메모리 관리
동일한 조건일 때 메모리 용량이 크면 작업속도가 빨라집니다. 하지만 이는 로그 그래프의 형태로 기울기가 바뀌기 때문에 메모리의 크기가 어느 수준 이상이 되면 속도의 차이가 작아집니다. 따라서 한정된 크기의 메모리를 관리하는 것은 굉장히 중요한 일입니다.
메모리 관리의 이중성
프로세스 입장에서는 메모리를 독차지하려 하고 메모리 관리자 입장에서는 되도록 관리를 효율적으로 하고 싶어합니다. 프로세스가 작업하는 도중에 할당된 공간이 부족하면 메모리 관리자는 새로운 공간을 확보하기 위해 옆의 프로세스를 밀어내거나 더 큰 공간으로 해당 프로세스를 옮깁니다. 작업을 마친 후 빈 공간이 생기면 다음 작업을 위해 빈 공간을 어떻게 처리해야 할지 결정해야 합니다. 빈 공간이 여러 개 생기면 합쳐서 하나의 공간을 만들고 이렇게 하기 위해 현재 작업 중인 공간을 옆으로 밀고 작은 공간을 합칩니다. 이렇듯 메모리 관리는 굉장히 복잡하게 이루어집니다. 그렇다면 이러한 관리는 누가 하는 것일까요?
메모리 관리자의 역할
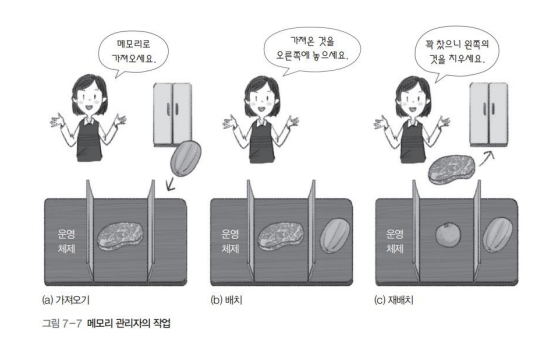
바로 메모리 관리자가 메모리를 관리합니다. 메모리 관리자는 Memory Manage Unit이라고 하며 메모리 관리를 담당하는 하드웨어입니다. 위의 3가지 작업에 대해 자세히 알아보겠습니다.
가져오기(Fetch) : 프로세스와 데이터를 메모리로 가져옵니다.
- 메모리 관리자는 사용자가 요청하면 프로세스와 데이터를 모두 메모리로 가져옵니다.
- 대용량 동영상과 같은 상황에서는 데이터의 일부만 가져와 실행합니다.
- 사용자의 요청이 없어도 앞으로 필요할 것이라고 예상되는 데이터를 미리 가져옵니다. 이를 Prefetch라고 합니다.
배치(Placement) : 가져온 프로세스와 데이터를 메모리의 어떤 부분에 올려놓을지 결정합니다.
- 배치 작업 전에 메모리를 어떤 크기로 나눌 것인지가 매우 중요합니다.
- 같은 크기로 자르느냐(페이징 혹은 고정분할), 실행되는 프로세스 크기에 맞게 자르느냐(세그멘테이션 혹은 가변분할)에 따라 메모리 관리 복잡성이 달라집니다.
재배치(Replacement) : 꽉 차 있는 메모리에 새로운 프로세스를 가져오기 위해 오래된 프로세스를 내보냅니다. 가까운 미래에 사용하지 않을 프로세스를 찾아서 내보내는 알고리즘을 교체 알고리즘이라고 합니다.
메모리 주소
32bit CPU와 64bit CPU의 차이는 CPU의 bit차이입니다. CPU의 bit는 한 번에 다룰 수 있는 데이터의 최대 크기를 의미하고 이를 워드(word)라고 부릅니다. 32bit CPU 내의 레지스터 크기는 전부 32bit, 산술 논리 연산장치와 대역폭도 32bit로 설계되어 있습니다. 그렇다면 메모리 크기는 어떨까요?
32bit CPU의 메모리 크기는 표현할 수 있는 메모리 주소의 범위가 0~2^32-1, 총 개수가 2^32개 입니다. 16진수로 나타내면 00000000~FFFFFFFF이고 총 크기가 2^32B로 약 4GB입니다.
64bit CPU의 메모리 크기는 0~2^64-1번지의 주소 공간을 제공하기 때문에 총 크기가 2^64B로 약 16777216TB로 무한대에 가까운 메모리 사용이 가능합니다.
주소 공간에는 물리 주소 공간과 논리 주소 공간이 있습니다.
