
배경
Kafka 설정을 하고 디버깅을 하던 중, 오류 부분을 찾아서 서버 실행을 중지하고 다시 서버를 실행했을 때, Produce 않아도 이벤트를 Consume 후 breakpoint에 걸려있는게 아닌가..!
문득 정상 consume 처리되지 않았을 때 Kafka와 서버에선 어떻게 동작하는지 궁금해졌다.
아래 순서에 따라서 살펴보자.
1. 브로커가 컨슈머의 생존여부를 감지하는 방법.
2. 컨슈머가 종료될 때 브로커로 전달되는 내용 (정상종료 / 비정상 종료)
3. 컨슈머가 살아났을 때 브로커로부터 가져오는 데이터
1. 브로커는 컨슈머가 죽었는지 살았는지 어떻게 알까?
브로커와 카프카는 heartBeat를 통해서 healthCheck 상태를 확인한다.
글에 쓰여져 있는 대로, 특정 주기마다 반드시 heartbeat을 보내야만, "살아있는" 클라이언트 상태로 간주하여 브로커의 리벨런싱을 피할 수 있다.
KafkaConsumer.poll 메서드는 단순히 데이터를 가져오기만 하지 않는다.
poll메서드로 Kafka에서 데이터를 가져옴과 동시에, coordinator.poll()이 호출된다.
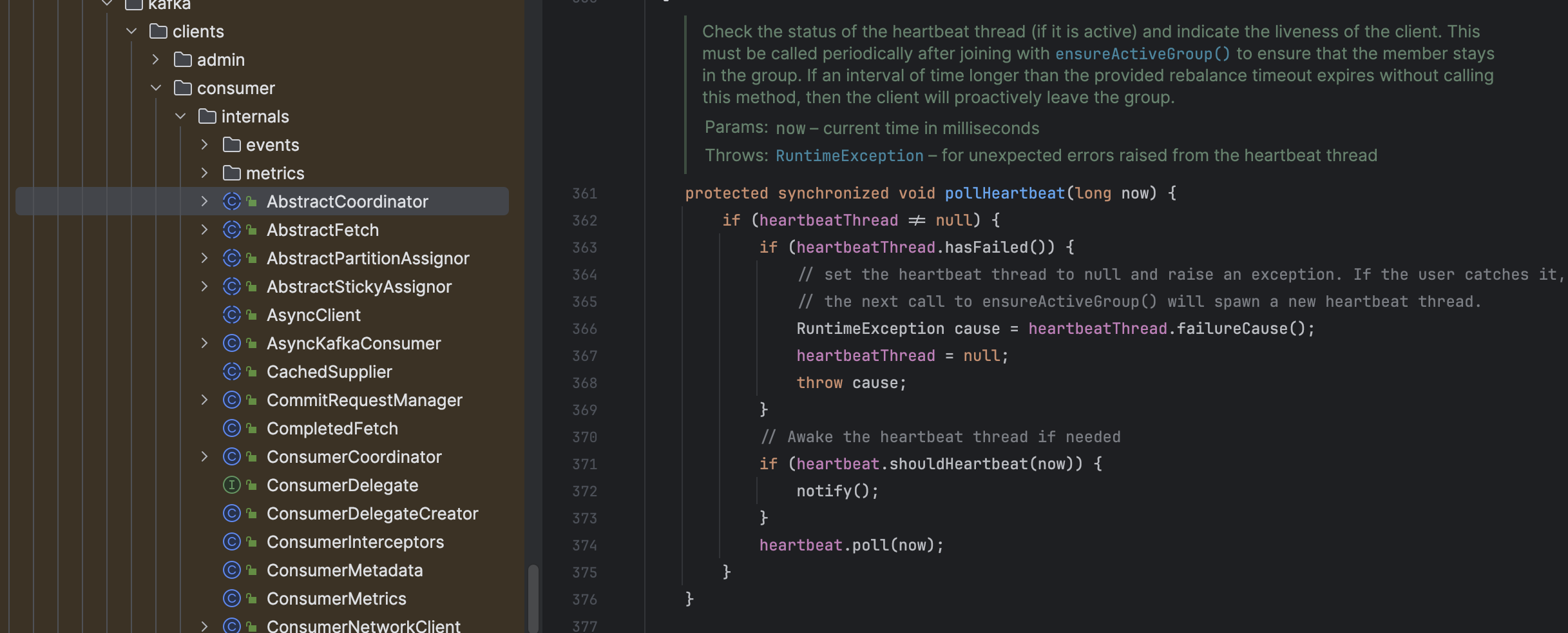
KafkaConsumer 내부 poll함수는 ConsumerDelegate(LegacyKafkaConsumer, AsynceKafkaConsumer)에 의해 구성되어있는데, 이 중 ConsumerCoordinator를 직접 참조하는 LegacyKafkaConsumer(아래 사진 참조) 기준으로 분석했다.
