https://parksb.github.io/article/29.html
캐시란?
기술의 발전으로 프로세서 속도는 빠르게 증가하지만 메모리의 속도는 부족하다. 시스템의 입장에서 아무리 프로세서 처리가 빠르게 진행되어도 메모리 처리 속도가 느리게 된다면 전체적으로 느려지기때문에 캐시가 생겨났다.
캐시는 CPU내부에 들어가는 작은 메모리이다.
프로세서가 매번 데이터를 필요로 할 때마다 메인 메모리에 접근해서 받아온다면 시간이 오래걸리게 된다.
캐시는 자주 사용하는 데이터를 담아놓고 있다가 해당 데이터가 필요로 할때 프로서세가 메인 메모리 대신 캐시에 접근하여 데이터를 처리한다.
캐시는 반응 속도가 빠른 SRAM으로 주소에 키값이 주어지면 해당 공간에 즉시 접근이 가능해진다.
대신 SRAM이므로 전원이 유지되어야만 데이터를 저장할 수 있다.
또한 캐시의 개념상 쓰일것으로 예상되는 데이터들은 계속해서 변화하므로 데이터의 휘발성이 있다.
주소에 키값이 주어졌을때 즉시 접근이 가능한 개념은 해쉬테이블과 동일하며 하드웨어로 구현한 해쉬테이블이라고 부를수 있겠다.
캐시의 실제 모습
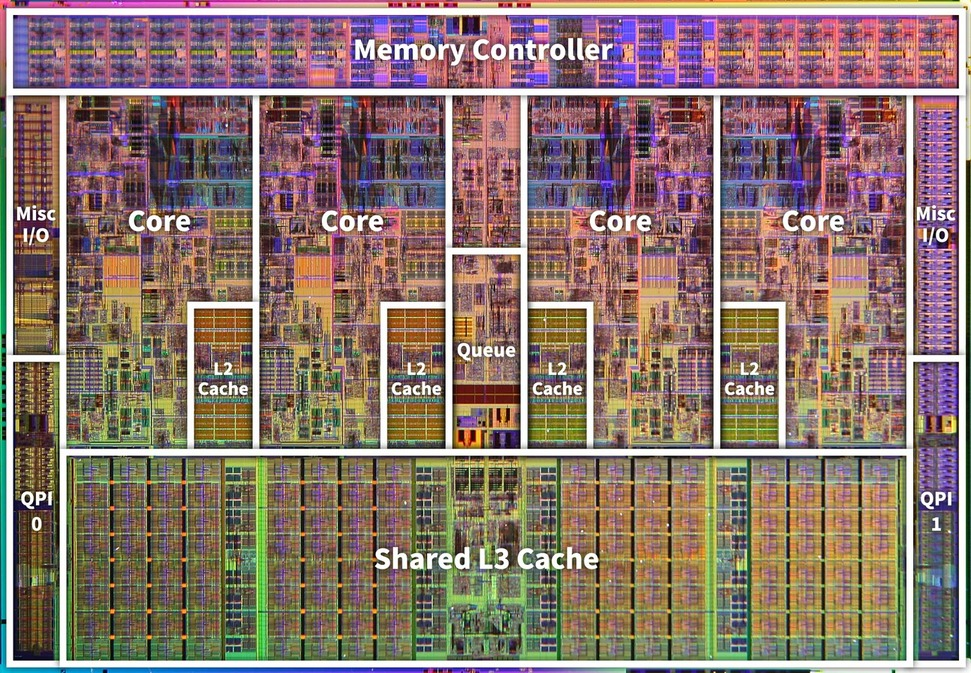
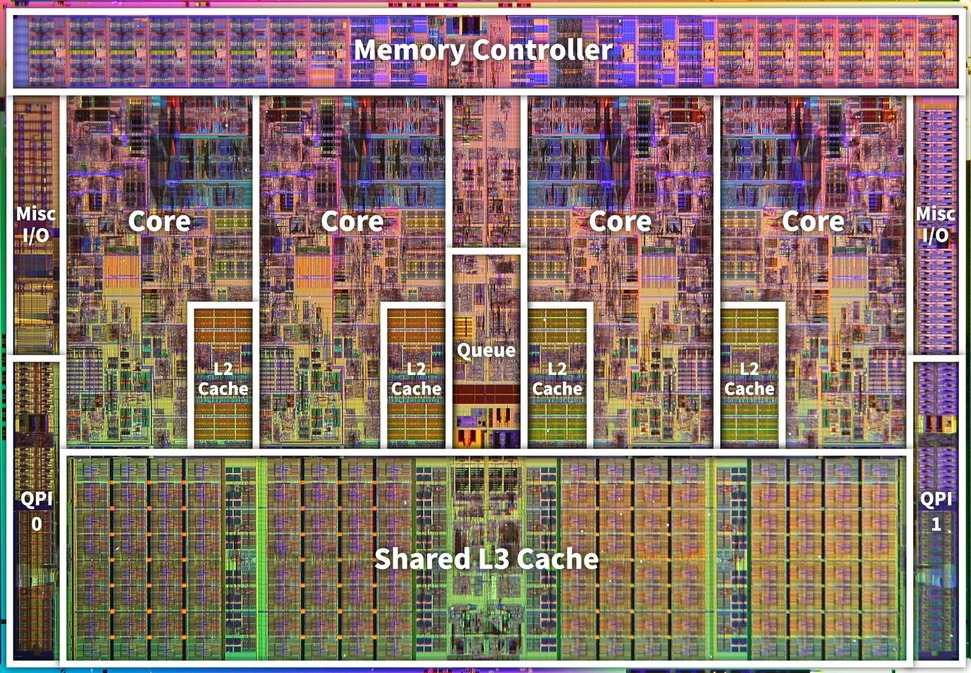
위의 사진은 CPU의 사진이다. 캐시의 종류는 3개이며 각각의 목적과 역할이 나누어져있다.
- L1 Cache: 프로세서와 가장 가까운 캐시. 속도를 위해 I로 나뉜다.
