
TCP: flowcontrol
수신자의 상태에 맞춰서 데이터를 보내는 것, 수신자의 버퍼가 넘치지 않도록(overflow방지)
시스템이 stable하려면 feedback이 있어야한다.
- feedback
- sender로 부터 signal이 도착하면 binary 데이터로 변환(모뎀) - frame
- binary 데이터를 interrupt routine을 수행하면서 header에 대한 처리를 해주고 상위 계층으로 넘겨준다. - datagram
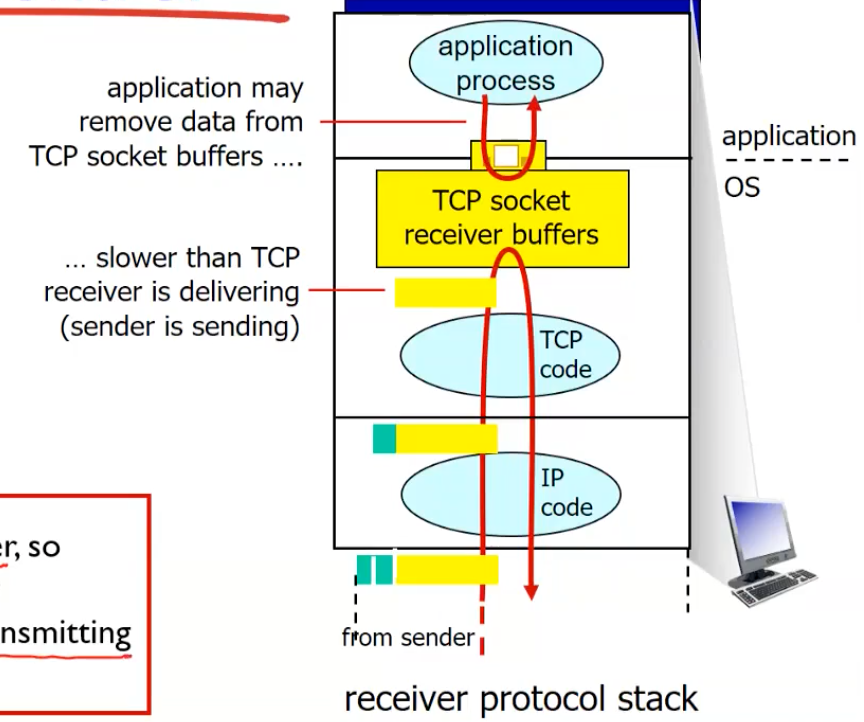
- segment 들은 TCP buffer에 패킷에 저장이 되어야함
어느 정도 free space가 있는지 얼마나 저장할 수 있는지를 알기 위해서 flow control이 필요하다.
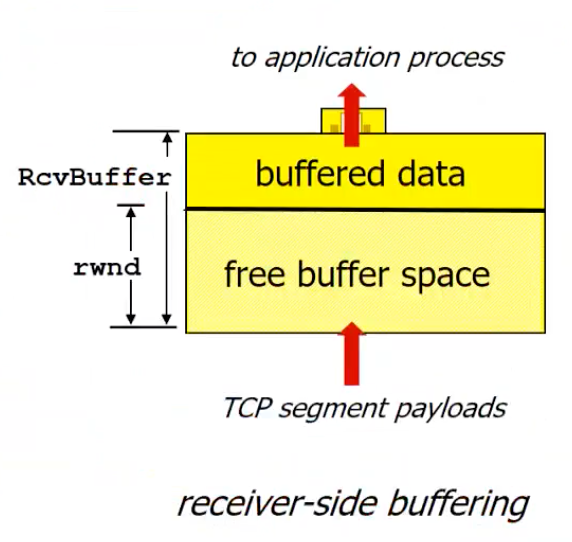
- rcvbuffer : 저장되어있는 데이터, 총 데이터양 (4096 bytes : default), 사용자가 api 및 operating system으로 조절가능
- rwnd : free buffer space, 매번 sender에게 알려줄 내용
TCP 헤더에 rwnd란 field가 있다.
"in-flight / unacked" 데이터를 rwnd에 맞춰 조절해 overflow를 막을 수 있다.
TCP: connection management
"handshake" : 데이터 교환하기 전 반드시 해야할 단계
connection state를 교환해야한다.
- state
- seq # (server → client / client → server)
rcvbuffer size
위와 같은 것들을 주고 받으면서 서로의 상태 정보를 교환한다.- server :
accept( ) - client :
netSocket( )/connect( )
패킷들이 무순차적으로 도착하거나 잃어버리거나 할 때 re-ordering 하거나 복구(recover)하기위해서 사용하기 위해 필요하다.
상태를 어떻게 주고 받을 것 인가?
2-way handshake
상태정보를 먼저 주고 받고 데이터를 주고받고
항상 네트워크 상에서 잘 동작할 수 있는가? → 안된다.
