[WEEK 08] PintOS - Project 1: Threads (Priority Scheduling) - Part 1. Synchronization
Today I Learned
Task 2: Priority Scheduling
Instructions
- Implement priority scheduling and priority donation in Pintos.
우선순위 스케줄링과 우선순위 기부 함수 구현
- When a thread is added to the ready list that has a higher priority than the currently running thread, the current thread should immediately yield the processor to the new thread.
현재 실행 중인 쓰레드보다 우선순위가 높은 쓰레드가 대기 리스트에 추가되는 경우, 현재 쓰레드는 프로세서 사용 권한을 새로운 쓰레드에게 즉시 양보한다.
- Similarly, when threads are waiting for a lock, semaphore, or condition variable, the highest priority waiting thread should be awakened first.
여러 쓰레드가 락, 세마포어, 조건 변수 등을 기다리는 경우 가장 높은 우선순위를 가진 대기 쓰레드가 가장 먼저 기상하도록 한다. (CPU를 점유한다.)
- A thread may raise or lower its own priority at any time, but lowering its priority such that it no longer has the highest priority must cause it to immediately yield the CPU.
쓰레드는 자신의 우선순위를 언제든 조정할 수 있지만 우선순위를 낮추는 것은 자신의 우선순위가 더이상 가장 우선순위가 높지 않다는 것을 의미하기 때문에 CPU 사용을 즉시 양보해야 한다.
- One issue with priority scheduling is "priority inversion".
"우선순위 전도"는 우선순위 스케줄링에서 고려해야 할 사항이다.
- A partial fix for this problem is for H to "donate" its priority to L while L is holding the lock, then recall the donation once L releases (and thus H acquires) the lock.
이러한 우선순위 문제를 해결하기 위한 해결 방안은 우선순위가 높은 쓰레드가 락을 가지고 있는 우선순위를 낮은 쓰레드에게 우선순위를 일시적으로 기부하는 것이다. 우선순위가 낮은 쓰레드가 락을 반환하면 기존의 우선순위를 되찾는다.
- You must also handle nested donation.
우선순위 이중 기부 상황 또한 고려해야 할 사항이다.
- If necessary, you may impose a reasonable limit on depth of nested priority donation.
필요하다면 우선순위 기부에서 합리적인 제한이 필요한 경우 깊이의 제한을 두어야 한다.
You must implement priority donation for locks.
락을 획득하기 위한 우선순위 기부를 구현해야 한다.
void thread_set_priority (int new_priority);Sets the current thread's priority to new priority. If the current thread no longer has the highest priority, yields.
