[Programmers/프로그래머스] 2020 KAKAO BLIND RECRUITMENT 가사 검색 - Python/파이썬 [해설/풀이]
0

[Programmers/프로그래머스] 2020 KAKAO BLIND RECRUITMENT [코딩테스트]
- [Lv. 2] 문자열 압축
- [Lv. 2] 괄호 변환
- [Lv. 3] 자물쇠와 열쇠
- [Lv. 4] 가사 검색
- [Lv. 3] 기둥과 보 설치
- [Lv. 3] 외벽 점검
- [Lv. 3] 블록 이동하기
📌 문제

📝 가사 단어 제한사항

📝 검색 키워드 제한사항
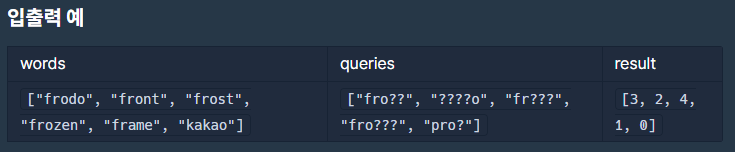
💻 입출력 예
📖 입출력 예에 대한 설명

📌 풀이
📖 해설
- 각 길이별로 단어를 사전순으로 정렬한 정순/역순 딕셔너리 생성
# sorted dictionary
5: {['frame', 'frodo', 'front', 'frost', 'kakao'], 6: ['frozen']}
# sorted rdictionary
{5: ['emarf', 'oakak', 'odorf', 'tnorf', 'tsorf'], 6: ['nezorf']}
- 정순/역순 딕셔너리 선택
2-1. 접두사가 와일드카드 '?' 일 경우 역순
2-2. 접미사가 와일드카드 '?' 일 경우 정순- 이진탐색을 활용하여 와일드카드 범위에 해당하는 단어 탐색
# fro?? -> froaa ~ frozz | 와일드카드 접미사 -> 정순 딕셔너리 사용
['frame', 'frodo', 'front', 'frost', 'kakao']
'froaa' 'frozz'
# 'froaa', 'frozz'가 삽입될 수 있는 위치 탐색
-> bisect_left = 1 # 'froaa'가 삽입될 수 있는 위치(인덱스)
-> bisect_right = 4 # 'frozz'가 삽입될 수 있는 위치(인덱스)
-> right - left = 4 - 1 = 3개 # froaa ~ frozz 사이에 포함되는 단어 개수# ????o => o???? -> oaaaa ~ ozzzz | 와일드카드 접두사 -> 역순 딕셔너리 사용
['emarf', 'oakak', 'odorf', 'tnorf', 'tsorf']
oaaaa ozzzz
# 'oaaaa', 'ozzzz'가 삽입될 수 있는 위치 탐색
-> bisect_left = 1 # 'oaaaa'가 삽입될 수 있는 위치(인덱스)
-> bisect_right = 3 # 'ozzzz'가 삽입될 수 있는 위치(인덱스)
-> right - left = 3 - 1 = 2개 # oaaaa ~ ozzzz 사이에 포함되는 단어 개수# fr??? -> fraaa ~ frzzz | 와일드카드 접미사 -> 정순 딕셔너리 사용
['frame', 'frodo', 'front', 'frost', 'kakao']
'fraaa' 'frzzz'
# 'fraaa', 'frzzz'가 삽입될 수 있는 위치 탐색
-> bisect_left = 0 # 'fraaa'가 삽입될 수 있는 위치(인덱스)
-> bisect_right = 4 # 'frzzz'가 삽입될 수 있는 위치(인덱스)
-> right - left = 4 - 0 = 4개 # fraaa ~ frzzz 사이에 포함되는 단어 개수# fro??? -> froaaa ~ frozzz | 와일드카드 접미사 -> 정순 딕셔너리 사용
['frozen']
froaaa frozzz
# 'froaaa', 'frozzz'가 삽입될 수 있는 위치 탐색
-> bisect_left = 0 # 'froaaa'가 삽입될 수 있는 위치(인덱스)
-> bisect_right = 1 # 'frozzz'가 삽입될 수 있는 위치(인덱스)
-> right - left = 1 - 0 = 1개 # froaaa ~ frozzz 사이에 포함되는 단어 개수# pro? -> proa ~ proz | 와일드카드 접미사 -> 정순 딕셔너리 사용
[]
proa proz
# 'proa', 'proz'가 삽입될 수 있는 위치 탐색
-> bisect_left = 0 # 'proa'가 삽입될 수 있는 위치(인덱스)
-> bisect_right = 0 # 'proz'가 삽입될 수 있는 위치(인덱스)
-> right - left = 0 - 0 = 0개 # proa ~ proz 사이에 포함되는 단어 개수💻 전체코드
from collections import defaultdict
from bisect import bisect_left, bisect_right
# 이진탐색O(NlogN)을 통한 인덱스의 차이를 계산하여 단어 개수 측정
def count_by_range_with_binary_search(start, end, words_list):
return bisect_right(words_list, end) - bisect_left(words_list, start)
def solution(words, queries):
dictionary = defaultdict(list) # 정순 단어사전
rdictionary = defaultdict(list) # 역순 단어사전
# key, value = 길이, 단어
for word in words:
dictionary[len(word)].append(word) # 각 길이별로 정순 단어 저장
rdictionary[len(word)].append(word[::-1]) # 각 길이별로 역순 단어 저장
# 길이별 단어목록 사전순 정렬
for key, value in dictionary.items(): # 정순 단어 각 길이별로
dictionary[key].sort() # 단어목록 사전순 정렬
for key, value in rdictionary.items(): # 역순 단어 각 길이별로
rdictionary[key].sort() # 단어목록 사전순 정렬
answer = []
for query in queries:
if query[0] == '?': # 접두사가 와일드카드(?) 일 때
words_list = rdictionary[len(query)] # 역순 단어사전에서 query와 길이가 같은 단어목록 불러오기
start = query[::-1].replace('?', 'a') # 와일드카드(?) 탐색시작지점 a로 변환
end = query[::-1].replace('?', 'z') # 와일드카드(?) 탐색종료지점 z로 변환
elif query[-1] == '?': # 접미사가 와일드카드(?) 일 때
words_list = dictionary[len(query)] # 정순 단어사전에서 query와 길이가 같은 단어목록 불러오기
start = query.replace('?', 'a') # 와일드카드(?) 탐색시작지점 a로 변환
end = query.replace('?', 'z') # 와일드카드(?) 탐색종료지점 z로 변환
answer.append(count_by_range_with_binary_search(start, end, words_list))
return answer
개발을 즐길 줄 아는 백엔드 개발자