- variable delay
- retransmitted msg
이와 같은 문제로 2-way는 부족하다.
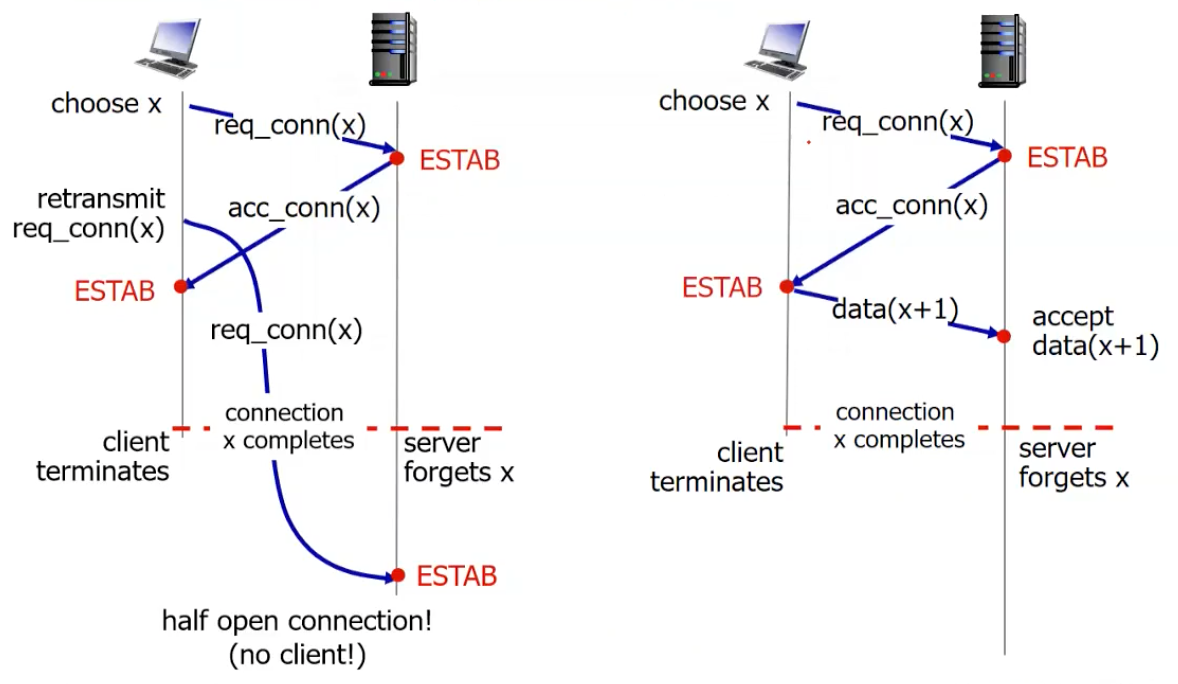
🔥 예제를 만들어서 설명할 줄 알아야한다.
[왼쪽 그림]
accept_connection이 늦게 도착하는 경우, timeout이 발생해서 재전송을 하게 된다. connection이 다 끝난 뒤에 서버로 도착할 수 도 있는 경우, 최악의 경우, 서버는 ESTAB 상태 유지 반면에 클라이언트는 CLOSE
[오른쪽 그림]
서버는 connection이 끊긴 뒤에 도착하는 데이터를 valid 데이터로 인식해서 처리하는 심각한 문제가 발생
TCP: connection
3-way-handshake
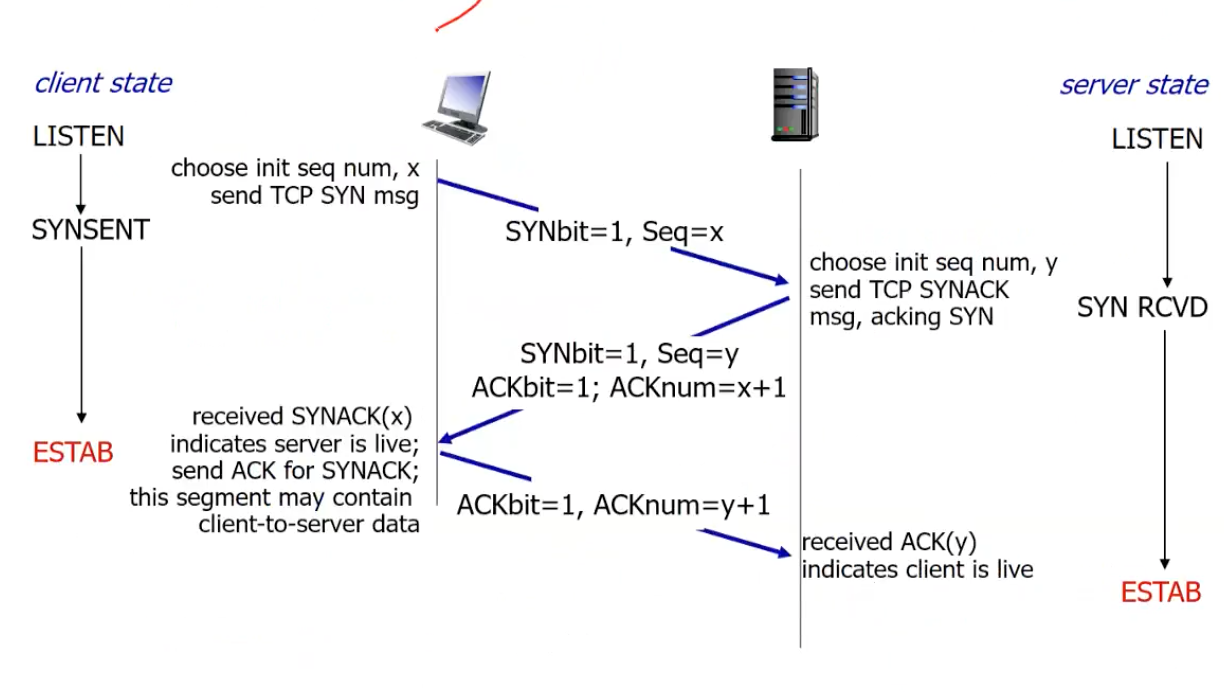
