
1. 정렬
정렬(Sorting)은 데이터를 사용자가 설정한 기준에 따라서 순서대로 나열하는 것을 말한다. 보통은 문제의 조건에 따라서 오름차순이나 내림차순으로 정렬을 한다. 정렬되는 데이터는 꼭 하나의 '수' 혹은 '문자' 뿐만 아니라, 데이터 값이 2개가 입력된 튜플 자료형이 하나의 값으로써 사용자의 설정에 따라서 정렬되기도 한다. 단순히 정렬을 해야 하는 경우라면 내장 함수 sort, sorted를 사용하는데, 문제의 조건에 따라서 직접 정렬을 시켜야 하는 경우도 있기에 여러가지 방법으로 데이터를 정렬하는 법을 살펴보자.
특히 선택, 삽입, 버블, 계수정렬은 for/while 반복문을 통해 정렬을 시키는데 반해, 병합정렬과 퀵정렬은 재귀함수를 통한 반복문을 실행시키기에 앞의 4가지 방법보다 연산이 빠르다는 장점이 있지만 재귀함수의 이해가 선행되지 않으면 이해하기 조금 어렵다는 단점이 있다. 병합과 퀵정렬을 살펴보겠다.
2. 퀵정렬
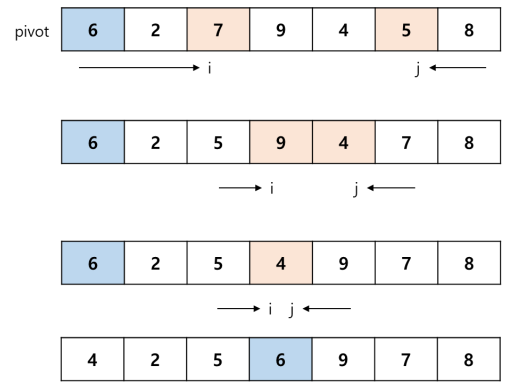
퀵정렬은 정렬되지 않은 데이터가 리스트로 입력되면, 리스트 중 임시 피봇(Pivot)의 값을 정하고 피봇값을 중심으로 나눈다. 피봇보다 작은 값은 왼쪽, 큰 값은 오른쪽으로 나눈다. 나눈 그 값을 다시 재귀적으로 반복하여 피봇값을 다시 정하고 길이가 최소가 될 때까지 나누면서 정렬해 나가는 방식이다. 퀵정렬은 전위순회 방식으로 진행된다. 위의 예시는 중간값을 찾아 Pivot로 설정하였다.
그림출처:제로베이스

2.1 과정
- 파이썬에서는 퀵정렬을 위해 리스트를 사용한다. 먼저 리스트 안의 데이터 값 중에서 기준값이 될 Pivot값을 설정해야 한다. 그 Pivot값을 중심으로 왼쪽은 Pivot보다 작은 값을 오른쪽은 Pivot보다 큰 값을 둔다. 이 기준값은 리스트의 제일 앞 자리의 수가 될 수도 있고 마지막 수가 될수도 있다. 아니면 아래의 그림과 같이 처음부터 리스트에 담긴 배열값들 중에서 중간 값을 찾아서 시작할 수도 있다.
- 이제 피봇을 중심으로 왼쪽과 오른쪽 값이 정해졌고 피봇의 값 또한 제자리(피봇값을 중심에 두고 좌우로 나눴기 때문에)를 찾아 갔다. 두 부분으로 나뉜 리스트를 다시 피봇값을 정하여 피봇값을 중심으로 최소의 길이가 될 때까지 분할한다.
- 병합정렬 때에는 먼저 나눈 후 병합 과정에서 오름차순으로 합쳤던 반면, 퀵정렬은 나누면서 왼쪽엔 작은 값을, 오른쪽은 큰 값으로 나누기 때문에 최소값까지 내려간다면 정렬이 이미 되어있는 상태다. 그래서 최소단위로 나눈 것을 왼쪽부터 순서대로 합쳐주면 된다.