- Instruction Cache (I$): 메모리의 TEXT 영역 데이터를 다루는 캐시.
- Data Cache (D$): TEXT 영역을 제외한 모든 데이터를 다루는 캐시.
- L2 Cache: 용량이 큰 캐시. 크기를 위해 L1 캐시처럼 나누지 않는다.
- L3 Cache: 멀티 코어 시스템에서 여러 코어가 공유하는 캐시.
Latency
CPU에서 요청한 데이터가 캐시에 존재하는 경우를 Hit라고 하고 없을 경우 Miss라고 한다.
히트 레이턴시는 히트여서 메모리→CPU의 시간을 의미하며
미스 레이턴시는 미스의 경우 상위 캐시에서 데이터를 가져오거나(L1 → L2 → 메모리...)
메모리에서 데이터를 가져올 때 걸리는 시간을 의미한다.
평균 접근 시간은 다음과 같다.
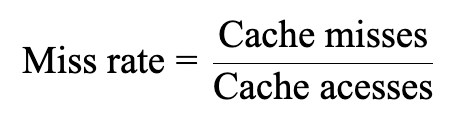
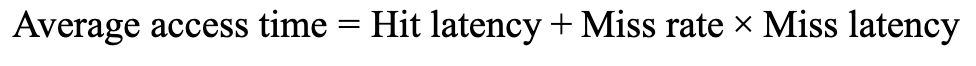
캐시 구분 방법
캐시는 프로세서가 요구할 데이터를 예상하고 가지고 있어야 한다. 그렇다면 예상하는 방식은 무엇일까?
지역성 원리는 시간 지역성(Temporal locality)과 공간 지역성(Spatial locality)으로 구분해서 볼 수 있다.
시간지역성은 다음과 같은 예시로 이해할 수 있다.
loop를 돌때 i 는 짧은 시간 내에 여러번 접근이 이뤄질것이다.
for(i in 1..10){
Log.d("TEST","${i}")
}공간 지역성은 최근 접근한 데이터의 주변에 다시 접근하는 경향을 의미한다.