init seq #는 고정 값이 아니라 random하게 사용한다. 그 이유는 데이터를 재전송을 하는 경우에는 old connection/new connection 데이터 판단을 해야하기 때문이다. random number는 in-lifetime에 해당해야한다.
half-open connection problem(2-way handshake이용 시)을 해결할 수 있다.
TCP: closing a connection
4-way-handshake
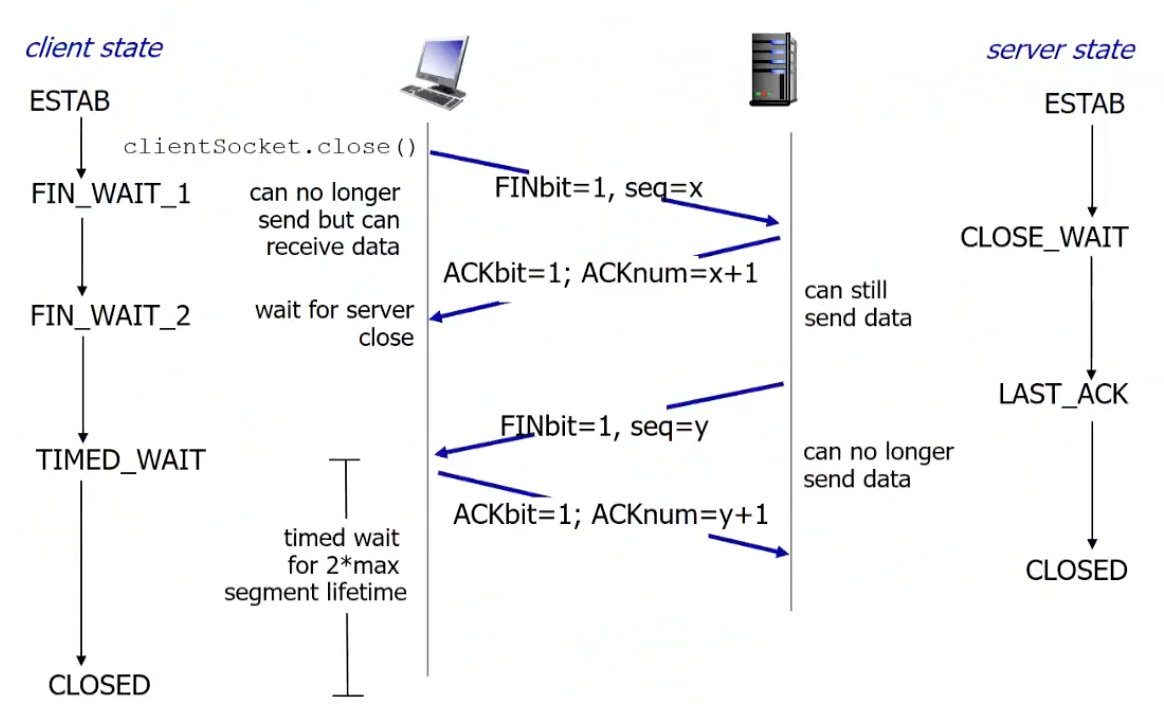
FIN 비트를 보내고 나서는 더 이상의 데이터를 보낼 수 없다.- server로 부터 data가 다 보내질 때 까지 client에서 close 하지 않는다.
timed wait for 2 max segment lifetime
Congestion Control의 원리
congestioin이란?
