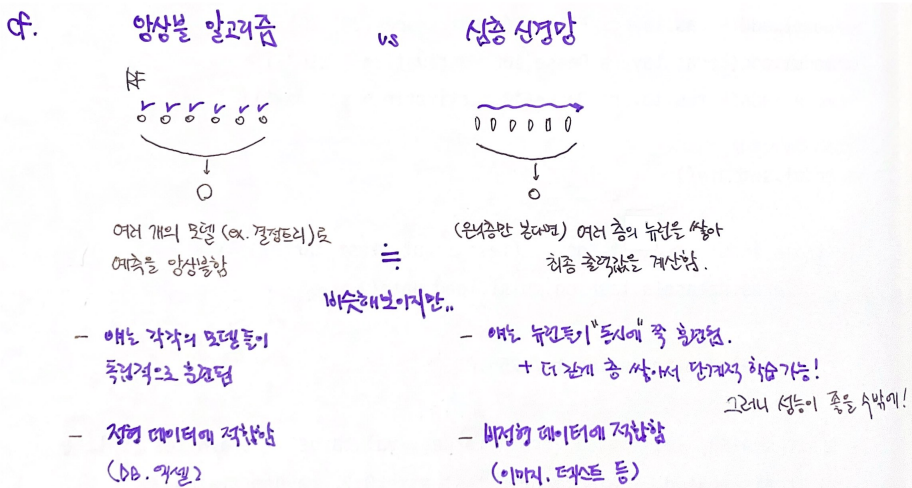
➌ 앙상블 알고리즘 🆚 심층 신경망
- 여러 개를 모아서 하나의 최종 모델을 구성한다는 점에서 비슷해보이지만,
완전히 다른 방식으로 훈련된다!
🤔 Hmmmm...
370p. 시그모이드는 그냥 0~1로 압축해주는 역할이었음. 근데 얘를 중간에 끼워넣는다고 성능이 좋아지는 이유가 뭐지?
👨🏻🏫 활성화 함수를 사용하는 이유는 369페이지 설명을 참고하세요. 🆗 아 그러네요 착각했습니다^^;; 성능이 좋아지는 건 활성화함수가 아니라 층을 쌓았기 때문..! 활성화함수는 그저 출력값의 존재가 무색해지지 않게 비틀어주는 것뿐! (본문 #3-1 참고)
그렇다면 질문을 바꿔서 드려야하겠네요. 그냥 똑같은 종류의 Dense 층을 하나 더 쌓았을 뿐인데 성능이 좋아지는 이유가 궁금합니다! 한번에 10개의 유닛(z)으로 가는 게 아니라, 100개의 h를 거치고 다시 10개의 z로 가니까 더 특징을 잘 잡아낸다 정도로 이해하면 되는 걸까요..?
377p. 렐루함수는 z가 양수일 때 z를 그대로 쓰는데, 그러면 활성화함수로서의 의미가 없는 게 아닌가요? 오히려 시그모이드 함수는 지수함수를 써서 비선형적으로 틀어줬는데, 왜 더 단순한 렐루함수가 유용하게 쓰이는 건지요ㅠ (음수는 걍 무시해버리는데 이것도 괜찮은 건지,,)
376p. 경사하강법에서 점진적으로 학습하려면
partial.fit으로 훈련시킨다고 배웠습니다. 그런데 제가 우연히 <run>을 잘못 눌러서fit으로 한번 더 훈련시켰는데 성능이 높아지는 것을 발견했습니다. 혹시 이건 왜 그런 걸까요?👨🏻🏫 케라스에서는
fit()메서드가 점진적인 학습 방법입니다. 🆗 오호라!

384p. 고급 옵티마이저인 Adam을 사용했는데도 성능이 거의 동일하게 나온 이유가 궁금합니다. 혹시 성능은 비슷한 대신 시간이 더 줄어드나요?
어떤 옵티마이저가 항상 더 나은 성능을 낸다는 보장은 없습니다. 🆗 그래.. 그냥 해당 문제에 더 잘 맞냐 안 맞냐가 있는 거겠지..!
🤓 To wrap up...
지난 시간에 배운 신경망에서 층을 추가하는 방법을 배웠다. 그러니 사실상 이제서야 신경망의 기본적인 형태를 배운 셈..! 다만 여러가지 고급 옵티마이저들을 보니 또 할 게 많이 남았다는 생각이 밀려온다 🥲 저스트 킵 고잉 ..
여전히 패션 럭키백을 만드는데, 지난 번에 만든 인공신경망을 더 업그레이드 하기로 함! = 심층신경망 → 이번엔 입력층과 출력층 사이에 은닉층이라는 걸 하나 추가함! → 층 추가하는 방법 (1) 객체로 만들고 전달 (2) Sequential 내에서 바로 생성 (3) 객체는 아니고 add 메소드로 전달 → 시그모이드 활성화함수의 단점을 극복한 렐루 활성화함수를 새롭게 도입 + 입력데이터를 일렬로 펼쳐주는 Flatten 층도 새로 도입 → 확실히 성능 좋아짐! → 더 나아가, 하강법의 종류를 설정해서 성능 더더욱 높일 수 있는 옵티마이저까지 배움!
