2일차에는 오라클 이론 수업과 문자열과 숫자형 데이터타입의 비교에 대해 학습했습니다.
오라클 이론
Mulit Tenancy는 단일 인스턴스를 가지고 여러 개의 서비스를 제공하는 것을 의미합니다.
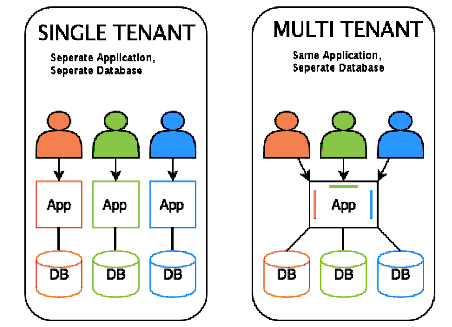
사진출처 : https://m.blog.naver.com/ki630808/221778753901
OOP : 객체 지향 프로그래밍을 의미합니다.
오라클 12c 부터는 멀티태넌시를 지원하면서 Plug In, Out 기능이 가능해졌습니다. 예를들면 인사 시스템을 잠시 멈춘다고 가정하면 최신정보는 메인 시스템에 동기화가 되어 있기 때문에 참조만 하면 됩니다.
오라클의 특징
오라클은 Non DBA DBMS라는 사명을 가지고 출발했습니다. 이런 오라클의 마인드를 다른 말로 하면 Self Managed DB라고도 불렀습니다. 말을 해석하자면 DBA가 없이도 스스로 움직이고 관리될 수 있는 DB를 제작하는 것을 모토로 오라클은 시작된 것입니다.
관계형(Relational) DB
관계형 DB는 쉽게 말하자면 Excel과 같이 테이블 형태로 데이터를 저장하는 것을 관계형 DB라고 합니다. 현재의 오라클과 옛날의 오라클의 차이는 현 오라클은 램 중심의 서비스를 하는 형태로 변화하였습니다.(속도 저하의 해결책으로 램을 활용하기 시작하였습니다.)
현재 오라클은 객체 성향이 강합니다. 여기서 ORDB는 객체 관계 DB라고 합니다.
Grid Computing은 분산 병렬 컴퓨팅의 한분야로 컴퓨터들을 하나로 묶어 대용량 처리를 수행하는 것을 의미합니다. 오라클 11c부터는 맞춤형 서비스를 제공하겠다 하여 Grid Computing을 제공하기 시작했습니다.
테이블 단위의 명령(DDL)은 커밋 없이 진행되기 때문에 ROLLBACK이 불가능합니다. 따라서 DDL명령어를 사용할 때는 주의가 필요하며 항상 백업을 해주고 작업을 진행해야합니다.
SQL문의 실행순서는 아래와 같습니다.
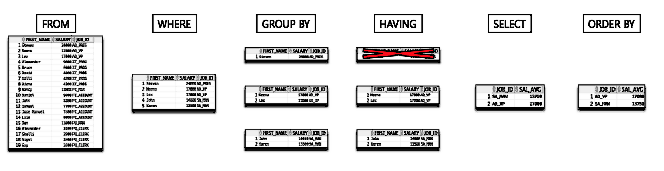
FROM절 -> WHERE절 -> GROUPY BY절 -> HAVING절 -> SELECT절 -> ORDER BY절 순서로 진행됩니다.
!!SQL문 작성 팁!!
- Driving Table은 FROM 절의 제일 왼편에 작성한다!
- WHERE 절의 처음에는 테이블 간의 JOIN 관계를 먼저 작성한다.
- Driving Table부터 필터링 조건을 기술합니다!(Driving Table의 모순을 줄여줍니다.)
- WHERE 절의 조건 기호 중 =의 왼편은 가공하면 안된다!
- ORDER BY는 질의문의 맨 마지막에 한 번만 작성합니다.
SQL Plan에 대해서
작업 환경은 Toad 입니다!!!
SQL문을 CTRL+e 키를 누르면 Plan을 확인할 수 있는데 아래과 사진과 같이 원하는 형태로 플랜을 확인할 수 있습니다.
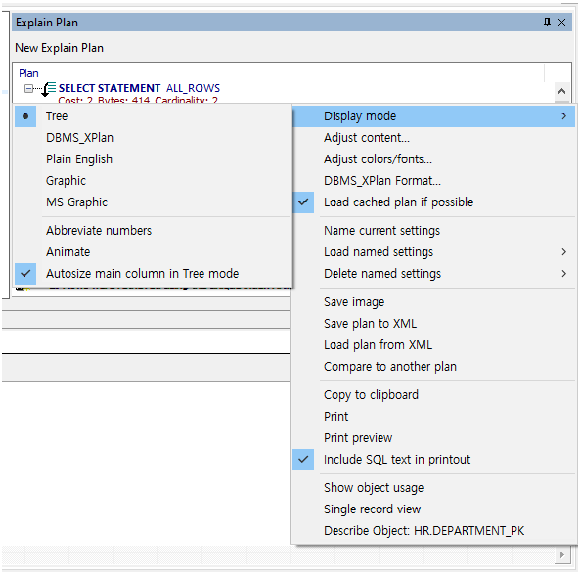
※오라클 SQL문 작성법에는 종래 오라클 스타일과 ANSI 표준 질의문 스타일이 있습니다. 둘의 차이는 조인을 걸어서 조회를 하는지 아닌지의 차이가 있습니다. 종래 오라클 스타일이 조인을 사용하지 않고 = 을 사용하여 두 테이블을 조회하는 방법입니다.