: 네트워크 상에서 너무 많은 데이터를 너무 빠르게 보내는 경우
congestion으로 표출된 결과는 ?
- buffer overflow(lost packet)
- long delay
Causes/costs of congestion: scenario - 1
- 두개의 송신자(sender), 두개의 수신자(receiver)
- 하나의 라우터, 무제한의 버퍼(buffer)
- output link capacity :
- 입력되는 데이터의 속도는 , 전송되는 속도는
- 재전송 X
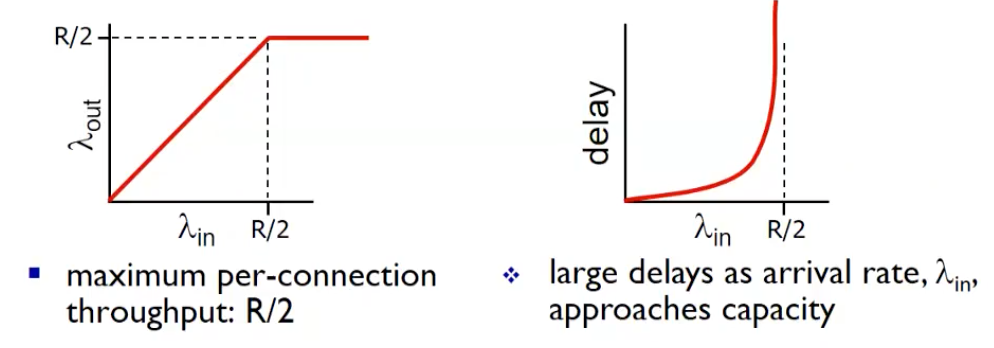
두개의 sender가 공유하기 때문에 최대 까지 이용가능
delay는 queing이 계속 발생하기 때문에 무한으로 증가 (poissiom process 가정)
Causes/costs of congestion: scenario - 2
ideal situation
-
한개의 라우터, 유한(finite) 버퍼
-
유한한 버퍼를 사용하기 때문에 packet-loss가 발생함에 따라 time-out이 발생해 retransmission이 생김
-
application layer 상에서 입력되는 속도와 전송되는 속도가 같아야한다. , 시스템이 stable하기 위해서
-
TCP에서 재전송(retransmission)을 해야하기 때문에,
여기서 는 original data + retransmitted data -
loss된 패킷만 재전송 할 수 있다.
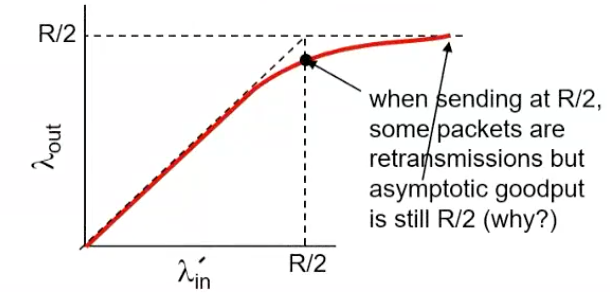
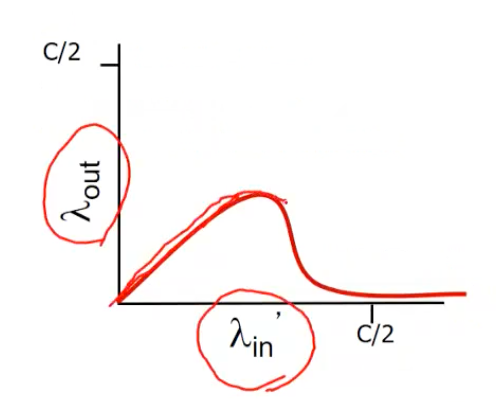
재전송이 많아지게되면 어느 순간에는 은 로 수렴한다. loss된 패킷만 재전송하기 때문에 goodput(재전송을 뺀)이 로 수렴한다.
Realistic situation
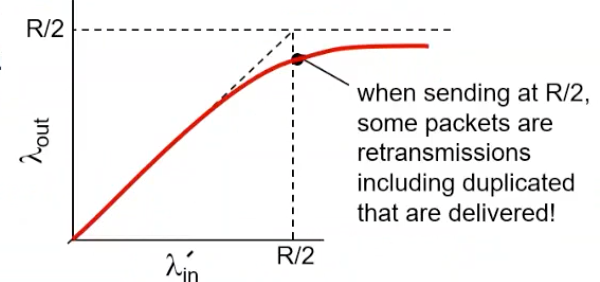
중복된 패킷들이 계속 증가되기 때문에 은 보다는 작은 값으로 수렴한다.
