
이 포스팅은 백준 내 질문검색을 돌아다니다가 palilo님의 글을 보고 정리하게되었습니다.
이분탐색이 필요하거나 사용되는 경우
💡 case 1. 어떤 f(x)를 만족하는 x의 최솟값을 찾는 경우
💡 case 2. 어떤 f(x)를 만족하는 x의 최댓값을 찾는 경우
우선 이분탐색의 기본 조건은 찾고자 하는 자료구조가 오름차순 정렬되어있어야 한다. 정렬된 배열이 있다고 가정을 해보면 왼쪽 부분을 사용할 건지 오른쪽 부분을 사용할 건지 먼저 정하고 시작을 해야한다.
- 왼쪽 부분: 찾는 범위 내 시작점부터 중간지점,
L-M/L-(M-1) - 오른쪽 부분: 찾는 범위 내 중간지점부터 종료지점,
(M+1)-R/M_R
최솟값을 찾는 경우
왼쪽 부분을 사용한다면 최솟값을 찾기에 용이할 것으로 보인다. 왜냐하면 같은 값이 존재해도 왼쪽부분으로 해당하면 최소 index를 찾을 수 있기 때문인데 예를 들면 아래 그림과 같다.
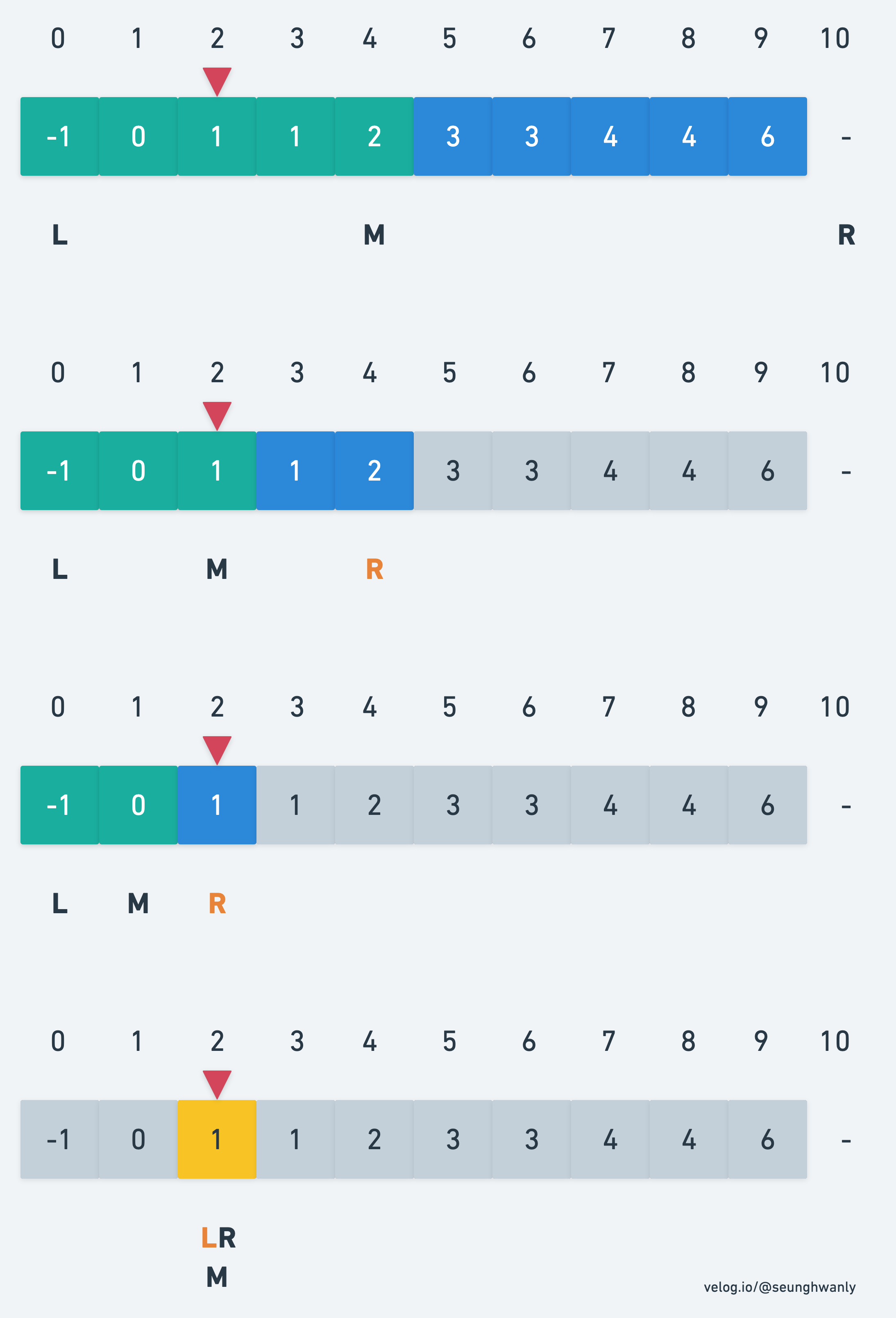
확인된 f(M) 값이 target보다 크거나 같으면 R값을 M으로 설정해준다. 그렇게 되면 L부터 M까지의 크기가 더 크게 설정되기 때문에 M - 1값으로 설정하지 않는다. 이때 M 값은 (L + R) >> 1로 사용한다. (비트연산)