물리 주소 공간은 하드웨어 입장에서 바라본 주소 공간으로 컴퓨터마다 크기가 다릅니다. 논리 주소 공간은 사용자 입장에서 바라본 주소 공간입니다.
절대주소 및 상대주소

위의 사진은 한 번에 한 가지 일만 처리하는 일괄 처리 시스템에서 볼 수 있는 단순 메모리 구조로 메모리를 운영체제 영역과 사용자 영역으로 나누어 관리합니다. 사용자 프로세스는 운영체제 영역을 피하여 메모리에 적재합니다. 사용자 프로세스가 운영체제의 크기에 따라 매번 적재되는 주소가 달라지는 것은 번거롭기 때문에 이를 개선하여 사용자 프로세스를 메모리의 최상위부터 사용합니다. 여기서 최상위는 그림상 999번 주소를 위치를 말합니다. 그러나 이러한 방법도 메모리를 거꾸로 사용하기 위해 주소를 변경하는 일이 복잡하기 때문에 잘 쓰이지 않고 경계 레지스터를 이용하는 방법을 사용합니다.
경계 레지스터는 운영체제 영역과 사용자 영역 경계 지점의 주소를 가진 레지스터입니다. CPU내에 있는 경계 레지스터가 사용자 영역이 운영체제 영역으로 침범하는 것을 방지합니다. 메모리 관리자는 사용자가 작업을 요청할 때마다 경계 레지스터의 값을 벗어나는지 검사하고 만약 경계 레지스터를 벗어나는 작업을 요창하는 프로세스가 있으면 해당 프로세스를 종료합니다. 이제 절대주소와 상대주소의 개념에 대해서 알아봅시다.
절대주소(absolute address)
- 실제 물리 주소(physical address)를 가리키는 주소입니다.
- 메모리 주소 레지스터가 사용하는 주소입니다.
- 컴퓨터에 장착된 램 메모리의 실제 주소입니다.
상대주소(relative address)
- 사용자 영역이 시작되는 번지를 0번지로 변경하여 사용하는 주소입니다.
- 사용자 프로세스 입장에서 바라본 주소입니다.
- 절대 주소와 관계없이 항상 0번지 부터 시작입니다.
- 프로세스 입장에서 상대 주소가 사용할 수 없는 영역의 위치를 알 필요가 없고 주소가 항상 0번지부터 시작하기 때문에 편리합니다.
위에서 설명한 논리 주소 공간은 상대 주소를 사용하는 주소 공간이고 물리 주소 공간은 절대 주소를 사용하는 주소 공간 입니다.
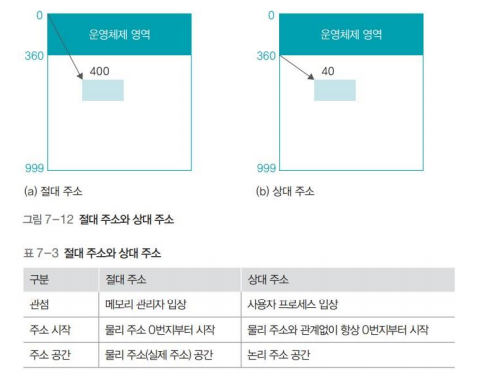
다음은 상대 주소를 절대 주소로 변환하는 과정에 대해 알아보겠습니다.
메모리 접근 시 상대 주소를 사용하면 절대 주소로 변환해야 합니다. 메모리 관리자는 사용자 프로세스가 상대 주소를 사용하여 메모리에 접근할 때마다 상대 주소 값에 재배치 레지스터 값을 더하여 절대 주소를 구합니다. 재배치 레지스터는 주소 변환의 기본이 되는 주소 값을 가진 레지스터로 메모리에서 사용자 영역의 시작 주소 값이 저장됩니다. 위의 그림에서는 360번 주소부터 사용자 영역이 시작되므로 재배치 레지스터에는 360이 저장되어 있을 것 입니다.
메모리 중첩
메모리 중첩(오버레이)는 단일 프로그래밍 환경에서의 메모리 할당을 의미합니다. 정의가 살짝 어려운데 프로그램의 크기가 실제 메모리보다 클 때 전체 프로그램을 메모리에 가져오는 대신 적당한 크기로 잘라서 가져오는 기법입니다. 따라서 메모리 오버레이를 사용하면 물리 메모리보다 더 큰 프로그램도 실행이 가능합니다. 예를 들어 워드 프로그램을 실행하고 워드 프로그램의 크기가 실제 메모리의 크기보다 클 때 현재 사용하고 있는 기능인 모듈만을 적당한 크기로 잘라 메모리에 올리는 것 입니다.