cost의 congestion
- 주어진 goodput을 위해서는 더 일을 해야한다. premature timeout(불필요한 재전송)에 의해서 재전송을 해야한다. 불필요한 재전송 = 같은 패킷의 여러개의 copy가 도착
Causes/costs of congestion: scenario - 3
- 4 senders
- multihop paths
- timeout / retransmit
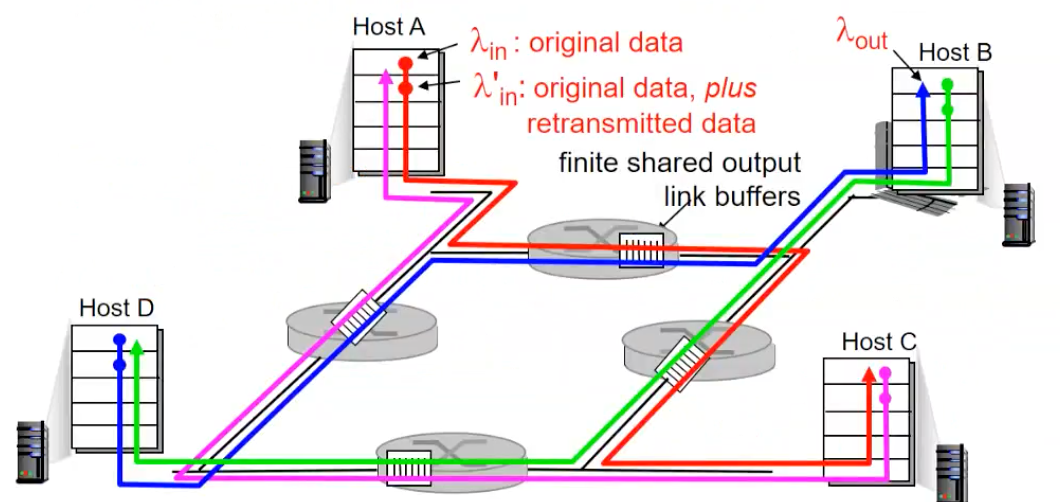
connection들이 라우터를 공유하는 상황에서 throughput은 어떻게 되는 가?
파란색 패킷은 왼쪽의 첫번째 라우터를 통과하고, 두번째 라우터를 통과해야하기 때문에 라우터가 낭비가 되는 모습
이 계속해서 증가하게되면 빨간색 패킷과 파란색 패킷이 지나는 라우터의 버퍼는 유한하기 때문에 통과하는 파란색의 패킷을 점점 줄어들고 Host B에서 파란색의 throughput에서 점점 더 loss가 발생한다. 그래서 시점 이후로는 0으로 수렴하게 된다.
TCP: Congestion control
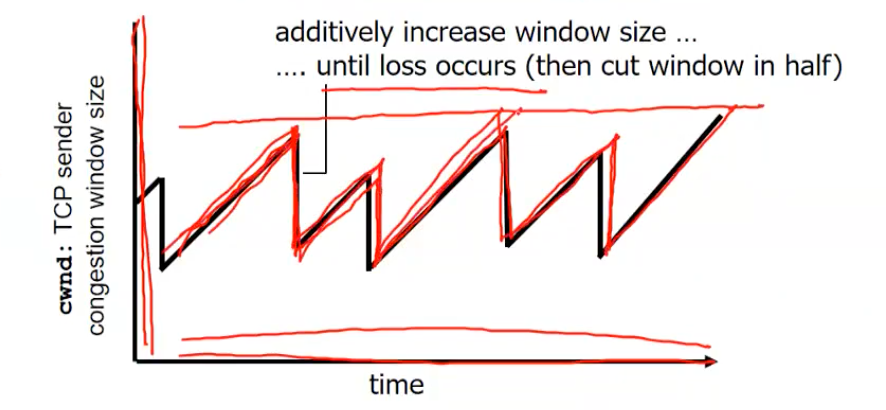
AIMD(additive increase multiplicative decrease)
- additivie : 서서히, cwnd를 증가 시킨다(1 MSS 씩 매 RTT 마다 증가)
- multiplicative : 급격히, 현재 cwnd의 값을 만큼 줄인다.(
cwnd /= 2)
TCP: Congestion control, details
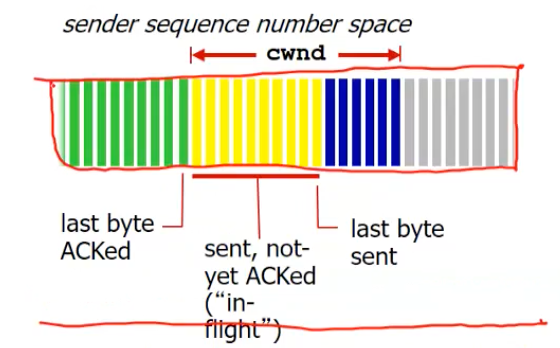
- cwnd : maximum window size(Byte로 이루어짐)
- 노란색 구간 : head pointer와 tail pointer로 처음과 끝을 알려줌
sender는
- last byte sent : 최종 ack를 받지 않고 보낸 바이트의 seq #
- last byte ACKed : ack를 받은 최종 바이트의 seq #
- min(rwnd, cwnd) : receiver와 sender의 윈도우 사이즈 중에서 최소값
(last byte sent - last byte ACKed) min(rwnd, cwnd)
- RTT 마다 cwnd만큼(byte) 보내짐
- throughput : 어떤 시간 동안에 얼만큼 보냈는지를 나타낸다.
rwnd > cwnd 를 가정한다면 결국 ack를 받지않고 보내는 양은 cwnd / RTT 만큼 전송된다.