반대로 f(M) 값이 target보다 작으면 어떻게 해야할까? L은 곧 찾는 범위의 시작점을 의미하기 때문에 L을 M + 1 땡겨준다. 이를 코드로 구현하면 다음과 같다.
case 1. 소스코드
left, right = min, max + 1
while left != right:
mid = (left + right) // 2
if f(mid) == True:
right = mid
else: left = mid + 1
if left == max + 1: return IMPOSSIBLE
return left최댓값을 찾는 경우
반대로 오른쪽 부분을 사용한다면 최댓값을 찾기에 용이할 것으로 보인다. 왜냐하면 같은 값이 존재해도 오른쪽 부분을 계속 유지한다면 최대 index를 찾을 수 있기 때문이다.
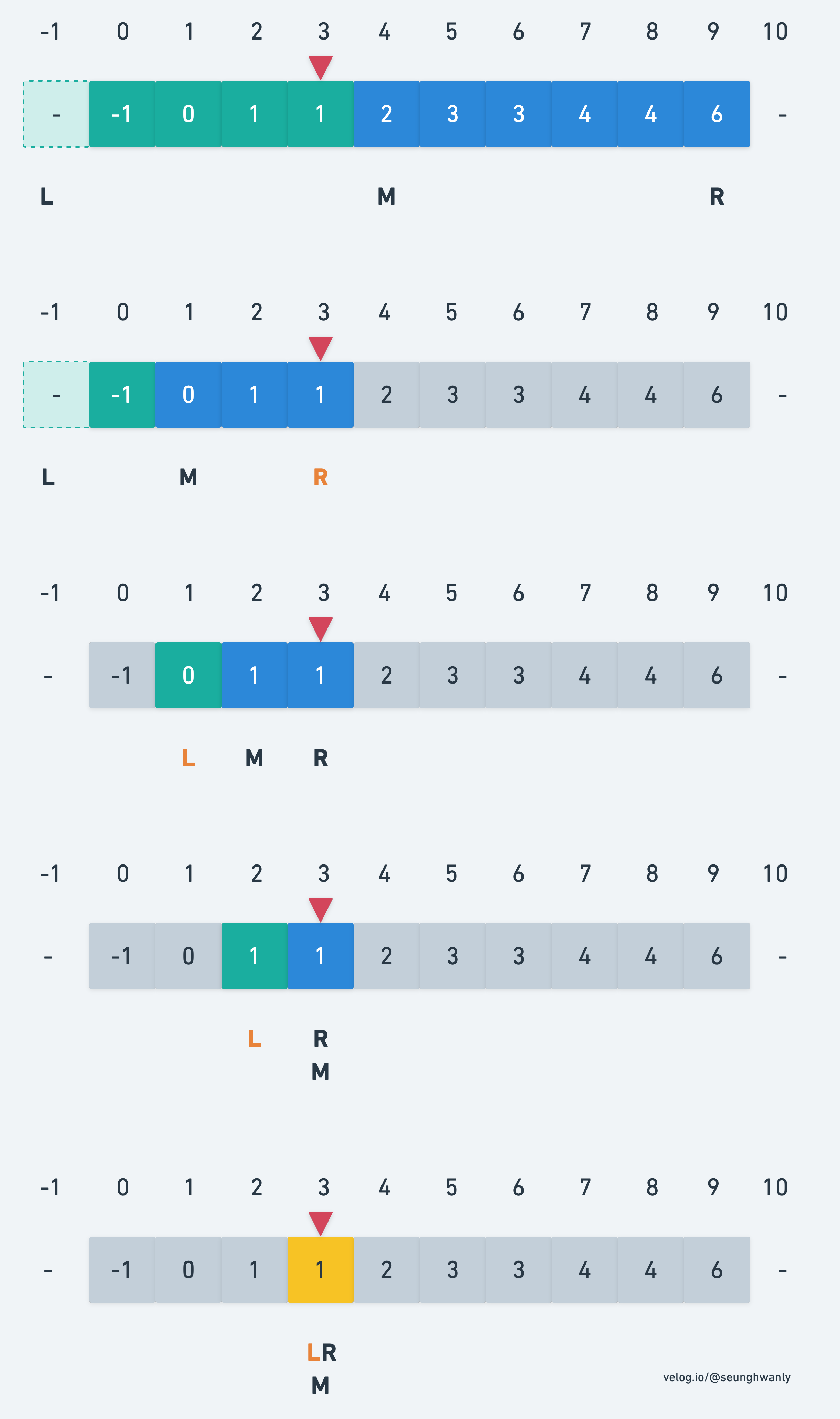
그림처럼 찾는 값인 target은 오른쪽 부분에 위치해야 최댓값이 나오기 때문에 여기서 M 값을 구할때는 최솟값과는 다르게 (L + R + 1) >> 1를 해준다. 이유는 아래 그림을 보면 알 수 있다.

L을 초기화해줄 때 M으로 하기 때문에 이와 같이 f(M)이 참인 경우에는 무한루프가 돌게 된다. 무한루프를 방지하기 위해서 +1을 해줘야 한다. 만약에 +1을 해주지 않았더라면 최댓값을 찾는 과정에서 M의 변화가 아래와 같이 이루어졌을 것이다.
