크롤링
크롤링은 웹스크래핑이라고도 하며 말 그대로 웹에 있는 정보들을 긁아서 원하는 정보를 추출하고 활용하는 것입니다.
지난 시간에 학습한 jQuery, ajax와 크롤링을 비교해보면 'jQuery, ajax' 는 json 형식의 정돈된 데이터가 필요하지만 크롤링은 html만으로도 웹 정보를 가져올 수 있다는 점이 현재까지 느낀 가장 큰 차이 같습니다.
(잘못된 점이 있으면 언제든 댓글로 남겨주시면 감사하겠습니다!)
이런 크롤링을 가능하게 해주는 것이 바로 바로 파이썬 라이브러리 중 requests와 bs4(BeautifulSoup)라는 라이브러리들입니다!
✨👀👀✨
✔ request/bs4 라이브러리 기본 구조
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('정보를 크롤링할 url주소',headers=headers) #get방식과 post방식이 있다.
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듭니다.
# requests 로만 가져온 정보는 그냥 웹텍스트 문서에 그치지만 그것을 html로 인식할 수 있게끔 바꿔주는 것이 BeautifulSoup 라이브러리 입니다.
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됩니다.
soup = BeautifulSoup(data.text, 'html.parser')
# 크롤링 코딩 구현(보통 selector 사용)✔ 크롤링 예제
예제사이트👇
네이버 영화 페이지

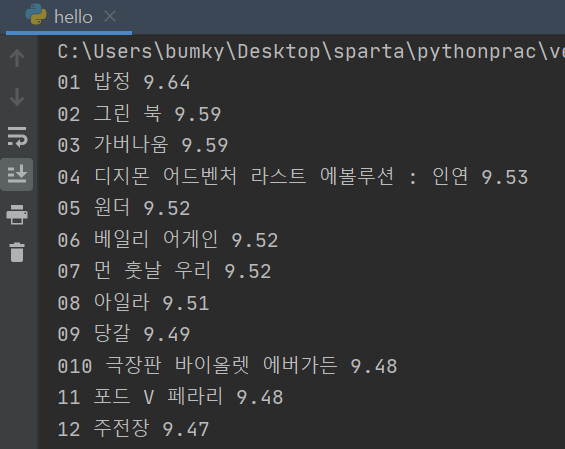
위 사진의 사이트에서 개발자도구를 활용하여 크롤링을 진행하고, 순위/ 제목/ 평점 순으로 나열해서 아래 결과와 같이 정보를 표현해보겠습니다.
결과
코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies_info = soup.select('#old_content > table > tbody > tr')
for i in movies_info:
movie = i.select_one('td.title > div > a')
rank = i.select_one('td:nth-child(1) > img')
point = i.select_one('td.point')
if movie is not None:
rank_ = rank['alt']
title_ = movie.text
point_ = point.text
print(rank_, title_, point_) 해설
-
해당 사이트를 html언어로 파싱한 것을 soup에 담고 soup의 select라는 함수를 사용해 '#old_content > table > tbody > tr'에 해당하는 html을 리스트 형식으로 받습니다.
-
위와 같은 사이트들은 대부분 html상 정형화된 틀을 갖추고 정보만 바꿈으로 리스트를 for문으로 돌렸을 시 원하는 정보를 쭉 얻을 수 있을 것입니다.
(ex. 제목이면 제목, 평점이면 평점 쭉!/ 사실 위의 movie_info 변수도 공통으로 갖고 있는 html 요소들을 묶어 놓은 html 리스트입니다.)