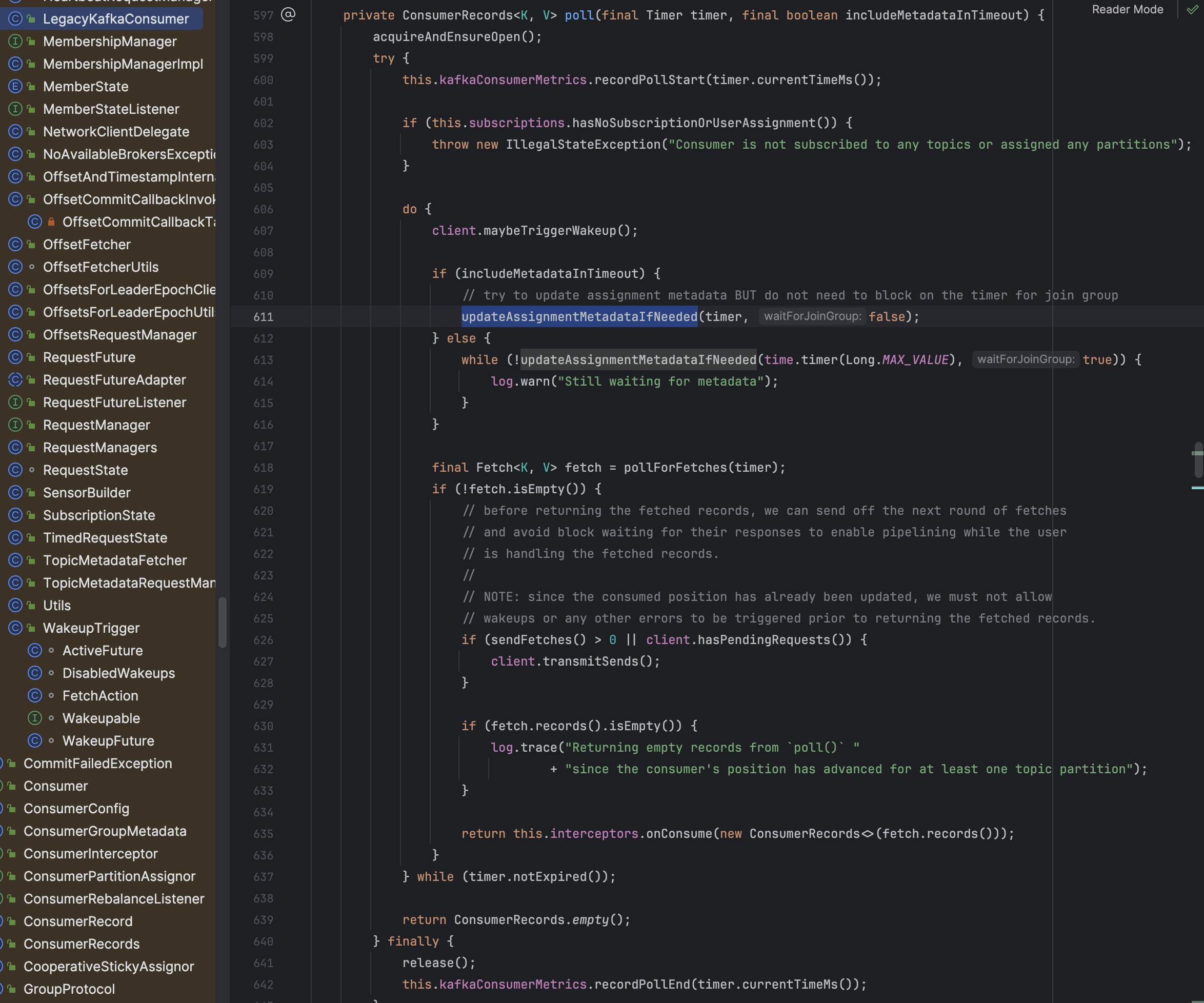
상단 updateAssignmentMetadataIfNeeded 함수 내부 coordinator.poll 동작을 수행하게 된다.
즉 poll이 멈추면 consumer group 내부에서 heartbeat도 끊겨서 session.timeout.ms 이후 브로커가 해당 consumer가 죽었다 판단 후 Rebalance 동작이 진행된다.
그러면 Coordinator.poll 함수는 어떤 역할을 할까?
Coordinator.poll 동작 수행 시, commit / offset 관리 및 heartbeat을 전송하게 된다.