PLAN을 해석하는 방법
Cardinality는 어떤 집합에 부속되어 있는 공통된 원소의 갯수를 의미합니다.(이 단계에서 결과 값으로 예상되는 행수를 의미합니다.) -> 쉽게 이야기하면 교수는 1명 학생은 2명 이런식으로 반환합니다.(집합 중 공통된 특정의 원소들을 카디널리티라고하 합니다.)
COST는 결과값을 가져오는데 에너지의 총합을 의미합니다. COST가 0인 SQL은 존재할 수가 없지만 가끔 플랜을 확인하면 중간 중간에 COST가 0인 것을 확인할 수 있습니다. 아때 0으로 표기가 되는 이유는 COST가 상수로 표기되다 보니 0.1-0.4까지 반올림하면 0이 되기 때문에 0으로 표기가 되어 보이는 것입니다.
Rowid, ROWNUM
- Rowid
실제 자료가 들어있는 레코드의 물리적 주소를 가리키는 포인터입니다.
Rowid에 의한 한 행 접근은 무조건 COST가 1, 결과값이 1입니다. 이 방법은 관계형 DB에서 레코드를 가장 빨리 찾을 수 있는 확실한 방법을 의미합니다. 다만 암호화가 되어 있어서 사람이 알기 힘들다는 단점이 있습니다. 따라서 대부분의 사용자가 PK를 통해 접근할려하는데 이런 방법을 한 행의 접근 방법이라고 합니다. 물론 Rowid를 통해 접근하는 방법도 마찬가지로 한 행의 접근 방법이라고 합니다.
Rowid는 Pseudo 코드 즉, 의사컬럼이라고도 하며 rowid, rownum, by cval등이 의사컬럼에 속합니다.
SELECT rowid, s.*
FROM Student s
WHERE deptno = 101
;- ROWNUM
의사(의심스러운데 사용되는)코드로 없는 것을 있는 것처럼 표현하는 것을 의미합니다. 자료사전에 저장이 되어 있습니다. 자료사전은 DB의 엔진부분에 있습니다.
옵티마이저
위에 Rowid를 사용하면 COST를 1로 한 행 접근이 가능하다고 설명했는데 여기서 더 실행시간을 줄일 수 있는 방법이 있습니다. 바로 옵티마이저를 사용하는 것입니다. 옵티마이저는 오라클 엔진을 의미합니다.(실제적으로 데이터를 찾고 Plan을 짜는 엔진 부분을 옵티마이저라고 합니다.) 옵티마이저는 최적화(Not Best But Not Worst(최고의 방법은 아니지만 최악을 피하는 방법))방법을 사용합니다.
Hint
Hint를 사용하면 SQL문이 더 빠르게 작동하도록 하는 방법입니다. Hint 주석으로 작성하여 인덱스처리를 해주어 SQL문의 성능을 튜닝하는 방법입니다. 즉, 풀어서 해석하자면 오라클에게 사용자가 직접 권고안을 제공하는 것입니다. 주석문의 일종이기 때문에 문법의 유효성을 체크하지 않으며 또한, 강제성이 없습니다. 강제성이 없다는 것은 말이 안되는 Hint문은 오라클이 자체적으로 판단하여 힌트를 사용하지 않습니다.
- 사용 문법은 --+ Hint 또는 /+ Hint /가 있습니다.
예제 문법은 아래와 같습니다.
Select /*+ INDEX(p professor_pk)
INDEX(e department_pk) */
STUDNO 학번, s.NAME 성명, GRADE 학년, s.SEX 성별
, HEIGHT||'cm' 키
, Case When s.SEX = 'M' Then s.WEIGHT||'kg'
When s.SEX = 'F' Then '***'||'kg'
else ' '
END AS 체중
, s.DEPTNO||'-'||d.dname 소속학과
, s.PROFNO||'-'||p.NAME 지도교수, p.POSITION 직책
, d.COLLEGE||'-'||e.dname 소속학부
From Student s -- Driving Table
, Department d -- 1차 Driven
, Professor p -- 2차 Driven
, Department e
Where s.deptno = d.deptno(+)
And s.profno = p.profno(+)
And d.COLLEGE = e.DEPTNO(+)
And s.deptno = 101 -- 컴퓨터공학과
;
힌트를 사용할 때의 규칙 -> 인덱스의 힌트일 경우 INDEX(별칭 테이블명_pk)
SELECT 사용시 주의사항
- 질의문의 한 줄에는 되도록이면 단수의 의미를 갖도록 한다.