현재의 쓰레드를 새로 추가된 쓰레드의 우선순위로 변경한다. 현재 쓰레드의 변경된 우선순위가 가장 우선순위가 높지 않은 경우 프로세서 사용을 양보한다.
int thread_get_priority (void);Returns the current thread's priority. In the presence of priority donation, returns the higher (donated) priority.
현재 쓰레드의 우선순위를 리턴한다. 우선순위의 기부가 이뤄지는 경우 기부받은 더 높은 우선순위를 리턴한다.
Backgrounds
쓰레드의 진행 흐름
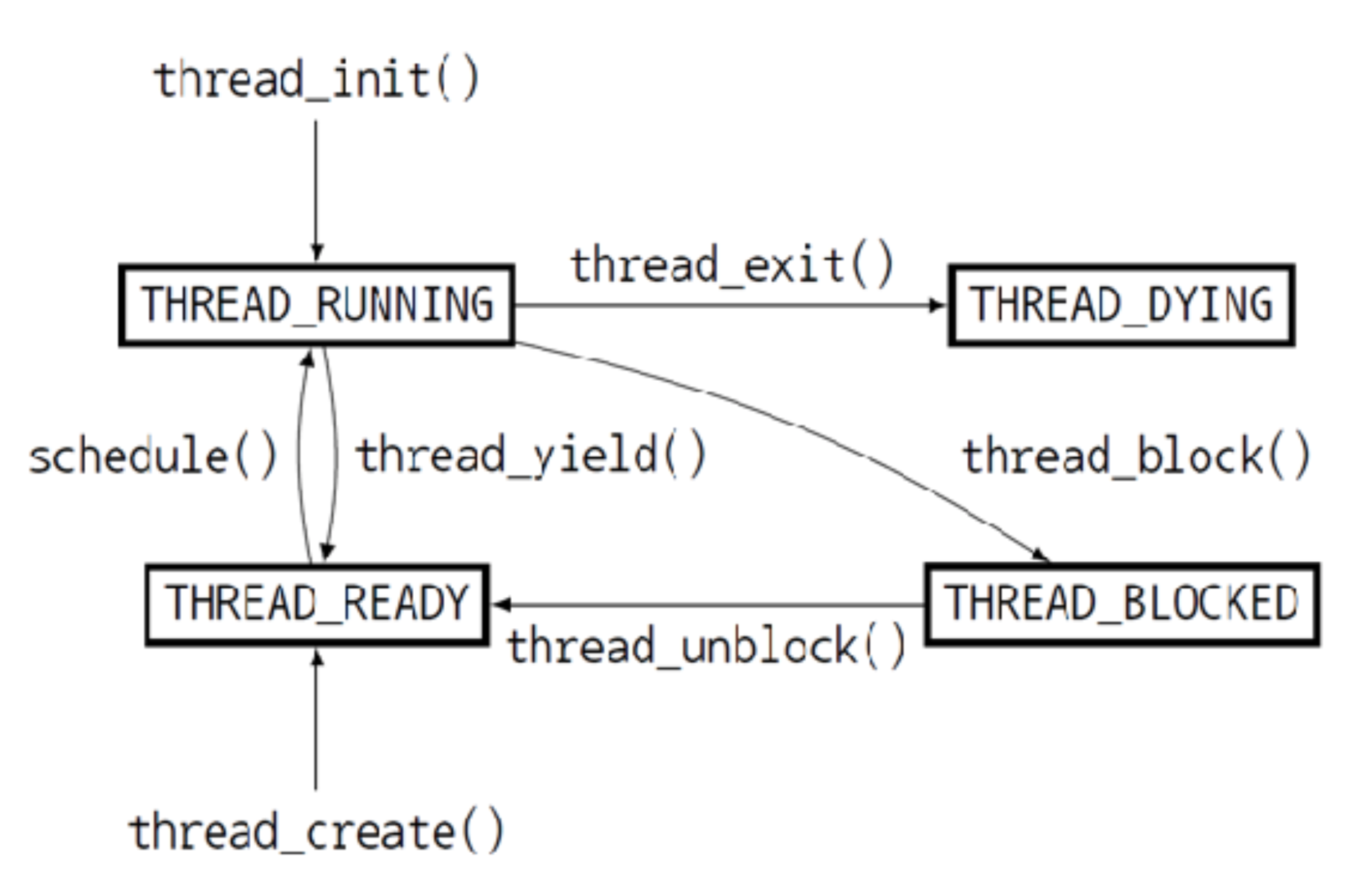
-
THREAD_RUNNING (실행): 현재 실행 중인 쓰레드를 의미하며 한 번에 하나의 쓰레드만이 RUNNING 상태일 수 있다.
-
THREAD_READY (준비): 실행될 준비가 되어 실행을 기다리고 있는 상태로 현재 실행 중인 쓰레드가 실행을 마치면 READY 상태인 쓰레드 중 한 쓰레드가 실행을 시작한다. READY 상태인 쓰레드들은 ready_list에 추가되어 관리된다.
-
THREAD_BLOCKED (불낙): 실행이 불가능한 상태로 thread_unblock() 함수를 통해 실행 가능한 상태로 전환되면 READY 상태가 되어 ready_list에 추가된다.
-
THREAD_DYING (임종): 실행이 종료된 상태이다.
쓰레드의 적용
쓰레드를 적용하는 데에는 OS 즉 커널 수준의 쓰레드가 쓰레드를 관리하는 방법과 프로세스 내 유저 수준에서 쓰레드를 관리하는 방법 두 가지 방법이 존재한다.
#### User-level Threads
The user-level threads are implemented by users and the kernel is not aware of the existence of these threads. It handles them as if they were single-threaded processes. User-level threads are small and much faster than kernel level threads. They are represented by a program counter(PC), stack, registers and a small process control block. Also, there is no kernel involvement in synchronization for user-level threads.
유저 수준의 쓰레드는 유저에 의해 실행되며 커널은 유저 수준의 쓰레드의 존재를 인식하지 못한다. 유저 수준의 쓰레드는 단일 쓰레드 프로세스로 취급되기 때문에 커널 수준의 쓰레드보다 작고 빠르다.
#### Kernel-level Threads
Kernel-level threads are handled by the operating system directly and the thread management is done by the kernel. The context information for the process as well as the process threads is all managed by the kernel. Because of this, kernel-level threads are slower than user-level threads.
커널 수준의 쓰레드는 운영체제와 커널에 의해 직접 관리된다. 프로세스의 컨텍스트 정보 또한 커널에 의해 관리된다. 그렇기 때문에 커널 수준의 쓰레드는 유저 수준의 쓰레드보다 느리다.
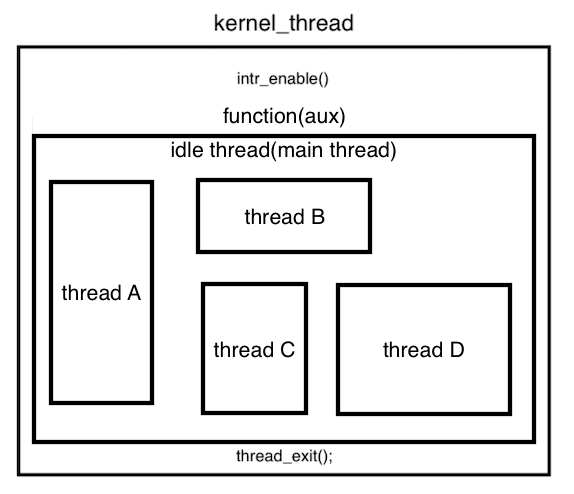
핀토스에서의 쓰레드는 커널 쓰레드를 의미하며 사용자 쓰레드는 user_thread라고 표현된다. 쓰레드와 관련된 함수들은 <thread.h>와 <thread.c> 파일에 작성되어 있다.
