AI정보
1.AI? ML? DL?
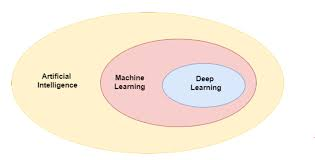
인공지능(AI), 머신러닝(ML), 딥러닝(DL)
2.Spiking Neural Network(SNN)이란?
스파이킹 신경망(Spiking Neural Networks, SNN)은 인공지능 분야에서 유망한 접근 방식으로 떠오르고 있다.
3.Tesseract (테서렉트)를 이용한 문자인식

Tesseract는 다양한 운영 체제를 위한 광학 문자 인식 엔진이다.요즘 스마트폰을 이용해서 글이나 문자를 카메라로 찍어서 사진을 확인해보면. 그 문자들을 인식해서, 복사를 하거나, 검색을 할 수 있는 기능이 있다.이러한 기능이 바로 OCR(광학문자인식)을 이용한 것
4.LLM이란?

LLM(대규모 언어 모델, Large Language Model)은 최근 인공지능(AI)과 자연어 처리(NLP) 분야에서 가장 주목받고 있는 기술 중 하나이다.
5.BERT: 자연어 처리의 혁신

BERT(Bidirectional Encoder Representations from Transformers)는 구글이 2018년에 발표한 혁신적인 자연어 처리(NLP) 모델이다.
6.인공지능의 윤리적 문제: 책임성과 투명성을 위한 고찰

인공지능(Artificial Intelligence, 이하 AI)은 현대 기술 혁신의 중심에 있으며, 많은 분야에서 변화를 일으키고 있다. 의료, 금융, 교육, 제조 등 여러 산업에서 AI의 적용은 이미 널리 퍼져 있으며, 그 영향력은 계속해서 확장되는 추세다. 그러나
7.Anaconda3: Data Science와 Machine Learning 을 위한 필수 플랫폼

Anaconda3는 데이터 과학과 머신러닝 분야에서 필수적인 플랫폼으로 자리 잡고 있다.
8.Convolutional Neural Networks (CNN): 이미지 처리와 딥러닝의 핵심 기술
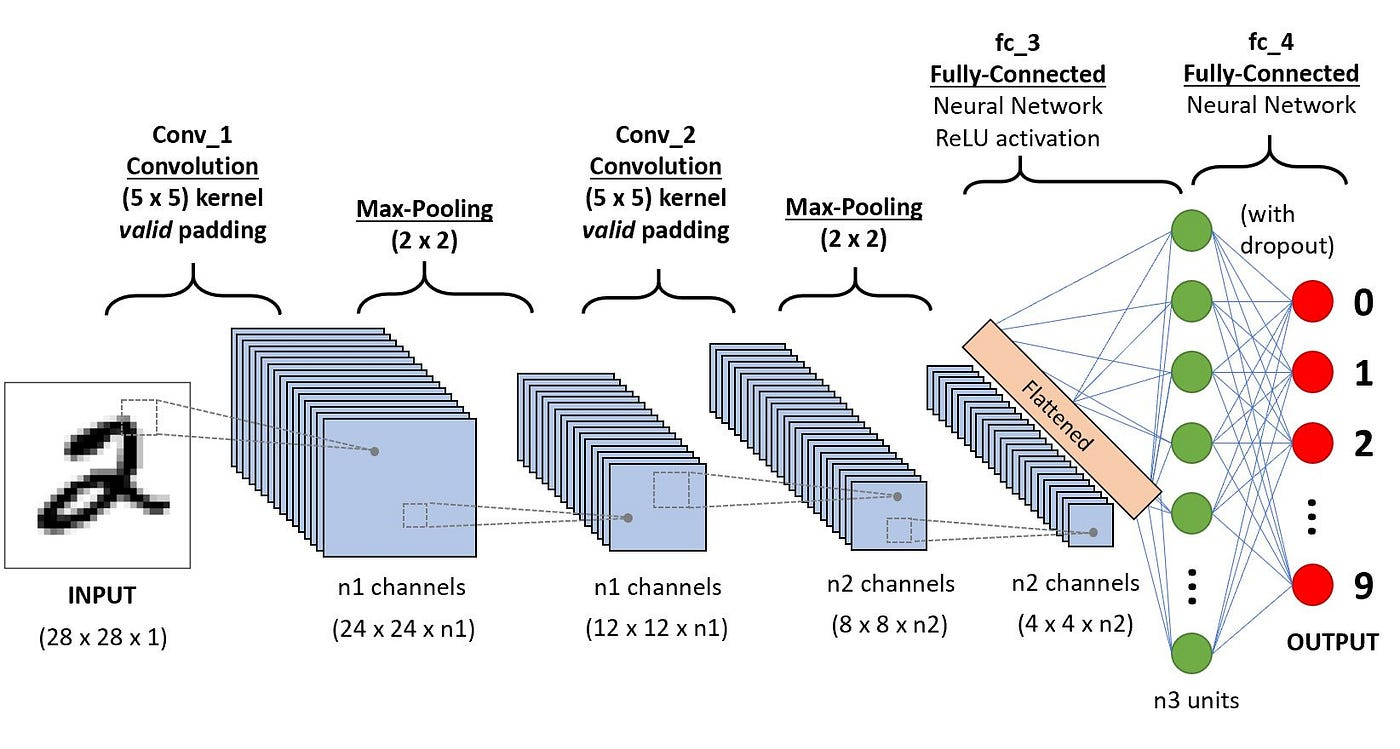
Convolutional Neural Networks (CNN)은 딥러닝에서 가장 널리 사용되는 모델 중 하나로, 특히 이미지 처리 및 컴퓨터 비전 분야에서 큰 성공을 거두고 있다.
9.U-Net: 이미지 분할을 위한 딥러닝 모델