👉아래 결과는 movie = i.select_one('td.title > div > a')를 프린트 해본 것입니다. 사진과 같이 같은 형식의 html이 산출되고 딱봐도 저기서 텍스트만 뽑아내면 될 것 같습니다.👇
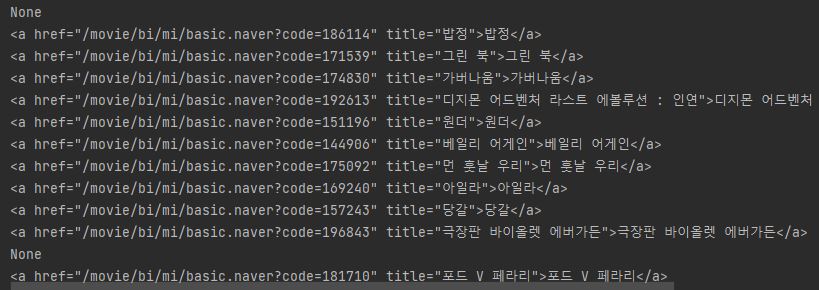
-
동일한 방법으로 rank, point를 크롤링하고 print해주면 결과값이 나옵니다.
크롤링은 이렇게 스크래핑 해오는 작업 외에도 자동화 라이브러리인 selenium과 같이 많이 쓰이는데 나중에 기회가 되면 selenium도 정리해서 올려보도록 하겠습니다.
클라우드 환경 몽고DB 사용
DB란 데이터베이스를 의미하며 말 그대로 데이터를 저장해주는 저장소를 말합니다. 일반 코드를 실행시키면 프로그램이 종료되고 메모리가 내려가면 데이터는 사라지는데, 이를 방지하는 것이기도 하고 요즘 같은 데이터 시대에 정말 중요한 기술이라고 할 수 있겠습니다.
이러한 데이터베이스는 관계형 데이터베이스, 비관계형 데이터베이스롤 나뉘는데 자세한 설명은 이곳을 참조하시길 바랍니다.
간단히 두 유형의 장단점 및 특성만 언급해보겠습니다!
👀👀
✔ 관계형 데이터베이스 'RDBMS(SQL)'
행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다.
ex) MS-SQL, My-SQL 등
✔ 비관계형 데이터베이스 'No-SQL'
딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다.
ex) MongoDB
✨ 그런데 이러한 데이터베이스를 예전엔 서버(컴퓨터)를 따로 사서 관리해야했다면, 이젠 클라우드의 시대가 도래하면서 사용하는 데이터공간만큼 가상화공간을 빌려받는 것이 가능해졌습니다. 그에 따라 우리도 NoSQL의 mongoDB를 클라우드 환경에서 사용해보겠습니다.
👉 pip install 해야하는 것 : pymongo, dnspython
mongoDB사용 명령어(기본 CRUD)
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:<비밀번호>@cluster0.okxdx.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta #db객체 생성(dbsparta는 데이터베이스 이름)
#입력
doc={
'name':'hogun2',
'age':27
}
db.user.insert_one(doc) #db 다음 user는 콜렉션 이름을 지정해주는 것임
#조회(모두)
all_users=list(db.user.find({},{'_id':False})) #False를 통해 원하지 않는 값 출력 안하는 것 숙지
#모두 조회하는 것은 주로 get방식으로 진행하며 리스트형식으로 받아오는 것이 일반적
for i in all_users:
print(i)
#조회(하나)
agent=db.user.find_one({'age':24},{'_id':False}) #앞 중괄호가 조건임, 뒤는 동일
print(agent)
#수정(하나)
#(update_one({조건},{'$set':바꿀내용})
db.user.update_one({'name':'seungho'},{'$set':{'age':26}}) #name 값이 seungho인 docs에서 age를 26으로 변경!