/* thread/thread.c */
/* Function used as the basis for a kernel thread. */
static void kernel_thread (thread_func *function, void *aux) {
ASSERT (function != NULL);
intr_enable (); /* The scheduler runs with interrupts off. */
function (aux); /* Execute the thread function. */
thread_exit (); /* If function() returns, kill the thread. */
}kernel_thread() 함수의 인자 thread_func *function은 커널이 실행할 함수를 가리킨다.
또다른 인자 void *aux는 보조 인자로 세마포어, 뮤텍스와 같은 동기화 기법 함수인 synchronization primitives가 입력된다.
실행시키는 함수는 해당 쓰레드가 종료될 때까지 실행하는 main 함수라고 생각할 수 있다.
이 함수는 idle thread라고 하는 쓰레드를 실행시키는데, C 프로그램의 하나의 main 함수 안에서 여러 함수의 호출들이 이루어지는 것처럼, 핀토스 커널 위에서 여러 쓰레드들이 동시에 실행될 수 있도록 하는 단 하나의 main thread라고 볼 수 있다. 따라서 우리의 목적은 idle thread 위의 여러 쓰레드들이 동시에 실행될 수 있도록 하는 것이다.
/* thread.c */
void thread_start(void) {
/* Create the idle thread. */
struct semaphore idle_started;
sema_init(&idle_started, 0);
thread_create("idle", PRI_MIN, idle, &idle_started);
/* Start preemptive thread scheduling. */
intr_enable();
/* Wait for the idle thread to initialize idle_thread. */
sema_down(&idle_started);
}init.c의 메인 코드에 작성된 thread_init() 함수에서 인자 thread에 입력되야 하는 여러 정보들을 초기화한 후 thread_start()에서 idle thread를 생성하면서 본격적으로 쓰레드를 시작한다.
thread_start() 함수에서 thread_create() 함수를 호출하는 순간 idle thread가 생성되고 동시에 idle() 함수가 실행된다. 이 과정에서 idle thread는 스케줄을 할당받고 sema_up 상태로 함수의 마지막에서 sema_down을 통해 thread_start() 함수가 작업을 마치면 run_action()이 실행될 수 있도록 해주고 idle thread 자신은 block 상태로 전환한다.
idle thread는 핀토스에서 실행 가능한 쓰레드가 없을 때 CPU가 하나 이상의 쓰레드가 실행하고 있는 상태를 만들기 위해 다시 작동한다.
static void idle(void *idle_started_ UNUSED) {
struct semaphore *idle_started = idle_started_;
idle_thread = thread_current();
sema_up(idle_started);
for (;;) {
/* Let someone else run. */
intr_disable ();
thread_block ();
asm volatile ("sti; hlt" : : : "memory");
}
}쓰레드 스케줄링
스케줄링은 하나의 쓰레드가 실행을 마치면 CPU를 사용할 다음 쓰레드를 결정할 때에 일어난다.
스케줄링은 thread_yield(), thread_block(), thread_exit()와 같은 스케줄링 함수가 실행될 때 일어난다.
이 함수들은 현재 쓰레드에서 호출해주어야 하는데, 실행 중인 쓰레드가 이 함수들을 실행시키지 않고 계속 CPU 소유권을 가지는 것을 방지하기 위한 타이머 인터럽트라는 장치가 존재한다.
/* Timer interrupt handler. */
static void timer_interrupt(struct intr_frame *args) {
ticks++;
thread_tick();
if (get_next_wakeup() <= ticks) {
thread_wakeup(ticks);
}
}타이머 인터럽트는 시간이 경과됨에 따라 ticks라는 변수를 증가시킨다. 매 tick마다 증가하는 ticks가 TIME_SLICE보다 커지는 순간 intr_yield_on_return() 인터럽트가 실행되는데, 이 인터럽트는 thread_yield() 함수를 실행시킨다.
따라서 스케줄링 함수가 호출되지 않더라도 일정 시간마다 스케줄링이 자동으로 발생한다.
static void schedule(void) {
struct thread *curr = running_thread();
struct thread *next = next_thread_to_run();
struct thread *prev = NULL;
ASSERT (intr_get_level() == INTR_OFF);
ASSERT (curr -> status != THREAD_RUNNING);
ASSERT (is_thread (next));
/* Mark us as running. */
next -> status = THREAD_RUNNING;
/* Start new time slice. */
thread_ticks = 0;
if (curr != next)
prev = switch_threads(curr, next);
thread_schedule_tail(prev);curr은 현재 실행 중인 쓰레드 next는 next_thread_to_run() 함수(ready queue에서 다음에 실행될 쓰레드를 robin-round 방식으로 고른다.)에 의해 다음에 실행될 쓰레드를 가리킨다. *prev는 현재 실행 쓰레드가 CPU의 소유권을 next 쓰레드에게 양보한 후 현재 쓰레드를 가리키게 되는 포인터다.
- ASSERT (intr_get_level() == INTR_OFF): 스케줄링 도중에는 인터럽트가 발생하면 안되기 때문에 INTR_OFF 상태인지 확인한다.
- ASSERT (curr -> status != THREAD_RUNNING): CPU 소유권을 양보하기 전에 실행 중인 쓰레드가 스케줄링 함수에 의해 실행 중이 아닌 다른 상태로 바뀌어야 하고 이를 확인한다.