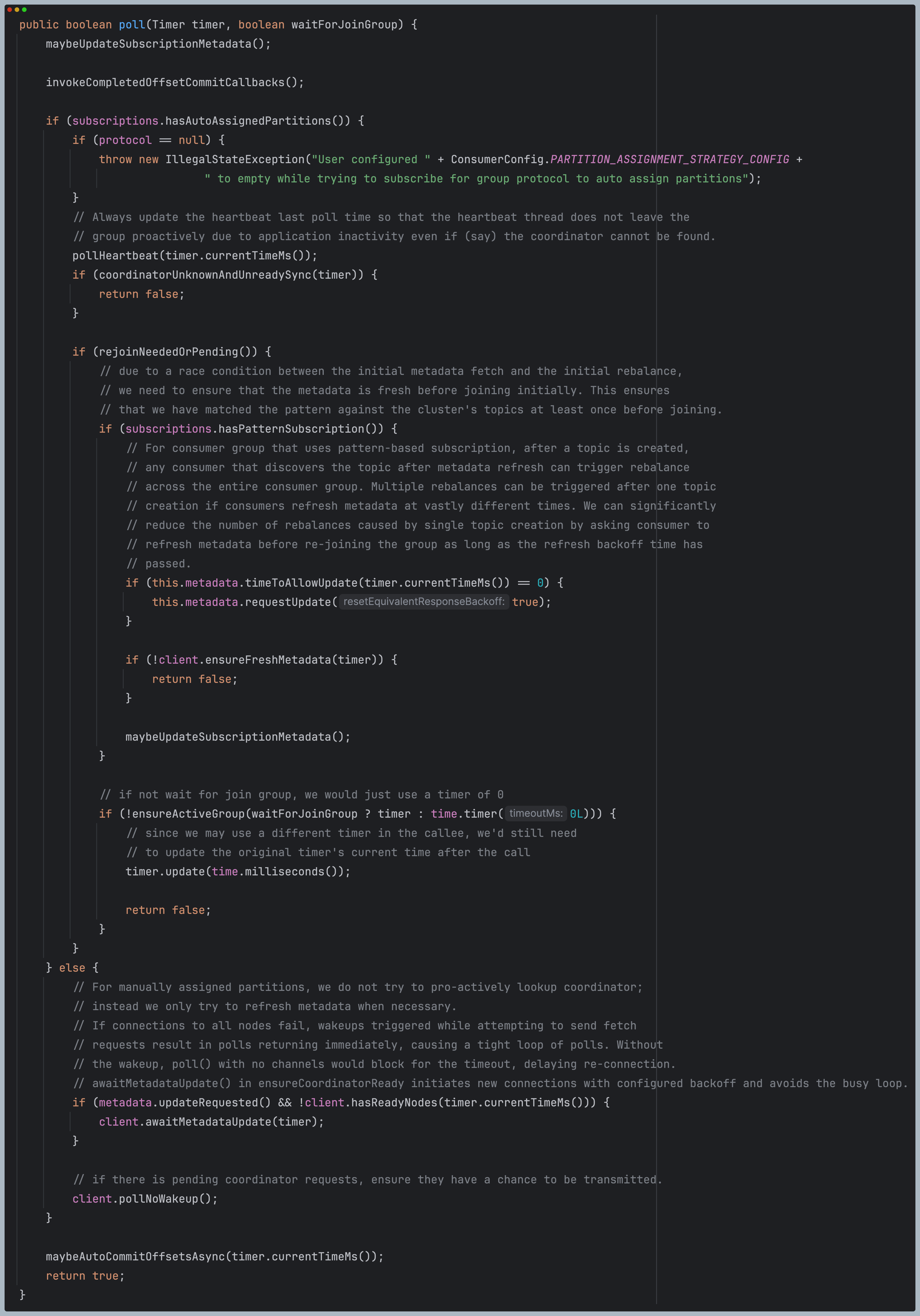
해당 메서드에선 크게 아래와 같은 동작을 수행한다
1. 토픽 최신화 및 메타데이터 관리
2. rebalance 필요여부 관리 (pollHeartbeat)
3. heartbeat 전송 관리
4. offset commit 관리
마무리
이렇게 consumer는 데이터를 poll 할 때 마다 지속적으로 브로커에게 "나 살아있어" 라는 식의 heartbeat 전송을 통해, 컨슈머 그룹에서 빠지지 않고 값을 가져오는 방식에 대해서 알아봤다.
코드를 살펴보다보니, Coordinaotr.poll 부분에서 일어나는 동작 중 아주 일부분만 살펴보게 된 것 같다.
commit이 관리되는 방식이나, rebalance 및 컨슈머 그룹 관리 부분을 조금 더 자세히 알아봐야겠다.

내용 잘 보고 갑니다!