우리는 너무 많은 데이터 속에서 살아가고있다. 많은 사람들이 데이터를 원석으로 정보라는 보석을 만들어내기 위해 노력한다.
효율적으로 데이터를 관리할 수 있다면, 더 적은 비용으로 더 의미있는 정보를 만들어낼 수 있을 것이다.
데이터 관리
효율적인 데이터 관리란?
- 데이터를 통합하여 관리한다.
- 일관된 방법으로 관리한다.
- 데이터 누락 | 중복을 제거한다.
- 여러 사용자가 동시에 사용가능하다.
파일 시스템
-
각각의 응용프로그램에서 필요한 데이터를 각자 저장하고 관리한다.
-
단층 파일구조라고도 불린다. -
데이터를 각자 관리하기 때문에, 두 프로그램 사이에 데이터 중복 혹은 누락이 발생할 수 있다.
-
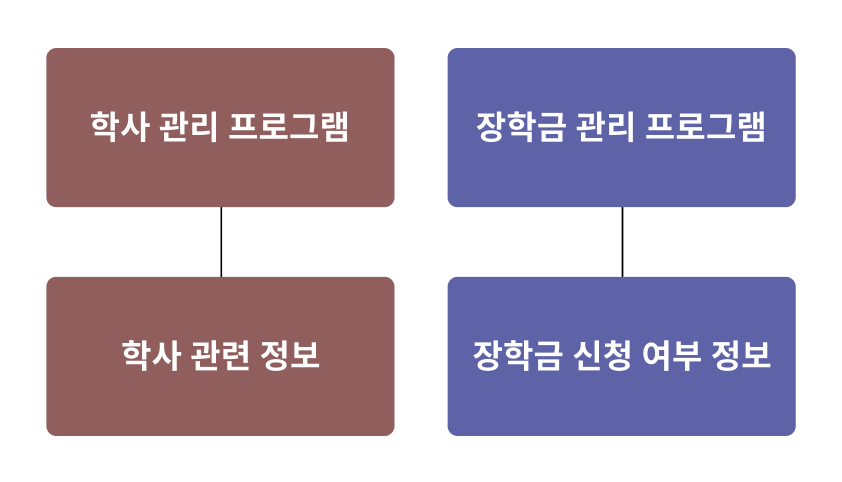
예를 들어,
학사 관리 프로그램과장학금 관리 프로그램에서 학생 졸업 여부 정보를 각각 갖고있다고 하자.
학사 관리 프로그램에서 A학생은 졸업생이라고 저장되어있지만,장학금 관리 프로그램에선 A학생이 재학생이라고 저장되어있을 수 있다.
이럴 경우, 데이터의 결함으로인해 졸업생에게 장학금을 주는 문제가 발생할 수 있다.
DBMS : DataBase Manage System

-
데이터를 통합하여 관리하는 시스템이다.
-
응용프로그램이 특정 서비스를 위해 특정 데이터를 DBMS에 요청한다. DBMS는 DB에 접근하여 응용프로그램이 원하는 데이터를 전달한다.
-
서비스의 역할 분담이 이루어질 수 있다.
- 응용프로그램 - 서비스 제공
- DBMS - 데이터 관리
- DB - 데이터 저장
-
효율적인 데이터 관리가 가능해진다.
데이터 모델
데이터 모델이란?
- 컴퓨터에서 데이터를 저장하는 방식을 정의한 개념모형
- 계층형, 네트워크형, 관계형, 객체지향형 등이 있다.
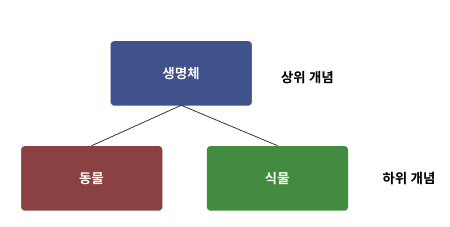
계층형 모델
-
트리 구조를 활용한다.
-
개체간의 관련성을 계층별로 나타낸다.
-
상위 개념에 하위 개념이 포함되는 모델이다. (1:N 관계)
-
단, 여러 부모를 가진 관계를 표현할 수 없다.
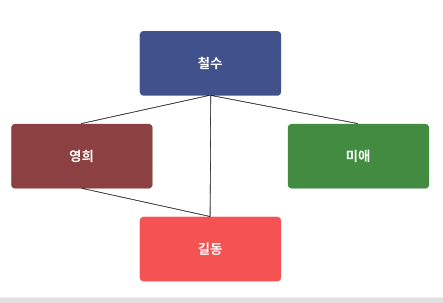
네트워크형 모델
-
그래프 구조를 활용한다.
-
개체간의 관계를 파악할 수 있다.
-
자식 개체가 여러 부모 개체를 가질 수 있다.
객체 지향형 모델
-
데이터를 독립된 객체로 구성한다.
-
상속 / 오버라이드 등 객체지향 프로그램링에 사용되는 강력한 기능을 사용할 수 있다.
-
하지만 객체 지향형 개념을 완전이 DB에 적용하는 것은 쉽지 않다.
관계형
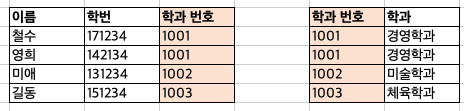
중복 데이터 발생 예시

독립 특성 유지 및 중복 데이터 제거
-
현대에서 가장 많이 사용하는 모델이다.
-
데이터 간 관계에 초점을 둔다.
-
각 데이터의 독립 특성을 규정하여 데이터 묶음으로 나눈다.
-
중복이 발생할 수 있는 데이터는 별개의 릴레이션으로 나눈다.
- 개체
데이터화하려는 사물 / 개념의 정보- 속성
개체를 구성하는 가장 작은 논리적 단위- 관계
개체와 개체 또는 속성간의 연관성