- ASSERT (is_thread(next)): next_thread_to_run()에 의해 올바른 쓰레드가 리턴되었는지 확인한다.
다음 실행할 쓰레드를 정하면 switch(curr, next) 명령어를 실행한다. switch()는 <threads/switch.s>에서 어셈블리어로 작성된 우선순위 스케줄링 과제에서 핵심적인 함수이다.
CPU와 범용 레지스터
CPU의 구성
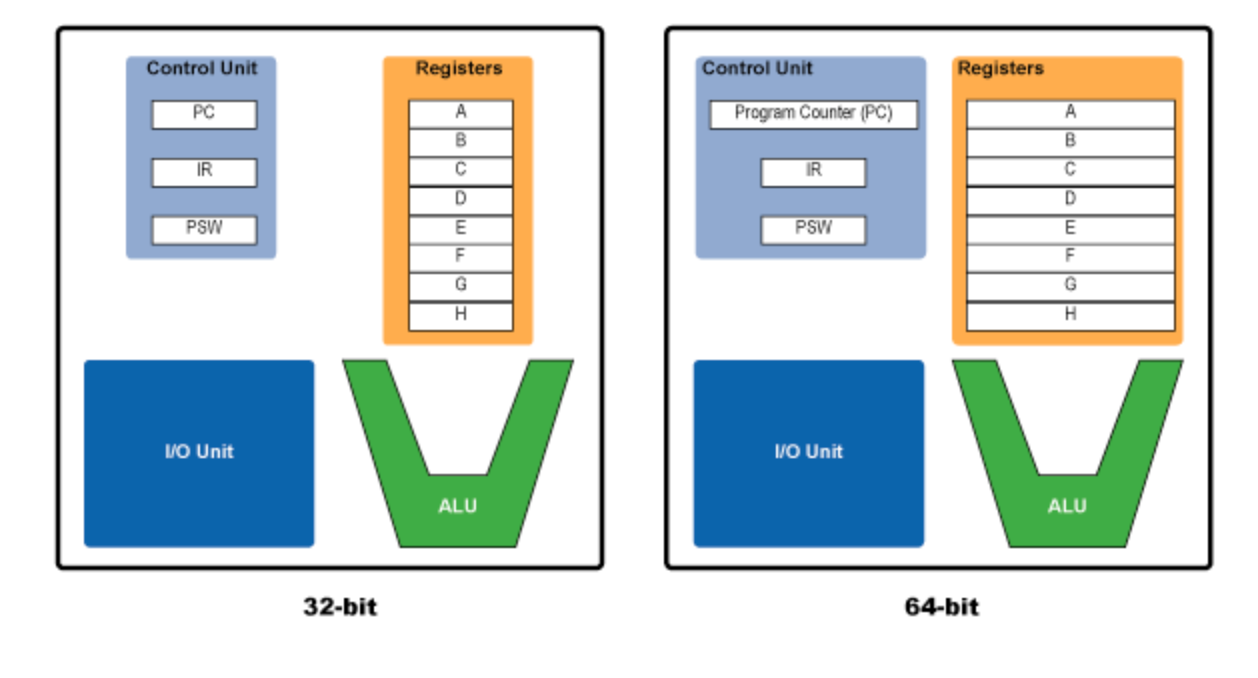
Control Unit은 CPU를 제어하는 장치, I/O Unit은 입출력 장치를 관리하고 ALU는 연산을 처리하는 장치이다. 그 외에 CPU에는 레지스터라는 작은 저장공간들이 존재하며 이들은 CPU가 데이터에 접근하는 가장 빠른 방법을 제공한다. x86 장치에서 CPU는 8개의 범용 레지스터가 CPU의 효율적인 작업을 위해 용도에 맞게 설계되어 있다.
EAX(Extended Accumulator Register): 산술연산 또는 함수의 리턴 값 저장. 이 레지스터의 값을 살펴보면 함수의 리턴 여부, 리턴 값을 알 수 있다.
EDX(Extended Data Register): EAX 의 확장 개념으로 복잡한 연산의 추가 데이터 저장을 위해 사용된다.
ECX(Extended Counter Register): 반복적으로 수행되는 연산에 사용되는 카운터 값이 저장된다. 항상 감소되는 방향으로 설계되어 있다.
ESI(Extended Source Index): 데이터 연산에서 데이터의 source, 즉 입력 데이터의 앖 혹은 입력 스트림의 위치를 나타낸다. 주로 Read 작업을 위해 사용된다.
EDI(Extended Destination Index): 데이터 연산에서 데이터의 destination, 즉 연산의 결과값의 위치를 나타낸다. 주로 Write 작업을 위해 사용된다.
ESP(Extended Stack Pointer): 스택의 가장 높은(최근 PUSH된) 위치를 가리킨다. 함수 호출 시 리턴 주소가 가장 마지막에 PUSH 되므로 함수 호출 직후 ESP는 보통 리턴 주소를 가리킨다.
EBP(Extended Base Pointer): ESP와 반대로 스택의 시작점을 가리킨다.
EBX : 특정 용도 X, 추가적인 저장소로써 사용된다.
EIP : 현재 실행중인 명령의 주소를 가리킨다.
