1. 데이터 수집
ai hub 에서 다운로드
라벨링 데이터와 모델을 학습시키는 코드까지 모두 다운.
2. path 바로 잡기
코드를 대충 보자. 이 부분은 뭔가 작업이 필요할 것 같다.
data_train_path = './train_data/' + train_name + '/train'
data_validation_path = './train_data/' + train_name + '/validation'
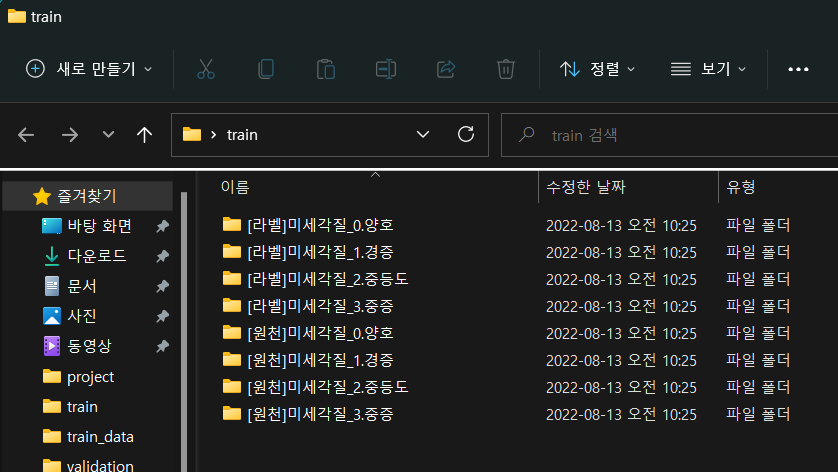
data_test_path = './train_data/' + train_name + '/test'/면 폴더 경로 같은데 암튼 이런거 배운 적 없다. 하지만 구글링이 있으니까 안심하자. 일단 path 니까 트레인, 벨리, 테스트 셋 파일의 경로를 잡아주는 것 같다. 하지만 이런식으로 경로를 변수로 잡아주는 건 처음본다. 정확히 무슨 의미인지 이해하기 힘들다. 특히 + train_name + 이건 뭐지? 오픈톡방에 물어본다. 대답은 이렇다. 처음 적힌 점은 코드파일이 담긴 현재폴더라는 의미이고 그 다음 train_data 폴더 > train_name 이 abc라면 abc 폴더 > train 폴더 순. 이 설명을 듣고 처음엔 이해하지 못했다. 그러다 생각이 났다. 코드에서 ctr+f로 train_name을 검색하니 train_name 이 변수로 설정되어 있었다. model1 이라고. 즉 ./train_data/model1/train 로 폴더를 잡아줘야 한다는 뜻.(으로 이해했다) 다운로드한 파일의 폴더는 이런식으로 잡혀있었다.
그리고 model이 1번부터 6번까지인데 1번은 벨리셋, 테스트셋이 없고 2번부터 6번은 테스트셋이 없었다. 일단 멘토님이 조언대로 모델1만 수작업으로 테스트셋 30% 벨리셋 20%를 분리했다.

3. 코드 실행 및 디버깅
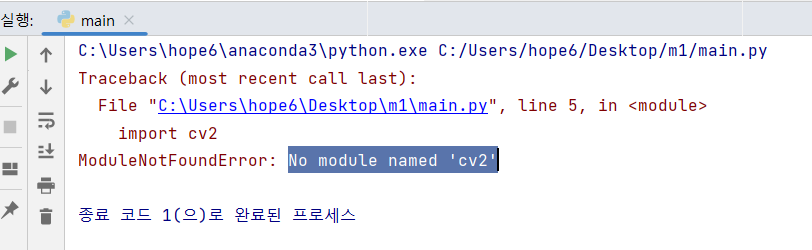
이제 코드를 실행시켜 보자.
에러 문구를 검색해 본다.
이렇게 해결 후 다시 실행시켜 본다.
같은 오류라 안심이 된다.
이젠 무슨 오류가 뜰까.
이젠 검색을 안해도 알 것 같다.
다시 실행.
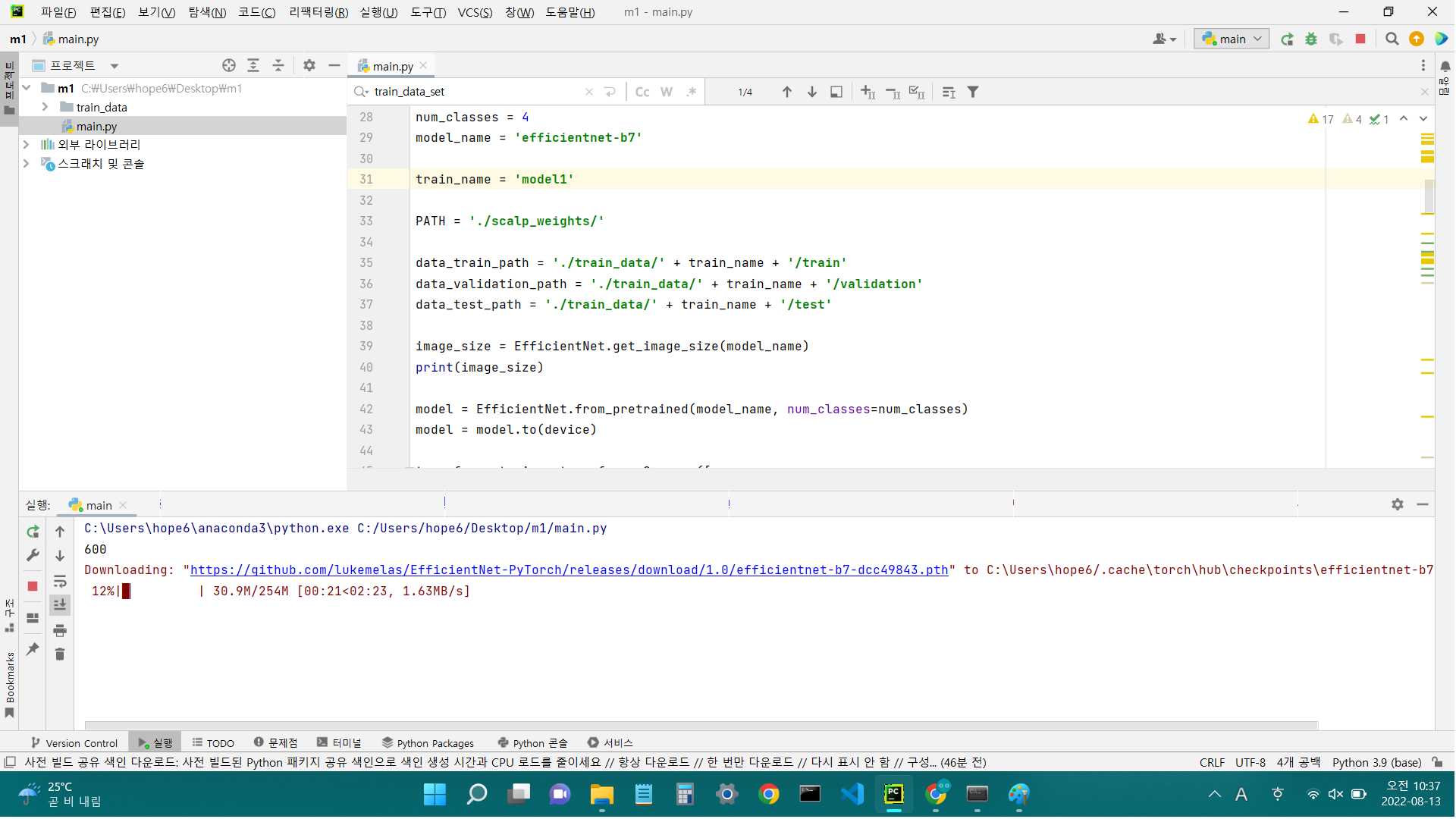
뭔지는 모르겠지만 다운로딩 중이다. 일단 실행에 성공했다^^
하지만 다운 100% 후 이어서 엄청난 오류가 떴다.
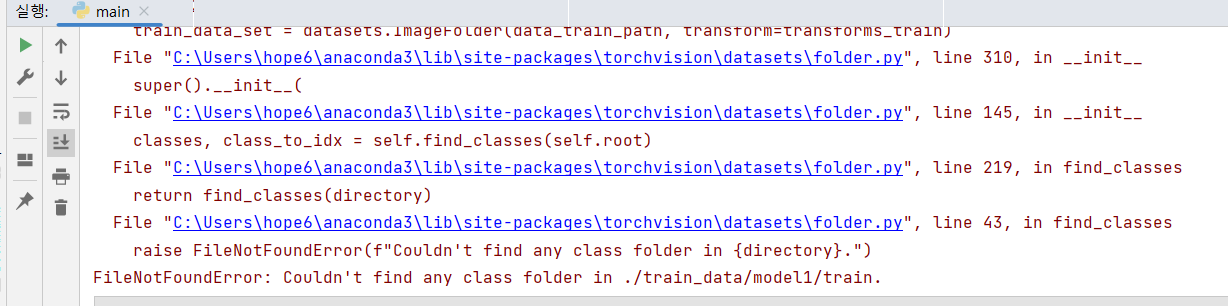
./train_data/model1/train. 에 클래스 폴더가 없다고요?... 벨리, 테스트셋만 나누고 한글 폴더는 유지했어야 하는 건가? data_train_path = './train_data/' + train_name + '/train' 이 경로를 보면 마지막에 train 폴더 다음 바로 파일이 와야 하는 거 아니야? 일단 train셋만 한글 폴더로 다시 배치하고 실행시켜서 확인을 해보자.
FileNotFoundError: Found no valid file for the classes [라벨]미세각질_0.양호, [라벨]미세각질_1.경증, [라벨]미세각질_2.중등도, [라벨]미세각질_3.중증. Supported extensions are: .jpg, .jpeg, .png, .ppm, .bmp, .pgm, .tif, .tiff, .webp라고 뜨는 걸로 봐서는 한글 폴더를 유지해야하는 건 맞는 것 같다. 라벨 폴더에는 json파일이 있는데.. 일단 라벨 폴더를 빼보자.
