
⭐️해싱
🪐해싱이란?
해싱에서 Hash란 본래의 뜻은 고기나 감자같은 음식을 잘게 쪼갠다는 뜻을 가지고 있다. 자료구조에서 해싱은 데이터를 효율적으로 저장하고 검색하기 위한 자료구조와 알고리즘의 일반적인 개념이다. 해싱은 데이터를 해시 함수를 사용하여 고정 크기의 값인 해시 코드(또는 해시 값)로 매핑하는 과정을 의미합니다. 다시 말해, 데이터를 해시 함수를 사용해서 잘게 쪼개고 합쳐서 새로운 값을 만들어내고 해당 값으로 매핑하여 데이터를 저장하는 방식을 의미한다.
해싱의 종류에는 Static Hashing과 Dynamic Hashing이 존재한다. Static Hashing은 해시 테이블의 크기가 고정되어 있는 해싱의 종류를 의미하며 해당 게시글에서는 Static Hashing을 다룰 것이다.

해시 테이블은 위와 같이 구성되어 있다. Hash 함수를 통해서 만들어진 값을 key값으로 활용하여, key값에 해당하는 index에 해당 데이터를 저장한다.
즉, 해시 테이블은 key와 bucket으로 고정되어있으며 bucket의 사이즈를 조절하여 테이블의 크기를 조절할 수 있다. 위 테이블은 index의 size가 8이고 index별로 bucket의 사이즈가 1인 예제이다.
🪐해싱의 장점
- 빠른 성능: 정적 해싱은 키의 검색, 삽입 및 삭제 작업에 대해 평균적으로 O(1)의 성능을 제공한다. 이는 키의 검색, 삽입 및 삭제 작업을 상수 시간에 수행할 수 있음을 의미한다.
- 효율적인 메모리 사용: 정적 해싱은 배열을 기반으로 하며, 미리 고정된 크기의 해시 테이블을 생성한다. 이를 통해 메모리를 효율적으로 사용할 수 있다.
🪐Collision & Overflow
해시 테이블에 데이터를 저장하다 보면은 Collision 혹은 Overflow의 상황을 마주하게 된다. 각각의 상황에 대해 알아보자.
☄️Collision

위 그림과 같이 0번부터 7번까지 hash table에 데이터가 저장된 상황에서 기존의 데이터와 동일한 인덱스를 가지는 새로운 값들이 들어온 상황을 두고 Collision(충돌)이라고 한다. 위 그림에서 Taiwan이 5번 index에 존재하는데 Thailand라는 새로운 값이 5번 index에 들어오게 된다면 충돌이 발생한다. Singapore과 Spain도 마찬가지이다.
☄️Overflow

Overflow는 Collision을 넘어서 이제는 테이블에서 저장한 bucket의 수를 넘어서게 데이터가 들어온 상황을 의미한다.
🪐해싱의 궁극적인 목표
- minimize collision: 충돌은 해시 함수가 서로 다른 키를 동일한 인덱스로 매핑할 때 발생한다. 해싱의 목표는 충돌을 최소화하여 동일한 인덱스에 해시된 키들을 분산시키는 것이다.
- minimize overflow: 해싱의 목표는 오버플로우를 최소화하여 데이터의 손실이나 성능 저하를 방지하는 것이다.
- minimize has table size: 해시 테이블의 크기는 메모리 사용량과 성능에 직접적인 영향을 미친다. 해싱의 목표는 효율적인 공간 사용을 위해 가능한 작은 해시 테이블 크기를 유지하는 것이다.
🪐해싱의 핵심적인 요소
- Selecting a hash function: 각각의 데이터들을 최대한 겹치지 않고 균등하게 key값들을 분산시킬 수 있는 hash function을 골라야 한다.
- Collision resolution: 충돌(collision)이 발생한 경우에 적절한 해결책을 내놓아야 한다.
🪐해싱의 종류
- Modulo Fucntion: 나머지 연산자를 이용해서 해싱을 하는 방법이며 가장 널리 이용된다. 예를 들어 375라는 데이터가 입력되면 101로 나눈 나머지인 72를 key값으로 사용하는 것이다. 나누는 값은 hash table의 index size를 결정하고 그 값은 소수(prime number)일 경우에 가장 고르게 분포가 이루어진다.
- Digit Analysis: 데이터의 길이가 일정할 경우에 데이터의 특정 index값을 추출하여 연산한 후 key값으로 이용하는 것이다.
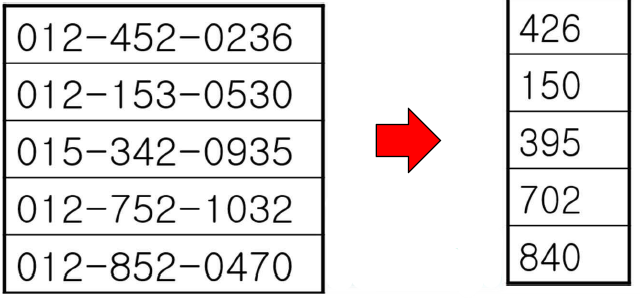
위와 같이 4, 8, 10번째 index값을 3자리수로 합쳐서 사용하는 것이 하나의 예제가 될 수 있다.
이 외에도 해싱에는 훨씬 더 많은 종류의 함수들이 이용되고 있으며 상황에 따라 적절한 해시함수를 사용하면 된다.
⭐️Collision Resolution
Collision이 발생하면 어떻게 해결할 것인지에 대한 2가지의 방법이 있다.
🪐Closed addressing
닫힌 주소화(Closed addressing)는 해싱에서 사용되는 충돌 해결 기법 중 하나입니다. 이 방식은 충돌이 발생한 경우 충돌하는 키들을 해시 테이블의 같은 인덱스 내에 저장하는 방법입니다.
닫힌 주소화에서는 각 인덱스에 충돌하는 키들을 저장하기 위한 별도의 버킷 또는 공간을 할당합니다. 즉, 충돌이 발생하면 같은 인덱스 내에서 키를 해시하여 다른 위치에 저장합니다.
이 방식은 해시 테이블이 "닫혀" 있어서 키들이 다른 버킷을 침범하지 않고 충돌을 해결한다는 의미에서 "닫힌 주소화"라고 불립니다.
닫힌 주소화는 간단하고 직관적인 방법이지만, 해시 테이블의 크기가 커지면 충돌이 자주 발생하여 성능 저하를 초래할 수 있습니다. 또한, 추가적인 공간이 필요하게 되므로 메모리 사용량이 증가할 수 있습니다.
-chatGPT
☄️Hash Table as a Full 2-D Array

