[2021.09.28] 2 Stage Detectors
0

💡 R-CNN부터 SPPNet, Fast R-CNN, 그리고 최신 2 Stage Detector들의 기초가 되는 Faster R-CNN
Background
입력 이미지 -- 계산 --> Localization -- 계산 --> Classification
1. 객체 위치
2. 각각의 객체 classification
R-CNN
- 이미지 입력
- Region proposal (객체가 있을법한 후보 영역) 추출
- Sliding window
- Selective Search
- CNN feature 계산
- Classify Regions
Pipeline
- 입력 이미지 받기
- Selective search -> 2000개의 RoI 추출
- RoI -- Warping --> 동일한 size
- CNN의 마지막 FC layer 입력 사이즈가 고정
- RoI -- CNN --> Feature 추출
- 각 region마다 4096 dim feature vector 추출 (2000x4096)
- Pretrained AlexNet 구조
- 마지막에 FC layer 추가
- 필요에 따라 Finetuning 진행
- CNN에서 추출한 Feature -- SVM --> 분류
- Input: 2000x4096 features
- Output: Class (C+1(배경)) + Confidence scores
- CNN 통해 나온 feature -- Regression --> bounding box 예측
- Selective search 통해 나온 후보 위치를 미세 조정
- 중심점 좌표 (x,y), w, h
Training
AlexNet
- Domain specific finetuning
- Dataset
- IoU > 0.5: (+)
- IoU < 0.5: (-)