FileNotFoundError: Couldn't find any class folder in ./train_data/model1/validation.그러자 벨리셋을 요구한다. json 파일은 필요가 없는건가? 라벨링이 안된 파일인가? json파일을 이용해서 내가 라벨링을 한 후 실행하는 건가? 일단 벨리셋이랑 테스트셋 먼저 나누자.
_pickle.PicklingError: Can't pickle <function <lambda> at 0x000002DD50AE89D0>: attribute lookup <lambda> on __main__ failed이건 또 뭐냐... 코드에 pickle도 없는데 왜 피클 에러가 뜨지?
4. 코드 분석
그럼 일단 코드 분석 먼저 하자.
import time # time() 함수 : 현재 Unix timestamp을 소수로 리턴, 정수부는 초단위이고 소수부는 마이크로 초단위 import datetime # datetime.timedelta : 기간을 표현하기 위해서 사용 import copy # 복사 import cv2 import random # 랜덤 import numpy as np import json # JSON(JavaScript Object Notation), attribute–value pairs / array data types / any other serializable value 로 이루어진 데이터를 전달하기 텍스트를 사용하는 포맷 import torch # facebook에서 제공하는 딥러닝 도구, numpy와 효율적인 연동을 지원 import torch.nn as nn import torch.optim as optim import torchvision from torch.optim import lr_scheduler from torchvision import transforms, datasets from torch.utils.data import Dataset,DataLoader from torch.utils.tensorboard import SummaryWriter import matplotlib.pyplot as plt # 시각화 from PIL import Image # PIL 이미지 제어 from efficientnet_pytorch import EfficientNet # EfficientNet : 이미지 분류 최고의 모델 #변수 선언 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # torch.cuda.device(device) : 선택된 장치를 변경하는 context 관리자 # torch.cuda.device 의 파라미터 : device ( torch.device 또는 int ) – 선택할 장치 인덱스, 인수가 음의 정수 또는 None이면 작동X(no-op) hyper_param_batch = 6 # 배치 사이즈 random_seed = 100 # 랜덤 시드 # random_seed = 100 활용, 랜덤값 고정 random.seed(random_seed) torch.manual_seed(random_seed) # 변수 선언 num_classes = 4 # 이피션트넷 모델선언 (파라미터) model_name = 'efficientnet-b7' # 진짜 모델 이름 train_name = 'model1' # 트레인, 벨리, 테스트 셋 상위폴더 이름 PATH = './scalp_weights/' # 경로 설정 현재폴더 하위에 scalp_weights 폴더 data_train_path = './train_data/'+train_name+'/train' # 현재폴더/train_data/model1/train data_validation_path = './train_data/'+train_name+'/validation' # 현재폴더/train_data/model1/validation data_test_path = './train_data/'+train_name+'/test' # 현재폴더/train_data/model1/test # ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ image_size = EfficientNet.get_image_size(model_name) # model_name = 'efficientnet-b7' print(image_size) # 600 출력 # ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ # 모델 model = EfficientNet.from_pretrained( model_name, num_classes=num_classes ) # 이피션트넷 모델 선언 # pretrained weight 로드 # num_classes = 4 # 이피션트넷 모델선언 (파라미터) # model_name = 'efficientnet-b7' # 진짜 모델 이름 model = model.to(device) # device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # transforms.Compose : Rescale 과 RandomCrop 을 한번에 수행 # Rescale: 이미지의 크기를 조절 # RandomCrop: 이미지를 무작위로 자른다 # 정규화 transforms_train = transforms.Compose([ transforms.Resize([int(600), int(600)], interpolation=4), transforms.RandomHorizontalFlip(p=0.5), transforms.RandomVerticalFlip(p=0.5), transforms.Lambda(lambda x: x.rotate(90)), transforms.RandomRotation(10), transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) transforms_val = transforms.Compose([ transforms.Resize([int(600), int(600)], interpolation=4), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # data_train_path 경로의 이미지를 transforms.Compose 로 정규화 train_data_set = datasets.ImageFolder(data_train_path, transform=transforms_train) val_data_set = datasets.ImageFolder(data_validation_path, transform=transforms_val) # 변수 선언 dataloaders, batch_num = {}, {} # dataloaders 빈딕셔너리에 train/val 키랑 DataLoder 밸류 넣기 # DataLoader로 학습용 데이터 준비 : 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한다 dataloaders['train'] = DataLoader(train_data_set, batch_size=hyper_param_batch, shuffle=True, num_workers=4) dataloaders['val'] = DataLoader(val_data_set, batch_size=hyper_param_batch, shuffle=False, num_workers=4) # 즉 dataloaders 딕셔너리에는 train / val 이 key 각 밸류는 정규화한 이미지 데이터에 + 라벨이 붙음 # 배치_넘은 빈 딕셔너리 # train/val 을 key로 각 밸류 선언 batch_num['train'], batch_num['val'] = len(train_data_set), len(val_data_set) print('batch_size : %d, train/val : %d / %d' % (hyper_param_batch, batch_num['train'], batch_num['val'])) # 출력 : batch_size : 6, train/val : 2066 / 499 # hyper_param_batch = 6 train/val : len(train_data_set) / len(val_data_set) class_names = train_data_set.classes # train_data_set 정규화한 트레인셋 print(class_names) # 출력 : [ '[원천]미세각질_0.양호', '[원천]미세각질_1.경증', '[원천]미세각질_2.중등도', '[원천]미세각질_3.중증' ] # def 선언 후 마지막에 train_model(model, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=num_epochs) 로 실행 def train_model(model, criterion, optimizer, scheduler, num_epochs=25): ## 변수 선언 # 시간변수 선언 start_time = time.time() # end_sec 종료시간 = time.time() - start_time, # 종료시간 : since = time.time() # time_elapsed 경과시간 = time.time() - since, # 경과시간 : 모든 에폭을 돌리는데 걸린 시간 best_acc = 0.0 # 베스트 정확도 갱신시킬 변수 best_model_wts = copy.deepcopy(model.state_dict()) # 베스트가중치도 갱신: 베스트 정확도 갱신할 때 같이 갱신 # state_dict 는 간단히 말해 각 계층을 매개변수 텐서로 매핑되는 Python 사전(dict) 객체입니다. # state_dict : 모델의 매개변수를 딕셔너리로 저장 # copy.deepcopy 깊은복사: 완전한복사 (얕은복사:일종의 링크 형태) # 손실, 정확도 빈리스트 선언 train_loss, train_acc, val_loss, val_acc = [], [], [], [] # for문 for epoch in range(num_epochs): # epoch만큼 실행 print('Epoch {}/{}'.format(epoch, num_epochs - 1)) # 1000에폭을 넣으면 Epoch 0/999 이렇게 출력 왜 -1을 넣었을가 ? print('-' * 10) # 그저 ---------- 구분 선 epoch_start = time.time() # 매 에폭을 돌리는 시간 for phase in ['train', 'val']: if phase == 'train': model.train() # model.train() ≫ 모델을 학습 모드로 변환 else: model.eval() # model.eval() ≫ 모델을 평가 모드로 변환 # train이 들어가면 학습모드로 아래 코드 실행, val이 들어가면 평가모드로 val로 평가 # 변수 running_loss = 0.0 running_corrects = 0 num_cnt = 0 # 아래코드이해를위한 # dataloaders 빈딕셔너리에 train/val 키랑 DataLoder 밸류 넣기 # DataLoader로 학습용 데이터 준비 : 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한다 # dataloaders['train'] = DataLoader(train_data_set, # batch_size=hyper_param_batch, # shuffle=True, # num_workers=4) # dataloaders['val'] = DataLoader(val_data_set, # batch_size=hyper_param_batch, # shuffle=False, # num_workers=4) for