각 쓰레드는 하나의 페이지에 저장되며 그 구조는 <thread/thread.h>에 저장되어 있다.
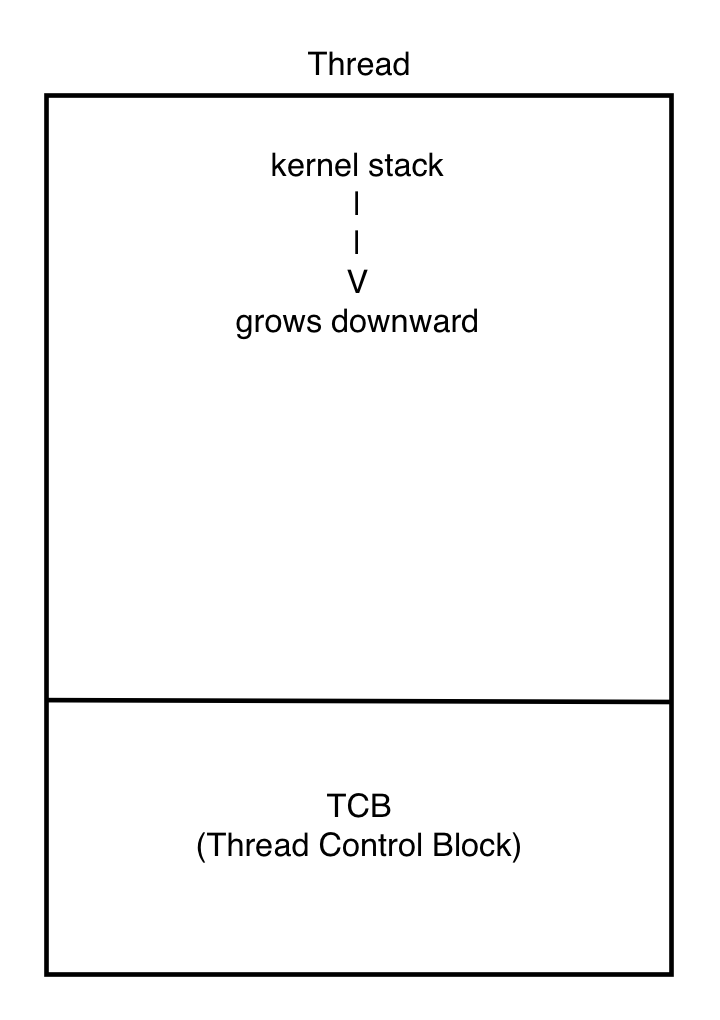
쓰레드는 쓰레드의 정보를 저장하는 TCB 영역과 여러 정보를 저장하는 kernel stack 영역으로 나누어져 있다.
TCB 영역은 offset 0에서 시작하여 1KB를 넘지 않는 작은 크기를 차지하고, kernel stack 영역은 나머지를 차지하며 TCB 영역을 침범하지 않기 위해 위에서 아래로 저장한다.
struct thread
{
/* Owned by thread.c. */
tid_t tid; /* Thread identifier. */
enum thread_status status; /* Thread state. */
char name[16]; /* Name (for debugging purposes). */
uint8_t *stack; /* Saved stack pointer. */
int priority; /* Priority. */
struct list_elem allelem; /* List element for all threads list. */
/* Shared between thread.c and synch.c. */
struct list_elem elem; /* List element. */
#ifdef USERPROG
/* Owned by userprog/process.c. */
uint32_t *pagedir; /* Page directory. */
#endif
/* Owned by thread.c. */
unsigned magic; /* Detects stack overflow. */
};TCB 영역은 위와 같이 구성되어 있다.
stack이라는 포인터는 현재 실행 중인 쓰레드가 스케줄링에 의해 다른 상태로 전환하면 현재 CPU가 실행 중이던 상태, 즉 현재 CPU의 레지스터들에 저장된 값들을 이 stack에 저장한다. 현재 쓰레드가 이후 다시 실행되면 stack에 저장된 값들이 다시 CPU의 레지스터로 로드되어 실행을 이어갈 수 있게 된다. stack은 kernel stack의 특정 부분에 저장되기 때문에 stack 포인터는 kernel stack의 특정 부분을 가리킨다.
Implementations - Part 1
우선순위 스케줄링의 목적은 ready 상태인 쓰레드들의 순서를 관리하여 가장 높은 우선순위를 가진 쓰레드가 running 상태가 될 수 있도록 만들어주는 것이다.
현재 스케줄링의 상태를 확인하기 위해서 ready_list에 새로운 쓰레드가 추가(push)되는 순간을 확인한다.
void thread_unblock(struct thread *t) {
enum intr_level old_level;
ASSERT(is_thread (t));
old_level = intr_disable ();
ASSERT (t -> status == THREAD_BLOCKED);
list_push_back(&ready_list, &t -> elem);
t -> status = THREAD_READY;
intr_set_level(old_level);
}void thread_yield(void) {
struct thread *curr = thread_current ();
enum intr_level old_level;
ASSERT (!intr_context());
old_level = intr_disable();
if (curr != idle_thread)
list_push_back(&ready_list, &curr -> elem);
do_schedule(THREAD_READY);
intr_set_level(old_level);
}ready_list에 새로운 쓰레드가 추가되는 두 함수에서 공통적으로 list_push_back 함수가 사용된다. list_push_back() 함수는 새로운 elem을 리스트 맨 뒤에 push한다. 현재 핀토스는 새로운 쓰레드를 ready_list의 맨 뒤에 추가한다는 것을 의미한다.