- (+) samples 32 / (-) samples 96
Linear SVM
- Dataset
- Ground truth: (+)
- IoU < 0.3: (-)
- (+) samples 32 / (-) samples 96
- Hard negative mining
- Hard negative: False Positive
- 배경으로 식별하기 어려운 샘플 -> 강제로 다음 배치의 negative sample로 minig
Bbox regressor
- Dataset
- IoU > 0.6: (+)
- 중심점을 얼마나 이동, width & height 얼마나 확대/축소
- Loss function: MSE Loss
Shortcomings
- 2000개의 region 각각 CNN 통과 -> 연산량 많음. 속도 느림
- 강제 Warping -> 정보 손실 -> 성능 하락 가능성
- CNN, SVM classifier, bounding box regressor 따로 학습
- End-to-End X (Selective search)
SPPNet
R-CNN 한계점
- ConvNet 입력 이미지 고정 -> crop/warp
- RoI(Region of Interest)마다 CNN 통과
Pipeline
- Image --Conv layers--> Spatial pyramid pooling --FC layers--> Output
- 한번의 conv 연산으로 나온 feature map에 2000개의 region 뽑아냄
- warping하지 않고 spatial pyramid pooling으로 고정된 크기로 변환
Spatial Pyramid Pooling
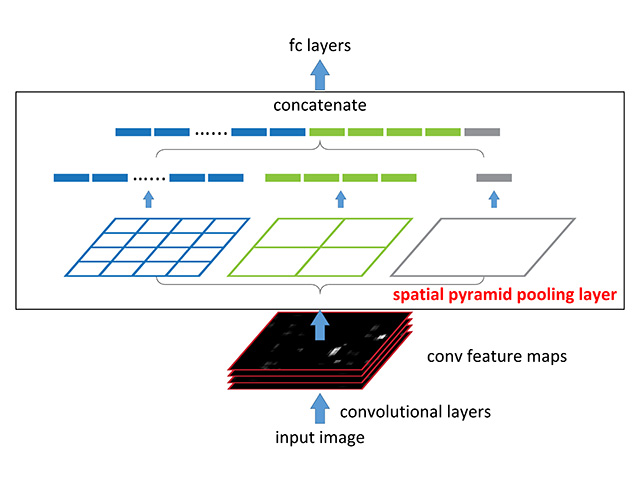
- 같은 사이즈로 나눠서 각 영역마다 하나의 feature 뽑아냄
=> 같은 개수(영역 개수)의 feature
Shortcomings
