
https://programmers.co.kr/learn/courses/30/lessons/42627
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
-
0ms 시점에 3ms가 소요되는 A작업 요청
-
1ms 시점에 9ms가 소요되는 B작업 요청
-
2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
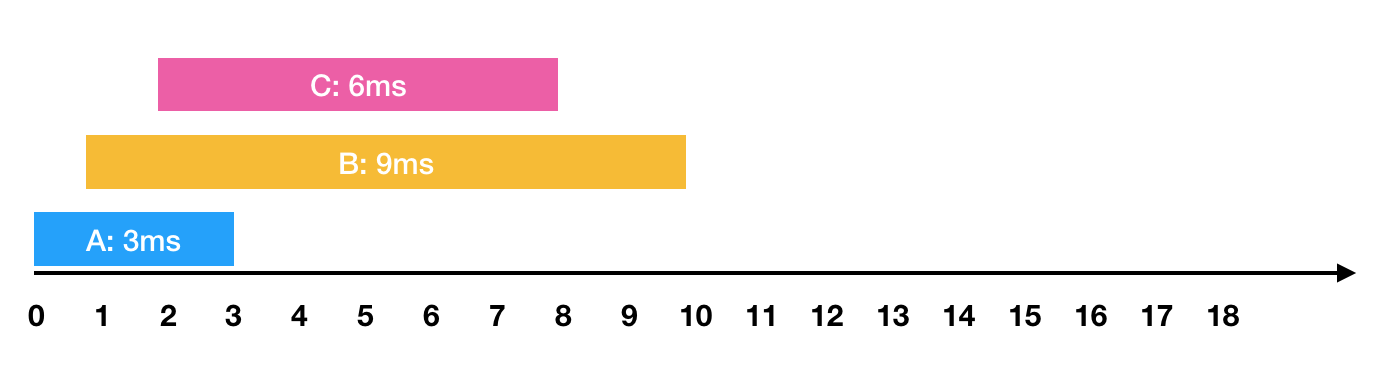
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
-
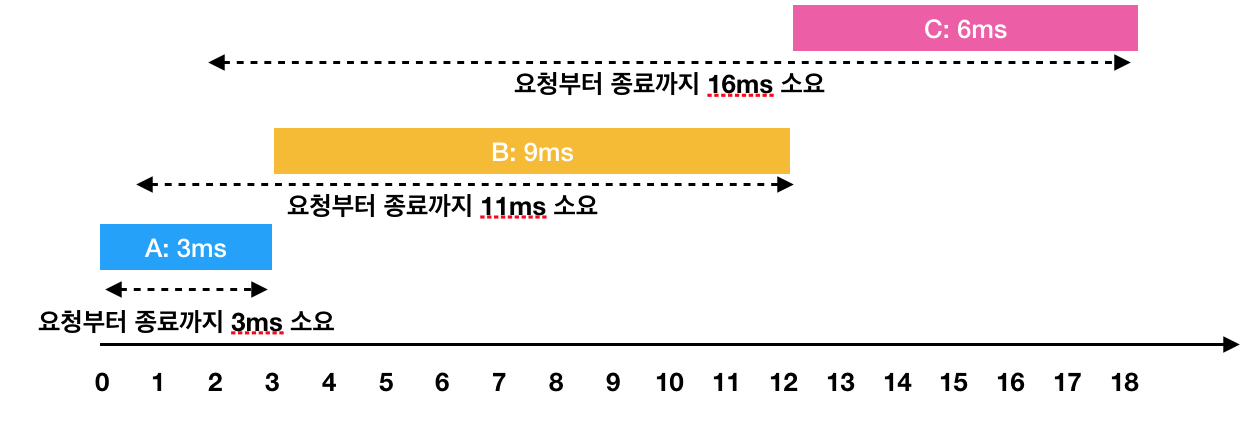
A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
-
B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
-
C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면

- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
jobs의 길이는 1 이상 500 이하입니다.
jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예
| jobs | return |
|---|---|
| [[0, 3], [1, 9], [2, 6]] | 9 |
Solution
#include <string>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
int solution(vector<vector<int>> jobs) {
int answer = 0;
sort(jobs.begin(), jobs.end());
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> PQ;
int idx = 0, time = 0;
int length = jobs.size();
while(idx < length || !PQ.empty()){
if(idx < length && time >= jobs[idx][0]){
PQ.push({jobs[idx][1], jobs[idx][0]});
idx++;
continue;
}
if(!PQ.empty()){
time += PQ.top().first;
answer += time - PQ.top().second;
PQ.pop();
}
else{
time = jobs[idx][0];
}
}
return answer / length;
}우선 정렬을 해야한다. 무조건 먼저온놈 기준으로 확인을 해야한다. 데이터가 순서대로 들어온다는 말은 없었으니까. 그리고 Min heap 기반 우선순위큐를 선언한다.
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> PQ;
int idx = 0, time = 0;
int length = jobs.size();
while(idx < length || !PQ.empty()){
if(idx < length && time >= jobs[idx][0]){
PQ.push({jobs[idx][1], jobs[idx][0]});
idx++;
continue;
}
if(!PQ.empty()){
time += PQ.top().first;
answer += time - PQ.top().second;
PQ.pop();
}
else{
time = jobs[idx][0];
}
}
return answer / length;일단 현재 시간 시점을 0, 인덱스도 0으로 둔다. 가장 초기 상태에서부터 시작하게 된다.
우선 PQ에 1번 인덱스 먼저 넣는 이유는 PQ가 마냥 vector 기반이었으면 모르겠지만 pair 데이터에 대해서는 뒷부분의 데이터를 기준점으로 Heapify를 하기 때문이다.
if(idx < length && time >= jobs[idx][0]){
PQ.push({jobs[idx][1], jobs[idx][0]});
idx++;
continue;
}어쨌든 현재 보고있는 데이터가 현재 시점의 시간보다 이전에 있다면, 즉 일을 시작할 수 있는 데이터라면 우선순위큐에 집어넣는다.
if(!PQ.empty()){
time += PQ.top().first;
answer += time - PQ.top().second;
PQ.pop();
}
else{
time = jobs[idx][0];
}그리고 PQ에 데이터가 있다면 PQ의 Top 데이터 기준으로 실행 시간을 갱신한다. 해당 데이터의 실행시간 만큼 시간이 갱신되었고 answer에는 총 시간이 저장되어야하니까 시작시간을 빼 준 다음 저장한다.
만약 PQ가 비어있다면 자연스럽게 현재 시점의 데이터의 시작시간으로 time은 갱신된다.
이걸 length 까지 탐색을 마칠때까지 한다. PQ는 가끔 empty상태가 되기야 하겠지만 index 값은 length까지 다 처리를 해야 마칠 수 있다.
우선순위큐를 써야하는 것은 이해하고있지만 쉽게 처리하기 힘들었던 문제였다.