마찬가지로 대기열에 있는 쓰레드를 어떤 방식으로 꺼내는지도 확인한다. 현재 실행 중인 쓰레드가 CPU를 양보하여 다음에 실행할 쓰레드를 고르는 순간을 보면 알 수 있다. thread_exit(), thread_yield(), thread_block() 세 개의 함수에서 이러한 과정이 이루어진다.
void thread_exit(void) {
ASSERT (!intr_context ());
#ifdef USERPROG
process_exit ();
#endif
/* Just set our status to dying and schedule another process.
We will be destroyed during the call to schedule_tail(). */
intr_disable();
do_schedule(THREAD_DYING);
NOT_REACHED();
}void thread_yield(void) {
struct thread *curr = thread_current();
enum intr_level old_level;
ASSERT (!intr_context());
old_level = intr_disable();
if (curr != idle_thread)
list_push_back(&ready_list, &curr -> elem);
do_schedule(THREAD_READY);
intr_set_level(old_level);
}void thread_block(void) {
ASSERT(!intr_context());
ASSERT(intr_get_level() == INTR_OFF);
thread_current() -> status = THREAD_BLOCKED;
schedule();
}따라서 현재 핀토스의 스케줄링은 우선순위를 고려하지 않고 ready_list의 맨 뒤에 새로운 쓰레드를 push하고, 맨 앞에서 pop하는 robin-round 방식을 채택하고 있다는 것을 알 수 있다.
Priority Scheduling 구현
우선순위 스케줄링은 두 가지 방법으로 구현할 수 있다.
- ready_list에 push할 때 우선순위 순으로 push하는 방법
- ready_list에서 pop할 때 우선순위 순으로 pop하는 방법
첫 번째 방법은 ready_list가 항상 정렬된 상태를 유지하고 두 번째 방법은 pop할 때마다 전체 쓰레드의 우선순위를 확인해야 하므로 첫 번째 방법이 더 효율적이다.
첫 번째 방법에서 ready_list의 맨 앞의 쓰레드를 pop하는 방법을 유지하기 때문에 next_thread_to_run() 함수는 변경하지 않는다.
list_push_back() 함수가 포함된 thread_yield() 함수와 thread_unblock() 함수를 수정해야 한다.
thread_create() 함수에서도 새로운 쓰레드가 ready_list에 추가되지만 thread_unblock() 함수를 포함하고 있기 때문에 thread_create() 함수를 수정할 필요는 없다.
list_push_back() 함수에서 내림차순으로 정렬하여 push하는 부분을 수정해야 한다.
void list_push_back (struct list *list, struct list_elem *elem) {
list_insert (list_end (list), elem);
}list_push_back() 함수에는 list_insert 함수가 포함되어 있다.
void list_insert (struct list_elem *before, struct list_elem *elem) {
ASSERT (is_interior(before) || is_tail(before));
ASSERT (elem != NULL);
elem -> prev = before -> prev;
elem -> next = before;
before -> prev -> next = elem;
before -> prev = elem;
}
void list_insert_ordered (struct list *list, struct list_elem *elem, list_less_func *less, void *aux) {
struct list_elem *e;
ASSERT (list != NULL);
ASSERT (elem != NULL);
ASSERT (less != NULL);
for (e = list_begin(list); e != list_end(list); e = list_next(e))
if (less(elem, e, aux))
break;
return list_insert(e, elem);
}list_insert_ordered() 함수는 ready_list에 정렬된 상태로 추가하는 함수이다. insert할 list와 추가할 elem과 비교 함수 less를 인자로 입력한다. for 반복문을 통해 입력 받은 elem이 less 함수를 통과하면
list_insert() 함수에서 해당 elem을 추가하는 위치가 e의 앞인지 뒤인지 확인해야 한다. elem -> next = before은 elem이 e의 앞에 삽입된다는 것을 의미한다. ready_list에서 쓰레드를 pop할 때 가장 앞에서 꺼내기 때문에 ready_list의 앞에는 가장 우선순위가 높은 쓰레드가 와야 한다.
list_insert()가 실행되는 순간 elem은 e의 앞으로 삽입되기 때문에 내림차순으로 정렬하기 위해선 if (less(elem, e, aux))가 elem > e인 경우 break;를 실행해주어야 한다.
ready_list의 쓰레드들을 우선순위 내림차순으로 정렬하기 위해서 현재 쓰레드와 우선순위를 비교하는 thread_compare_priority() 함수를 생성한다.
bool thread_compare_priority (struct list_elem *l, struct list_elem *s, void *aux) {
return list_entry(l, struct thread, elem) -> priority > list_entry(s, struct thread, elem) -> priority;
}생성한 thread_compare_priority() 함수를 이용하여 list_push_back()을 list_insert_ordered()로 대체한다.