메모리 오버레이는 한정된 메모리에서 메모리보다 큰 프로그램이 실행 가능하다는 가상 메모리의 기본 개념이라는 의미가 있습니다. 또한 메모리를 여러 조각으로 나누어 여러 프로세스에 할당할 수 있다는 의미도 있습니다.
스왑(Swap)
스왑은 단일 프로그래밍 환경에서 메모리 할당을 의미합니다. 메모리 오버레이에서 메모리에 프로그램의 모듈 A를 올려 사용하고 있다고 가정해봅시다. 만약 모듈 B를 가져다가 쓰고 싶으면 모듈 A를 꺼내어 어딘가에 보관해야 합니다. 이를 하드디스크 위치에 옮겨 보관할 수도 있지만 언제 모듈 A를 다시 사용할지도 모르고 아직 작업이 끝났는지도 모르기 때문에 별도의 공간에 보관해야 합니다. 이렇듯 메모리가 부족해서 교체된 프로세스는 저장장치의 특별한 공간에 모아두는데 이 영역을 스왑 영역(swap area)라고 합니다. 메모리에서 교체되었다가 다시 돌아가는 데이터가 머무는 곳이기 때문에 저장장치는 장소만 빌려주고 메모리 관리자가 관리합니다. 사용자는 실제 메모리의 크기와 스왑 영역의 크기를 합쳐서 전체 메모리로 인식하고 사용합니다.
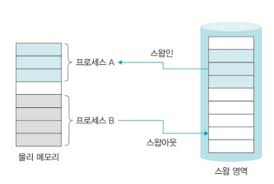
스왑인 : 스왑 영역에서 메모리로 데이터를 가져오는 작업을 의미합니다.
스왑아웃 : 메모리에서 스왑 영역으로 데이터를 내보내느 작업을 의미합니다.
메모리 분할 방식
이번 포스팅의 가장 중요한 부분이라고 생각합니다. 다중 프로그래밍 환경에서 메모리를 어떤 방법으로 분할하여 프로세스들을 올릴 수 있는지에 대해 공부해보도록 하겠습니다.
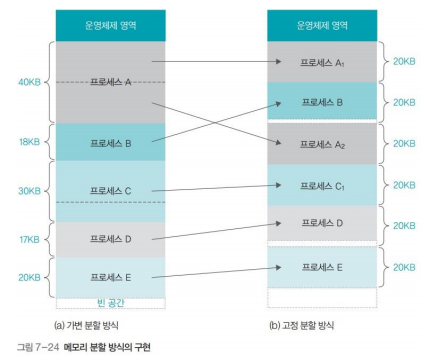
가변 분할 방식(세그멘테이션) : 프로세스의 크기에 따라 메모리를 나누는 것입니다. 따라서 메모리의 영역이 크기가 각각 다릅니다. 한 프로세스가 연속된 공간에 배치되기 때문에 연속 메모리 할당이 가능합니다. 이러한 연속 메모리 할당이 가변 분할 방식의 장점이지만 비어 있는 공간을 하나로 합쳐야 하며 이 과정에서 다른 프로세스의 자리도 옮겨야 하므로 메모리 관리가 복잡해진다는 단점이 있습니다. 위의 그림에서 프로세스 B와 D의 작업이 종료되고 19KB의 프로세스가 올라오려고 한다면 빈 공간이 분리되어 있기 때문에 올라올 수 없을 것 입니다. 따라서 빈 공간을 하나로 합쳐야 하며 이 과정에서 프로세스 C의 이동이 필연적으로 발생합니다. 이렇게 가변 분할 방식에서 발생하는 작은 빈 공간을 외부 단편화(external fragmentation)이라고 합니다.
고정 분할 방식(페이징) : 프로세스의 크기와 상관없이 메모리를 동일한 크기로 나누는 것입니다. 고정 분할 방식은 큰 프로세스가 메모리에 올라오면 여러 조각으로 나누어 배치하고 한 프로세스가 분산되어 배치되기 때문에 비연속 메모리 할당입니다. 메모리를 일정한 크기로 나누어 관리하기 때문에 메모리 관리가 수월하다(메모리 통합 같은 부가적인 작업을 할 필요가 없기때문에)는 장점이 있지만 쓸모없는 공간으로 인해 메모리 낭비가 발생할 수 있다는 단점이 있습니다. 위의 그림에서 프로세스 B는 18KB, D는 17KB이기 때문에 메모리의 한 조각인 20KB에 배치하면 각각 2KB, 3KB씩 공간이 남습니다. 이러한 현상을 내부 단편화(internal fragmentation)라고 합니다.
