1장. 자바 시작하기
- JAVA는 플랫폼 독립성을 가짐
⇒ 자바의 실행파일 .class가 JVM을 사용하여 어떤 운영체제로도 실행이 가능
몇 개의 클래스가 존재하든 최대 1개의 클래스만 public을 포함할 수 있음.
- 컴파일 후 생성되는 바이트 코드
ex) class A{} → A.class
ex) class C{class D{}} → C$D.class // D는 C의 이너클래스 이기 때문
System.out.println() → 실행 후 줄바꿈
System.out.print() → Just실행 (줄바꿈 X)
System.out.printf() → &d,&o,&x,&f,%s 등 사용
%d → 10진수
%o → 8진수
%x → 16진수
%f → 실수
%s → 문자열2장. 자료형
변수,상수,메서드의 이름일 지을 때 지켜야할 공통사항
1. 영문 대소문자와 한글 사용 가능
2. 특수문자는 밑줄(_), 달러($)만 표기 가능
3. 아라비아 숫자 가능 , 단 첫 글자로는 X
4. 자바에서 사용하는 예약어 X이름을 지을 때 지키면 좋은 권장 사항
1. 변수명
- 영문 소문자로 시작
ex) avg, name, value
- 영문 단어를 2개 이상 결합할 시 새 단어의 첫 글자를 대문자로 한다.
ex) int ourClassNum;
2. 상수명
- 모두 대문자로 표기
- 단어가 여러개 결합하면 밑줄 사용하여 분리
ex) final int MY_DATA;
3. 메서드명
- 변수명과 같음.자료형의 종류
1. 기본 자료형
- 참, 거짓 → boolean
- 정수 → byte, short, int, long
- 실수 → float, double
- 문자(정수) → char
2. 참조 자료형
- 객체 : Object → 배열, 클래스, 인터페이스
* 참조 자료형의 이름은 대문자로 시작
ex) String, System, …자바에서는 대입 연산자(=)를 중심으로 양쪽의 자료형이 똑같아야 함.
3장. 연산자
- 산술 연산자 ( +, -, *, /, %)
정수/정수 → 몫
정수%정수 → 나머지 (‘모듈로 연산’)- 증감 연산자 (++, --);
int a1 = 3;
int b1 = ++a1;
System.out.println(a1); → 4
System.out.println(b1); → 4
int a2 = 3;
int b2 = a2++;
System.out.println(a2); → 4
System.out.println(b2); → 3- 비트 연산자 ( &, |, ^, ~)
AND(&) → 1, 1 이면 1
OR( | ) → 0, 0이면 1
XOR(^) → 0, 1 or 1, 0이면 1
NOT(~) → 1이면 0, 0이면 1
값의 첫 번째 비트는 부호비트임.
0 : 양수, 1 : 음수
따라서 NOT 연산자를 수행하면 항상 부호가 바뀜.- 시프트 연산자 ( <<, >>, >>>)
산술 시프트
숫자의 부호 비트는 유지하면서
나머지 비트를 왼쪽(<<) 또는 오른쪽(>>)으로 이동하는 연산자.
<< → x2의 효과가 있음. 이 때 빈칸이 오른쪽으로 생기며 0으로 빈칸을 채움.
>> → ÷2의 효과가 있음. 이 때 빈칸이 왼쪽으로 생기며 부호 비트값과 동일한 값으로 빈칸을 채움.
시프트 연산 결과
<< : 양수, 음수 → 1 bit 시프트당 x2, 부호 유지
ex) 3<<1 = 6
-3<<1 = -6
>> : 양수 → 1 bit 시프트당 ÷2, 부호 유지, 소수 **버림**
ex) 5>>2 = 1
음수 → 1 bit 시프트당 ÷2, 부호 유지, 소수 **올림**
ex) -5>>2 = -2논리 시프트
>>> → 부호 비트를 포함해 전체 비트를 오른쪽으로 이동, 빈칸은 모두 0으로 채움.
- 비교 연산자 (>, <, ≥, ≤, ==, ≠)
= 는 항상 오른쪽에 위치함
자바에서는 불리언값(true, false)으로 출력됨.- 논리 연산자 (&&, || , ^, !)