Closed addressing의 한 가지 방법은 여러 개의 bucket을 만들어서 각 index에 여러 개의 값들을 놓는 방법이다.
☄️Overflow Chaining
다른 한 가지의 방식은 bucket을 여러 개를 사용하지 않고 overflow를 발생시키고 발생하면 linked list를 이용해서 값들을 연결시키는 것이다.
☄️search
table의 특정 index값이 존재하면 그 값의 뒤에 이어서 값을 이어붙히는 방식을 그대로 search를 진행하면 된다.

예를 들어 702라는 값을 찾고 싶으면, 702를 hashing한 2번 index에 가서 값을 search 한다. 9는 원하는 값이 아니니 next node로 이동하고 44도 원하는 값이 아니니 next node로 이동하면 702를 찾을 수 있다.
🪐Open addressing
개방 주소화(Open addressing)는 해싱에서 사용되는 충돌 해결 기법 중 하나입니다. 이 방식은 충돌이 발생했을 때 다른 위치에 충돌하는 키를 저장하는 대신, 동일한 인덱스 내에 충돌 키를 저장하는 방법입니다.
개방 주소화에서는 충돌이 발생하면 다른 위치에 키를 저장하는 대신, 충돌한 키를 해시 테이블의 동일한 인덱스 내에 저장합니다. 이를 위해 다른 위치를 찾아내는 방법을 사용하여 충돌이 발생했을 때 다른 인덱스를 찾아냅니다.
-chatGPT
다시 말해서, 특정 index의 위치에 값이 있으면 closed addressing 처럼 다른 위치에 저장하는 것이 아니라 다른 index에 저장하는 것을 의미한다.
다른 index에 값을 저장하는데에는 3가지의 알고리즘이 존재한다.
☄️Linear Probing
만약에 collision이 발생을 하면은 다음 index에 값을 저장하는 방식을 의미한다. 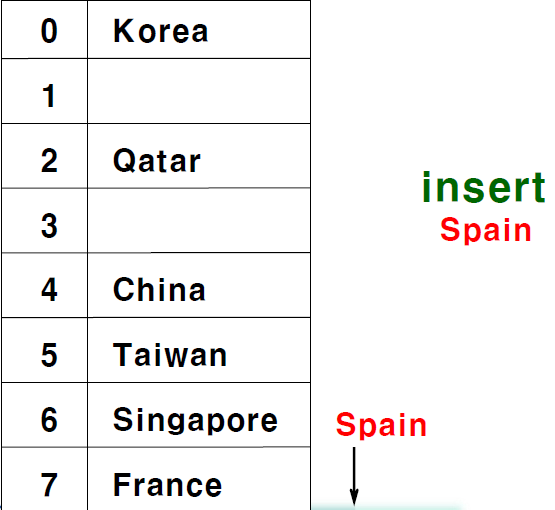
위 그림에서 spain을 저장하려고 6번에 갔는데 이미 값이 존재해서 다음 값이 비어있는 다음 index로 가기 위해서 순차적으로 탐색을 한다.
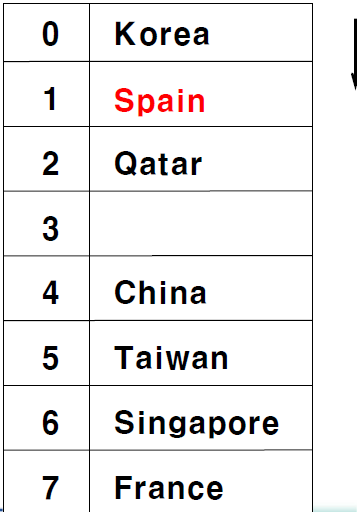
그래서 결국엔 비어있는 1번 index에 저장을 하는 것이다.
하지만 이런 방식에는 단점이 존재한다. 위 그림을 예시로, 만약에 0번에 korea가 없어진다고 해보자. spain을 해싱해서 얻은 6번 index로 이동을 하고 해당 index에 존재하는 값이 spain이 아니므로 다음 indx로 이동하면서 spain을 찾는다. 하지만 0번이 비게 된다면 알고리즘 상으로 spain은 없다고 판단이 되므로 spain은 사실 1번 index에 존재하는데 없다고 판단이 된다.
