Introduction
Indexed and Extensible Files
The basic file system allocates files as a single extent, making it vulnerable to external fragmentation, that is, it is possible that an n-block file cannot be allocated even though n blocks are free (i.e. external fragmentation). Eliminate this problem by modifying the on-disk inode structure.
기존의 파일 시스템은 파일을 개별적으로 파일을 할당하기 때문에 n개의 블록이 가용한 상황에도 n-블록 파일은 할당될 수 없는 외부 단편화 문제를 유발한다. on-disk inode 구조를 수정함으로써 이러한 문제점을 해결한다.
In practice, this probably means using an index structure with direct, indirect, and doubly indirect blocks. (In previous semesters, most students adopted something like what you have learned as Berkeley UNIX FFS with multi-level indexing.) However, to make your life easier, we make you implement it in an easier way: FAT. You must implement FAT with given skeleton code. Your code MUST NOT contain any code for multi-level indexing (FFS in the lecture). You will receive 0pts for file growth parts.
direct, indirect, doubly indirect 블록을 사용하는 인덱스 구조를 통해 단편화 문제를 해결할 수 있다. FAT 인덱스 구조를 구현한다.
NOTE: You can assume that the file system partition will not be larger than 8 MB. You must support files as large as the partition (minus metadata). Each inode is stored in one disk sector, limiting the number of block pointers that it can contain.
파일 시스템 파티션은 최대 8MB의 크기를 초과하지 않는다. 각 inode는 한 디스크 섹터에 저장되며 블록 포인터의 수를 제한한다.
Indexing large files with FAT (File Allocation Table)
In the basic filesystem that you have used for the previous projects, a file was stored as a contiguous single chunk over multiple disk sectors. Let's call contiguous chunk as cluster, since a cluster (chunk) can contain one or more contiguous disk sectors. In this point of view, the size of a cluster in the basic file system was equal to the size of a file that stored in the cluster.
기존의 파일 시스템에서 파일은 여러 디스크 섹터에 걸쳐 인접한 chunk에 저장된다. 인접한 chunk를 클러스터라고 부르며 클러스터는 하나 이상의 인접한 디스크 섹터를 포함한다. 기존 파일 시스템에서 클러스터의 크기는 클러스터에 저장된 파일의 크기와 같다.
To mitigate external fragmentation, we can shrink the size of cluster (recall the page size in virtual memory). For simplicity, in our skeleton code, we fixed number of sectors in a cluster as 1. When we use smaller clusters like it, a cluster might not enough to store the entire file. In this case, we need multiple clusters for a file, so we need a data structure to index the clusters for a file in the inode. One of the easiest way is to use linked-list (a.k.a chain). An inode can contain the sector number of the first block of the file, and the first block may contain the sector number of the second block. This naïve approach, however, is too slow because we have to read every block of the file, even though what we really need was only the last block. To overcome this, FAT (File Allocation Table) puts the connectivity of blocks in a fixed-size File Allocation Table rather than the blocks themselves. Since FAT only contains the connectivity value rather than the actual data, its size is small enough to be cached in DRAM. As a result, we can just read corresponding entries in the table.
외부 단편화 문제를 해결하기 위해 클러스터의 크기를 줄인다. 한 클러스터에 하나의 섹터로 고정한다. 작은 크기의 클러스터를 사용하면 파일 전체를 저장하기에 부족할 수 있다. 이러한 경우 여러 클러스터를 사용하여 파일을 저장하며, 클러스터가 inode의 파일을 가리키기 위해 자료구조가 필요하다.
가장 간단한 방법은 연결 리스트를 사용하는 방법이다. inode는 파일의 첫 번째 블록의 섹터의 개수를 저장하며, 첫 번째 블록은 두 번째 블록의 섹터의 개수를 저장한다. 이러한 단순한 방식은 파일의 모든 블록을 읽어야 하기 때문에 느리다(비효율적이다). FAT는 고정된 크기의 file allocation table에 연결 블록을 사용한다. FAT는 실제 데이터 대신 connectivity value를 포함하기 때문에 크기가 작아 DRAM에 캐시되기에 적합하다. 따라서 테이블로부터 엔트리를 읽기만 하면 된다.