XOR 연산자는 모두 기호 ^를 사용함
정수^정수 → 비트 연산자
불리언^불리언 → 논리 연산자
비트 연산자와 매우 비슷하지만, 피연산자로 불리언값(true, false) 만 가능.논리 연산자와 비트 연산자는 둘 다 논리연산을 수행할 수 있음.
→ 차이점은 쇼트 서킷의 적용 여부.
쇼트 서킷 : 결과가 이미 확정됐을 때 나머지 연산 과정을 생략.
ex) (5 > 3) || (3 < 2) 일 때 (3 < 2)를 읽지도 않음.
논리 연산자 → 쇼트 서킷 적용 O
비트 연산자 → 쇼트 서킷 적용 X
결과엔 영향을 미치지 않으므로 논리연산의 결과는 같음.- 대입 연산자 ( = )
+=, -=, *=, %=, /=, <<=, >>=, >>>=
- 삼항 연산자 (?)
( true or false ) ? 참 : 거짓
ex) int a = (true) ? 1 : 2; → a=1
int b=(a % 2 ==0) ? 10 : 20; → b=204장. 제어문과 제어 키워드
제어문 : 프로그램의 처리 순서를 바꾸는 것
- if 선택 제어문
if( 3 > 5 ) { System.out.prinfln(”실행1”); // 실행 X System.out.prinfln(”실행2”); // 실행 X } if( 3 > 5 ) System.out.prinfln(”실행1”); // 실행 X System.out.prinfln(”실행2”); // 실행 O
else if 구문의 개수는 상관 X
else는 모든 조건식이 false일 때 실행
if문은 처음 참이 되는 블록 하나만 실행됨
- switch 선택 제어문
특정 위치( case )로 이동해 구문을 실행하는 선택 제어문
switch(점프 위치 변수)
{
case 위칫값 1:
실행 구문;
case 위칫값 2:
실행 구문;
case 위칫값 n:
실행 구문;
default: // 일치하는 위칫값이 없을 때 이 위치로 이동 (생략 가능)
실행 구문;
}switch문은 조건식이 true인 위치 이후의 case들을 전부 실행
break문을 사용하여 제어 가능.
int a = 8;
switch(a) {
case 10:
case 9:
case 8:
System.out.println(”출력”); // a가 8이상인 값은 모두 출력 가능.
default:
System.out.prinfln(”출력”); // 출력 X- for 반복 제어문
컴파일러는 문법적으로 for문의 소괄호 안에 세미콜론(;)이 2개 있는지만 점검함.
초기식의 포함된 변수의 선언 위치
int i;
for(i=0; i<3; i++) {
System.out.println(”실행”);
}
System.out.println(i); // 3조건식이 생략되면 무한루프가 일어남
- while 반복 제어문
주의 : 초기식을 중괄호 안에 넣으면 매 반복마다 초기화돼 원하지 않는 무한루프에 빠질 수 있음.
while문에서는 조건식을 생략할 수 없다.
무한루프 사용법
while(true) - do-while 반복 제어문
초기식;
do { // 최초 1회는 무조건 실행.
실행 구문;
증감식;
} while(조건식); ← 세미콜론 꼭 쓰기일단 do 구문을 실행한 이후 조건식을 검사함.
true → 다시 do 구문 실행
false → 제어문 탈출
주의 : do-while구문이 while구문보다 1번 더 실행하는 것이 절대 아님. 동일하게 실행.
- break 제어 키워드
break를 이용해 탈출하는 것은 if 문을 제외한 가장 가까운 중괄호 하나임.
break로 다중 반복문을 한 번에 탈출하는 법
break + Lable(레이블)
레이블명은 개발자가 임의로 지을 수 있음.