inputs, labels in dataloaders[phase]: # phase 에 train or val 이 들어가서 인풋과 라벨로 나뉜다 inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() # optimizer.zero_grad() : Pytorch에서는 gradients값들을 추후에 backward를 해줄때 계속 더해주기 때문"에 # 우리는 항상 backpropagation을 하기전에 gradients를 zero로 만들어주고 시작을 해야합니다. # 한번 학습이 완료가 되면 gradients를 0으로 초기화 with torch.set_grad_enabled(phase == 'train'): # torch.set_grad_enabled # 그래디언트 계산을 켜키거나 끄는 설정을 하는 컨텍스트 관리자 # phase == 'train' 이 true 면 gradients를 활성화 한다. outputs = model(inputs) # 모델에 인풋을 넣어서 아웃풋 생성 _, preds = torch.max(outputs, 1) # _, preds ? # torch.max(input-tensor) : 인풋에서 최댓값을 리턴하는데 tensor라 각 묶음마다 최댓값을 받고 ,1 은 축소할 차원이1이라는 뜻 loss = criterion(outputs, labels) # 로스 계산 # 매 epoch, 매 iteration 마다 back propagation을 통해 모델의 파라미터를 업데이트 시켜주는 과정이 필요한데, # 아래 다섯 줄의 코드는 공식처럼 외우는 것을 추천드립니다. # optimizer.zero_grad() # init grad # pred = model(x) # forward # loss = criterion(pred, x_labels) # 로스 계산 # loss.backward() # backpropagation # optimizer.step() # weight update if phase == 'train': loss.backward() # backpropagation optimizer.step() # weight update running_loss += loss.item() * inputs.size(0) # 학습과정 출력 # running_loss = 0.0 # loss 는 로스계산 ? running_corrects += torch.sum(preds == labels.data) # running_corrects = 0 ? num_cnt += len(labels) # num_cnt = 0 ? # for inputs, labels in dataloaders[phase]: # phase 에 train or val 이 들어가서 인풋과 라벨로 나뉜다 # inputs = inputs.to(device) # labels = labels.to(device) if phase == 'train': scheduler.step() # 학습 규제 # 학습률이 크면 가중치 업데이트가 많아 가중치가 overflow 될 수도 있습니다 # 훈련 초기에 학습률은 충분히 좋은 가중치에 도달하기 위해 크게 설정됩니다. 시간이 지남에 따라 # 이러한 가중치는 작은 학습률을 활용하여 더 높은 정확도에 도달하도록 미세 조정됩니다. # 결국, 가중치를 규제(regularization)하는 방식과 비슷하게, 학습률을 규제하는(Learning Rate Decay)것이 Learning Rate Scheduler라고 할 수 있습니다. # optimizer와 scheduler를 먼저 정의한 후, 학습할 때 batch마다 optimizer.step() 하고 epoch마다 scheduler.step()을 해주면 됩니다. # def 밖에서 op sc 선언 def안에서 op.step sc.stop 완료 epoch_loss = float(running_loss / num_cnt) # ? 에폭손실 epoch_acc = float((running_corrects.double() / num_cnt).cpu() * 100) # ? 에폭 정확도 # 손실, 정확도 빈리스트 선언 # train_loss, train_acc, val_loss, val_acc = [], [], [], [] if phase == 'train': train_loss.append(epoch_loss) train_acc.append(epoch_acc) else: val_loss.append(epoch_loss) val_acc.append(epoch_acc) print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) # 출력 train/val, 손실, 정확도 if phase == 'val' and epoch_acc > best_acc: best_idx = epoch # 에폭인덱 best_acc = epoch_acc # 베스트정확도 best_model_wts = copy.deepcopy(model.state_dict()) print('==> best model saved - %d / %.1f' % (best_idx, best_acc)) # 몇번째 에폭의 베스트 정확도가 세이브되었나 출력 # best_acc = 0.0 # 베스트 정확도 갱신시킬 변수 # best_model_wts = copy.deepcopy(model.state_dict()) # 베스트가중치도 갱신: 베스트 정확도 갱신할 때 같이 갱신 # state_dict 는 간단히 말해 각 계층을 매개변수 텐서로 매핑되는 Python 사전(dict) 객체입니다. # state_dict : 모델의 매개변수를 딕셔너리로 저장 # copy.deepcopy 깊은복사: 완전한복사 (얕은복사:일종의 링크 형태) epoch_end = time.time() - epoch_start # train/val 전부 에폭 한번 돌리는 시간을 구해서 아래 출력 print('Training epochs {} in {:.0f}m {:.0f}s'.format(epoch, epoch_end // 60, epoch_end % 60)) #트레이닝에폭 epoch 몇분 몇초 print() # for문 끝 time_elapsed = time.time() - since # 경과시간 : 모든 에폭을 돌리는데 걸린 시간, for 문이 끝났으니까 print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) # 경과시간을 몇분 몇초로 출력 print('Best valid Acc: %d - %.1f' % (best_idx, best_acc)) # best_idx : 몇번째 에폭이 베스트인지, 베스트정확도 출력 model.load_state_dict(best_model_wts) # state_dict: 모델의 매개변수를 딕셔너리에 담은 > 것을 load 한다 # best_model_wts = copy.deepcopy(model.state_dict()) # PATH = './scalp_weights/' # 경로 설정 현재폴더 하위에 scalp_weights 폴더 torch.save(model, PATH + 'aram_' + train_name + '.pt') # 모델을 path경로에 aram_트레인네임.pt 라는 이름의 pt파일로 저장한다 torch.save(model.state_dict(), PATH + 'president_aram_' + train_name + '.pt') # 모델의 매개변수 path경로에 president_aram_ 트레인네임.pt 라는 이름의 pt파일로 저장한다 print('model saved') end_sec = time.time() - start_time # 종료시간 # 초단위에서 end_times = str(datetime.timedelta(seconds=end_sec)).split('.') # 시분초로 치환 # import datetime # end = 8888 # datetime.timedelta(seconds=end) #출력 datetime.timedelta(seconds=8888) # str(datetime.timedelta(seconds=end)) # type str #출력 '2:28:08' # str(datetime.timedelta(seconds=end)).split('.') # type list #출력 ['2:28:08'] ? # str(datetime.timedelta(seconds=end)).split('.')[0] # type str #출력 '2:28:08' end_time = end_times[0] # 종료시간 시분초 print("end time :", end_time) # 출력 return model, best_idx, best_acc, train_loss, train_acc, val_loss, val_acc # def 문 끝 # def실행할 train_model 파라미터 선언 model = EfficientNet.from_pretrained( model_name, num_classes=num_classes ).to(device) # 첫번째 파라미터 (위에서 선언) criterion = nn.CrossEntropyLoss() # 두번째 파라미터 optimizer_ft = optim.Adam(model.parameters(), lr=1e-4) # 세번째 파라미터 exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) # 네번째 파라미터 # 스케줄러 선언 num_epochs = 1000 # 다섯번째 파라미터 # def 문 실행 train_model(model, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=num_epochs)구글링하면서 대충 이해하면서 주석을 달았다. 주석이 코드 길이보다 더 길어보인다. 내 수준을 너무 웃도는 거라 완벽히 이해하는 건 나중에. 근데 이게 맞나? 원래 첫 프로젝트는 이렇게 하는 건가? 거의 하나도 못 배운 걸 독학으로 대충 하고, ai hub에서 몽땅 다운로드 받아서 대충 실행만 시켜서 하는 척만 하는 게 의미가 있는지 모르겠다. 이런식이면 어짜피 팀원 한명이 코드 실행만 시킬 줄 알면 그냥 뚝딱! 하고 끝나는 거라 팀 단위로 할 프로젝트도 아니다.(그래서 우리팀은 각자 할 수 있는 부분까진 혼자서 코드를 분석하면서 공부하기로 했다) 이럴 시간에 HTML, CSS 기초 공부를 하던가 딥러닝 배운 거 정리하는 게 좋을 것 같긴 한데, 프로젝트 체험이라고 생각하고 시키는 거나 하자.
주석을 달다 보니 save 파일이 저장될 경로를 설정해 줘야 한다는 걸 알 수 있었다. save를 위한 폴더를 만들었다.PATH = './scalp_weights/' 경로만 잡아주고 그 뒤로는 파일 이름 설정이었다.
5. 아나콘다
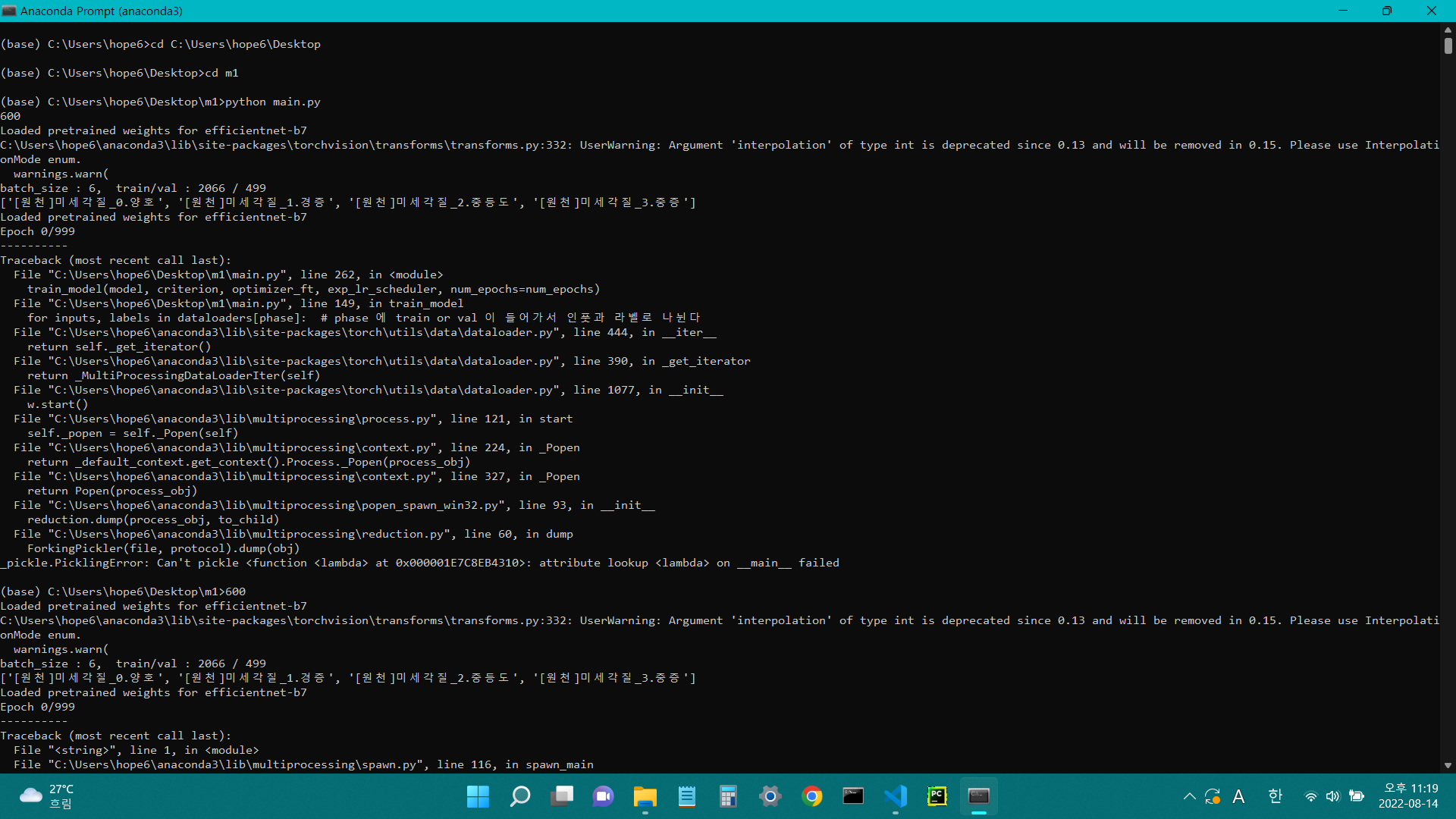
save 경로에 폴더를 만들어준 후 다시 파이참을 돌려도 그대로 피클 에러다. ai hub 에서 안내영상을 보면 아나콘다 프롬프트에서 돌리는 것 같다. 아나콘다에서 돌려보면
아나콘다로 돌리니까 오히려 에러가 늘었다. 피클에러에 런타임에러까지 추가. 에러코드를 보면 특이한 점이 600 이랑 epoch 0/999 가 두번 뜬다 피클에러가 걸려서 코드가 한번 멈추고 자동으로 재시작이 되고 런타임에러로 다시 멈춘다.

6. vgg16 활용
위 코드의 문제를 해결하는 것은 잠시 포기하고 인터넷에서 vgg코드를 복붙했다. 두피 데이터를 돌리니 accuracy가 1.2가 나왔다. 어떻게 정확도가 120%가 나오지? 선생님에게 어떻게 정확도가 100%를 넘는 건지 질문하니, 그건 코드를 뜯어봐야 아는 것이고, 하루에 8시간씩 파이토치를 독학하면 실력이 오를 거라고 하신다. 해결을 위한 키워드도 안알려주신다.