AIMD를 사용하면 cwnd / RTT 만큼 받을 수 있다.
TCP: Slow Start
AIMD를 개선할 수 있는 알고리즘
초기에 사용하며, 조금 더 급격하게 성능을 개선할 수 있음
어느 정도 sending rate를 올린 후에 linear increase를 한다.
- init
cwnd = 1 MSS - 매 RTT 마다(ACK를 받을 때 마다)
cwnd *= 2
AIMD와는 다르게 조금의 공간이 생기면 급격하게 window size를 늘렸다가 threshold 이상으로 넘어가는 순간 1로 초기화한다.
TCP: packet loss
추적할 수 있는 두가지 방법
- timeout
cwnd = 1 MSS reset(initial value)
: heavy congestion - 3 duplicate ack : fast retransmit algorithm
loss가 알려졌다면, cwnd /= 2 하고 (3 duplicate ack 추가 후) 바로 linear increase
중복된 ack는 어느정도 일부의 데이터가 전달됐다는 의미
: light congestion
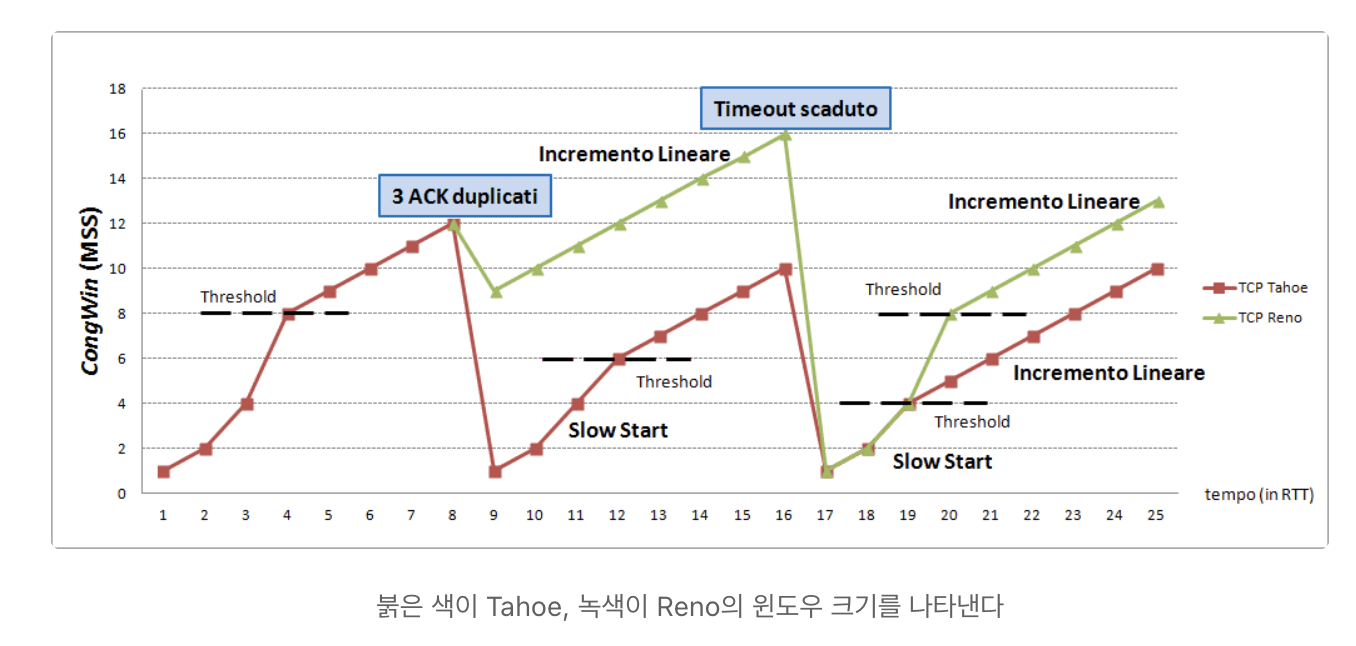
- Tahoe : 초기버전 동일하게, 1로 set
- RENO : 3 duplicate ack를 추가한 버전, (cwnd /= 1/2)로 set
packet loss가 발생한 지점의 가 새로운 threshold
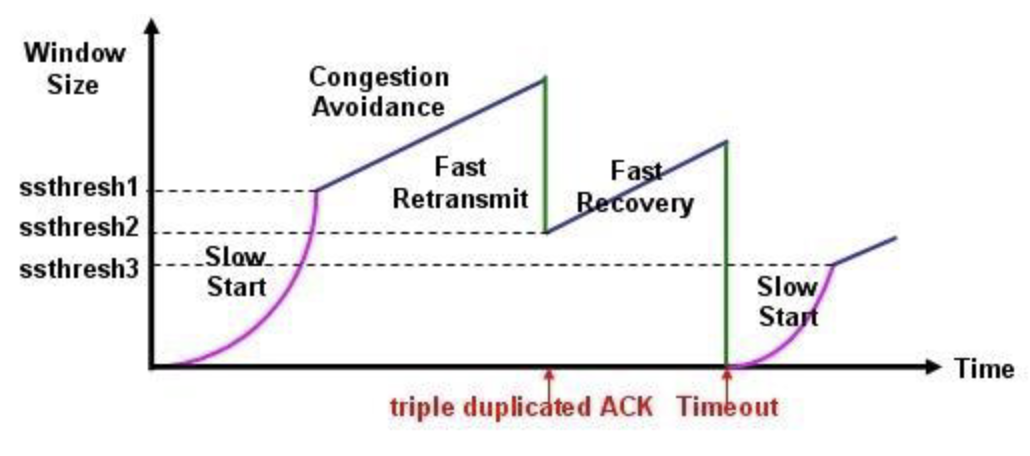
threshold : 급격하게 증가시킬 기준선
- cwnd < threshold :
exponentially growth(Slow Start)
cwnd = cwnd * 2 - cwnd > threshold :