Extensible Files

Extensible Files 개요
현재 PintOS는 파일 생성 시 파일의 크기가 결정되고, 추후 변경이 불가능하다.
파일에 쓰기 동작을 수행할 때에 디스크 블록을 할당 받아 사용하도록 구현한다.
이를 통해 파일의 크기가 생성 시에 고정되지 않고 확장 가능하도록 한다.

디스크 블록 주소 표현 방식
struct inode_disk 구조체를 통해 파일을 표현한다.
파일 생성 시, 디스크 상에 연속된 블록을 할당 받는다.
start는 시작 블록번호를, length는 할당 된 블록의 길이를 의미한다.

블록번호 표현 방법 변경
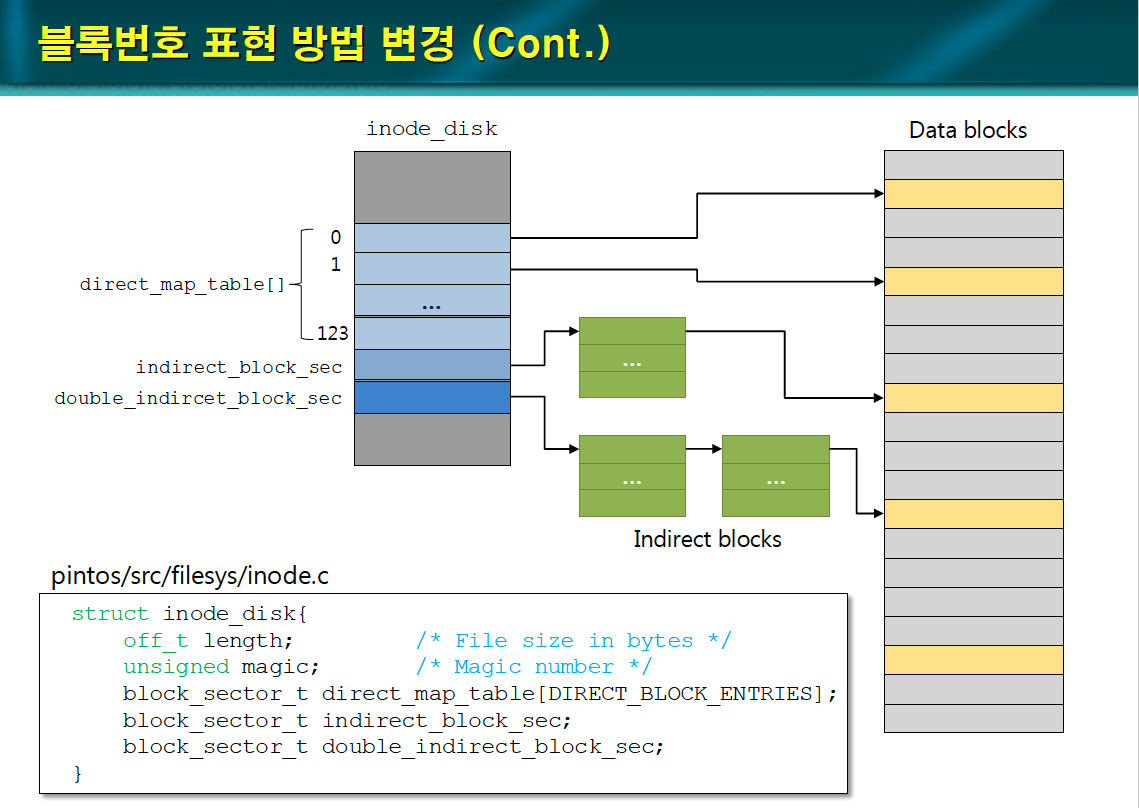
블록 위치를 direct, indirect, double indirect 방식으로 표현하도록 변경한다.
inode_disk 자료구조의 크기가 1 블록 크기가 되도록, direct 방식으로 표현할 블록의 수를 결정한다.

전역 변수 추가
INDIRECT_BLOCK_ENTRIES: 하나의 인덱스 블록이 저장할 수 있는 다음 인덱스 블록 번호의 개수로 값을 할당한다.