U-Net은 2015년 Olaf Ronneberger와 그의 동료들이 개발한 딥러닝 기반의 이미지 분할 모델이다.
10.YOLO (You Only Look Once): 실시간 객체 탐지를 위한 혁신적인 딥러닝 모델

YOLO(You Only Look Once)는 실시간 객체 탐지(Object Detection) 분야에서 혁신을 일으킨 딥러닝 모델이다. YOLO는 이미지를 한 번만 처리하여 객체를 탐지하는 방식으로, 매우 빠른 속도와 높은 정확도를 자랑한다
11.생성적 적대 신경망(GAN): AI 기반 생성 기술의 혁신

생성적 적대 신경망(GAN, Generative Adversarial Network)은 2014년 제안된 딥러닝 모델로, 데이터 생성 분야에서 혁신적인 변화를 가져온 기술이다. GAN은 두 개의 신경망, 즉 생성자(Generator)와 판별자(Discriminator)
12.선형 회귀란?
선형 회귀는 머신러닝 알고리즘 중 하나로, 주어진 입력 데이터에 대해 숫자 값(예: 집값, 주식 가격 등)을 예측하는 데 사용된다. 이 알고리즘은 선형 함수를 사용하여 입력과 출력 사이의 관계를 모델링한다. 쉽게 말해, 선형 회귀는 "입력값에 따라 결과값이 선형적으로 변한다"는 가정을 기반으로 한다. 예를 들어, 집 크기가 클수록 가격도 비례해서 올라간다...
13.DeepSeek V3 의 등장

최근 인공지능(AI) 분야에서 주목할 만한 소식이 전해졌습니다. 중국의 AI 스타트업 딥시크(DeepSeek)가 6,710억 개의 매개변수를 가진 초대형 오픈 소스 언어 모델인 DeepSeek-V3를 발표했습니다. 이는 현재까지 공개된 오픈 소스 모델 중 최대 규모로,
14.AI 에이전트란 무엇인가?
AI 에이전트(Artificial Intelligence Agent)는 사용자의 요청을 이해하고 이에 맞는 작업을 수행하는 지능형 시스템을 의미합니다. 최근 ChatGPT와 같은 생성형 AI가 주목받으면서 AI 에이전트의 활용이 다양한 산업군에서 빠르게 확산되고 있습니
15.RAG란 무엇인가? – 검색 기반 생성 모델 (Retrieval-Augmented Generation)
AI와 자연어 처리(NLP)의 발전으로 인해 언어 모델(LLM, Large Language Model)이 많은 관심을 받고 있습니다. 그러나 언어 모델은 사전에 학습한 데이터만으로 답변을 생성하기 때문에 최신 정보나 구체적인 문맥을 반영하기 어렵다는 한계가 있습니다.
16.알리바바의 최신 언어 모델: Qwen 2.5 소개