현재 실행 중인 쓰레드의 우선순위가 바뀌는 경우를 고려해야 한다. 이 때 실행 중인 쓰레드의 바뀐 우선순위가 ready_list의 가장 우선순위가 높은 쓰레드의 우선순위보다 낮은 경우 CPU를 양보해야 한다.
현재 실행 중인 쓰레드의 우선순위가 바뀌는 경우는 thread_create()와 thread_set_priority() 두 가지 경우이다.
thread_create()와 thread_set_priority() 두 함수의 마지막에 실행 중인 쓰레드와 ready_list의 가장 앞에 있는 쓰레드의 우선순위를 비교하여 우선순위가 더 높으면 CPU 사용을 양보하는 함수를 추가한다.
void thread_test_preemption(void) {
if (!list_empty(&ready_list) && thread_current() -> priority <
list_entry(list_front(&ready_list), struct thread, elem) -> priority)
thread_yield();
}tid_t thread_create(const char *name, int priority, thread_func *function, void *aux) {
struct thread *t;
tid_t tid;
ASSERT (function != NULL);
/* Allocate thread. */
t = palloc_get_page(PAL_ZERO);
if (t == NULL)
return TID_ERROR;
/* Initialize thread. */
init_thread (t, name, priority);
tid = t -> tid = allocate_tid();
/* Call the kernel_thread if it scheduled.
* Note) rdi is 1st argument, and rsi is 2nd argument. */
t -> tf.rip = (uintptr_t)kernel_thread;
t -> tf.R.rdi = (uint64_t)function;
t -> tf.R.rsi = (uint64_t)aux;
t -> tf.ds = SEL_KDSEG;
t -> tf.es = SEL_KDSEG;
t -> tf.ss = SEL_KDSEG;
t -> tf.cs = SEL_KCSEG;
t -> tf.eflags = FLAG_IF;
/* Add to run queue. */
thread_unblock(t);
thread_test_preemption();
return tid;
}void thread_set_priority(int new_priority) {
thread_current() -> priority = new_priority;
thread_test_preemption();
}Implementations - Part 2
우선순위 스케줄링을 구현하기 위해 사용할 세마포어, 락, 조건 변수 세 가지의 동기화 도구들은 synch.h와 synch.c 파일에 구현되어 있다.
semaphore 구조체는 공유 자원의 개수를 나타내는 value와 공유 자원을 사용하기 위해 대기하는 waiters의 리스트를 멤버로 구성되어 있다.
lock 구조체는 value = 1인 특별한 세마포어로 구현되어 있고, 현재 lock을 가지고 있는 쓰레드의 정보와 세마포어 semaphore를 멤버로 가진다.
condition 구조체는 condition variables를 기다리는 waiters의 리스트를 멤버로 가진다.
Semaphore
세마포어를 예시로 생각하면, 하나의 공유 자원을 사용하기 위해 sema_down 상태로 대기하고 있을 때, 공유 자원을 사용하고 있던 쓰레드가 자원의 사용을 마치고 sema_up할 때 어떤 쓰레드가 가장 먼저 공유 자원을 사용할 것인가에 대한 문제를 스케줄링을 이용해 해결해야 한다.
세마포어를 다루는 함수는 sema_down과 sema_up 두 가지 함수이다.
공유 자원 사용을 마친 쓰레드는 sema_up을 이용해 thread_unblock을 실행하는데 list_pop_front() 함수로 대기열의 가장 앞에 있는 쓰레드를 꺼낸다.
기존 방식을 우선순위 내림차순으로 가장 높은 우선순위를 가진 쓰레드가 실행될 수 있도록 새로운 쓰레드가 추가될 때 ready_list가 우선순위 내림차순으로 정렬되도록 수정해야 한다.
void sema_down(struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
ASSERT (!intr_context());
old_level = intr_disable();
while (sema->value == 0) {
list_insert_ordered (&sema->waiters, &thread_current ()->elem, thread_compare_priority, 0);
thread_block ();
}
sema -> value--;
intr_set_level(old_level);
}기존의 방식에서 공유 자원을 사용하고자 하는 쓰레드는 sema_down을 실행하고, 사용 가능한 자원이 없는 경우 sema -> waiters 리스트에 list_push_back() 함수를 통해 ready_list의 맨 뒤에 추가된다. list_insert_ordered()를 list_push_back() 대신 사용하여 추가되는 방식을 변경한다.
void sema_up(struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
old_level = intr_disable();
if (!list_empty(&sema -> waiters))
list_sort(&sema -> waiters, thread_compare_priority, 0);
thread_unblock (list_entry(list_pop_front(&sema->waiters), struct thread, elem));
sema->value++;
thread_test_preemtion();
intr_set_level (old_level);
}sema_up()에서는 waiters 리스트의 쓰레드들의 우선순위의 변화가 생겼을 경우를 고려하여 list_sort()를 사용하여 우선순위 내림차순으로 정렬한다. 또한 thread_test_preemtion()을 사용하여 실행 중인 쓰레드의 우선순위가 ready_list에서 가장 높은 우선순위를 가진 쓰레드와 비교하여 후자의 우선순위가 더 높다면 CPU를 양보한다.