1. 2000개의 RoI 각각 CNN 통과 - 먼저 CNN 통과해서 RoI 뽑음
2. 강제 Warping - Spatial pyramid pooling으로 고정된 크기 feature 뽑음
3. CNN, SVM classifier, bounding box regression 따로 학습
4. End-to-End X
Fast R-CNN
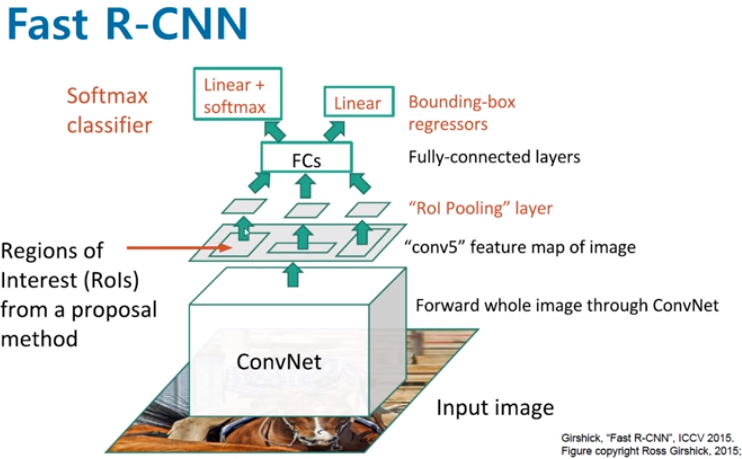
Pipeline
- 이미지를 CNN에 넣어 feature 추출 (CNN 한 번 사용)
- VGG16
- RoI projection --> feature map 상 RoI 계산
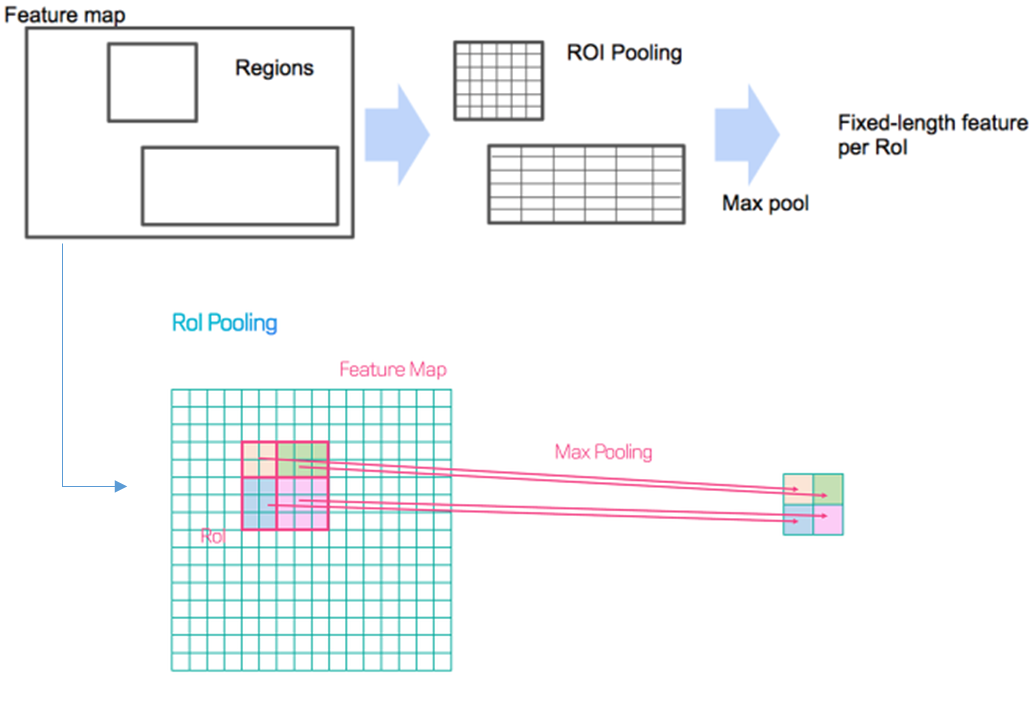
- RoI pooling --> 일정한 크기의 feature
- Spatial pyramid pooling
- Pyramid level: 1
- Target grid size: 7x7
- Fully connected layer
- Softmax Classifier & Bounding Box Regressor
- 클래스 개수: C+1(배경)개
Training
- Multi task loss 사용
- Classification loss + bounding box regression
- Loss function
- Classification: Cross entropy
- BB regressor: Smooth L1 (다른 L1, L2보다 outlier 덜 민감)
- Dataset 구성
- IoU > 0.5: (+)
- 0.1 < IoU < 0.5: (-)
- (+) 25% / (-) 75%
- Hierarchical sampling
- R-CNN의 경우 이미지에 존재하는 RoI 전부 저장해 사용
- 한 배치에 서로 다른 이미지의 RoI 포함됨
- Fast R-CNN: 한 배치에 한 이미지의 RoI만 포함
