상황
서버의 로그인 기능 구현 부분에서 프론트로부터 소셜 로그인이 완료된 유저의 oauthId와 개인 정보 등이 넘어오고 있는 상황이다.
로직 중 일부인 이미 회원가입이 된 유저인지 확인하기 위해 oauthId를 조건으로 유저를 조회했다.
기존
Data JPA를 통해
Optional<User> findByOauthId(String oauthId); 유저 엔티티를 조회
실행되는 쿼리
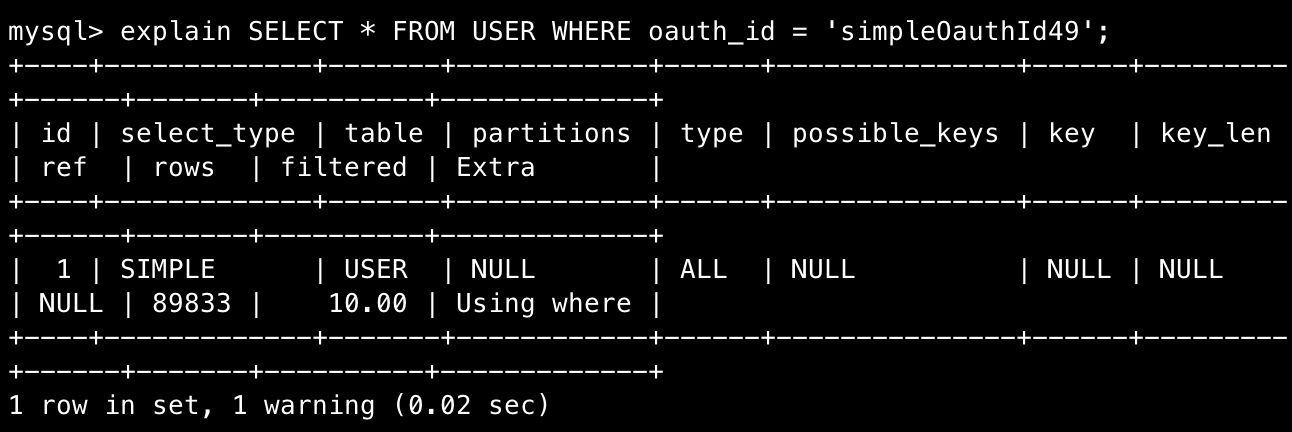
SELECT * FROM USER WHERE oauth_id = '유저의 oauthId'평소였으면 그냥 조회만 되겠거니 생각했겠지만, 현재 진행하는 프로젝트에서는 대용량 트래픽 상황 및 많은 유저가 있는 상황을 가정하고 진행하고 있기 때문에 꼼꼼히 고려 중이다.
현재는 유저 데이터 자체가 매우 적기 때문에 문제가 되지 않는다. 하지만 만약 10만명의 유저가 있는 서비스라면?이렇게 조회를 했을때 유저 별로 oauthId가 전부 다를텐데 그러면 full scan이 일어나서 서비스에 큰 지장을 주게 된다.
기존 상황의 성능을 테스트 하기 위해 유저 10만명 데이터를 통해 확인해보자.
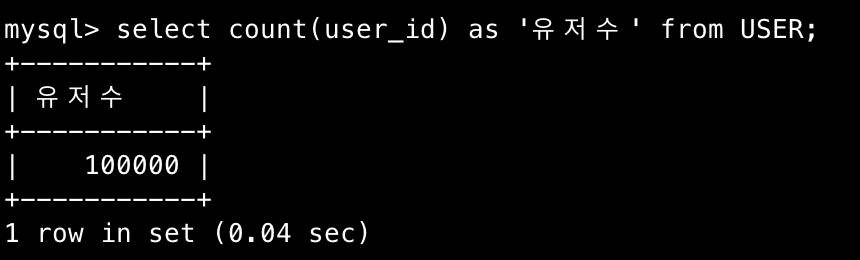
explain 결과
89833개의 row를 스캔한다.