Lock
락을 다루는 함수는 sema_down과 sema_up 두 가지 함수이다. lock은 value = 1이고, holder의 정보를 가지고 있다는 것을 제외하고는 세마포어와 동일하게 작동하기 때문에 기존에 구현된 lock_acquire()과 lock_release() 함수를 수정할 필요가 없다.
void lock_acquire(struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context());
ASSERT (!lock_held_by_current_thread(lock));
sema_down (&lock -> semaphore);
lock -> holder = thread_current();
}void lock_release(struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread(lock));
lock -> holder = NULL;
sema_up(&lock -> semaphore);
}Condition Variables
조건 변수를 다루는 함수는 cond_wait()과 cond_signal() 두 가지 함수이다. 조건 변수 또한 waiters 리스트를 가진다. 그러나 세마포어에서의 waiters 리스트는 쓰레드들의 리스트인 반면에 조건 변수의 waiters 리스트는 세마포어의 리스트라는 점에서 다르다.
void cond_wait(struct condition *cond, struct lock *lock) {
struct semaphore_elem waiter;
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context());
ASSERT (lock_held_by_current_thread(lock));
sema_init(&waiter.semaphore, 0);
list_insert_ordered(&cond -> waiters, &waiter.elem, sema_compare_priority, 0);
lock_release(lock);
sema_down(&waiter.semaphore);
lock_acquire(lock);
}cond_wait() 함수에서 list_push_back()을 이용해 cond -> waiters 리스트에 추가하는데 인자 waiter는 함수의 최상단에서 선언한 구조체 semaphore_elem의 waiter이다. 조건 변수가 달성되기를 기다리는 여러 세마포어들의 리스트 중 가장 우선순위가 높은 세마포어를 깨워야 한다. 이미 세마포어 함수에서 쓰레드들이 우선순위 내림차순으로 정렬되었기 때문에 각 세마포어의 waiters 리스트에는 가장 우선순위가 높은 쓰레드들이 가장 앞에 위치해 있다. 이들과 비교하여 가장 높은 우선순위를 가진 쓰레드를 가진 세마포어를 깨운다.
void cond_signal(struct condition *cond, struct lock *lock UNUSED) {
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context());
ASSERT (lock_held_by_current_thread(lock));
if (!list_empty(&cond -> waiters)) {
list_sort(&cond -> waiters, sema_compare_priority, 0);
sema_up(&list_entry(list_pop_front(&cond -> waiters), struct semaphore_elem, elem) -> semaphore);
}
}bool sema_compare_priority(const struct list_elem *l, const struct list_elem *s, void *aux UNUSED) {
struct semaphore_elem *l_sema = list_entry(l, struct semaphore_elem, elem);
struct semaphore_elem *s_sema = list_entry(s, struct semaphore_elem, elem);
struct list *waiter_l_sema = &(l_sema -> semaphore.waiters);
struct list *waiter_s_sema = &(s_sema -> semaphore.waiters);
return list_entry(list_begin(waiter_l_sema), struct thread, elem) -> priority > list_entry(list_begin(waiter_s_sema), struct thread, elem) -> priority;
}sema_compare_priority() 함수는 semaphore_elem.elem을 인자로 입력 받으면 list_entry()로 semaphore_elem 구조체를 구하여 저장하고 이 구조체를 가지는 semaphore의 waiters 리스트를 가져온다. 이 waiters 리스트의 가장 앞에 위치한 element 쓰레드의 우선순위를 비교하여 반환한다.
cond_wait() 함수는 list_push_back()을 대신하여 list_insert_ordered() 함수에 sema_compare_priority() 함수를 이용해 가장 우선순위가 높은 쓰레드가 포함된 세마포어가 내림차순으로 정렬해 가장 앞에 위치하도록 cond -> waiters 리스트에 push한다.
cond_signal() 함수도 마찬가지로 wait 도중에 우선순위가 바뀌었을 경우를 고려하여 list_sort()를 이용해 내림차순으로 정렬하고 sema_up()으로 가장 앞에 위치한 세마포어를 깨운다.
pass tests/threads/alarm-single
pass tests/threads/alarm-multiple
pass tests/threads/alarm-simultaneous
pass tests/threads/alarm-priority
pass tests/threads/alarm-zero
pass tests/threads/alarm-negative
pass tests/threads/priority-change
FAIL tests/threads/priority-donate-one
FAIL tests/threads/priority-donate-multiple
FAIL tests/threads/priority-donate-multiple2
FAIL tests/threads/priority-donate-nest
FAIL tests/threads/priority-donate-sema
FAIL tests/threads/priority-donate-lower
pass tests/threads/priority-fifo
pass tests/threads/priority-preempt
pass tests/threads/priority-sema
pass tests/threads/priority-condvar
FAIL tests/threads/priority-donate-chain
FAIL tests/threads/mlfqs/mlfqs-load-1
FAIL tests/threads/mlfqs/mlfqs-load-60
FAIL tests/threads/mlfqs/mlfqs-load-avg
FAIL tests/threads/mlfqs/mlfqs-recent-1
pass tests/threads/mlfqs/mlfqs-fair-2
pass tests/threads/mlfqs/mlfqs-fair-20
FAIL tests/threads/mlfqs/mlfqs-nice-2
FAIL tests/threads/mlfqs/mlfqs-nice-10
FAIL tests/threads/mlfqs/mlfqs-block
14 of 27 tests failed.