- 한 배치 안에서 연산, 메모리 공유 가능
- R-CNN의 경우 이미지에 존재하는 RoI 전부 저장해 사용
Shortcomings
1. 2000개의 RoI 각각 CNN 통과
2. 강제 Warping
3. CNN, SVM classifier, bounding box regression 따로 학습
4. End-to-End X
- Selective search -- CPU --> 학습 가능 X
Faster R-CNN

Pipeline
- 이미지 -- CNN --> feature maps (CNN 한 번 사용)
- RPN --> RoI 계산
- 기존 selective search 대체
- Anchor box
- 각 셀마다 N개의 Anchor box 정의 -> 여러 객체 크기 대응 가능
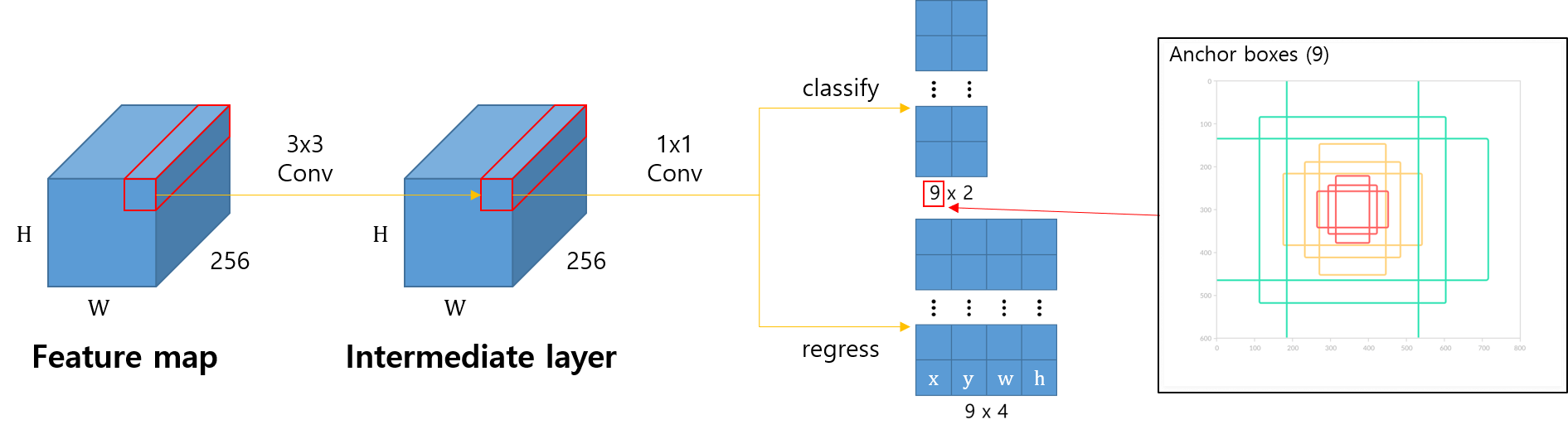
- 각 셀마다 N개의 Anchor box 정의 -> 여러 객체 크기 대응 가능
Region Proposal Network (RPN)
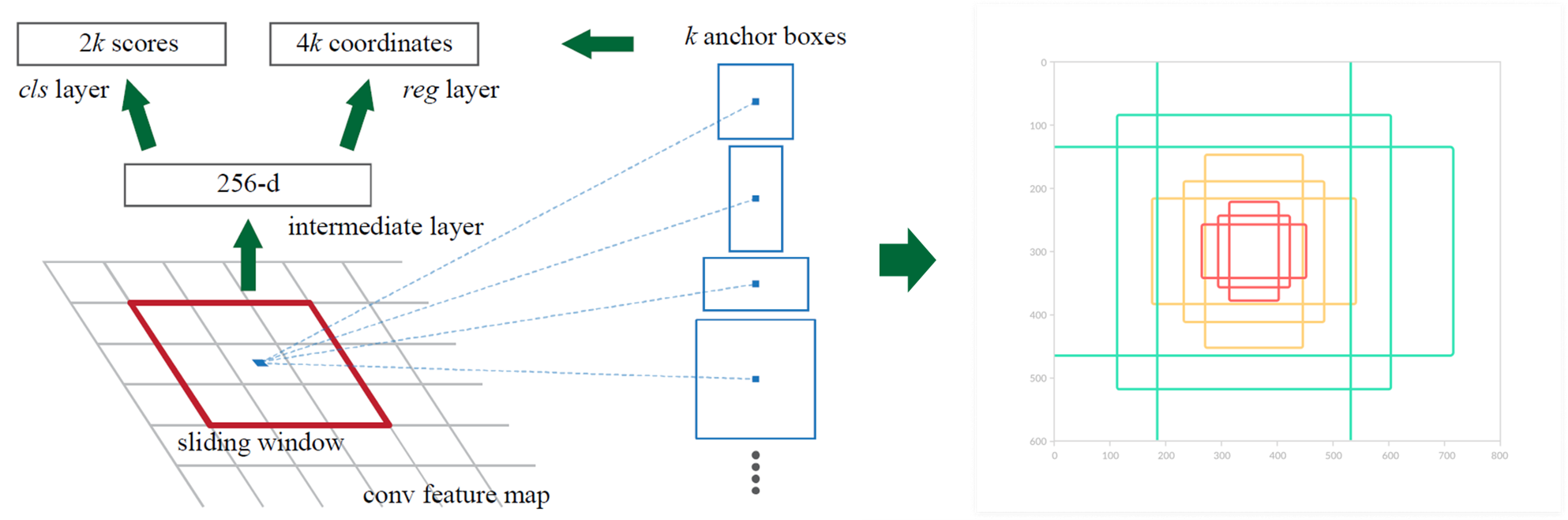
- Input: CNN에서 나온 feature map (H,W,C)
- 3x3 conv --> intermediate layer 생성
- 1x1 conv --> binary classification 수행
- 2 (object or not) x 9 (# of anchors) channel
- 1x1 conv --> bbox regression 수행
- 4 (bbox) x 9 (# of anchors) channel
- 4: 중심점 좌표 x, y, 가로, 세로 길이
NMS
- 유사한 RPN Proposals 제거
- Class score 기준으로 proposals 분류
- 각 bbox에 대해 다른 bbox와의 IoU 계산
- IoU >= 0.7 proposals 영역들은 중복된 영역으로 판단