실행
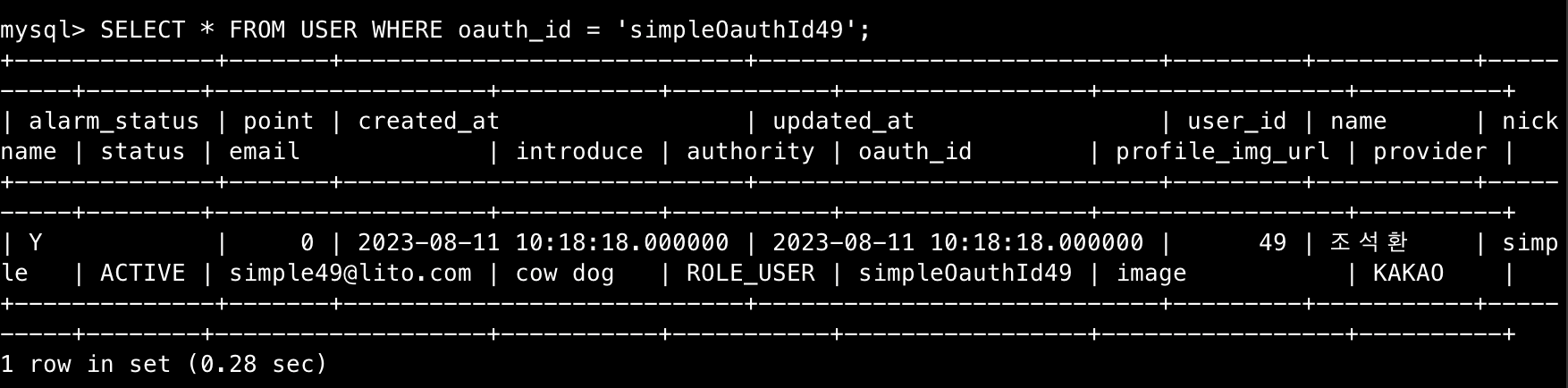
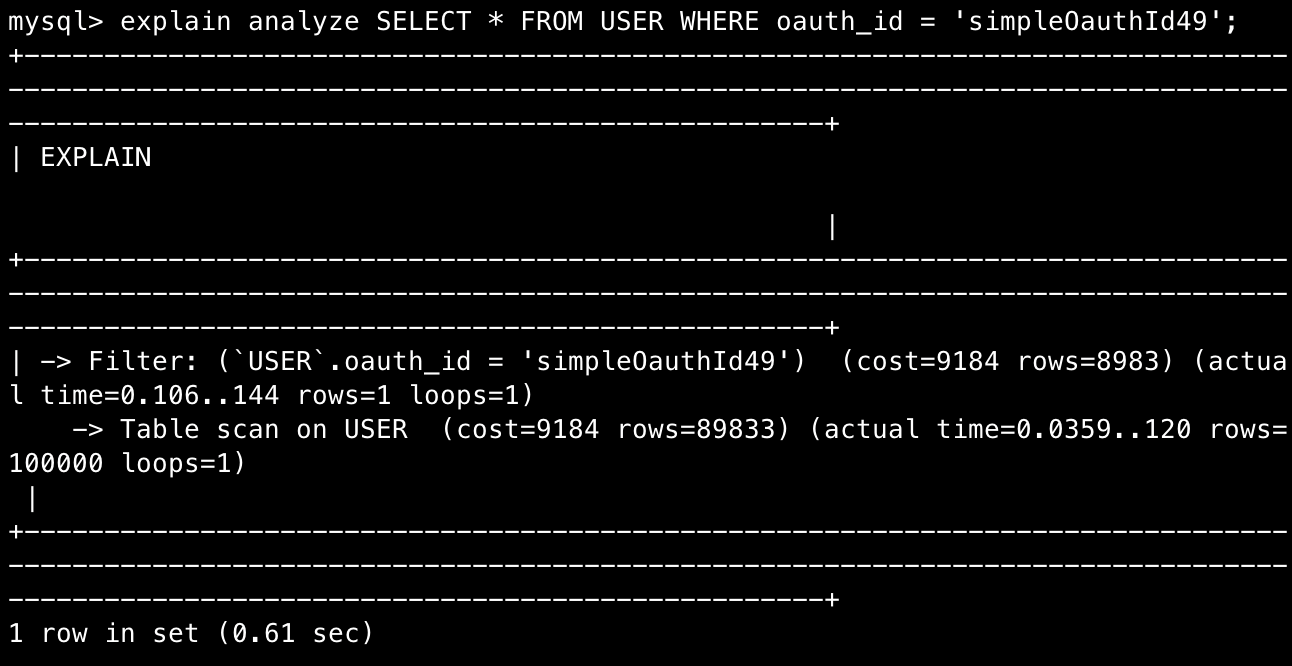
explain analyze 결과
개선 후

변경된 점
- 복합 인덱스 생성
- 기존 oauthId 조건 만으로 검색 ⇒ provider까지 조건으로 추가함으로써 유저 데이터의 고유성을 보장(카카오와 애플의 oauth_id 생성 방식은 지금은 다르지만 나중에 어떻게 될지 모르므로)
Data JPA를 통해
Optional<User> findByOauthIdAndProvider(String oauthId, Provider provider); 유저 엔티티를 조회