DIRECT_BLOCK_ENTRIES: inode에 direct 방식으로 저장할 블록번호의 개수로 inode_disk 자료구조의 크기가 1블록 크기(512 바이트)가 되도록 선언한다.

enum direct_t 변수 추가
enum direct_t 변수는 inode가 디스크 블록의 번호를 가리키는 방식들을 열거한다.

section_location 자료구조 추가
struct section_location 구조체는 블록 주소 접근 방식과 인덱스 블록 내의 오프셋 값을 저장한다.

파일 표현 방법 수정
struct inode_disk 구조체를 수정하여 인덱스 방식으로 블록 번호를 표현하도록 변경한다.
start와 unused[125] 필드를 제거하고 새로운 멤버를 추가한다.
-
direct_map_table: direct 방식으로 접근할 디스크 블록의 번호들이 저장된 배열
-
indirect_block_sec: indirect 방식으로 접근할 인덱스 블록의 번호
-
double_indirect_block_sec: double indirect 방식으로 접근할 경우, 1차 인덱스 블록의 번호
struct inode 자료구조 변경
inode 자료구조에서 data 변수를 제거하고 inode 접근 시 획득하는 세마포어 락(extend_lock)을 추가한다.

on-disk inode 획득 함수 구현
- get_disk_inode() 함수는 inode를 버퍼 캐시로부터부터 읽어서 전달한다.
inode -> sector: inode가 저장된 디스크 블록 번호
bc_read(): 버퍼 캐시로부터 디스크 블록 번호에 해당하는 데이터를 읽어오는 함수

인덱스 블록 내 오프셋 계산함수 구현
- locate_byte() 함수는 디스크 블록 접근 방법(direct, indirect, or double indirect)을 확인한다.
1차 인덱스 블록 내의 오프셋, 2차 인덱스 블록 내의 오프셋을 확인한다.
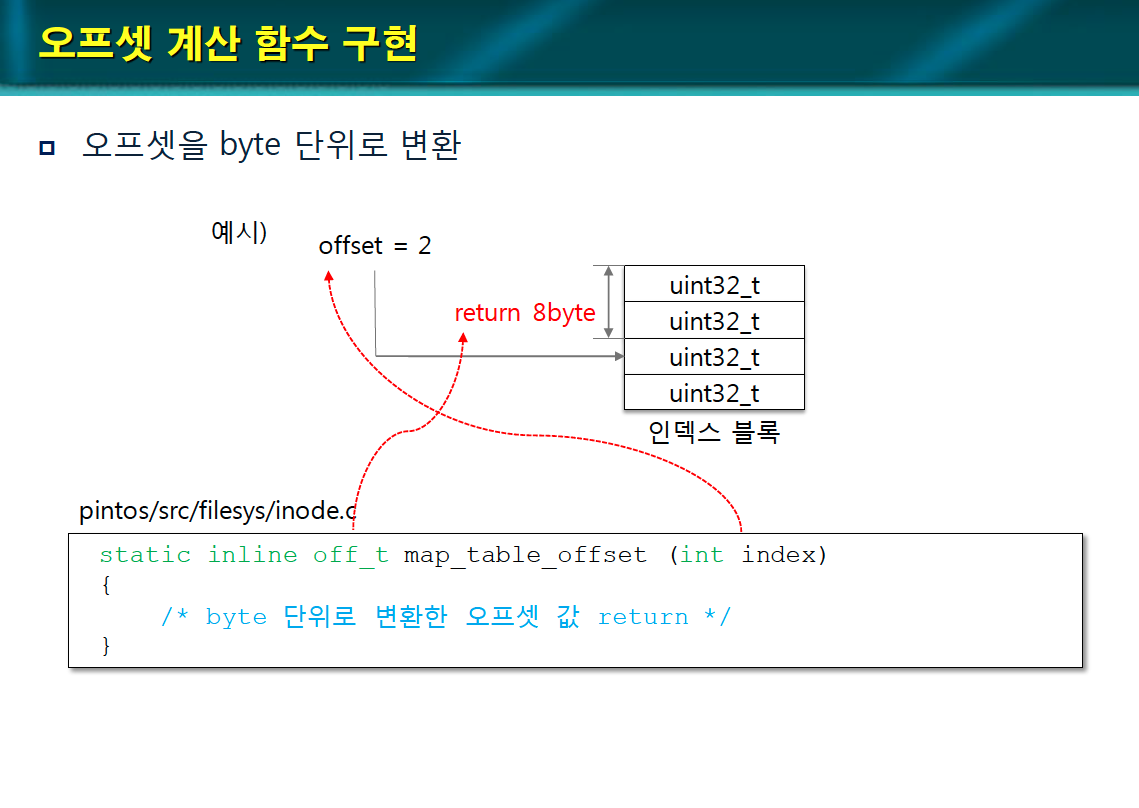
오프셋 계산 함수 구현
- map_table_offset() 함수는 오프셋을 byte 단위로 변환한다.