Training
- Region Proposal Network (RPN)
- RPN 단계에서 classification & regressor 학습 위해 anchor box (+)/(-) samples 구분
- Dataset
- IoU > 0.7 or GT 가장 높은 IoU: (+)
- IoU < 0.3: (-)
- 나머지: 학습데이터 사용 X
- Loss 함수
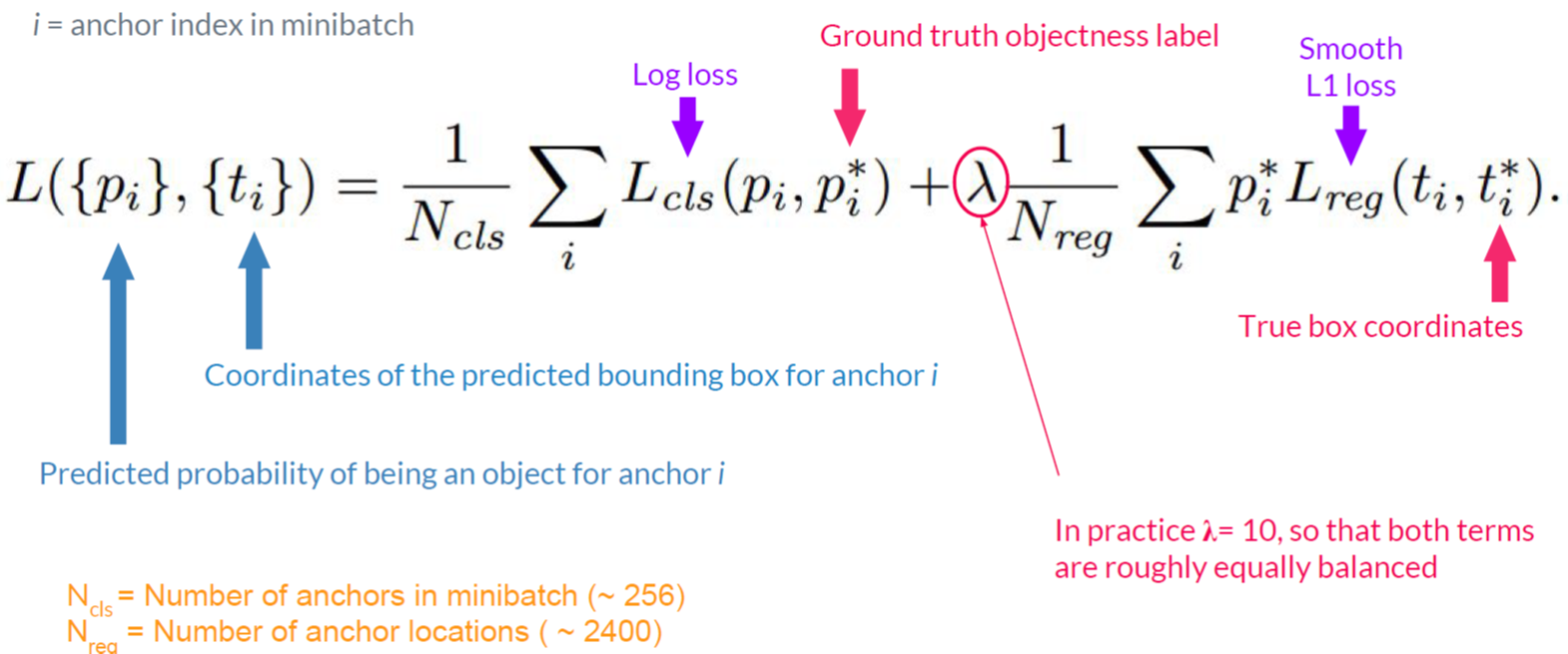
- Region proposal 이후 Fast RCNN 학습 위해 (+)/(-) samples 구분
- Dataset
- IoU > 0.5: (+) -> 32개
- IoU < 0.5: (-) -> 96개
- 128 samples로 mini-batch 구성
- Loss 함수 : Fast RCNN과 동일
- RPN & Fast RCNN 학습
- Imagenet pretrained backbone load + RPN 학습
- Imagenet pretrained backbone load + RPN (1) + Fast RCNN 학습
- (2) finetuned backbone load & freeze + RPN 학습
- (2) finetuned backbone load & freeze + RPN (3) + Fast RCNN 학습
- 학습 과정 복잡 => Approximate Joint Training 활용
- Loss들 다 더해서 한 번에 backward 시키는 방법 사용
Summary
| R-CNN | Faster R-CNN | Faster R-CNN | |
|---|---|---|---|
| Classification | SVMs | Linear | Linear |
| Resize | Warp | RoI Pooling | RoI Pooling |
| End-to-End | X | X | O |