알리바바 클라우드는 최근 최신 대규모 언어 모델(LLM)인 Qwen 2.5를 공개하였습니다.
17.멀티모달(Multimodal)이란 무엇일까?
멀티모달(Multimodal)은 여러 가지 형태의 데이터를 동시에 활용하는 방식을 의미합니다. 예를 들어, 텍스트, 이미지, 오디오, 비디오 등 다양한 형태의 데이터를 결합하여 정보를 처리하거나 표현하는 것을 말합니다. 이러한 접근 방식은 인간의 복합적인 의사소통 방식
18.Cursor AI: 혁신적인 AI 기반 코드 편집기

Cursor AI는 인공지능을 활용하여 개발자의 생산성을 극대화하는 혁신적인 코드 편집기입니다. 코드 자동 완성, 자연어 코드 생성, 실시간 오류 감지 등 다양한 기능을 제공하여 초보자부터 숙련된 개발자까지 모두에게 유용한 도구로 자리 잡고 있습니다. 이번 글에서는 C
19.LangChain: 언어 모델 기반 애플리케이션 개발의 새로운 패러다임
인공지능(AI)의 발전과 함께 대규모 언어 모델(LLM)의 활용이 급증하고 있습니다. 이러한 모델들은 자연어 처리 분야에서 혁신적인 변화를 이끌어내고 있으며, 다양한 애플리케이션 개발에 핵심적인 역할을 하고 있습니다. 그러나 LLM을 실제 애플리케이션에 통합하고 활용하
20.LLaMA 모델 파인튜닝: 이론과 실습
대규모 언어 모델(LLM)의 발전으로 자연어 처리 분야는 혁신적인 변화를 맞이하고 있습니다. 그중에서도 Meta AI에서 개발한 LLaMA(Large Language Model Meta AI) 모델은 상대적으로 적은 파라미터 수로도 우수한 성능을 보이며, 연구자들과 개
21.Llama에 RAG를 적용하여 똑똑한 인공지능 만들
Ollama 설치: 공식 문서 참조LLaMA3 모델 로드:필요 라이브러리:✅ 허용 데이터: 자체 제작 문서CC-BY, MIT License 등 오픈 라이선스 자료위키백과(CC BY-SA 3.0)❌ 금지 데이터:저작권이 있는 서적/논문웹 스크래핑 데이터(명시적 허락 없을
22.LLM에서의 양자화(Quantization): 개요와 활용
양자화는 모델의 가중치와 연산을 낮은 비트(bit)로 변환하는 기술입니다.예시: 32비트 부동소수점(FP32) → 8비트 정수(INT8)로 변환하여 모델 경량화.수식 예시 (간소화):FP32 값 범위: -3.4e38, 3.4e38INT8 변환: -128, 127 범위로
23.Grok3

2025년 2월 18일, 인공지능(AI) 업계에 또 한 번의 혁신이 찾아왔습니다. 일론 머스크가 이끄는 AI 전문 기업 xAI가 최신 AI 모델 Grok3를 공식 공개했습니다. 이번 Grok3는 기존 모델 Grok2의 10배에 달하는 연산 능력과 혁신적인 기능을 탑재하
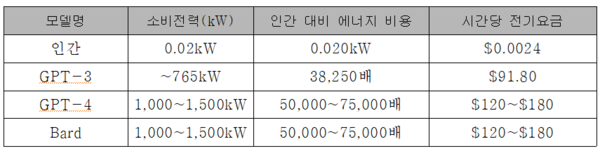
24.AI가 요구하는 막대한 전력량과 컴퓨팅 구조의 한계
최근 ChatGPT와 같은 거대 언어모델(LLM)의 등장은 사회 각 분야에 큰 변화를 일으키고 있습니다. 그러나 이러한 혁신 뒤편에는 막대한 전력 소모와 컴퓨팅 자원의 한계라는 심각한 문제가 숨겨져 있습니다.