- register_sector() 함수는 새로 할당 받은 디스크 블록의 번호를 inode_disk에 업데이트한다.
-
inode_disk: 업데이트 할 inode
-
new_sector: 새로 할당 받은 디스크 블록 번호
-
sec_loc: 접근할 인덱스 블록 내의 오프셋 값을 나타내는 자료구조

파일 오프셋으로 블록 번호 검색 구현
- byte_to_sector() 함수는 파일 오프셋으로 on-disk inode를 검색하여 디스크 블록 번호를 반환한다.

파일 크기 업데이트 함수 구현
파일 오프셋이 기존 파일의 크기보다 클 경우, 새로운 디스크 블록을 할당하고 inode를 업데이트한다.
-
start_pos: 증가시켜야 하는 파일 영역의 시작 오프셋
-
end_pos: 증가시켜야 하는 파일 영역의 마지막 오프셋
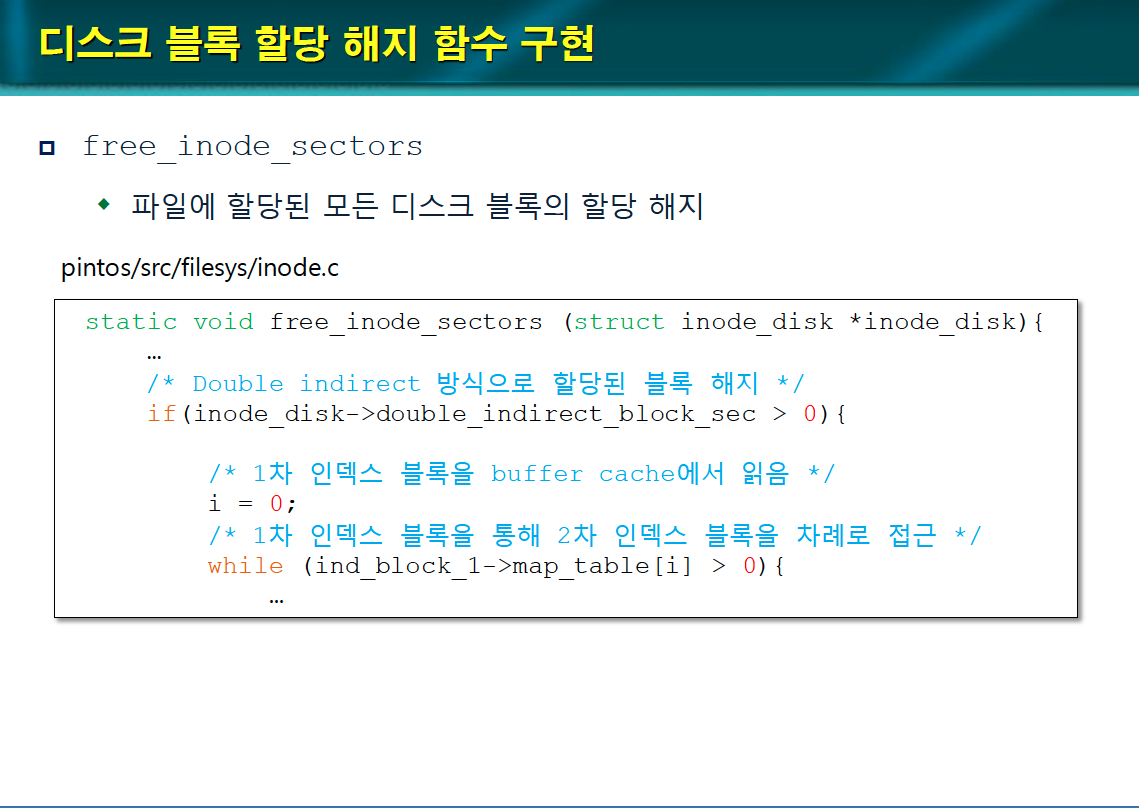
디스크 블록 할당 해지 함수 구현
- free_inode_sectors() 함수는 파일에 할당된 모든 디스크 블록의 할당을 해지한다.