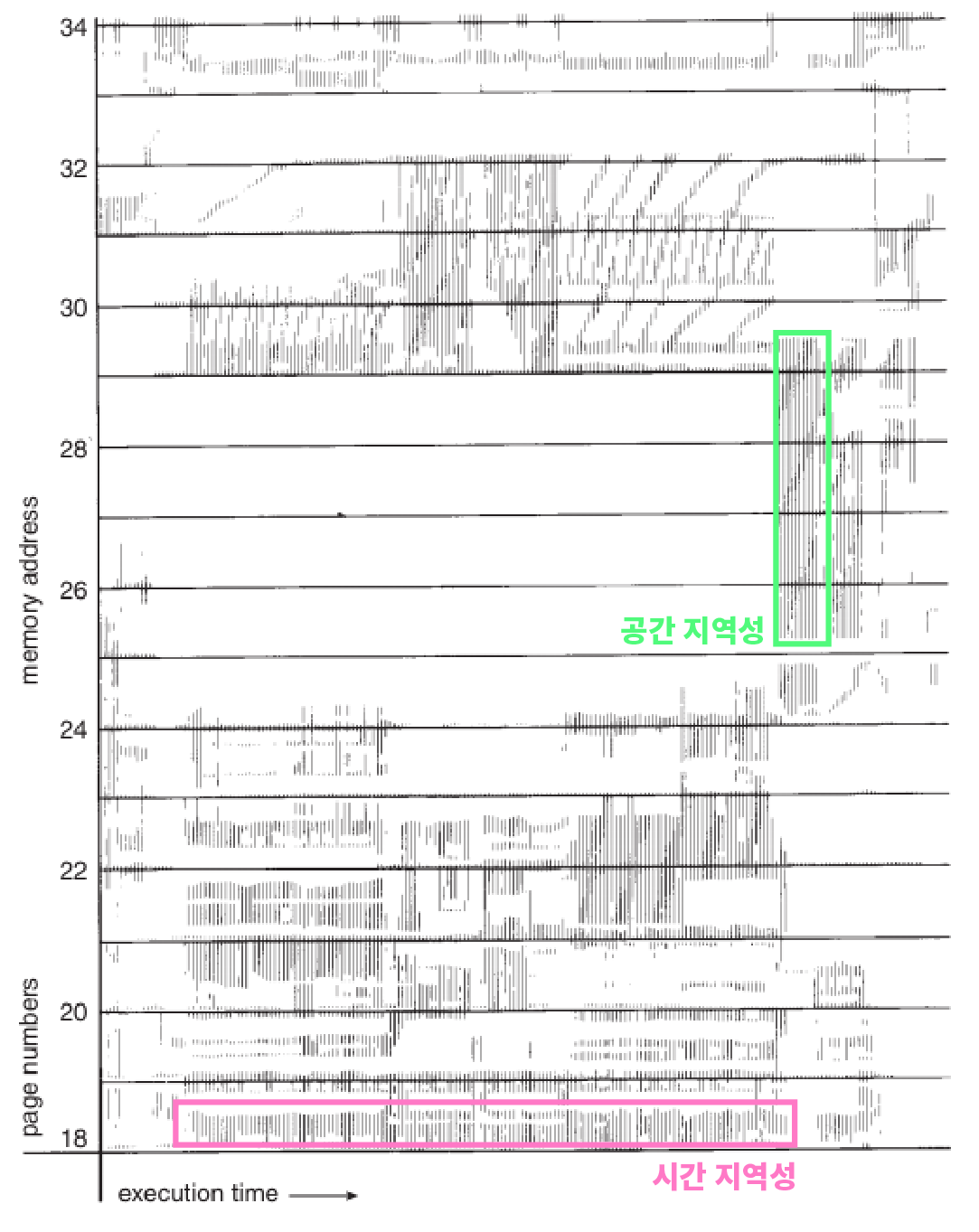
가로축은 시간이고 세로축은 메모리 주소이다. 즉 수평으로 이어진 참조 기록은 시간 지역성을, 수직으로 이어진
참조 기록은 공간 지역성을 의미한다.
이와 같은 방식으로 캐시는 다음에 프로세서가 접근할 데이터를 예상하고 캐시에 준비해 놓는다.