2.2 코드
마지막 인덱스를 pivot로 설정하여 진행하겠다.
그리고 새로운 임시 변수 리스트를 만들지 않고(공간 복잡도를 낮춰), 반복문을 진행하면서 pivot보다 작은 값이 발견되면 0번 인덱스의 자리에, pivot 보다 작은 값과 인덱스 0번 자리의 값을 바꾼다. 그리고 다음 바꿀 인덱스자리를 +1하는 식으로 설정하고 모든 반복문이 끝이 나면 바꿀 인덱스 자리와 pivot값을 바꾼다. 이렇게 되면 pivot보다 작은 값은 왼쪽에 큰 값은 오른쪽에 위치하게 된다.def Qsort(lt, rt): # 정렬되지 않은 리스트의 처음과 끝의 인덱스를 매개변수로 받는다 if lt < rt: # 리스트의 길이가 1 까지 분할(길이가 1이라면 lt == rt) pivot = arr[rt] # 마지막 값을 pivot 값으로 pt = lt # 피봇값을 중심으로 나누기에 피봇값이 들어갈 자리를 찾아갈 지점 변수(리스트 0번 인덱스, 작은 값과 교체할 인덱스 지점) for i in range(lt, rt): # pivot값 전까지 반복하며 작은 수는 왼쪽, 큰 수는 오른쪽으로 분할 한다. if arr[i] <= pivot: # pivot값 보다 작다면 교체 -> pt는 왼쪽 첫번째 인덱스로 피봇보다 작은 값을 왼쪽으로 넣어주는 역할. arr[i], arr[pt] = arr[pt], arr[i] # 피봇보다 작은 값이라면 왼족의 pt값 자리에 작은 수를 넣어 교체한다. pt += 1 # 교체한 작은 값 다음 인덱스에 자리(반복문이 끝나면, 이 자리에 pivot값을 넣어준다) # 피봇을 중심으로 크냐, 작으냐만 따져서 자리잠은 상태(아직 정렬은 X) # 반복문이 끝나면 pt의 자리는 pivot 값보다 작은 수 다음에 자리잡고 있기에 pivot과 교체 arr[rt], arr[pt] = arr[pt], arr[rt] print('Course:', arr) Qsort(lt, pt-1) # pivot 보다 작은 값을, 다시 분할/합병 Qsort(pt+1, rt) # pivot 보다 큰 값을, 다시 분할/합병 if __name__ == '__main__': arr = [4, 2, 3, 6, 5, 7, 11, 1, 10, 9, 8] lt = 0 rt = len(arr) print('Before:', arr) Qsort(lt, rt-1) print('After :', arr) 출력: Before: [4, 2, 3, 6, 5, 7, 11, 1, 10, 9, 8] Course: [4, 2, 3, 6, 5, 7, 1, 8, 10, 9, 11] Course: [1, 2, 3, 6, 5, 7, 4, 8, 10, 9, 11] Course: [1, 2, 3, 4, 5, 7, 6, 8, 10, 9, 11] Course: [1, 2, 3, 4, 5, 7, 6, 8, 10, 9, 11] Course: [1, 2, 3, 4, 5, 6, 7, 8, 10, 9, 11] Course: [1, 2, 3, 4, 5, 6, 7, 8, 10, 9, 11] Course: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] After : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
3. 복잡도
보통 퀵정렬은 병합정렬과 같이 O(NlogN)의 연산 횟수를 가진다. 하지만 이미 정렬이 되어있는 배열을 정렬하게 된다면 최악의 경우는 O(N2)가 된다. 예로 1부터 11까지 정렬이 되어있고 11이 pivot가 된다면 왼쪽/오른쪽으로 나눌 시, 11과 왼쪽 부분으로만 나눠지게 된다. 다음 나눌 때에도 10과 왼쪽......이렇게 진행이 된다. 그러면 N길이 만큼 N번의 분할이 일어나게 되어 N2의 연산 횟수를 가진다.
공간복잡도는 반으로 계속 나누어 내려가기에 O(logN)의 복잡도를 가진다.