실행되는 쿼리
SELECT * FROM USER WHERE oauth_id = '유저의 oauthId' AND provider = '소셜 로그인 제공 주체'explain 결과

실행 결과
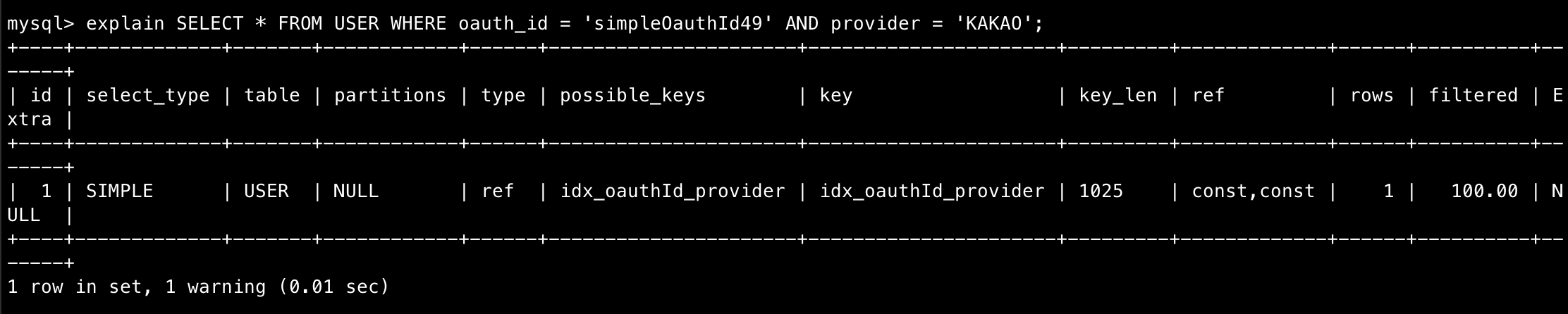
explain analyze
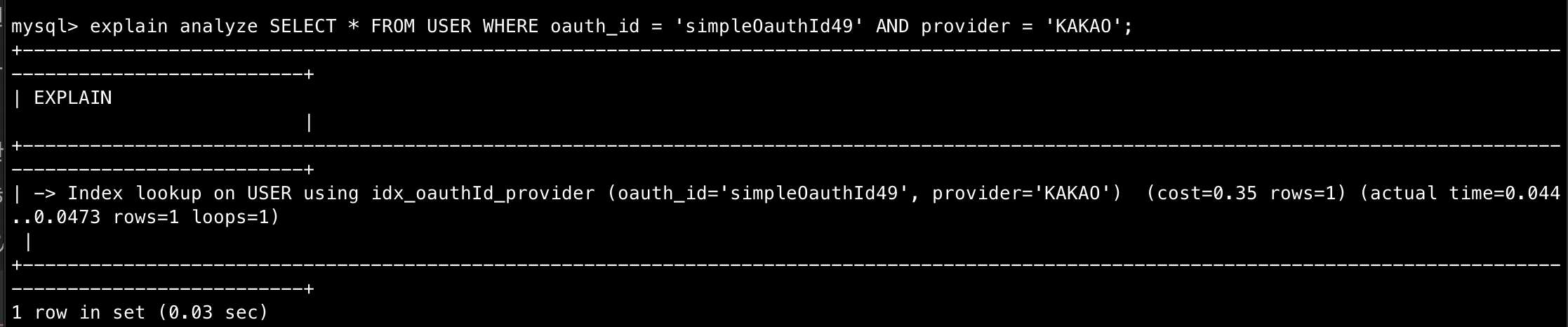
쿼리 실행 시간 280ms → 10ms 약 28배 향상,
예상 실행 시간을 explain analyze로 알게된 결과는
9.184초 → 0.00035초로 26,240배의 cost 차이를 예상할 수 있다.(어디까지나 통계적인 예상이다.)