linear growth(Congestion Avoidance)
cwnd = cwnd + 1
TCP: throughput
- SLOW START는 계산에서 제외한다.
- 3 duplicate ack에 의해서 많이 detect된다.
W : packet loss가 발생했을 때의 window size
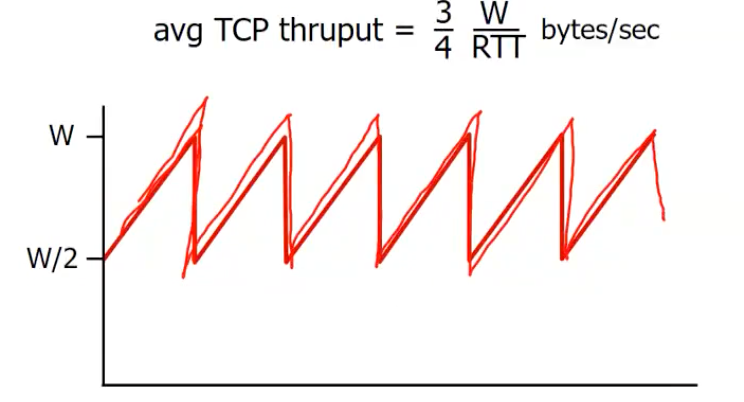
min : W/2, max : W, avg : W*(3/4)
TCP: long, fat pipe(widearea)
TCP의 성능비교
ex) 10Gbps throughput 얻기 위해서는 window size는 어떻게 되야하는지?
- 1500 bytes segment
- 100ms RTT
-> W = 83,333 in-flight segments, ack없이 이만큼 보내야함
TCP는 10Gbps 만큼의 속도를 제공하지 못함
10 Gbps의 throughput을 얻기 위해서는 만큼의 loss rate가 필요하다. → 불가능하다. TCP가 새롭게 변해야한다.
결론, TCP는 HIGH SPEED 네트워크에 어울리지 않다. sending window size를 키울 수 없기 때문이다.
TCP Fairness
자원을 항상 극대화 해야한다.
Fairness란 K의 TCP 세션에서 대역폭인 R인 링크를 공유한다면 평균 속도는 R/K가 보장 되어야 한다.
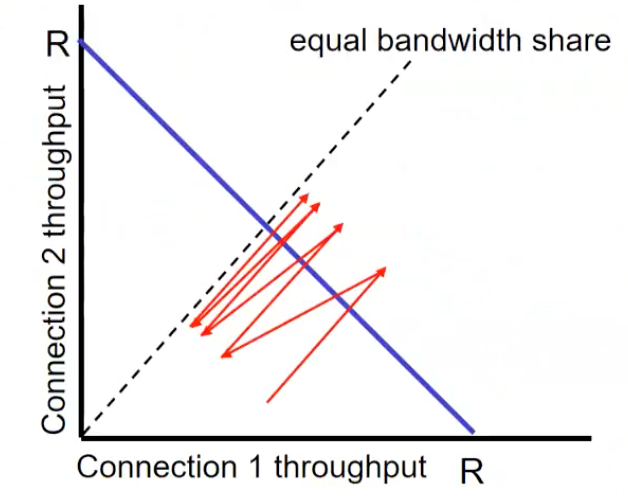
-
파란 직선 안에 있는 경우, linear increase
인 직선으로 움직인다. -
파란 직선 밖에 있는 경우,
바깥에 있는 점과 원점을 잇는 직선 내에서 이동
다른 경우일 때는 Fairness가 어떻게 작용될까?