내 수준에서 파이토치를 기본부터 공부하기엔 시간도 문제고 독학도 힘들다. 효율 측면에서 너무 떨어지는 행위라고 생각한다. 내가 이걸 왜 하고 있는지 모르겠다. 이럴 시간에 딥러닝 복습하고 HTML, CSS 공부하면 좋을텐데. 더 삽질할 것도 없다. 삽질도 뭘 알아야 다양하게 해볼 수 있으니까. 그리고 삽질하면서 뭘 얻을 수 있나? 어짜피 구글링 복붙해서 제대로 이해하는 것도 아닌데.
7. 2차 멘토링
이번엔 멘토선생님 두분이 오셨다. 막막한 현상황을 타개할 명쾌한 답은 듣지 못했다. 삽질을 몇일 더 하라고 하시니까 답답했다. 난 삽질을 할만큼 해서 더 할 것도 없다고 말씀드렸다. 담임선생님한테 물으면 파이토치를 8시간씩 독학하라고 하셨다는 것도. json파일(라벨링데이터)이 있는 aihub데이터를 받은 것인데 json파일 없이 학습이 가능한지.(원천데이터가 폴더로 나뉘어져 있기 때문에 그것 자체가 라벨링이 된 것으로 볼 수 있다는 명쾌한 답을 얻었다) 그리고 이피션트넷 코드 속에는 컨볼층, 덴스층 같은 것도 없다는 것도 말했다. 멘토님은, 그런 질문은 코드를 자세히 봐야 알 수 있고 코드를 확인하고 원격으로 다시 만나자고 하신다. 마지막으로 나에게 질문이 더 남았냐고 물으신다. 내 이름도 물으신다. 열심히 하는 것처럼 보인 것 같다. 삽질에 대한 하나의 소득은 있었다.
삽질을 왜 시키는지 아직도 모르겠다. 파이썬 배울 땐 혼자서 코드를 이리저리 바꿔보면 원리를 이해하게 되는데 지금 하는 삽질은 그런게 아니다. 딥러닝배울 때 진도를 엄청 빠르게 나갔기 때문에 복습 및 정리 속도가 못 따라갔다. 밀린 공부가 많은 상황에서 삽질하고 있으니까 불안, 답답한 마음이다.
8. 디버그
- interpolation warning 디버그 :
interpolation=4 에서 interpolation=transforms.InterpolationMode.BICUBIC) 로 변경
- 버전 업데이트에 의한 warning을 해결
- pickle error ~ lambda~ 디버그 :
transforms.Lambda(lambda x: x.rotate(90)) 에서 transforms.Lambda(func) 로 변경 하고
def func(x): return x.rotate(90) 로 func함수를 지정
이렇게 하면 런타임에러 if name == 'main': ~~ 라고 하나의 에러가 뜬다.
이걸 코드 여기저기 넣어봤는데 에러가 안 잡힌다.
- runtime error 디버그 :
def train_model(model, criterion, optimizer, scheduler, num_epochs=25): 아래
if name == 'main': 코드를 추가
- worker 디버그 :
에러문을 해석하면 워커 최대권장치는 2인데 4로 설정되었다고 한다. 4를 2로 줄여서 해결
팀원의 도움을 받아 (내가 고치고 싶었는데) 이렇게 하니 에러는 안 뜨고 epoch화면에서 자꾸 컴터만 돌아간다. 한참을 돌아가다 런타임 에러로 마무리. 아직 코드도 한번 제대로 못 돌려봤다.
9. 코랩
수업시간에 구글드라이브에 데이터를 업로드 하고 그걸 코랩으로 마운트하는 방법을 배웠다. 코랩은 gpu설정이 쉬워서 될 줄 알았다. 아나콘다프롬프트에서 안되는 이유는 gpu로 실행하기 위한 cuda설치가 잘못 되었을 거라고 생각했기 때문이다. 하지만 코랩에서도 또 에러.
필요 없어 보이는 코드를 지워보며 삽질을 하다가 배치사이즈를 1로 줄여보았다. 에폭은 1. 에폭 1번 돌리는데 30분이(트레인15분+벨리15분) 걸리지만 돌아가긴 한다. 그저 컴퓨터 사양 문제일까? 모델이 .pt파일로 저장되었다. 정확도는 20~40% 수준이고 에폭을 2~5번 늘려도 정확도가 늘지 않는다.

배치를 1로 줄여도 아나콘다프롬프트에서는 돌아가지 않는다.
10. 모델1의 학습코드 완성
부담임선생님에게 상황을 알리니 주피터 원격 접속 링크를 주셨다. 폴더를 생성하고 데이터를 업로드. 속도가 엄청 빠르다. 하지만 이상하게도 학습은 돌아가지 않는다. cuda out of memory 라는 런타임에러다.
그저 이미지파일을 이피션트넷으로 돌리는 것뿐인데 백만원짜리 노트북으로 감당이 안되는 것인지 자꾸 의문이 들지만 주피터원격접속으로 잠깐 돌아갈 때 아큐러시가 70% 까지도 오르는 것을 보면 사양 문제가 맞는 것 같다. 즉 model1 의 학습 코드를 완성했다고 할 수 있다.
11. model1_test 코드 완성
aihub 안내 영상을 보면 학습은 model1_train.py 로 하지만 테스트 파일로 아큐러시를 도출할 땐 model1_test.py 을 돌리는 것을 볼 수 있다. 하지만 다운로드한 파일에는 model1_test.py가 없다. 즉 처음부터 끝까지 내가 만들어야 한다. 정말 다행인 점은 학습코드가 배치사이즈1이라도 돌아가긴 한다는 것이다. 그렇게 생성된 aram_model1.pt 모델 파일을 활용하여
model1_train 코드를 작성하면 된다.
의외로 test 코드를 작성하는 것은 쉬웠다. 반나절도 걸리지 않았다. 삽질 실력이 늘었다. 구글링으로 바로 복붙한 건 아니다. 모델을 저장했으니 그걸 불러와야지. 이미지를 학습할려면 전처리를 해야지, 등의 생각을 하며 부분 부분 구굴링해서 맞추고 문법에러를 계속 고쳤다. 위에서 삽질을 많이해서 그런가? 그렇게 생각하긴 싫다. 아무튼 학교를 마치기 전에 99%를 완성했다. train 코드처럼 자꾸 에러가 뜨면 답이 없어서 허탈해 하며 멍 때리는 시간이 많다. 하지만 이번엔 달랐다. 계속 코드를 치느라 정말 피곤했다. 위에서 발생한 치명적인 에러들과는 달리, 문법 에러가 대부분이었다. 그럼 코드를 바꿔보고 뜯어볼보며 여러가지 시도를 할 수 있다.
model1_test 코드 (코랩용)
# 구글드라이브 마운트 from google.colab import drive drive.mount('/content/drive') # 모델.pt파일 경로 PATH = '/content/drive/MyDrive/Colab Notebooks/scalp_weights/'+'aram_model1.pt' # 모델1 # PATH2 = '/content/drive/MyDrive/Colab Notebooks/scalp_weights/'+'president_aram_model1.pt' # 모델1 파라미터 # CUDA 를 활용한 GPU 가속 여부에 따라, 장치를 할당 할 수 있도록 변수로 선언 import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 모델1 불러오기 !pip install efficientnet_pytorch model1 = torch.load(PATH, map_location=device) # 모델1 파라미터 불러오기 # model1_p = torch.load(PATH2, map_location=device) ## test 이미지파일 전처리, 텐서화 import torchvision from torchvision import transforms # 전처리-트랜스폼 규칙 선언 # model1_train 코드의 validation set 의 트랜스폼 규칙과 동일하게 함 transforms_test = transforms.Compose([ transforms.Resize([int(600), int(600)], interpolation=transforms.InterpolationMode.BICUBIC), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # root 경로 폴더 속 jpg를 전처리, 텐서화 (rood 속에 폴더를 하나 더 만들어서 jpg를 묶어야 함) testset = torchvision.datasets.ImageFolder(root = '/content/drive/MyDrive/Colab Notebooks/train_data/model1/test', transform = transforms_test) ## 확인 testset.__getitem__(0)[0].shape # (0) 테스트셋의 0번째 item # rgb three channel 이니까 3 # 높이 넓이 600 600 리사이즈 # 전처리 정상 완료 확인 # DataLoader를 통해 네트워크에 올리기 from torch.utils.data import Dataset,DataLoader testloader = DataLoader(testset, batch_size=1, shuffle=False, num_workers=2) # dataiter = iter(testloader) # images = dataiter.next() # images[0].shape # [1, 3, 600, 600] # 처음1은 배치사이즈와 동일 ## 아웃풋, 로스, 프레딕, 아큐러시 output_list = [] model1.eval() # 평가모드로 전환 # 평가모드와 학습모드의 layer 구성이 다르다 correct = 0 # 로스 연산 # import torch.nn.functional as F # F : 테스트_로스 연산 함수 # test_loss = 0 from tqdm import tqdm # 진행률 표시를 위한 with torch.no_grad(): # 평가할 땐 gradient를 backpropagation 하지 않기 때문에 no grad로 gradient 계산을 막아서 연산 속도를 높인다 for data, target in tqdm(testloader): data, target = data.to(device), target.to(device) output = model1(data) # model1에 데이터를 넣어서 아웃풋 > [a,b,c,d] 각 0,1,2,3 의 확률값 리턴 가장 큰 것이 pred output_list.append(output); # test_loss += F.nll_loss(output, target, reduction = 'sum').item() # test_loss변수에 각 로스를 축적 pred = output.argmax(dim=1, keepdim=True) # argmax : 리스트에서 최댓값의 인덱스를 뽑아줌 > y값아웃풋인덱 # correct += pred.eq(target.view_as(pred)).sum().item() # accuracy 측정을 위한 변수 # 각 예측이 맞았는지 틀렸는지 correct변수에 축적 맞을 때마다 +1 # # view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. # test_loss /= len(testloader.dataset) # 로스축적된 로스를 데이터 수(경로안jpg수)로 나누기 # 아큐러시 출력 ( :.4f 소수점반올림 ) # print('\nTest set Accuracy: {}/{} ({:.4f}%)\n'.format(correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) # 축적된 예측값을 데이터 개수로 나누기 *100 > 확률%값 # 로스, 아큐러시 출력 # print('\nTest set: Average Loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(test_loss, correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) # 업로드 이미지에 대한 output predict 값 # 업로드 폴더로 실행 > 아웃풋리스트에서 최근 업로드 파일을 -1인덱스로 잡은 후 아웃풋 리스트에서 -1 인덱스로 최근 업로드 파일을 잡고 argmax로 아웃풋 0 1 2 3 중 최댓값의 인덱스를 리턴 # output_list[-1].argmax(dim=1, keepdim=True) # output_list[-1] 은 각 0 1 2 3 의 값 > argmax로 최댓값의 인덱스를 리턴 output_list[-1] , output_list[-1].argmax(dim=1, keepdim=True) # 각 0 1 2 3 갑 중 가장 높은 인덱스는 2 > 즉 2:중등도 를 predict 함 # 0:양호, 1:경증, 2:중등도, 3:중증배치사이즈1, 에폭1로 돌린 모델1.pt파일을 활용한 위 코드로 test set 의 accuracy 를 측정하면 약 40% 가 나온다. 마지막 줄은 이미지 파일 하나에 대해 predict값을 도출하는 것이다.