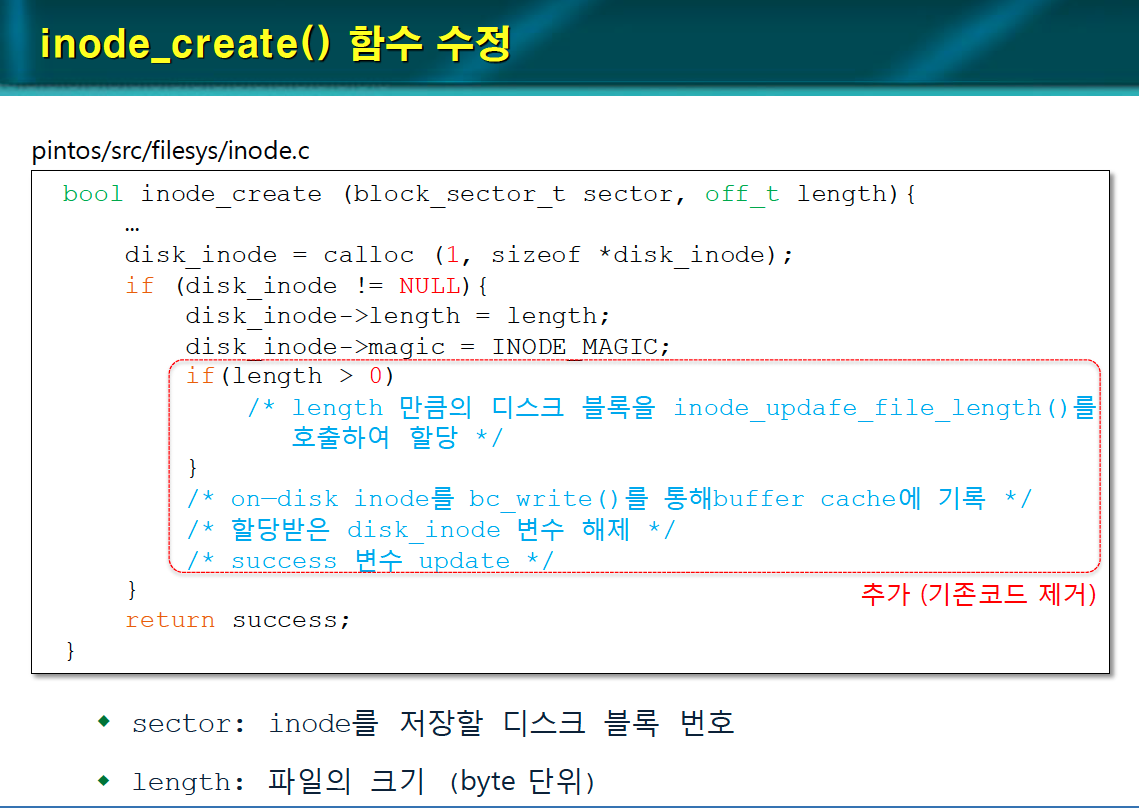
inode_create() 함수 수정
-
sector: inode를 저장할 디스크 블록 번호
-
length: 파일의 크기
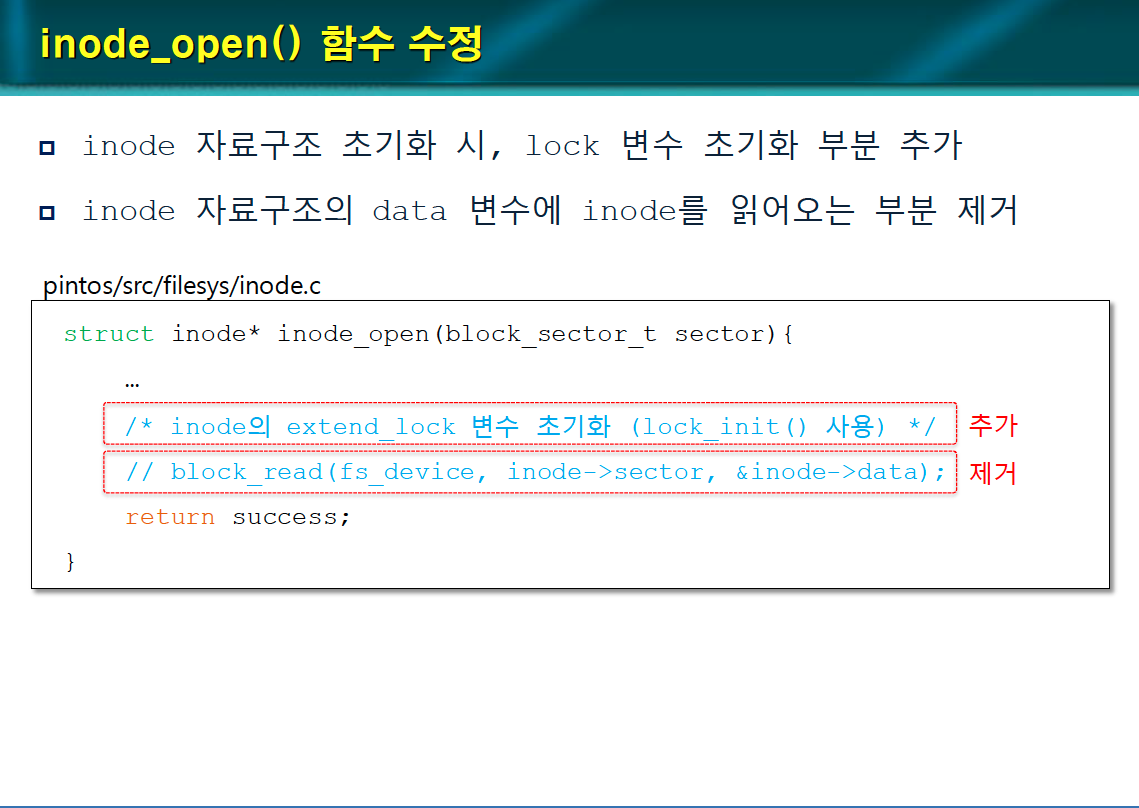
-
inode 자료구조 초기화 시, lock 변수를 초기화하는 부분을 추가한다.