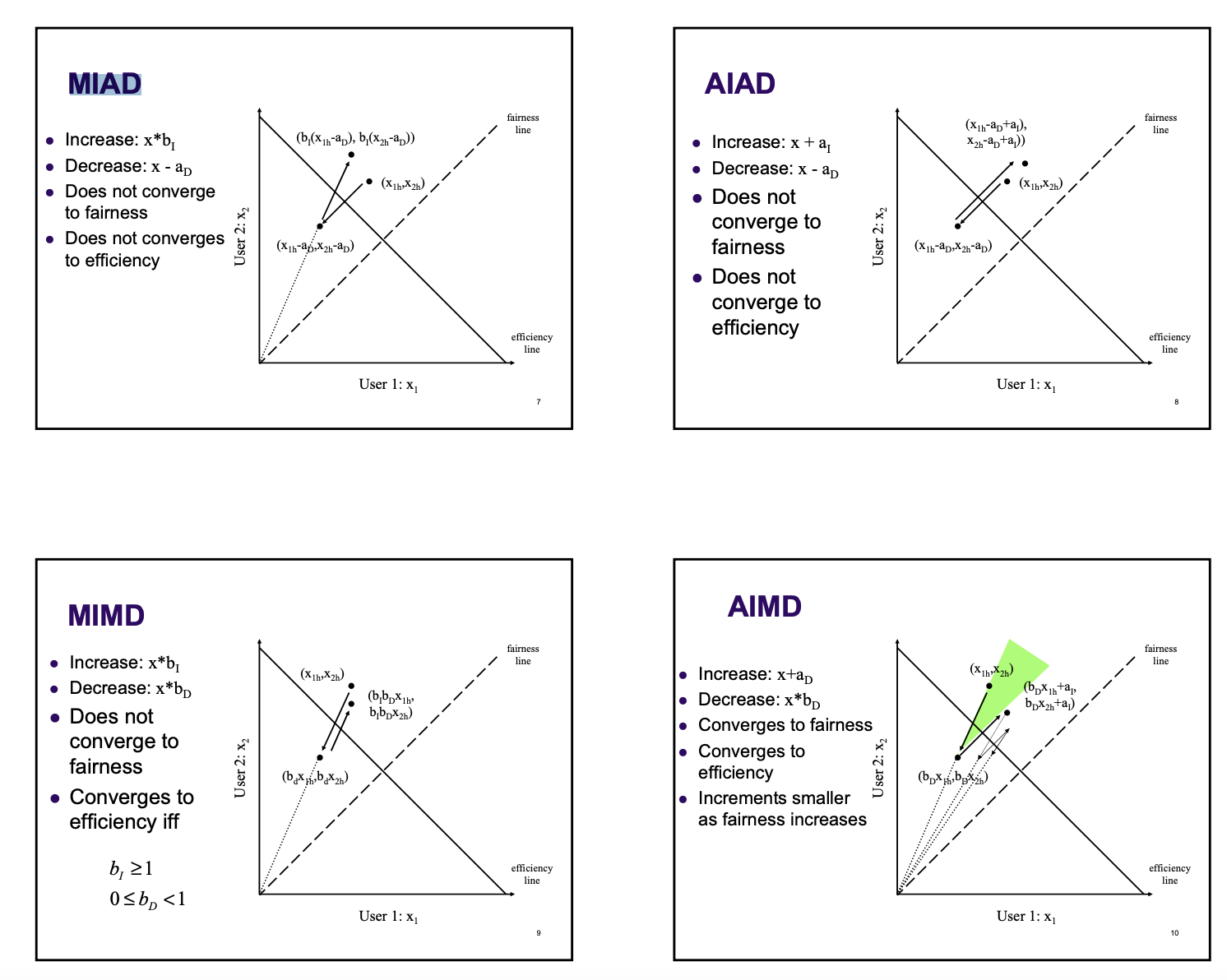
출처-(Materials with thanks to Vern Paxson, Jennifer Rexford, and colleagues at UC Berkeley)
Explicit Congestion Notification(ECN)
network 이 도와주는 congestion control을 할 수 있다.
ECN은 IP header에 ToS field안에 있는데, receiver이를 세팅해서 보내는 ECH-Echo라는 걸 세팅해주면 congestion을 알 수 있다.