out: ← 레이블 위치 지정(break하고자 하는 반복문 앞에 레이블 표기) + 콜론 표기
for( int i=0; i<10; i++)
{
for( int j=0; j<10; j++)
{
if(j==3) break out; ← out 레이블이 달린 반복문 탈출
System.out.println();
}
} ← break out으로 탈출하는 중괄호- continue 제어 키워드
continue는 주로 반복 과정에서 특정 구문을 실행하지 않고 건너뛰고자 할 때 사용함. (주로 if와 함께 사용)
for(int i=0; i<10; i++) {
if( i == 5 ) {
continue;
}
System.out.println(i); // 0, 1, 2, 3, 4, 6, 7, 8, 9
}* continue + Lable 문법 사용 가능
5장. 참조 자료형
- 배열
자바에서 8개의 기본 자료형 이외의 모든 자료형은 참조 자료형임
ex) 배열, 클래스, 인터페이스
배열 : 동일한 자료형을 묶어 저장하는 참조 자료형
1) 생성할 때 크기를 지정
2) 한 번 크기를 지정하면 절대 변경할 수 없음
3) 배열을 선언하면 스택 메모리에 변수의 공간만 생성
참조 자료형의 실제 데이터(객체)는 힙 메모리에 생성
⇒ new 키워드 사용
- 배열의 객체 생성
→ new 자료형 [배열의 길이]
new int[3]; // 정수 자료형 3개를 포함할 수 있는 배열 객체 생성
new double[5]; // 실수 자료형 5개를 포함할 수 있는 배열 객체 생성
new String[10]; // 문자열 자료형 10개를 포함할 수 있는 배열 객체 생성
new int[]; // error 객체의 크기를 지정하지 않아 오류 발생자료형[] 변수명 = new 자료형 [배열의 길이]; 스택 메모리(변수) 공간은 값을 초기화하지 않으면 빈 공간으로 존재
힙 메모리(객체)는 어떤 상황에서도 빈공간이 존재하지 않음
값을 주지 않으면 컴파일러가 값을 강제로 초기화함
숫자는 0, 불리언은 false , 이외의 모든 참조 자료형은 null
Arrays.toString(배열 객체)을 이용하면 배열의 모든 원소를 한번에 출력 가능
(단, import java.util.Arrays; 를 꼭 사용해야 함)- 배열의 길이
‘배열 참조 변수.length’ 로 배열의 길이를 구할 수 있음
int a[] = new int[] {3,4,5,6,7};
System.out.println(a.length); // 5- for-each 문
: 배열이나 컬렉션 등의 집합 객체에서 원소들을 하나씩 꺼내는 과정을 반복하는 구문
→ 집합 객체의 원소들을 출력할 때 사용
for(원소 자료형 변수명 : 집합 객체)
{
}ex)
int a[]=new int[100];
a[0]=1, a[1]=2, …, a[99]=100;
for(int k: a) {
System.out.println(k);
}- 2차원 정방 행렬 배열
: 직사각형의 형태 (모든 행의 길이가 같은 배열)를 띤 배열
ex)
int[][] a= new int[2][3];메모리는 2차원 데이터를 바로 저장할 수 없다
→ 1차원 배열을 원소로 포함하고 있는 1차원 배열
- 2차원 비정방 행렬 배열
: 각 행마다 열의 길이가 다른 2차원 배열
int[][] a= new int[2][3];와 같은 방법은 항상 정방 행렬만 생성하므로 사용할 수 없음
2차원 비정방 행렬 배열 생성법
1) 배열 객체의 행 성분부터 생성 후 열 성분 생성하기