0:양호, 1:경증, 2:중등도, 3:중증 중 하나의 값이 뽑힌다. 아큐러시와 로스까지 계산이 가능한데 연산 속도만 느려지니까 주석처리한 상태.
이로써 모델1의 백엔드 코드의 뼈대를 완성했다. 다듬어야 한다. 모델1 코드가 완전해지면, 모델2~6의 코드를 복붙하여 작성하고 폴더 경로를 잡고 폴더별 파일을 나눠주는 건 쉬운 작업이다. 시간 문제일 뿐이다. test 코드가 의외로 쉬워서 다행이다.
테스트 코드를 아나콘다프롬프트로 돌려보니 작동은 되지만 코랩gpu에 비해 속도가 훨씬 느리다. gpu 관련 설치가 제대로 되지 않은 것이 맞나보다.
자기 전 코드를 돌리고 일어나서 보니, accuracy는 약 14%로 측정이 되었다. 아마도 코랩에서 측정한 40%가 아니라 이 14%가 맞는 것 같다. 그렇게 생각하는 이유는 이렇다.
1. 코랩용 코드를 돌리면 test 파일 수가 10개 정도 높게 잡힌다.
2. train코드에서 1배치1에폭 학습을 돌리면 트레인셋 accuray는 40%가 나오지만 벨리셋
accuracy는 6~35% 수준이었다.
3. ipython에서 accuracy를 측정해도 14%.
vs code에서 돌리는 것과 아나콘다프롬프트로 돌리는 것의 결과는 같다. 코드에 print() 로 변수를 출력하는 코드를 넣을 경우 각종 에러가 생긴다. print 를 빼면 괜찮은 것으로 보아 큰 문제는 없어 보인다. 프롬프트에서 ipython 을 치고 코드를 직접 복붙할 경우 print() 코드도 에러가 생기지 않는다.
gpu가 아니더라도 업로드 파일 하나에 대해서는 연산이 빨리 끝나기 때문에 두피 이미지 하나를 받아서 아웃풋을 도출하는 모델 시연에는 문제가 되진 않는다.
12. 모델2~6 코드 복붙
복붙으로 어렵지 않게 완성 했다. 마지막으로 모델 1~6의 아웃풋을 바탕으로 두피 타입을 판단하는 코드까지 완성. 코드 길이가 6배 이상으로 늘었지만 작동에는 문제가 없다.
13. + 프론트엔드
이제 웹으로 연결만 하면 거의 완성 단계. 코랩에서 수업 자료인 예제 코드를 사용하여 만들었다. html, css 너무 배운게 없어서 기본적인 질문을 많이했다. 파이썬 처음 배울 때로 돌아간 기분. 코드를 통으로 복붙해서 6배가 넘게 늘어난 코드도 간략화 했다.
문제점 : 웹을 예쁘게 꾸미는 것이 아닌, 하나의 큰 문제가 있었다. 업로드 폴더에 파일이 들어가면 그것을 모델에 넣어서 프레딕을 하는데, 문제는 업로드 폴더에 파일이 2개 이상일 때 일어난다. 최근 업로드한 하나의 파일에 대한 아웃풋만 뽑아야 하는데 그게 힘들다. 업로드 폴더에 파일이 업로드가 되면 testloader에서 차례대로 인덱스가 매겨지질 않는다. 그래서 아웃풋 리스트에서 [-1]이나 [0]인덱스만 뽑아와도 최근 업로드 파일의 아웃풋만을 뽑을 수는 없다. 게다가 업로드 폴더에 있는 모든 파일에 대해 아웃풋을 연산하기 때문에 시간도 많이 걸린다. 이 문제를 해결하기 위해 일단 포문 마지막에 break를 걸어서 루프를 1번만 돌렸다. testloader에서 값들이 나오는 순서에 대해 파일을 하나씩 넣어서 아웃풋 값을 확인해 보았다. for문에서 testloader속 데이터는 업로드 파일의 제목 순서대로 자동으로 오름차순 순서로 뽑히는 것을 알 수 있었다. 하지만 testloader에는 인덱스로 슬라이싱이 안되고 숫자값이라 파일이름==데이터 식으로 이프문을 걸어서 뽑을 수도 없다. 이 문제를 해결하기 가장 쉬운 방법은 업로드 폴더에 항상 단 하나의 파일만 담기는 것이다. 즉 업로드를 하면 업로드 폴더 속 파일을 전부 삭제하고 업로드 하면 된다고 생각했다. 선생님은 그 방법에 대해 '파일 지우기 파이썬' 이라는 간단한 키워드로 구글링 하는 것만 보여주셨다. 이것을 토대로 삽집을 하면서 코드 구조도 더 잘 알게되었다.
해결 방법은 이렇다. 유저가 업로드를 하면 업로드 폴더에 유저가 올린 파일이름으로 저장되는 것이 아니라 upload.jpg라는 내가 정한 이름으로 저장된다.
그리고 다시 다른 이미지를 업로드를 하려고 하면 일단 폴더 속 upload.jpg를 지우라는 코드가 작동이 된다. if문을 활용하여 upload.jpg가 있다면 삭제하라는 코드가, 웹 실행시 먼저 실행된다.그 다음 업로드도 upload.jpg라는 이름으로 덮어쓰기 되어 업로드 폴더 속 파일은 upload.jpg 하나로 유지가 되는 것이다.
즉 프레딕 코드는 항상 하나의 최근 업로드 파일만 연산을 하기 때문에 연산 시간이 줄고 프레딕값은 하나만 나오기 때문에 특정 인덱스로 최근 업로드파일의 프레딕값을 뽑아낼 필요도 없다.
14. 코드 작성 과정
- train code : aihub에서 그대로 받은 train코드는 이미 완성된 코드인데 각정 에러와 컴퓨터사양 문제로 삽질만 하다가 결국 코랩에서 gpu로 배치사이즈를 1로 하면 에폭1에 15분이 걸리지만 돌아가긴 한다는 사실을 발견. 에폭2를 돌린 모델을 30분만에 뽑았다. 벨리셋 정확도는 약20%. 이 모델이 .pt파일로 세이브 된다.
- test code : 컴퓨터사양 문제가 해결되지 않은 상황에서 가만히 있을 수 없기에 이 모델.pt 파일을 6개까지 복사하여 파일명만 model 1~6 으로 바꿔서 6가지 모델 파일을 만들었다. 이것을 바탕으로 test code를 작성. test code는 aihub에서 안준다. 내가 처음부터 구글링 복붙하며 작성하는 거라 손이나 댈 수 있을까?라고 생각했지만, 의외로 별로 안어려워서 계속 코드를 치느라 정말 피곤했다. 대부분 문법에러였다. 문법에러는 코드를 잘 뜯어보면 해결책이 보인다. 에러문구에 정답이 있다.
- front-end : 선생님의 수업자료를 바탕으로 몇가지 문장과 이미지를 교체하고 test code를 간략화하여 깔끔하게 정리. 테스트코드와 프론트엔드까지는, train code보다 분량이 훨씬 많지만 3일 걸렸다. train code는 이미 완성된 코드 가지고.... 삽질하며 낭비한 시간이 아깝다.
15. operation
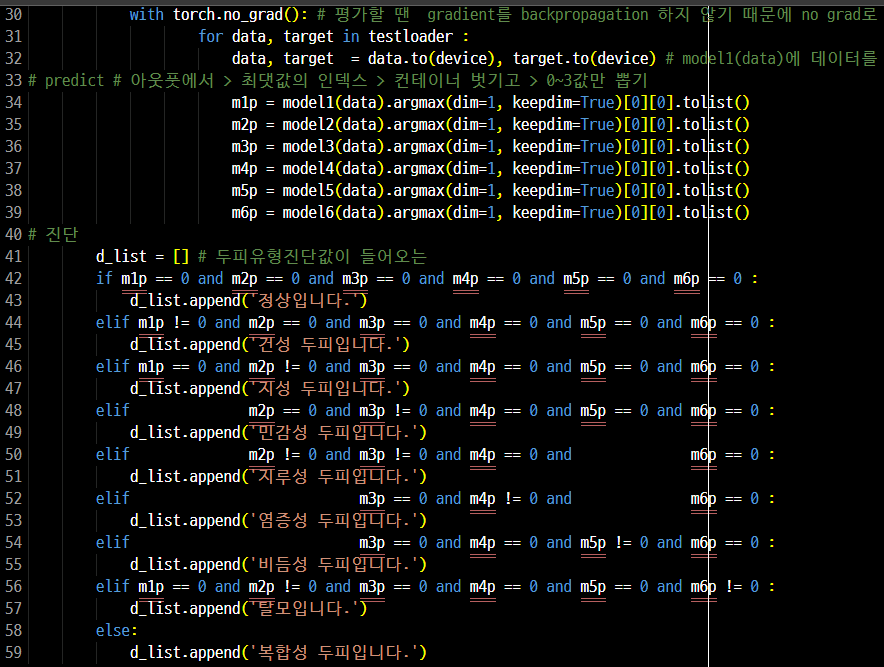
모델1~6의 predict 값을 받아서 두피 타입을 이렇게 진단한다. 코드는 이렇게 이미 준비가 되었다. 컴퓨터 사양 문제를 해결하고 아큐러시가 높은 모델pt파일 6개만 받아서 돌리면 된다.