가변 분할 방식의 메모리 관리
그렇다면 가변 분할 방식에서는 어떻게 메모리를 관리해야 할까요? 먼저 외부 단편화를 해결해야 합니다. 작은 조각이 발생하지 않도록 프로세스를 배치해야 하고 조각이 발생했을 때 작은 조각들을 모아서 하나의 큰 덩어리로 만드는 조각 모음 작업을 수행하면 됩니다.
작은 조각이 발생하지 않도록 프로세스를 배치하는 방식에는 3가지가 있습니다.
최초 배치(first fit) : 프로세스를 메모리의 빈 공간에 배치할 때 메모리에서 적재 가능한 공간을 순서대로 찾다가 첫 번째로 발견한 공간에 프로세스를 배치하는 방법입니다. 빈 공간을 찾아다닐 필요가 없습니다.
최적 배치(best fit) : 메모리의 빈 공간을 모두 확인한 후 적당한 크기 가운데 가장 작은 공간에 프로세스를 배치하는 방법입니다. 빈 공간을 모두 확인하는 부가 작업이 있지만 딱 맞는 공간을 찾는 경우 단편화가 일어나지 않습니다. 하지만 딱 맞는 공간이 없는 경우 아주 작은 조각을 만들어내는 단점이 있습니다.
최악 배치(worst fit) : 빈 공간을 모두 확인한 후 가장 큰 공간에 프로세스를 배치하는 방법입니다. 주로 큰 빈 공간이 있을 때 사용하면 좋습니다. 최적 배치와 반대로 접근하는 개념이며 프로세스를 배치하고 남는 공간이 크기 때문에 다른 프로세스가 와도 됩니다. 빈 공간의 크기가 클때는 효율적이지만 빈 공간의 크기가 점점 줄어들면 최적 배치처럼 작은 조각을 만들어내는 단점이 있습니다.
하지만 위의 3가지 방법을 이용해 프로세스를 배치해도 여전히 단편화 현상이 발생합니다. 이에 따라 조각 모음을 실행해야 합니다.
조각 모음 : 이미 배치된 프로세스를 옆으로 옮겨 빈 공간들을 하나의 큰 덩어리로 만드는 작업입니다. 조각 모음을 하기 위해서는 이동할 프로세스의 동작을 멈추고 프로세스를 적당한 위치로 옮깁니다.(프로세스가 이동하기 때문에 프로세스의 상대 주소 값을 바꿉니다.) 작업을 다 마친 후에는 프로세스를 다시 시작합니다.
고정 분할 방식의 메모리 관리
고정 분할 방식은 가변 분할 방식보다 공간을 효율적으로 관리합니다. 고정 분할 방식은 조각모음을 할 필요가 없어 관리가 원활하며 메모리 관리 시스템의 기본 방식으로 사용됩니다. 만약 메모리를 20KB씩 분할한다고 가정했을 때 프로세스 C의 크기가 30KB이면 C는 20KB인 C1과 10KB인 C2로 나뉜뒤 C2는 메모리에 남는 공간이 없을 경우 스왑 영역으로 옮겨지게 됩니다. 고정 분할 방식은 내부 단편화를 줄이기 위해 신중하게 메모리의 크기를 결정해서 나눠야 하지만 사용하는 프로세스의 크기가 제각각이기 때문에 메모리를 얼마로 나누느냐에 대한 정답은 없습니다.
버디 시스템
가변 분할 방식과 고정 분할 방식 외에 새로 등장한 메모리 분할 방법입니다. 버디 시스템의 작동 방식은 다음과 같습니다.
- 프로세스의 크기에 맞게 메모리를 1/2로 자르고 프로세스를 메모리에 배치합니다.
- 나뉜 메모리의 각 구역에는 프로세스가 1개만 배치 됩니다.
- 프로세스가 종료되면 주변의 빈 조각과 합쳐서 하나의 큰 덩어리를 만듭니다.
버디 시스템은 다음과 같은 특징을 가집니다.
- 가변 분할 방식처럼 메모리가 프로세스 크기대로 나뉩니다.
- 고정 분할 방식처럼 하나의 구역에 다른 프로세스가 들어갈 수 없고 메모리의 한 구역 내부에 작은 조각이 생겨 내부 단편화가 발생합니다.
- 비슷한 크기의 조각이 서로 모여 작은 조각을 통합하여 큰 조각을 만들기 쉽습니다.
- 효율적인 공간 관리 측면에서 보면 고정 분할 방식과 버디 시스템은 비슷합니다. 그러나 공간을 1/2로 나누어 가면서 메모리를 배분하는 버디 시스템보다 모든 공간을 동일한 크기로 나누는 고정 분할 방식이 메모리 관리 측면에서 단순하기 때문에 고정분할 방법이 많이 사용됩니다.