int [][]a = new int [2][];
a[0]=new int[2]; // 첫 번째 행의 열의 개수
a[0][0]=1; a[0][1]=2;
a[1]=new int[3]; // 두 번째 행의 열의 개수
a[1][0]=3; a[1][1]=4; a[1][2]=5;or
int[][] a= new int[2][];
a[0]=new int[]{1,2};
a[1]=new int[]{3,4,5}; * 비정방 행렬은 배열의 길이에 주의를 기울여야 함
2) 자료형과 대입할 값만 입력하기
int[][] a = new int[][] {{1,2},{3,4,5}};3) 대입할 값만 입력하기
int [][] a = {{1,2},{3,4,5}};- 2차원 배열의 출력
→ 2개의 인덱스를 사용하므로 기본적으로 이중 for문을 사용함
바깥쪽 for문은 행의 개수인 a.length를 사용
안쪽 for문은 열의 개수인 a[i].length를 사용
- main() 메서드의 입력매개변수
→ 자바 코드를 실행하면 JVM은 가장 먼저 main() 메서드를 실행함
입력매개변수가 String이면 모든 원소가 문자열로 인식됨
String + int = String
int + int = int
int + double = double- 타입 변환 메서드
문자열 → 정수 : Integer.parseInt(문자열)
문자열 → 실수 : Double. parseDouble(문자열)
정수 → 문자열 : String.valueOf(정수)
실수 → 문자열 : String.valueOf(실수)-
문자열의 표현과 객체 생성
String a = “문자열”;
String 클래스의 2가지 특징
1) 한 번 정의된 문자열은 변경할 수 없다
2) 문자열 리터럴을 바로 입력해 객체를 생성할 때 같은 문자열끼리 객체를 공유함 (메모리의 효율성을 위해)
ex)
String str1 = “안녕”;
String str2 = “안녕”;
→ 힙 메모리에 리터럴로 생성된 동일 문자열을 포함한 객체가 있으면 그 객체를 공유함
반면에 new String(”안녕”)은 동일하든 말든 항상 새로 생성
→ 메모리 낭비
- String 클래스의 주요 메서드
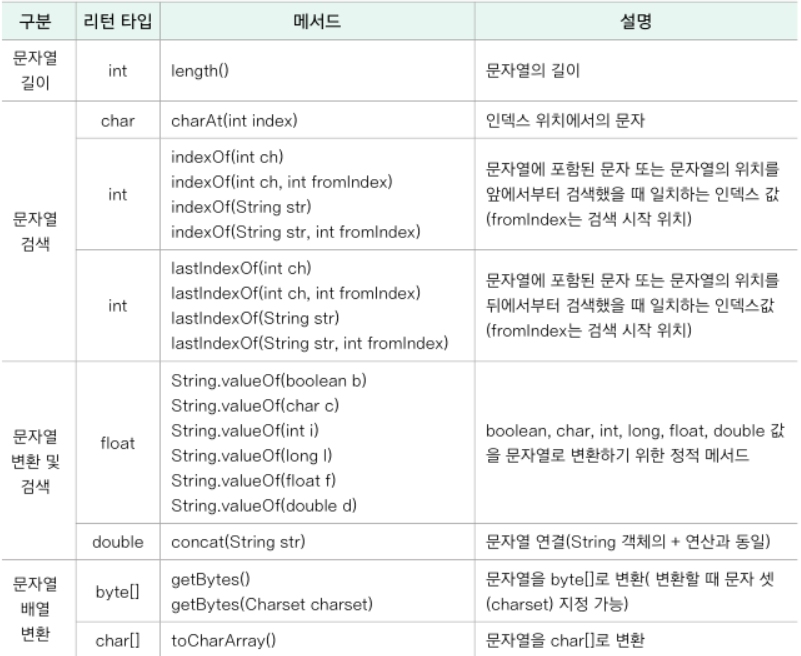
length() → 문자열의 길이 리턴
charAt() → 문자열에서 특정 인덱스에 위치해 있는 문자를 알아냄
indexOf() → 문자열에서 특정 문자나 특정 문자열을 앞에서부터 찾아 위칫값을 알아냄
lastIndexOf() : 문자열에서 특정 문자나 특정 문자열을 뒤에서부터 찾아 위칫값을 알아냄
String.valueOf() → 기본 자료형을 문자열로 바꾸는 정적메서드
getBytes() → 문자열을 byte배열로 변환 (자바 입출력 과정에서 주로 사용)
toCharArray() → 문자열을 char형 배열로 변환 (자바 입출력 과정에서 주로 사용)
toLowerCase() → 영문 문자를 모두 소문자로 변환
toUpperCase() → 영문 문자를 모두 대문자로 변환
replace() → 일부 문자열을 다른 문자열로 대체
substring() → 문자열의 일부만을 포함하는 새로운 문자열 객체 생성
split() → 특정 기호(|)를 기준으로 문자열을 분리
trim() → 문자열의 좌우 공백을 제거
equals() → 두 문자열의 위칫값이 아닌 실제 데이터값 비교 대소문자 구분 O
equalsIgnoreCase() → 대소문자 구분 X