-
inode 자료구조의 data 변수에 inode를 읽어오는 부분을 제거한다.
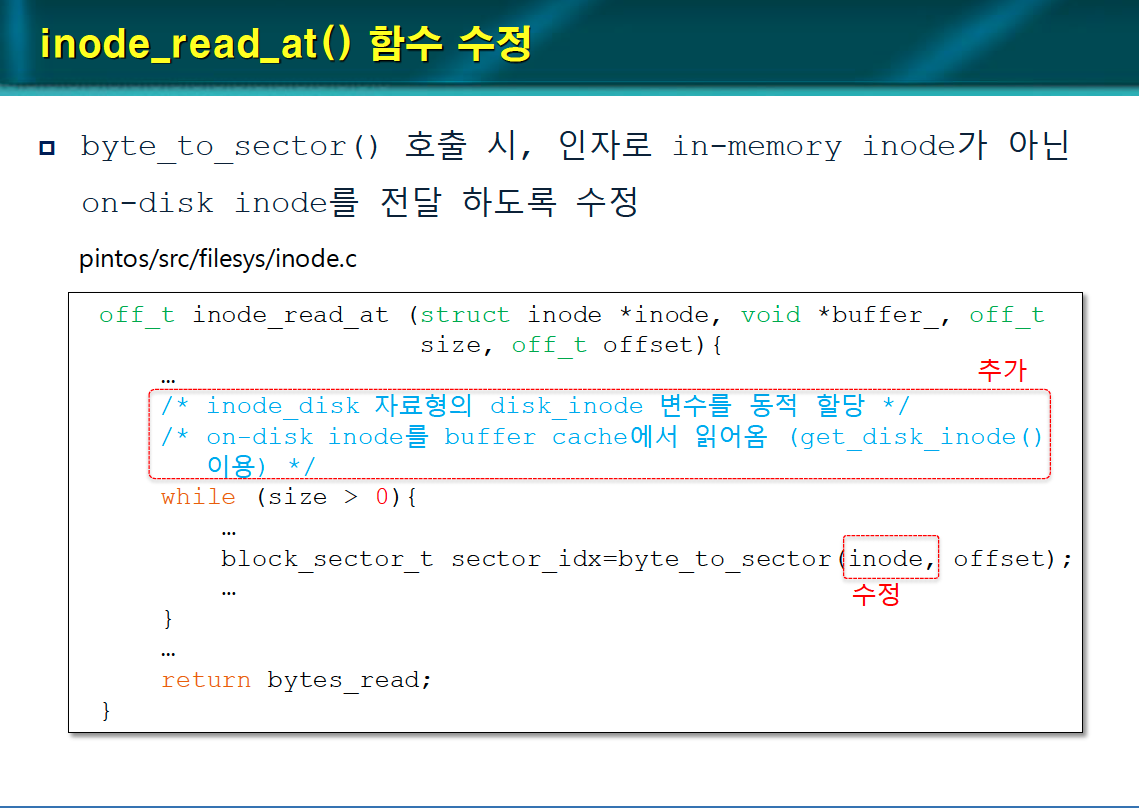
inode_reat_at() 함수 수정
byte_to_sector() 호출 시, 인자로 in-memory inode가 아닌 on-disk inode를 전달하도록 수정한다.