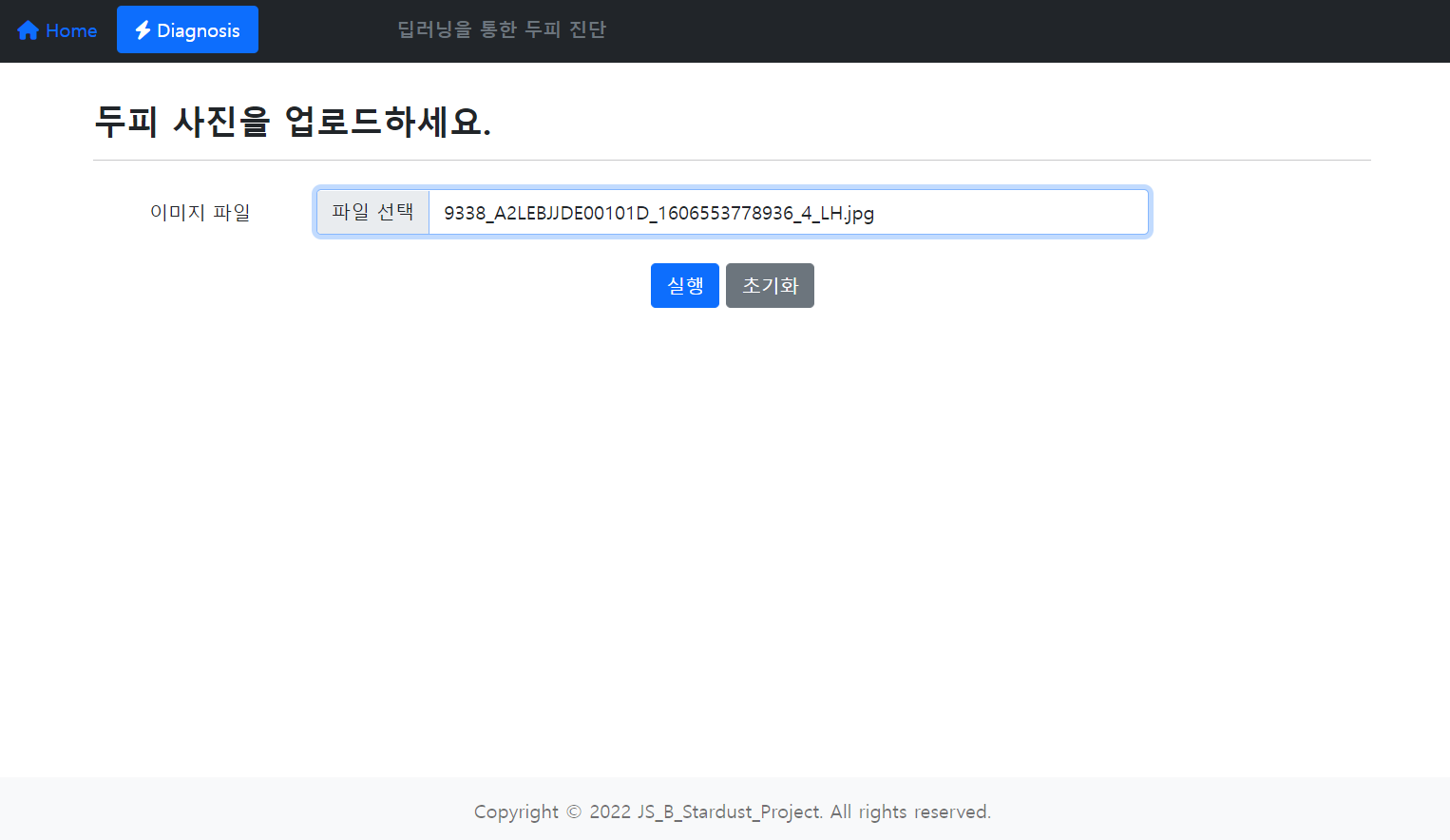
웹페이지 연동

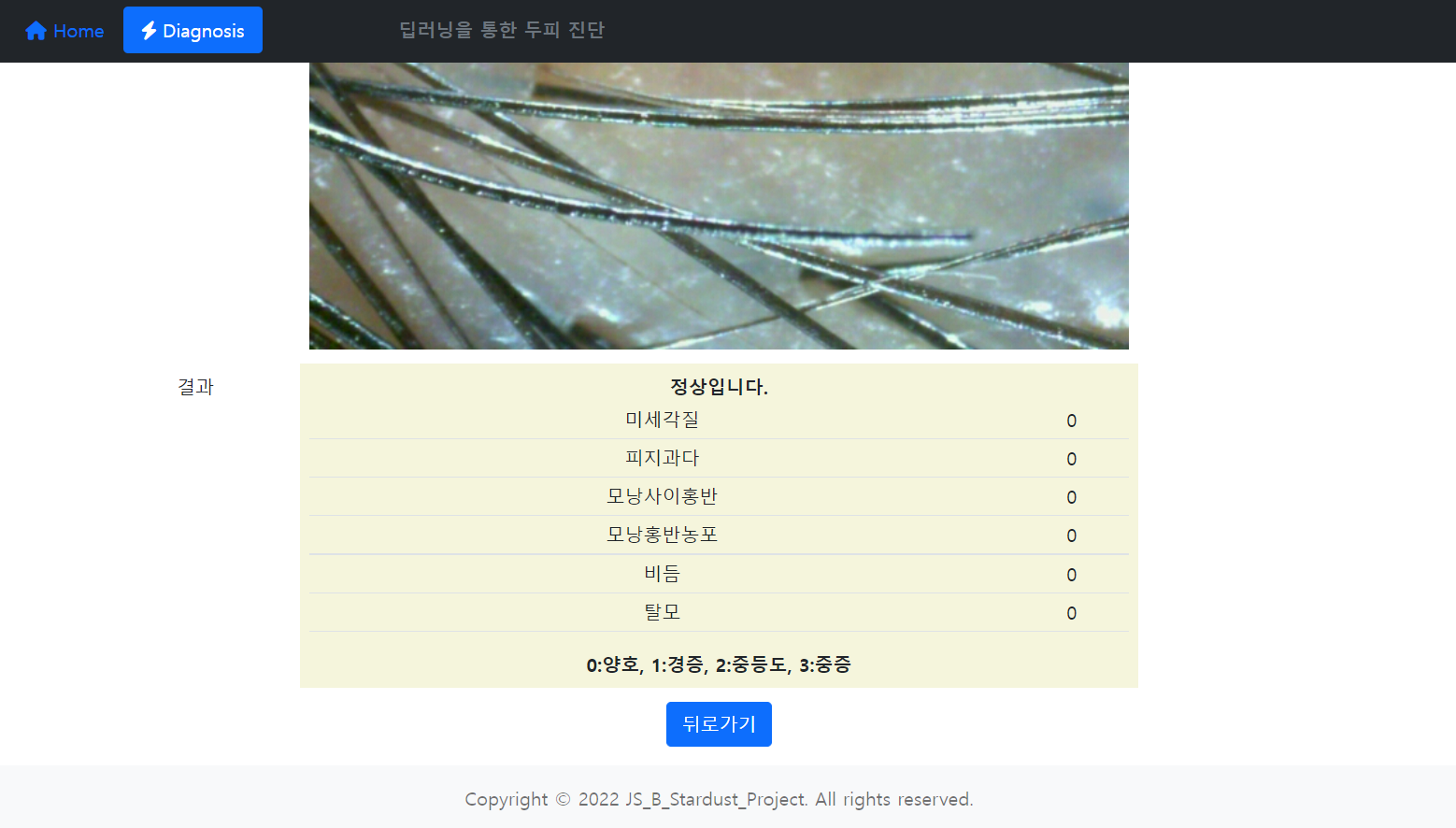
16. 두피 타입별 정보, 제품 추천
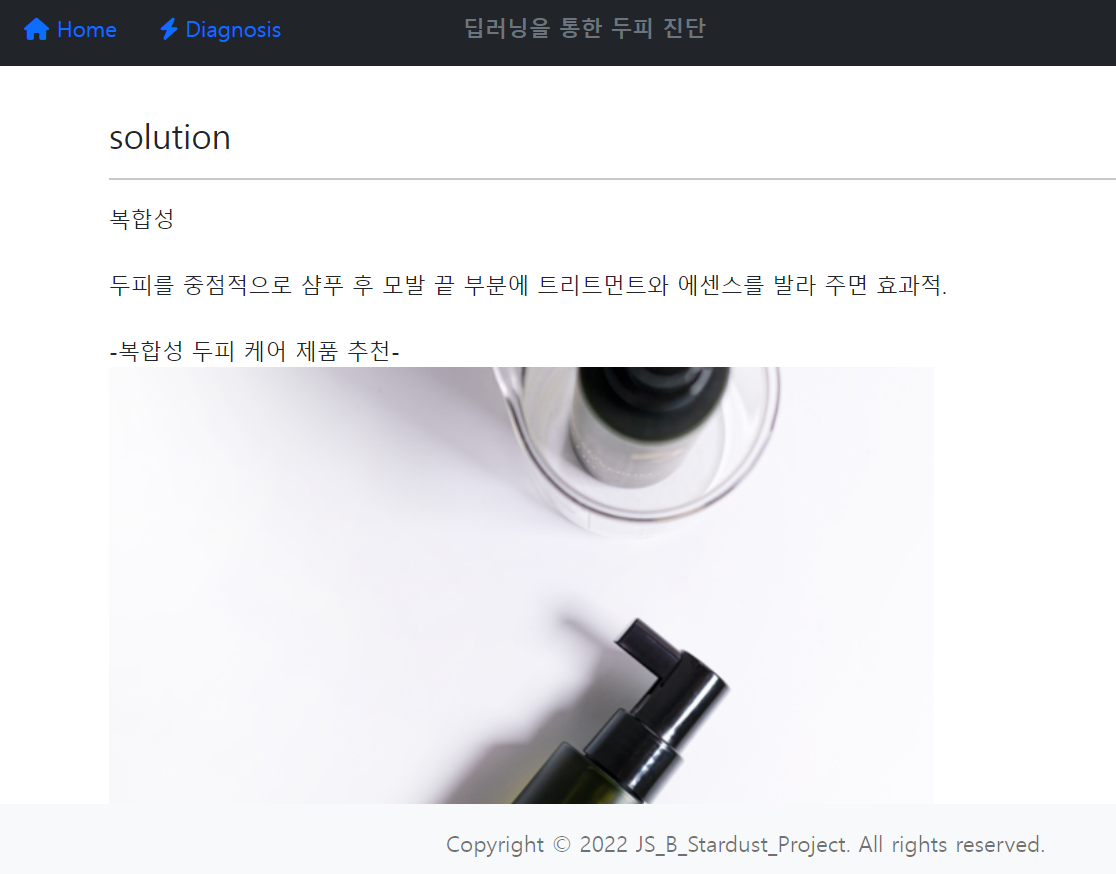
진단 결과가 정상이 아닐 경우 뒤로가기 버튼 오른쪽에 solution 버튼이 생기고 타입별로 간단한 정보와 하나의 제품을 추천하는 링크를 걸었다.