db.user.update_one({'name':'yujin'},{'$set':{'age':24}})
#삭제(하나)
db.user.delete_one({'name':'hogun2'})
mongoDB Atlas 저장 내용 확인
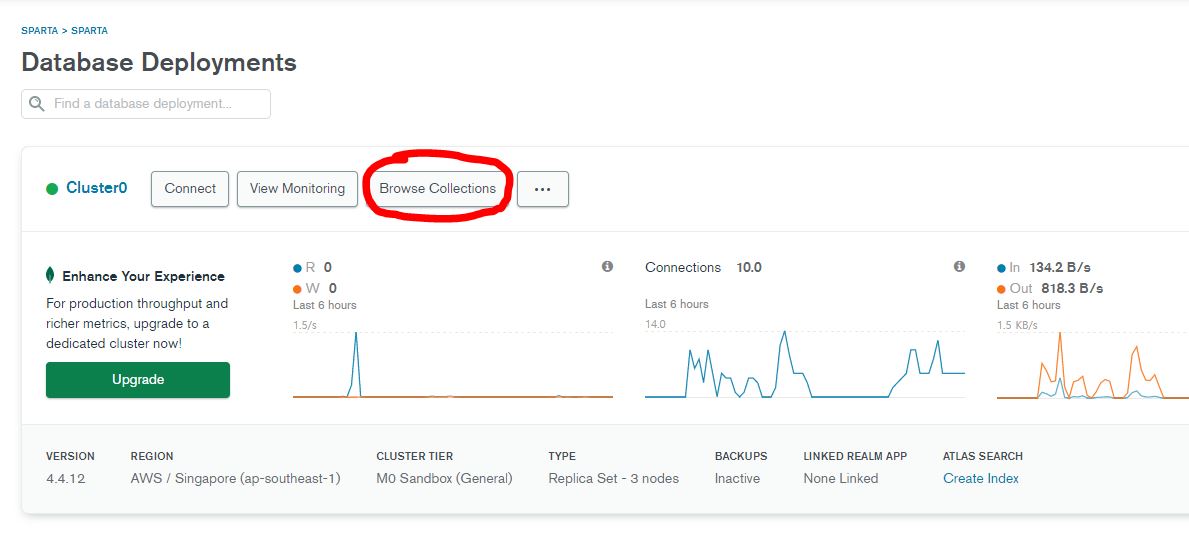
위 링크에서 설정을 잘 마쳤다면 사진과 같은 환경을 마주할 것 입니다.
위의 코드와 같이 user라는 콜렉션을 만들고 거기에 정보를 넣어준 것을 확인하기 위해선 빨간색 동그라미 부분을 우선 클릭합니다.
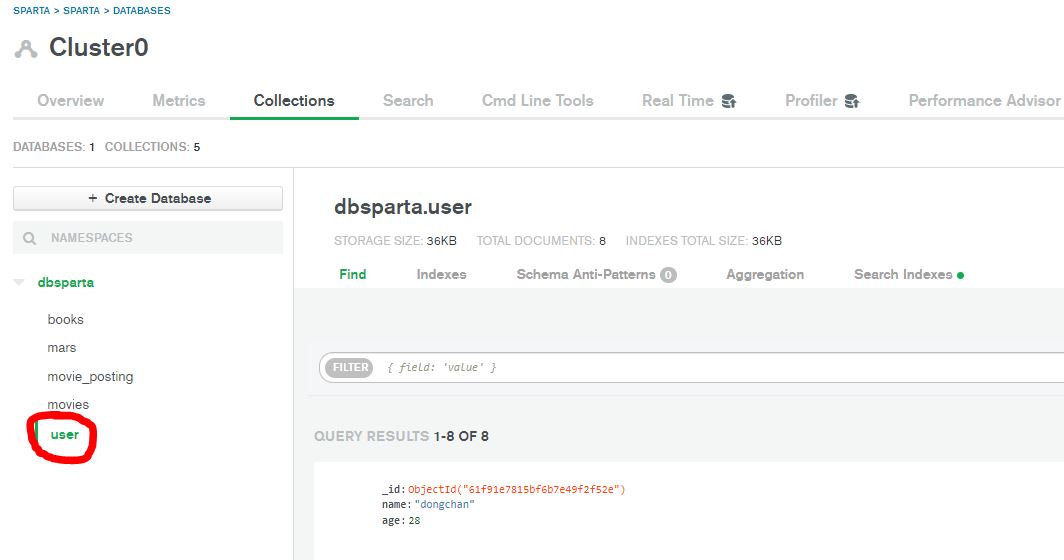
그럼 아래와 같은 화면이 나오고 좌측 배너에 콜렉션 리스트들이 나옵니다. 이때 본인이 만든 user라는 부분을 클릭하면 내용이 기입된 것을 확인할 수 있습니다.
참고
.jpg)