inode_disk 자료형의 disk_inode 변수를 동적 할당한다.
on-disk inode를 버퍼 캐시에서 읽어온다.
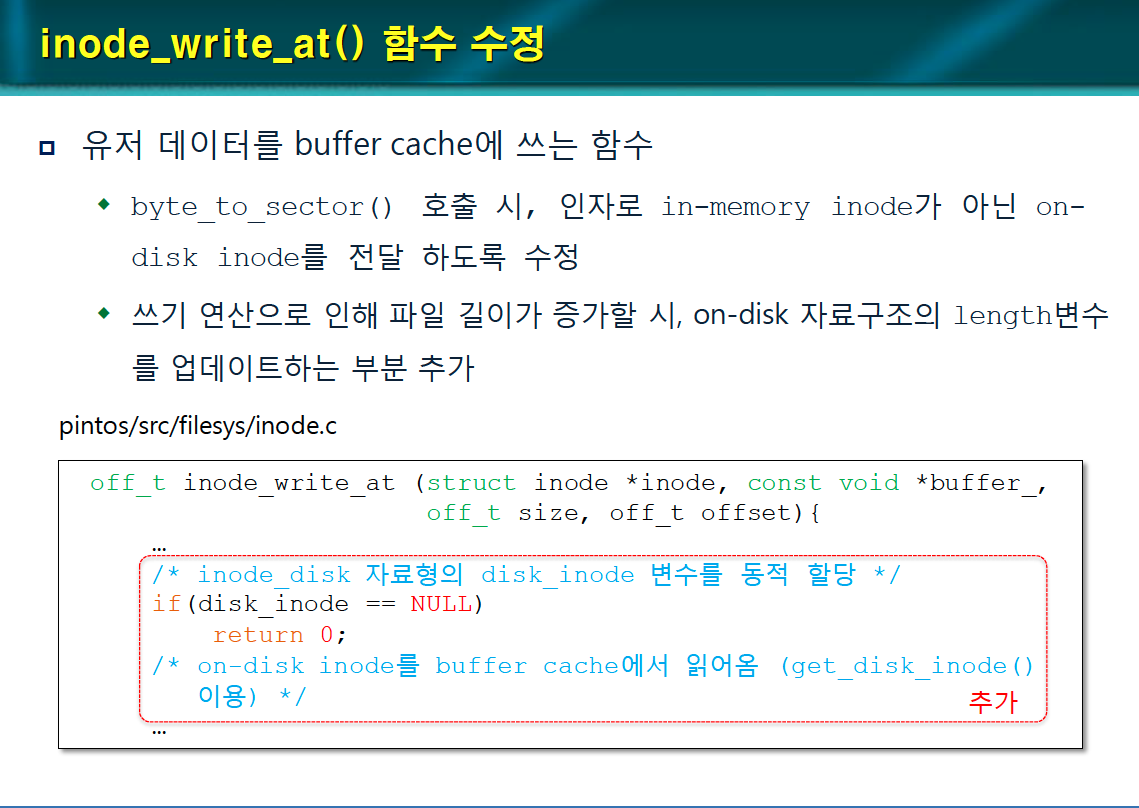
inode_write_at() 함수 수정
inode_write_at() 함수는 유저 데이터를 버퍼 캐시에 쓰는 함수이다.