여기서 한 가지 궁금한 점이 생기는 사람이 있을 수 있다.
WHERE절에 조건이 2개인데, 그러면 어떤 컬럼 순서로 복합 인덱스를 생성하는지도 중요한가? 라고 생각했다면 정답이다.
복합 인덱스 생성의 컬럼 순서는 디스크 I/O를 가장 적게 발생시키는 규칙을 가지고 순서를 구성하면 된다.
디스크 I/O가 적게 발생이 되려면 카디널리티가 높을수록 좋다.
예를 들어보자,
현재 프로젝트의 소셜 로그인 provider는 kakao와 apple 단 2개만 있다.
하지만 oauth_id는 유저마다 전부 다르다.(카카오와 apple의 oauth_id 생성 방식이 다르므로)
그렇기 때문에 복합 인덱스 생성시 oauth_id의 순서가 앞에 있는 것이다.
카디널리티가 높은 순서로 복합 인덱스 생성의 순서 정하기
만약 위 규칙을 지키지 않고 생성했다면?
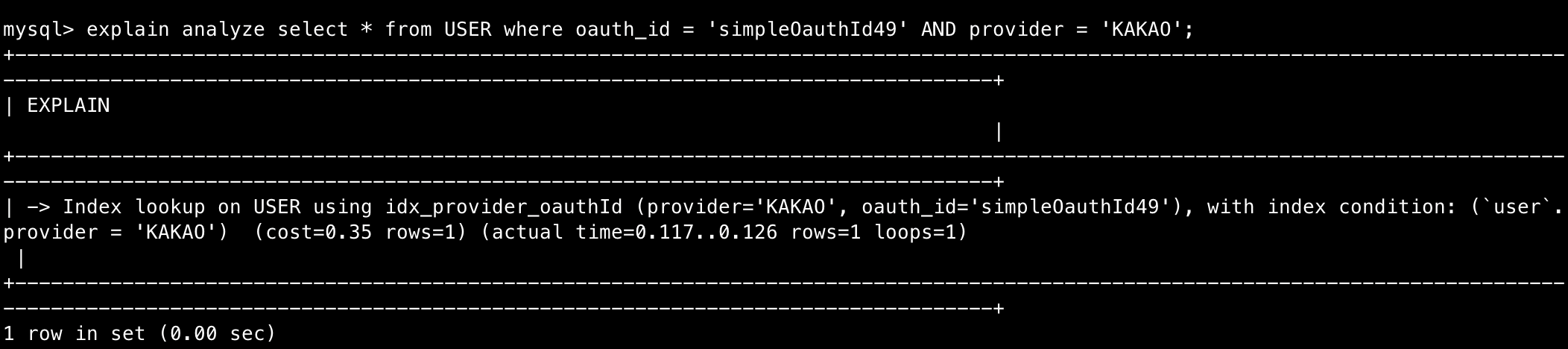
인덱스 명을 보면 알 수 있듯이 이전과 provider와 oauthId의 순서가 바뀌었고 그 결과 0.04초가 걸리던 쿼리가 0.117초로 약 3배나 예측 시간이 증가한 것을 알 수 있다.
응답 테스트
postman을 통해 api의 응답 시간을 테스트해봤다.
인덱싱 적용 전
제일 낮게 나온 값: 629ms
제일 높게 나온 값: 776ms
여러 차례 테스트한 값:
650, 629, 631, 701, 644, 689, 721, 712, 640, 776
평균: 679.3ms
인덱싱 적용 후
제일 낮게 나온 값: 47ms
제일 높게 나온 값: 61ms
여러 차례 테스트한 값:
66, 59, 62, 68, 77, 56, 55, 61, 55, 47
평균 60.6ms
=> 응답시간 약 11배 향상
주의할 점은 인덱싱을 생성한다고 무조건 좋은건 아니다.
- 삽입,수정,삭제가 빈번하지 않아야 한다.(즉, 조회에 많이 사용된다.)
- 카디널리티가 높을 수록 좋다.
이 외에도 여러 가지 인덱싱 설계 방법이 있으니 더 필요할 경우 추가적으로 찾아보면 도움이 된다.
결론
- 쿼리의 실행 계획을 통해 나의 쿼리가 문제 없이 잘 작동하고 있는지 확인하기
- 성능에 대한 테스트는 꾸준히
- 인덱스 설계의 중요성

좋은 글 감사합니다. 자주 올게요 :)