이 방법을 해결하는데에는 각 index마다 상태를 남기면 된다. 예를 들어, cocupied, empty, deleted 라는 3가지의 상태를 index마다 남기면 되는데 occupied는 채워져있는 상태, empty는 비워져있는 상태, deleted는 삭제된 상태를 의미한다. 만약에 같은 상황에서 korea가 존재하던 index에 deleted 상태를 남기게 된다면 index에 해당하는 값은 비어있지만 다음으로 넘어가서 값을 탐색할 수 있다.
하지만 가장 큰 문제가 남아있는데 그것은 바로 최악의 경우에 탐색 시간이 O(n) 일수도 있다는 것이다. hashing을 이용하는 가장 큰 이유가 시간 복잡도가 constant하기 때문인데 이런 linear probing을 이용하면 시간 복잡도가 선형일 수도 있다. 이를 두고 Formation of “ Cluster”s 라고 한다.
☄️Quadratic Probing
linear probing과 비슷하지만, linear은 하나씩 index를 늘려나가는 방식이라면 Quadratic은 제곱수로 index를 탐색하는 것을 의미한다. 예를 들어 처음 접근한 곳에서 collision이 발생했다면 1만큼 index를 이동하고 실패하면 다음은 4, 다음은 9만큼 이동하는 것이다. 이를 통해 Formation of Cluster 문제를 일정 부분 해결할 수 있다.
☄️Double Hashing
마지막으로는 Double Hashing이다. Double Hashing은 구별되는 2가지의 hash 함수를 이용해서 만약에 Collision이 발생하면은 한 번더 hashing을 해서 저장하는 방식이다. 여기에는 조건이 붙는데 바로 두 번째 해싱의 값이 첫 번째 해싱의 값과 같아서는 안되고 0이어서도 안된다.
특정 값에 대해서 첫 번째 hashing을 통해서 처음 들어갈 자리를 구하고 만약에 collision이 발생하면 두 번째 해싱을 통해서 얻은 값을 처음 얻은 index에 더해서 새로운 자리를 찾는다.
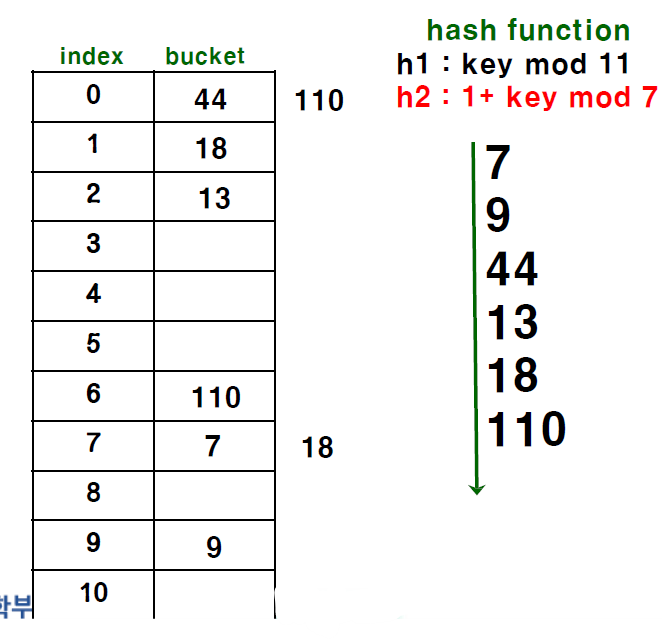
위 그림에서 18을 입력하려고 첫 번째 모듈러 연산을 수행했더니 7번 index가 선택되었지만 해당 index에 이미 값이 존재해서 두 번째 해싱한 값인 5를 더해서 2번 인덱스에 새로 자리를 잡았다.

글 너무 잘 읽고 갑니다!