byte_to_sector() 호출 시 인자로 in-memory inode가 아닌 on_disk inode를 전달하도록 수정한다.
쓰기 연산으로 인해 파일 길이가 증가할 시, on-disk 자료구조의 length 변수를 업데이트하도록 수정한다.
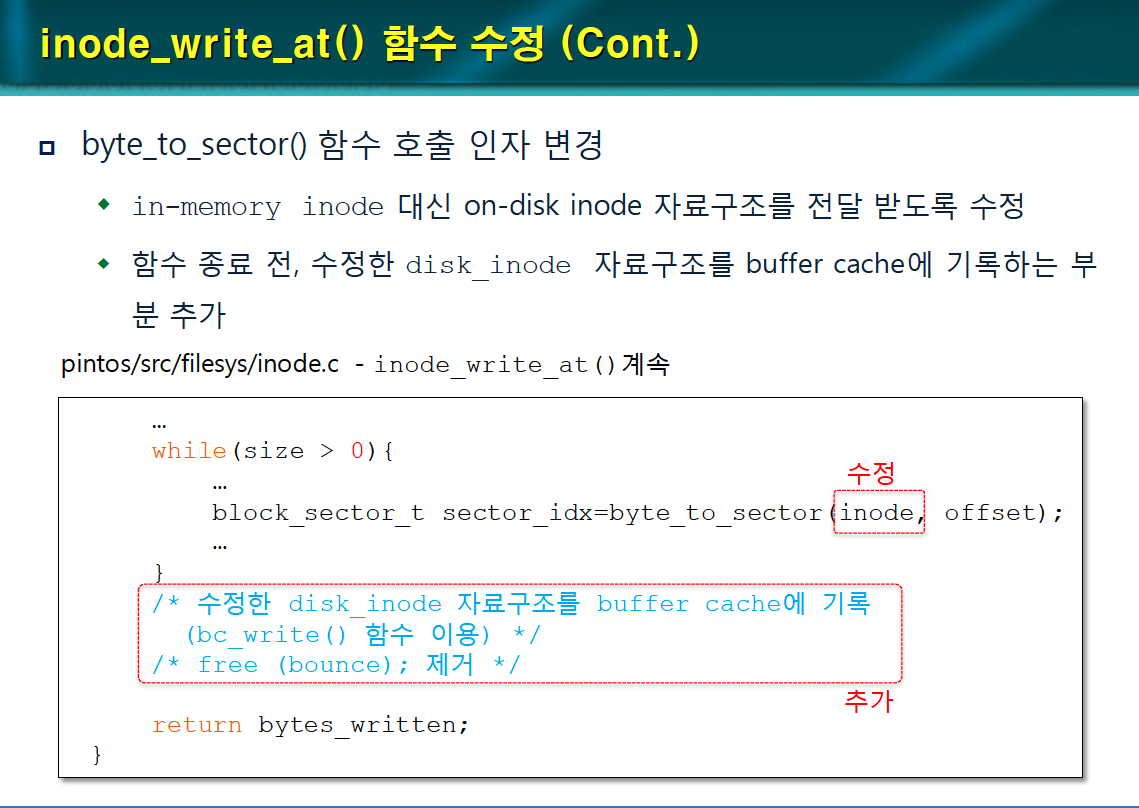
byte_to_sector() 함수 호출 인자 변경한다.
in-memory inode 대신 on-disk inode 자료구조를 전달 받도록 수정한다.
함수를 종료하기 전에 수정한 disk_inode 자료구조를 버퍼 캐시에 기록하도록 수정한다.