- 왼쪽(명령을 기술하는 부분)은 오른쪽 정렬을 해주고
- 오른쪽 그룹(아규먼트 기술부분)은 왼쪽으로 정렬을 해주어서
- 가운데에 터널이 생기도록 배치한다.
- 블록별로 들어가고 블록별로 나오는 구조를 띄도록 해야 한다.
- 질의문의 Plan(Ctrl + E)을 조회함으로 동작원리를 이해하도록 한다.
WHERE 사용시 주의사항
- 1차 필터링 : 레코드 단위 필터링 , 레코드 중에서 내가 원하는 것만 조회
- 학생중에서 컴퓨터공학과 학생만 조회해라.
Where deptno = 101 - 문자는 ' '안에 넣어서 표시하고 숫자는 그대로 표시
- 학생중에서 컴퓨터공학과 학생만 조회해라.
- 2차 필터링은 : Group By 이후에 집계된 결과에 대한 필터링
- 학과별로 집계한 후에 인원이 5명 이상인 학과만 모아라
Group By HAVING Count(*) > 5
- 학과별로 집계한 후에 인원이 5명 이상인 학과만 모아라
문자형 데이터 타입 비교
CHAR와 CHAR를 비교시에 오라클은 넓은쪽으로 맞춥니다. CHAR와 VARCHAR을 비교하면 CHAR가 더 크다고 나옵니다.
문자 상수와 CHAR을 비교하면 CHAR와 CHAR 비교 방식으로 비교(긴쪽으로 맞춘다.)하고 문자 상수와 VARCHAR을 비교하면 VARCHAR2와 VARCHAR2 비교 방식에 의해 비교(짧은 쪽으로)한다.
오라클은 DATE타입을 7비트 고정길이(숫자형)필드에 저장합니다.
오라클은 블록단위로 처리하고 한 블럭당 용량은 8kb입니다. 세그먼트는 블럭을 뭉쳐놓은 것을 의미합니다.
※crlf란, \c, \r을 의미합니다. \c는 캐리지리턴값으로 하나의 레코드의 끝을 의미하고 \r은 줄바꿈을 의미합니다.
Analys
테이블 analys는 토드에서 레코드 갯수를 분석해서 결과값을 알려줍니다. 분석(Analys)은 오라클이 테이블에 관련한 기본 통계자료를 모으는 작업을 의미하고 해당 작업을 수행하는 이유는 오라클은 통계값을 갱신함으로 처리속도를 올릴 수 있기 때문입니다.
해당 작업을 해주는 이유는 조회 속도의 향상을 위해 해주는 작업입니다.
HASH는 정보를 고르게 펴주는 역할을 합니다.(mod4를 사용하여...)
세그먼트는 메모리를 뭉쳐 놓은거고 클러스터는 관계를 가지고 포인터에 의해 뭉쳐져있는 것을 의미합니다. 즉, 관계가 있는 것을 클러스터라고 합니다.
예시코드 :
BEGIN
SYS.DBMS_STATS.GATHER_TABLE_STATS (
OwnName => 'HR'
,TabName => 'CAL_CO_MAST'
,Estimate_Percent => SYS.DBMS_STATS.AUTO_SAMPLE_SIZE
,Method_Opt => 'FOR ALL COLUMNS SIZE AUTO '
,Degree => NULL
,Cascade => DBMS_STATS.AUTO_CASCADE
,No_Invalidate => DBMS_STATS.AUTO_INVALIDATE
,Force => FALSE);
END;
/
analyze를 자주 하면 할 수록 좋다. 단, 단점은 기존에 Plan 짜놓은 경로가 꼬일 수 있다 라는 단점이 있습니다.(15%~20%이상을 모아야합니다.)
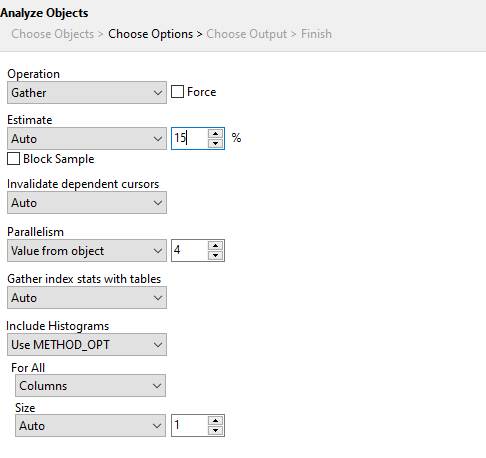
분석을 진행할 때 이런식으로 옵션을 설정할 수 있고 현재 커서가 있는 곳에서 퍼센테이지를 조절해서 15이상 모아주면 됩니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