17. loading page
유저가 이미지 업로드를 하면 cpu로 모델6개의 아웃풋을 뽑느라 시간이 30초 이상 소요된다. 그래서 그 시간동안 로딩중이라고 알려주는 페이지를 만들어야 한다는 선생님의 조언을 듣고 선생님 깃허브의 예제파일을 참고하여 만들려고 했다. 이것 저것 떼고 붙이고 계속 삽질만 하다 결국 포기.. 로딩페이지는 뜨는데 딥러닝 코드로 절대 넘어가질 않는다. 삽질만 한 것은 아니라고 스스로 정신승리 하려고 왼쪽 상단에 stardust라고 쓰인 아이콘을 추가했다. 예제파일을 보면 저 부분에 원래 아이콘이 들어가 있던 자린데 딥러닝 코드를 추가하는 과정에서 PATH들이 서로 꼬이면서 디버그가 필요했다. 머리 너무 복잡해져서 그냥 아이콘을 지워버리는 간단한 디버그 방법을 택했었다. 시간이 흘러 다시 보니까 할만해 보였다. 3가지 경로 설정을 꼬이지 않게 제대로 잡아주고 살렸다. 주말 하루 동안 달성한 소소한 성과다.
18. 로딩페이지 활성화 성공
딥러닝 코드로 절대 넘어가지 않았던 이유를 알아냈다. 선생님께서 각종 시도를 했지만 해결하지 못하는 상황. 선생님의 시도 중 f12 를 누르고 console로 들어갔을 때 에러문구가 있었던 것을 들여다보다가 에러문을 구글링했다. 여러 답변 중 html문에 제이쿼리 설치를 해야한다는 답변이 눈에 띄었다. 제이쿼리 설치법을 검색하니 여러 방법이 나왔다. 가장 간편할 것 같은 http주소를 넣는 방식을 따라 한줄의 코드를 추가했다. 성공! 드디어 딥러닝 코드가 실행되었다. 이어서 에러가 뜨긴 했지만 제품 추천 화면을 출력하는 과정에서 다른 라우트에 있는 predict 변수를 가져오지 못해서 생긴 문제와 같은 것이라 쉽게 해결할 수 있었다. 문제를 해결하고자 예제파일 코드를 분석하고 있던 선생님에게 이것을 설명드렸다. 선생님은 잘못된 예제파일을 수정하며 '정말 잘했다'고 칭찬해 주셨다.
19. 모델 학습 완료 (벨리셋, 테스트셋 아큐러시 측정)
코랩플러스를 지원 받았다. 덕분에 배치사이즈를 2로 올려서 학습할 수 있었다... 모델 아큐러시가 많이 올랐다.
# 최종 모델 벨리셋 / 테스트셋 정확도 # 모델1 model1(미세각질) : 모델 생성 완료(epoch 15회 best val score : 63.4%) train/val : 12739/3639 100%|██████████| 238/238 [03:01<00:00, 1.31it/s] Test set: Average Loss: -1.9017, Accuracy: 289/476 (60.7143%) # 모델2 model2(피지과다) : 모델 생성 완료(epoch 2회 best val score : 57.6%) train/val : 56826/16236 100%|██████████| 662/662 [01:17<00:00, 8.54it/s] Test set Accuracy: 324/662 (48.9426%) # 모델3 model3(모낭사이홍반) : 모델 생성 완료(epoch 5회 best val score : 78.4) train/val : 47726/13635 100%|██████████| 359/359 [03:24<00:00, 1.76it/s] Test set: Average Loss: -2.2255, Accuracy: 461/718 (64.2061%) # 모델4 model4(모낭홍반농포) : 모델 생성 완료(epoch 50회 best val score : 72.4) train/val : 3750/1070 100%|██████████| 197/197 [01:32<00:00, 2.12it/s] Test set: Average Loss: -3.4693, Accuracy: 281/394 (71.3198%) # 모델5 model5(비듬) : 모델 생성 완료(epoch 5회 best val score : 73.4) trian/val : 28873/8248 100%|██████████| 310/310 [02:31<00:00, 2.05it/s] Test set: Average Loss: -2.0950, Accuracy: 370/620 (59.6774%) # 모델6 model6(탈모) : 모델 생성 완료(epoch 8회(4회×2) best val score : 74.7) trian/val : 18513/5288 100%|██████████| 577/577 [05:12<00:00, 1.85it/s] Test set: Average Loss: -1.3145, Accuracy: 633/1154 (54.8527%)
21. 발표(프로젝트끝)
아쉬움이 많은 마무리였다. 다른조의 결과물과 멘토님들의 이야기를 들어보니 부족한 점이 많이 보였다. 우리반 총 여섯조 중에서 반인 3조가 상을 받는데 뽑히지 못했다... 아쉬움이 남아서 프로젝트는 끝났지만 코드를 더 만졌다.
22. 그래프 시각화
학습코드 에폭당 아큐러시 그래프 (배치1학습)
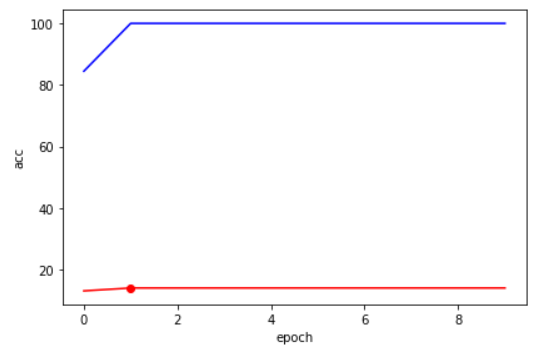
##에폭별 아큐러시 그래프 그리기 print('best model : %d - %1.f / %.1f'%(best_idx, val_acc[best_idx], val_loss[best_idx])) fig, ax1 = plt.subplots() ax1.plot(train_acc, 'b-') #선그래프Y축 ax1.plot(val_acc, 'r-') #선그래프Y축 plt.plot(best_idx, val_acc[best_idx], 'ro') #벨리셋 아큐러시 최대치 나오는 지점을 점 찍어주기 ax1.set_xlabel('epoch') #Make the y-axis label, ticks and tick labels match the line color. ax1.set_ylabel('acc', color='k') ax1.tick_params('y', colors='k') #ax2 = ax1.twinx() #ax2.plot(train_loss, 'g-') #ax2.plot(val_loss, 'k-') #plt.plot(best_idx, val_loss[best_idx], 'ro') #ax2.set_ylabel('loss', color='k') #ax2.tick_params('y', colors='k') fig.tight_layout() plt.show() #그래프 출력
블루 : train acc
레드 : test acc
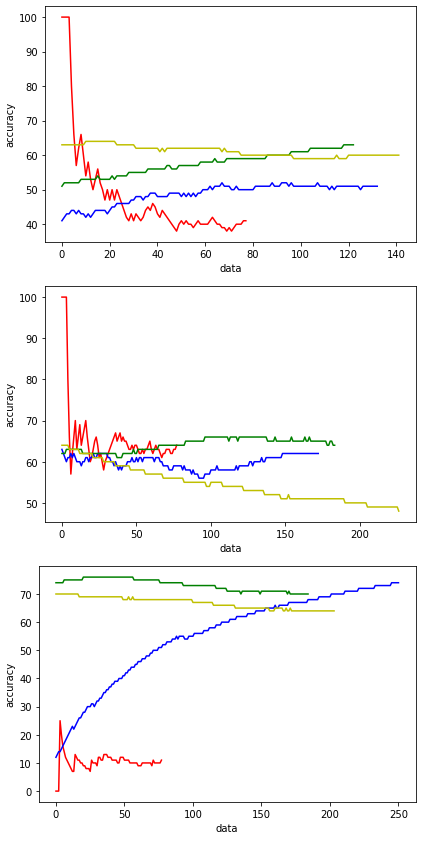
테스트코드 클래스별 아큐러시 그래프:
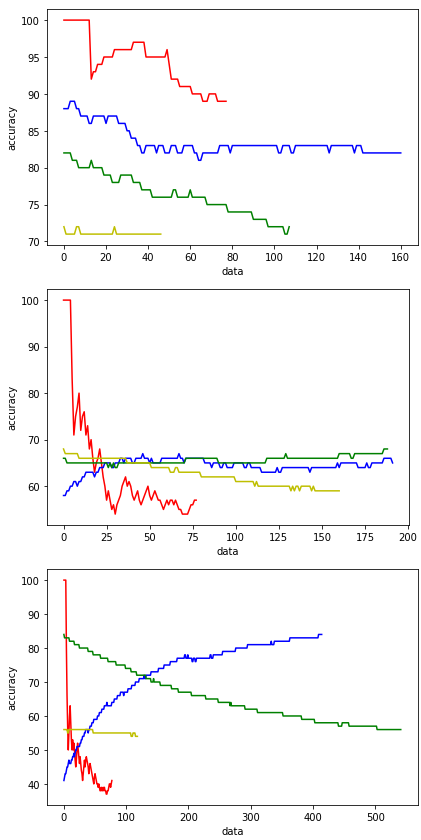
발표 때 다른팀이 조언 받은 내용 중 클래스별 아큐러시를 측정했냐는 이야기가 나와서 만들어 보았지만 이걸로 뭐하라는 건지 모르겠다.def aaa() : with torch.no_grad(): # 평가할 땐 gradient를 backpropagation 하지 않기 때문에 no grad로 gradient 계산을 막아서 연산 속도를 높인다 ###### test_acc_0 = [] test_acc_1 = [] test_acc_2 = [] test_acc_3 = [] count = 0 # 반복수카운트 #test_loss = 0 global correct correct = 0 ###### for data, target in tqdm(testloader): data, target = data.to(device), target.to(device) output = model(data) # model1에 데이터를 넣어서 아웃풋 > [a,b,c,d] 각 0,1,2,3 의 확률값 리턴 가장 큰 것이 pred #output_list.append(output); #test_loss += F.nll_loss(output, target, reduction = 'sum').item() # test_loss변수에 각 로스를 축적 pred = output.argmax(dim=1, keepdim=True) # argmax : 리스트에서 최댓값의 인덱스를 뽑아줌 > y값아웃풋인덱 correct += pred.eq(target.view_as(pred)).sum().item() # accuracy 측정을 위한 변수 # 각 예측이 맞았는지 틀렸는지 correct변수에 축적 맞을 때마다 +1 # # view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. # view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. # pred.eq(data) : pred와 data가 일치하는지 검사 ################################ count += 1 #모델1샘플파일수 (0,78) (1,133) (2,123) (3,142) 총476 if count <= 78 : test_acc_0.append( int(( correct / count ) * 100 ) ) # 반복/테스트데이터수별 아큐러시 # ( correct / elif count <= 211: test_acc_1.append( int(( correct / count ) * 100 ) ) elif count <= 334: test_acc_2.append( int(( correct / count ) * 100 ) ) else : test_acc_3.append( int(( correct / count ) * 100 ) ) ##에폭별 아큐러시 그래프 그리기 #print('best model : %d - %1.f / %.1f'%(best_idx, val_acc[best_idx], val_loss[best_idx])) import matplotlib.pyplot as plt fig, ax1 = plt.subplots() #ax1.plot(train_acc, 'b-') #선그래프Y축 #ax1.plot(val_acc, 'r-') #선그래프Y축 ax1.plot(test_acc_0 , 'r-') ax1.plot(test_acc_1 , 'b-') ax1.plot(test_acc_2 , 'g-') ax1.plot(test_acc_3 , 'y-') #plt.plot(best_idx, val_acc[best_idx], 'ro') #벨리셋 아큐러시 최대치 나오는 지점을 점 찍어주기 ax1.set_xlabel('data') #Make the y-axis label, ticks and tick labels match the line color. ax1.set_ylabel('accuracy', color='k') ax1.tick_params('y', colors='k') #ax2 = ax1.twinx() #ax2.plot(train_loss, 'g-') #ax2.plot(val_loss, 'k-') #plt.plot(best_idx, val_loss[best_idx], 