| index | 1번째 | 2번째 | 3번째 | 4번째 | 5번째 | 6번째 | ... |
|---|---|---|---|---|---|---|---|
| M | 4 | 1 | 2 | 2 | 2 | 2 | 2 |
결국에 모든 경우의 수에서 L-M과 M-R 배열의 크기를 균일하게 맞춰주기 위해서 +1이 필요하다. 그렇지 않으면 무한루프에 빠지게 된다.
case 2. 소스코드
left, right = min - 1, max
while left != right:
mid = (left + right + 1) // 2
if f(mid) == True:
left = mid
else: right = mid - 1
if left == min - 1: return IMPOSSIBLE
return left개인적으로 정리하면서 규칙(?)을 찾아봤는데,
-
최솟값을 찾을 때에는 왼쪽 배열의 크기가 큰 것이 유리하므로 f(M)가 참일 때 R을 M으로 초기화해준다.
-
최댓값을 찾을 때에는 오른쪽 배열의 크기가 큰 것이 유리하므로 f(M)가 참일 때 L을 M으로 초기화해준다.
-
각
-1을 해주는 부분은 f(M)이 거짓일 때 해주는 것. -
그리고 주의해야할 점은 최댓값을 찾을 때 M을 설정해주는 방식이
(L + R + 1) >> 1이란 점