'ro') #ax2.set_ylabel('loss', color='k') #ax2.tick_params('y', colors='k') fig.tight_layout() # plt.show() #그래프 출력 ################################ return output, count, pred, correct , test_acc_0 , test_acc_1, test_acc_2, test_acc_3 #view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. #test_loss /= len(testloader.dataset) # 로스축적된 로스를 데이터 수(경로안jpg수)로 나누기 #아큐러시 출력 ( :.4f 소수점반올림 ) #print('\nTest set Accuracy: {}/{} ({:.4f}%)\n'.format(correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) # 축적된 예측값을 데이터 개수로 나누기 *100 > 확률%값 #로스, 아큐러시 출력 #print('\nTest set: Average Loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(test_loss, correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) aaa() print('\nTest set Accuracy: {}/{} ({:.4f}%)\n'.format(correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) # 축적된 예측값을 데이터 개수로 나누기 *100 > 확률%값모델 위에서 아래로 1,2,3,4,5,6 컬러 r/b/g/y 프레딕 0/1/2/3
23. 유사 앙상블 구현하기
모델의 낮은 아큐러시를 보완하기 위해 이미지 여러개의 프레딕트 값의 평균값으로 진단을 내리는 코드이다. 발표날 우리팀이 조언 받은 내용이다. 프레딕트값을 전체데이터셋의 len으로 먼저 나누고 fmXp에 누적시키는 방법으로 평균 프레딕트 값을 구했다. 값이 소수점으로 나올 것이기 때문에 진단을 내리는 코드에서 약간의 변형을 했다. 프레딕트에서 1이 너무 잘나와서 복합성이 잘 나오니 0이 아닌 1을 기준으로 진단하게 바꿨다.
#다중이미지를 받아서 평균프레딕트값을 구할 변수 fm1p=0.0 fm2p=0.0 fm3p=0.0 fm4p=0.0 fm5p=0.0 fm6p=0.0 ##아웃풋, 로스, 프레딕, 아큐러시 #output_list = [] #correct = 0 # 그래프그리기위한 #로스 연산을 위한 #import torch.nn.functional as F # F : 테스트_로스 연산 함수 #test_loss = 0 # 로스연산을위한 from tqdm import tqdm # 진행률 표시를 위한 if __name__ == '__main__': with torch.no_grad(): # 평가할 땐 gradient를 backpropagation 하지 않기 때문에 no grad로 gradient 계산을 막아서 연산 속도를 높인다 for data, target in tqdm(testloader): data = data.to(device) output1 = model1(data) # model1에 데이터를 넣어서 아웃풋 > [a,b,c,d] 각 0,1,2,3 의 확률값 리턴 가장 큰 것이 pred output2 = model2(data) output3 = model3(data) output4 = model4(data) output5 = model5(data) output6 = model6(data) #predict # # 0~3값만 뽑기 m1p = output1.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm1p += m1p / len(testloader.dataset) m2p = output2.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm2p += m2p / len(testloader.dataset) m3p = output3.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm3p += m3p / len(testloader.dataset) m4p = output4.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm4p += m4p / len(testloader.dataset) m5p = output5.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm5p += m5p / len(testloader.dataset) m6p = output6.argmax(dim=1, keepdim=True)[0][0].tolist() # argmax로 최댓값의 인덱스 뽑기 fm6p += m6p / len(testloader.dataset) print() print(fm1p) print(fm2p) print(fm3p) print(fm4p) print(fm5p) print(fm6p) print() #진단 d_list = [] # 두피유형진단결과 #두피 유형 진단법 # ==0 은 1보다 작다로 변환, !=0은 1이상으로 변환 if fm1p < 1 and fm2p < 1 and fm3p < 1 and fm4p < 1 and fm5p < 1 and fm6p < 1 : d1 = '정상입니다.' d_list.append(d1) elif fm1p >= 1 and fm2p < 1 and fm3p < 1 and fm4p < 1 and fm5p < 1 and fm6p < 1 : d2 = '건성 두피입니다.' d_list.append(d2) elif fm1p < 1 and fm2p >=1 and fm3p < 1 and fm4p < 1 and fm5p < 1 and fm6p < 1 : d3 = '지성 두피입니다.' d_list.append(d3) elif fm2p < 1 and fm3p >= 1 and fm4p < 1 and fm5p < 1 and fm6p < 1 : d4 = '민감성 두피입니다.' d_list.append(d4) elif fm2p >= 1 and fm3p >= 1 and fm4p < 1 and fm6p < 1 : d5 = '지루성 두피입니다.' d_list.append(d5) elif fm3p < 1 and fm4p >= 1 and fm6p < 1 : d6 = '염증성 두피입니다.' d_list.append(d6) elif fm3p < 1 and fm4p < 1 and fm5p >= 1 and fm6p < 1 : d7 = '비듬성 두피입니다.' d_list.append(d7) elif fm1p < 1 and fm2p >= 1 and fm3p < 1 and fm4p < 1 and fm5p < 1 and fm6p >= 1 : d8 = '탈모입니다.' d_list.append(d8) else: d9 = '복합성 두피입니다.' d_list.append(d9) print(d_list[0]) #output_list.append(output); #test_loss += F.nll_loss(output, target, reduction = 'sum').item() # test_loss변수에 각 로스를 축적 #pred = output.argmax(dim=1, keepdim=True) # argmax : 리스트에서 최댓값의 인덱스를 뽑아줌 > y값아웃풋인덱 #correct += pred.eq(target.view_as(pred)).sum().item() # accuracy 측정을 위한 변수 # 각 예측이 맞았는지 틀렸는지 correct변수에 축적 맞을 때마다 +1 # # view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. # view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다. # pred.eq(data) : pred와 data가 일치하는지 검사 #test_loss /= len(testloader.dataset) # 로스축적된 로스를 데이터 수(경로안jpg수)로 나누기 #아큐러시 출력 ( :.4f 소수점반올림 ) #print('\nTest set Accuracy: {}/{} ({:.4f}%)\n'.format(correct, len(testloader.dataset), 100. * correct / len(testloader.dataset))) # 축적된 예측값을 데이터 개수로 나누기 *100 > 확률%값 #로스, 아큐러시 출력 #print('\nTest set: Average Loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(test_loss, correct, len(testloader.dataset), 100. * correct / len(testloader.dataset)))#출력 100%|██████████| 119/119 [01:10<00:00, 1.69it/s] 1.1512605042016801 1.1848739495798317 1.487394957983192 0.8991596638655458 0.8487394957983188 2.2689075630252065 복합성 두피입니다.탈모 레벨3 짜리 데이터 119개를 넣으니 탈모 모델에서는 2.26의 프레딕트값을 얻었다.
24. test accuracy
efficientNet 다른 모델로 바꿔도 컴터가 안 좋으니 이 정도가 한계다.
100%|██████████| 238/238 [04:38<00:00, 1.17s/it]
Test set Accuracy: 289/476 (60.71%)
100%|██████████| 331/331 [07:27<00:00, 1.35s/it]
Test set Accuracy: 411/662 (62.08%)
100%|██████████| 512/512 [12:15<00:00, 1.44s/it]
Test set Accuracy: 634/1024 (61.91%)
100%|██████████| 197/197 [04:26<00:00, 1.35s/it]
Test set Accuracy: 281/394 (71.32%)
100%|██████████| 310/310 [07:17<00:00, 1.41s/it]
Test set Accuracy: 370/620 (59.68%)
100%|██████████| 577/577 [12:32<00:00, 1.30s/it]
Test set Accuracy: 773/1154 (66.98%)

혹시 이 프로젝트에 관한오류가 발생하는걸로 질문하려고하는데 괜찮을까요..?